
热门标签
热门文章
- 1MySQL数据库之分库分表方案_mysql8 分库
- 2JSP简答题知识点
- 3C语言---------strlen的使用和模拟实现
- 4攻城狮久坐腰疼需要一把好的人体工学椅,附双11人体工学椅开箱体验
- 5Viterbi算法原理与实现-通俗易懂
- 6 记录使用微信小程序的开发过程中遇到的各种难点及教程(不定时更新)
- 7云计算:计算机网络基础(第二天课程分享)DNS协议 各协议_dns云计算
- 8微信小程序反编译教程获取源码_微信小程序反编译的代码怎么看
- 92024三掌柜赠书活动第十五期:Python高效编程——基于Rust语言
- 10大数据毕业设计 opencv指纹识别系统 - python 图像识别_基于opencv的毕业设计
当前位置: article > 正文
T5,一个探索迁移学习边界的模型
作者:你好赵伟 | 2024-04-01 10:35:35
赞
踩
t5模型

作者 | Ajit Rajasekharan
译者 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
T5是什么?
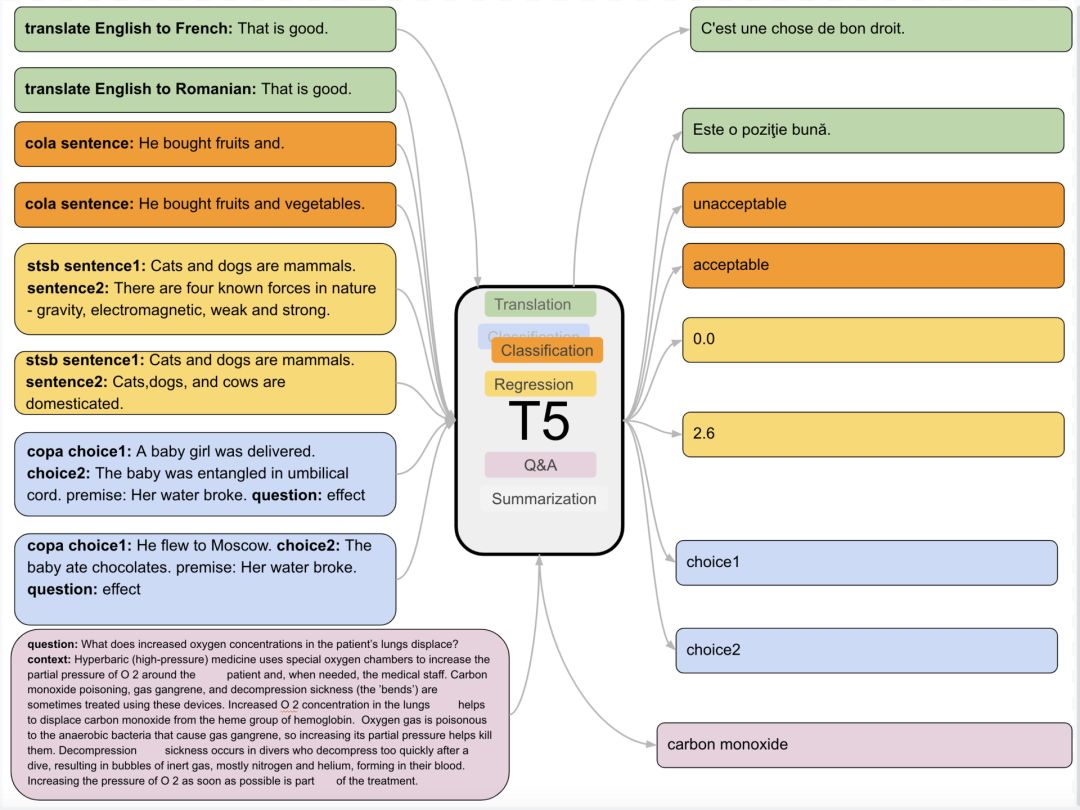
T5 是一个文本到文本迁移 Transformer 模型,通过将所有任务统一视为一个输入文本并输出文本,其中任务类型作为描述符嵌入到输入中。该模型使单个模型可以执行各种各样的有监督任务,例如翻译、分类、Q&A、摘要和回归(例如,输出介于 1 到 5 之间两个句子之间的相似性得分。实际上,这是一个 21 类分类问题,如下所述)。该模型首先在大型语料库上进行无监督的预训练(像 BERT 中一样的隐蔽目标),然后进行有监督训练,其中包含代表所有这些任务的输入文本和相关带标签的数据,也就是文本(其中输入流中的特定标记“将英语翻译为法语”或“ stsb句子1:…句子2”,“问题” /“上下文”等对任务类型进行编码,如上图所示,模型经过训练输出与标记数据匹配的文本。)通过这种为监督学习指定输入和输出的方法,该模型在所有不同的任务之间共享其损失函数、解码器等。
T5的贡献是什么?
T5 模型通过将不同的任务编码为输入流中的文本指令,以统一的方式处理各种多对一和多对一 NLP 任务。这样一来,就可以在多种 NLP 任务中(例如翻译、分类、Q&A、摘要,甚至回归)有监督地训练单个模型(尽管实际上它实际上是一种分类)。
虽然这项工作是大规模 Q&A、总结等方面的最新技术成果,但主要贡献也不在于模型,因为这种形式的文本编码方法此前已经有 GPT2 这样的“前辈”存在,除了是在无监督文本情况下之外,它们使用的是相同的思想(因为 GPT2 不能进行分类或标记问题,而 T5 可以在有监督学习阶段进行)。
本文的目的主要是通过使用 T5 模型
-
研究从大规模的无监督预训练到监督任务,与大规模利用转移学习相关的因素
在此过程中,性能指标也体现出迁移学习在某些语言理解(在人的层面上)任务上的局限性。虽然本文重点是解决未来研究的这些局限性,但在扩展语言理解(不仅是文本)上也有一些进展工作(例如,Yoshua Bengio 的 grounded language understanding https://openreview.net/pdf?id=rJeXCo0cYX)。这些新方法直接从文本解决了当前迁移学习方法的一些缺陷,如样本效率、常识理解、因果推理等。
论文的主要发现
-
本论文主要关注基于 Transfomer 的模型(与基于 RNN 的序列模型相反)。基于编码器/解码器的 Transfomer 体系结构最适合 T5 模型中使用的文本到文本方法。通过在编码器和解码器之间共享参数计数,参数数量与诸如 BERT 的仅编码器模型相同,而性能没有明显下降。
-
掩蔽目标(去噪)与 BERT 中使用的掩蔽目标(以及其变体,例如被掩盖的跨度)相同,其性能优于语言建模目标。
-
最好在大型数据集上进行预训练,而不是小型数据集(尤其是在预训练中多次出现的数据时,对于大型数据集而言,这不是问题)。此外,对域内数据进行预训练还可以提高下游任务的性能。
-
尽管计算量很大,但在微调过程中更新预训练模型的所有参数所达到的性能要优于仅更新几个参数(请参见下文的最终思路)。
-
通过在更多数据上训练模型,训练更大的模型或使用组合方法,都可以提高性能。
-
仅针对英语的预训练方法未在翻译中产生最先进的结果(法语、德语和罗马尼亚语;请参见下图),这表明这是一种与语言相关的方法。
-
通过使用掩膜(去噪)进行预训练以在下游任务中使用提取的知识,知识提取能力似乎在模型从仅预测损坏的文本跨度中学习知识时受到限制。如前所述,这一发现表明学习方法不仅限于文本(例如,grounded language understanding)。
其他细节
-
此模型的初始版本仅支持在 TPU 上运行。该链接(https://medium.com/@ajitrajasekharan/setting-up-a-tpu-node-in-google-cloud-step-by-step-instructions-2236ac2aacf7)将逐步介绍设置虚拟机和 TPU 节点的步骤。请注意,按照安装说明,使用具有正确的 Tensorflow 版本的 TPU 节点,以免发生错误。
-
下图显示了使用“小”模型对输入进行解码的完整测试结果(有关说明,请参见 Github https://github.com/google-research/text-to-text-transfer-transformer#decode 的解码部分。本测试还包括不同大小的预训练模型测试。由于内存需求较大,我无法使用基本模型和大型模型。其中 Winograd schemas style 测试没有产生本论文的结果,不知道是什么问题。

