
- 1maven项目创建可执行jar的6种方法_mvn命令构建jar包
- 2CMake与vs的配置对应(常规->附加包含目录,链接器->输入)_cmake如何对应到vs链接器输入中.lib
- 3【opencv】教程代码 —ImgProc (10)图像平滑处理
- 49. 什么是 SAP ABAP 为 Fiori 专门设计的编程模型(Programming Model)_abapfiori开发模式有哪些
- 5ChatGPT丨使用tiktoken计算tokens
- 6计算机领域国际会议分区表_sdm24是什么会议
- 7论文笔记:ShuffleNet v1_shufflenetv1论文
- 8postcss的安装与使用
- 9Could not allocate CursorWindow size due to error -12 错误解决方法
- 10incredbuild,msbuild 命令行调用实现自动化编译_incredibuild命令行
【EMNLP2021】Evaluating the Robustness of Neural Language Models to Input Perturbations_interpreting the robustness of neural nlp models t
赞
踩
【EMNLP2021】Evaluating the Robustness of Neural Language Models to Input Perturbations
原文链接:https://arxiv.org/abs/2108.12237
扰动方法是使用NLTK库在Python中实现的。源码链接:https://github.com/mmoradi-iut/NLP-perturbation
intro
BERT/XLNet/GPT-2性能很好,在很多NLP任务上达到了SOTA,甚至超过了人类表现。 但是在benchmark上表现好,和现实的实际工作间存在差距,即使模型训练的很好,也对微小的输入变化很敏感,导致模型输出错误决策。
在本文中,作者设计并实现了一系列(非对抗性扰动)对文本输入的字符级和词级系统扰动(对应TextFlint中的Transformation),以模拟NLP系统在现实世界用例中可能面临的不同类型的噪声。在不同的自然语言处理任务上进行了大量的实验,考察了四种神经语言模型的能力。
Bert、Roberta、XLNet和Elmo在处理稍有扰动的输入时所做的工作。结果表明,神经模型对人类容易处理的微小变化(如拼写错误、遗漏单词、重复单词、同义词等)不稳定,性能下降。
系统的输入扰动可以暴露NLP系统的漏洞,并使人们更深入地了解高性能模型在遇到噪声但可以理解的输入时的行为。这项研究表明,评估NLP系统鲁棒性时,仅仅依赖于基准数据集上获得的准确度分数可能过于简单。
按作者意思,本文是第一个用一套全面的非对抗性扰动方法测试非合成文本上自然语言处理系统稳健性的实验结果。这项工作的一个重要贡献是评估了几种高性能语言模型在使用不同类型的字符级和词级输入扰动的各种NLP任务上的稳健性。此外,为了确定扰动的有用性(即,如何有效地使用它们来自动生成有意义且可理解的扰动样本),作者还进行了广泛的用户调研。
task&dataset
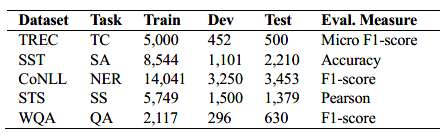
TREC文本分类数据集,包含超过6000个问题,50多个指定问题分类标签。
SST情感分析数据集,包含超过11000条来自“烂番茄”的影评,被分为5类:very positive, positive,neutral, negative, very negative
