
- 1GEE入门学习,遥感云大数据分析、管理与可视化以及在林业应用丨灾害、水体与湿地领域应用丨GPT模型应用
- 2OK6410开发环境的搭建_ok6410开发板引导设置
- 3Neovim开发环境搭建(2021.07.01)_neovim 远程开发
- 4Android自适应屏幕大小和layout布局(横屏|竖屏)_安卓横屏图片会自动缩小放大吗?
- 5调用MapReduce对文件中各个单词出现的次数进行统计_mapreduce统计单词出现次数
- 6ChatGPT最强对手Claude使用教程_chatgpt对手
- 7c++实现对图像数据的读写_c++读取图片
- 8【计算机视觉 | 目标检测】OVD:Open-Vocabulary Object Detection 论文工作总结(共八篇)_ovr-cnn
- 9『GDAL』读写TIFF文件_gdal读取tif
- 10动图轻松理解Self-Attention(自注意力机制)_self attention
Eclipse利用Hadoop平台实现统计单词个数_hadoop单词统计和去重eclip
赞
踩
统计单词个数
要求
1.将待分析的文件(不少于10000英文单词)上传到HDFS
2.调用MapReduce对文件中各个单词出现的次数进行统计
3.将统计结果下载本地。
过程
1.首先启动hadoop,用jps判断是否启动成功,如果成功,则如下图所示
2.递归创建/user/hadoop/input目录,将不少于10000字单词的文件上传到/user/hadoop/input目录下

3.打开eclipse进行配置,填写工作空间
4.选择 Window 菜单下的 Preference

5.切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Open Perspective -> Other(CentOS 是 Window -> Perspective -> Open Perspective -> Other),弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换
6.建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location
7.在弹出来的 General 选项面板中,进行配置
8.在eclipse中创建MapReduce项目,点击 File 菜单,选择 New -> Project…,选择 Map/Reduce Project,点击 Next
9.填写 Project name ,点击 Finish 就创建好了项目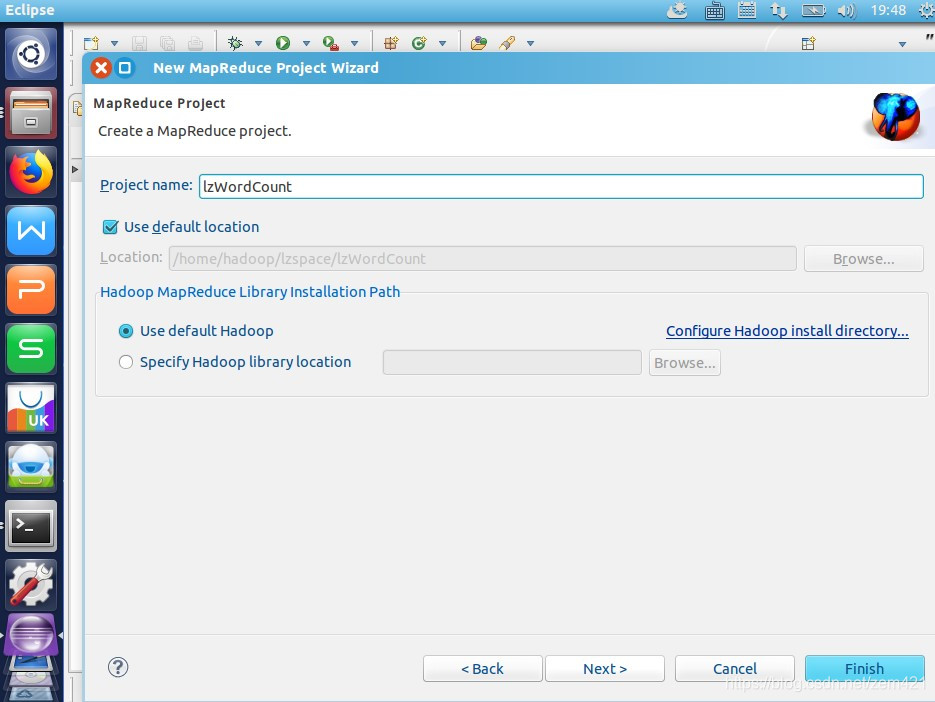
10.接着右键点击刚创建的 WordCount 项目,选择 New -> Class,需要填写两个地方:在 Package 处填写 org.apache.hadoop.examples;在 Name 处要填写

11.创建 Class 完成后,在 Project 的 src 中就能看到 lzWordCount.java 这个文件。将如下 lzWordCount 的代码复制到该文件中
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable- 1
- 2
- 3
- 4
- 5
- 6
- 7