-
这种文本到文本方法还带来了挑战,即该模型可能会不输出预期在测试阶段输出的单词之一。举例来说,在上述“可乐测试”(测试句子语法是可接受的/不可接受的)中,模型可能输出的是“选择1”或“选择2”以外的字符串。作者声称这种情况将被视为测试失败,虽然他们还未观察到这种情况。另外,模型对于相同的输入可能输出不同的结果,这在聚合时很明显。
-
最后,现实中用于回归的模型只是 21 类分类。与真正的回归模型输出可以是一个连续的值不同,T5 模型预测值的范围为 1-5,增量 .2.。这与值为 0 结合产生 21 个值,本质上是 21 类分类问题。
最后的思考
尽管在较大的数据集上训练的较大模型可以继续提高某些标准 NLP 任务的性能,但从大型语料库上进行预训练中提取的通用知识似乎仍无法使得诸如 Winograd Schema 挑战(WSC)之类的任务的性能接近人类水平(100%)。看起来,至少有两种不同的方法可以解决此问题。
-
继续扩大 T5 论文和其他相关工作所提出方法的规模或增加训练方法,例如通过不使用替代 tokens(由生成器网络输出)来更改当前的 masking words 预训练程序,并由鉴别器来预测 replacement。但所有这些方法仍然只在词的空间进行预测学习。
-
尝试完全不同的预测下一个 token 的方法,不是在单词的空间中,而是在抽象表示的变换空间中。这项早期研究强调了现有预测模型词空间上面临的很多挑战,如需要大量的训练数据(样本无效),不能做 WSC 等任务所要求的常识和因果推理。在抽象空间进行预测的目标与词空间相反(或图像-像素空间),这样做该模型可以学习基本的因果变量,除了推理之外,这些因果变量还可以适应基本分布的变化(因果结构仍然保持不变),只需要很少的新训练样本即可,这是迁移学习的关键目标之一。
参考链接:
https://medium.com/@ajitrajasekharan/t5-a-model-that-explores-the-limits-of-transfer-learning-fb29844890b7
(*本文为AI科技大本营翻译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
11.11惠不可挡!
BDTC 2019双十一豪礼大放送,凡11.11当天购买大会“单人票”,即可额外获得价值298元CSDN VIP年卡!(VIP年卡特权:全站免广告+600个资源免积分下载+学院千门课程免费看+购课9折)~
扫描下图二维码或点击阅读原文,领取你的VIP吧!
推荐阅读
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/348497
推荐阅读

相关标签