CoNLL-2003 NER数据集,包含路透社的新闻故事,超过200K tokens被标注为Person, Organization, Location,Miscellaneous, or Other
STS 语义相似度数据集,超过8K个文本对,来自图像标题,新闻标题,用户论坛。每对都被分配了0-5的相似度分数
WikiQA QA数据集,超过3000个问题和29000句子(从wiki百科提取作为答案)组成。
Perturbation methods
作者设计并实现了各种字符级和词级的扰动方法,来模拟NLP系统在现实世界中可能遇到的不同类型的噪声。下图为扰动方法示例。
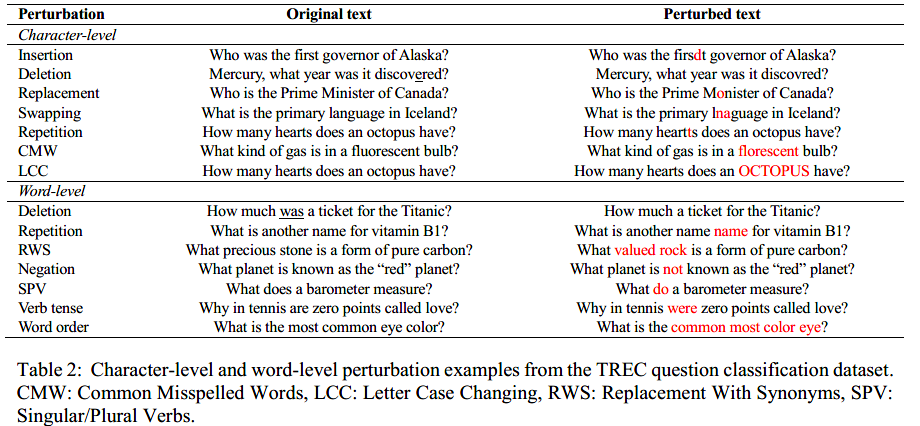
这里提出的几乎所有字符级扰动,之前的研究都已经在对抗性攻击场景中进行了测试,但除了Checklist实现的拼写错误扰动外,还没有在非对抗性测试框架中实现。
4.1字符级扰动
以下扰动方法随机选择一个单词Wordi扰动。
Insertion 如果Wordi包含至少3个字符,随机选择一个字符插入随机位置(第一个和最后一个位置除外)
Deletion 如果Wordi包含至少3个字符,随机选择并删除一个字符(第一个和最后一个字符除外)
Replacement 随机选择一个字符,并将其替换为键盘上的相邻字符。
Swapping 随机选择一个字符,并将其与Wordi中相邻的右字符或左字符交换。
Repetition 选择随机位置(第一个和最后一个位置除外)中的字符,并在所选字符后面插入该字符的复制
Common misspelled words 如果输入文本中的某个单词出现在常见拼写错误单词的维基百科语料库中,它将被替换为其拼写错误
Letter case changing 字母大小写转换。字母大小写的更改是针对Wordi的第一个或所有字符进行的。字母大小写改变的类型是以随机方式指定的。
4.2词级扰动
Deletion 随机选择一个单词删除
Repetition 随机选择一个单词,在它后面插入一个它的复制
Replacement with synonyms 用从WordNet词法数据库中提取的同义词替换示例中包含的单词
Negation 识别动词后,改为否定,或将否定改为肯定
Singular/plural verbs 动词的单复数形式的变换(does–do)
Word order 它从样本中随机选择M个连续单词,并更改它们在文本中的出现顺序。
Verb tense 动词时态变换
实验
所有实验都是在一台计算机上进行,该计算机配置Intel Core i5-9600K CPU(3.70 GHz)、32 GB RAM和GeForce RTX 2080Ti显卡(GPU)以及11 GB专用内存。
扰动方法在CPU上运行;在训练集上进行微调,在测试集和扰动样本上进行评估在GPU上运行。
语言模型
作者分别将每种字符级扰动方法应用于数据集中的所有测试样本,并使用所有产生的扰动样本来评估语言模型的鲁棒性。Perturbation Per Sample(PPS)超参数指定了样本中的最大扰动次数
作者监测并过滤了三个可能改变文本意义的词级扰动引起的扰动样本。这些扰动是删除、否定和替换同义词,对于通过这三种方法改变了含义的每个样本,并且需要更改测试集标签以保持一致性,如果适用,我们更改了标签。如果不能为受干扰的样本分配适当的标签,或者产生的文本不再有意义,我们会将该样本排除在评估之外。由于监控和过滤每个扰动样本非常耗时(因此平均需要大约一分钟来检查扰动样本的意义及其与测试集标签的一致性),我们更正了标签并过滤了扰动样本以上三种方法,直到每个数据集收集200个样本;然后我们使用这些样本来评估模型。我们对我们试验的所有 PPS 值(即 [1, 4] 范围内的值)进行了扰动样本的手动管理。
下面2个图中PPS=1,结果表明,语言模型对扰动很敏感,当输入稍微嘈杂时,它们的性能会下降。然而,RoBERTa 仍然比其他模型表现更好,而 ELMo 总体上获得最低分。结果表明,某些语言模型可以比其他模型更有效地处理特定类型的扰动。 ELMo 获得比 BERT 更高的分数,甚至在某些字符级扰动上的表现与 XLNet 和 RoBERTa 相当。这可能是由于其纯粹的基于字符的表示,使模型能够使用形态线索,从而产生更强大的模型来对抗字符级噪声。
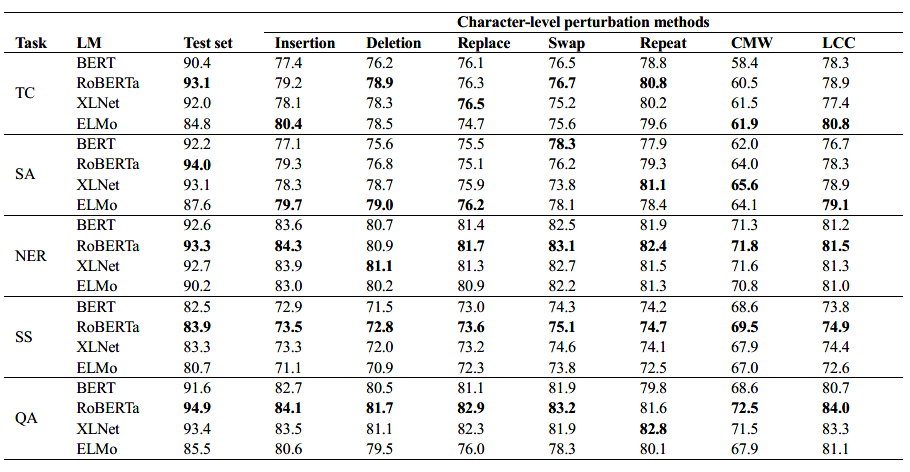

XLNet 显示出比其他方法更有效地处理词序扰动。这可能是置换语言建模的结果,当某些上下文词以不同的顺序出现时,它可以允许模型仍然捕获上下文并更准确地执行。结果还表明,当单词被同义词替换时,那些在更大的语料库(如 RoBERTa 和 XLNet)上预训练的模型更具有鲁棒性。此外,当否定扰动对部分任务有更大的影响时,例如情感分析,与其他任务相比,模型稳定性较差,处理噪声的效率较低。观察结果,我们还可以指出基于 LSTM 的模型,即 ELMo,比基于 Transformer 的模型对样本中单词的顺序更敏感。
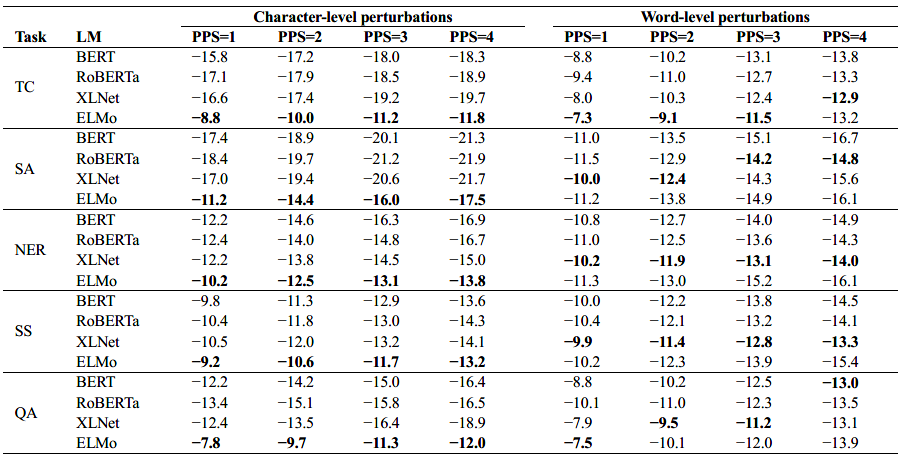
下图给出了PPS在1-4范围是语言模型性能的绝对下降。结果表明,这些模型对字符级的扰动更加敏感。受到扰动后,模型更容易在情感分析任务产生错误输出,问答任务受到噪声影响较小。
下图是6个示例,输入扰动让Roberta模型做出错误的判断(模型在原始输入做出正确的输出)。可以看出,示例1-3包含轻微的字符级噪声,这会导致模型做出错误的决定,但是,受干扰的文本似乎仍然可以理解。在示例4中,“Diameter”替换为“diam”,“Golf”替换为“Golf_GAME”,但模型无法处理这些更改。在示例5中,两个重复词导致模型估计出较低的相似度得分,但语义保持不变。
最后,示例6展示了删除单个单词如何导致模型选择错误的答案。

用户调研
作者将扰动后的文本对20名参与者进行研究,看这些文本人类的理解程度。
在研究的第一部分,每个参与者都被给予了30个扰动的样本,这些样本来自那些预计不会改变文本对于NLP任务的意义的扰动方法。这些都是字符级的扰动和三个词级的扰动,即重复、单复数动词和动词时态。研究人员还向参与者提供了原文和每个被扰乱的样本,并要求他们判断被扰乱的文本是否可以理解,以及是否仍然传达同样的意思。每个样本包含一个、两个或三个扰动。根据用户的评价,平均而言,94%的受扰样本是可以理解的,并且仍然传达了与原文相同的意思。
在研究的第二部分,每个参与者都得到了20个来自那些可能改变文本意义或导致无意义文本的扰动方法的扰动样本。它们是词级扰动的其余部分,即删除、同义词替换、否定和词序。参与者还被给予原始文本和每个被干扰的样本,并被要求判断(关于手头的任务)被干扰的文本是否仍然有意义并且与测试集标签一致。根据用户评估,平均而言,该集合中39%的扰动样本仍然有意义并且与标签一致,12%的扰动样本是有意义的,但标签应该改变,49%的扰动样本不再有意义。这些结果意味着需要监视、纠正或过滤某些干扰,以确保它们是可理解的、有意义的,并且与测试集标签一致。这有助于合理估计NLP系统对输入扰动的鲁棒性。

