
- 1C语言 C++ Web框架_c++ web开发框架
- 2docker搭建
- 3dolphinscheduler 2.0.6 资源中心改造方案一:通过SFTP下载文件_dolphinscheduler 支持ftp吗
- 4公开 学生课堂行为数据集 SCB-Dataset Student Classroom Behavior dataset_学生课堂数据集
- 5使用dva和ant-design组件在IE中的兼容问题记录
- 6鸿蒙操作系统如何打通 Windows 操作系统?
- 7微软 CEO Satya Nadella 的访谈
- 8Git高级操作之rebase
- 9HNU-计算机系统-讨论课1_讨论在不同的环境下(不同的操作系统、不同的编译器、不同的指令集架构等),这
- 10用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程_rag流程
【原创】理解ChatGPT之Transformer工作原理_transformer block
赞
踩

作者:黑夜路人
时间:2023年4月26日
想要连贯学习本内容请阅读之前文章:
【原创】理解ChatGPT之注意力机制和Transformer入门
【原创】理解ChatGPT之GPT工作原理
【原创】理解ChatGPT之机器学习入门
【原创】AIGC之 ChatGPT 高级使用技巧
Transformer中的注意力机制
Transformer是一种基于注意力机制的神经网络模型,它在自然语言处理领域中表现出色。Transformer中的注意力机制是一种非常重要的技术,它可以让模型更加聚焦于重要的信息,从而提高模型的准确性和效率。Transformer模型利用注意力机制来捕捉输入序列中每个位置的上下文信息,这比传统的循环神经网络和卷积神经网络更高效和直观。
Transformer中的注意力机制可以分为以下几个步骤:
1. 计算注意力权重:通过计算查询向量和键向量之间的相似度,得到每个键向量对应的注意力权重。
2. 加权求和:将每个值向量乘以对应的注意力权重,再求和得到最终的输出向量。
3. 多头注意力:为了更好地捕捉多个方面的信息,Transformer中使用了多头注意力机制。给不同的注意力机制分配不同的查询、键和值,并对其输出的结果进行组合,这可以让模型学习不同类型的依赖关系。
Transformer相比于传统的神经网络模型,注意力机制具有以下优势:
- 可以更好地处理长序列数据,避免信息丢失。
- 可以更好地捕捉输入序列中的关键信息,提高模型的准确性。
Transformer模型除了注意力机制其他设计思想:
1. Position-wise Feed-Forward Networks:每一个注意力层后使用的是简单的前馈神经网络,这可以增加Transformer模型的神经网络容量,并且也不涉及序列中不同位置之间的依赖,所以是并行计算的。
2. Layer Normalization:在每一层的输入进行层归一化处理,可以加速模型收敛,并且让模型对初始值不太敏感。
3. Residual Connection:注意力层和前馈层的输出通过残差连接相加,然后再进行转换,这可以更快的训练 Transformer 模型。
4. 可学习的位置编码:Transformer模型在编码器和解码器中输入的序列通过可学习的位置编码进行增强,这可以让模型更好的利用序列的顺序信息。
Transformer模型的设计思想是利用注意力机制来建模输入序列的全局依赖关系,并用残差连接、位置编码等方法提高模型的训练速度和性能,这使其在多种自然语言处理任务上取得了最先进的结果。
Transformer 的组成部分
Transformer 模型是一种基于自注意力机制的深度神经网络模型,其主要设计思想是通过自注意力机制来捕捉输入序列中的相关性,从而实现对序列的建模和处理。相比于传统的循环神经网络和卷积神经网络,Transformer 模型不需要考虑序列的顺序信息,可以并行计算,因此在处理长序列时具有更好的效率和表现。Transformer 模型主要由编码器和解码器两部分组成,其中编码器用于将输入序列转换为一系列抽象的特征表示,解码器则用于根据这些特征表示生成目标序列。Transformer 模型的主要创新点在于引入了多头自注意力机制和残差连接,使得模型可以更好地处理长序列和复杂的语言结构。
概要来说,Transformer中的注意力机制(Attention Mechanism)是用于处理序列数据的一种新的机器学习技术,与传统的机器学习方法有很大的不同。传统的机器学习方法,例如决策树和分类器,主要通过对输入数据进行特征提取来实现分类和预测,而注意力机制则通过对输入序列进行全局加权求和来实现序列数据的建模。
在Transformer中,注意力机制被用于对输入序列进行建模。它的核心思想是将输入序列表示为一组向量,然后对每个向量进行加权求和,最后得到序列的表示。在计算加权求和时,注意力机制会计算出每个序列向量与当前输入序列向量之间的相似度,然后将相似度向量添加到序列向量的表示中。这样,序列的表示就可以被表示为一组向量,每个向量都与当前输入序列向量相关联,同时也可以用于预测和分类。
与传统的机器学习方法相比,Transformer的注意力机制可以更好地处理序列数据,并用于文本生成、机器翻译等任务。同时,由于Transformer中的注意力机制是基于计算图实现的,因此可以与递归神经网络(RNN)等其他技术相结合,用于实现更加复杂的模型。
关于一下Transformer具体描述的内容可能会比较晦涩,有些内容可以跳过,如果上面内容读懂,了解了大概原理就可以。
我们主要看一下Transformer 框架的整个架构图:
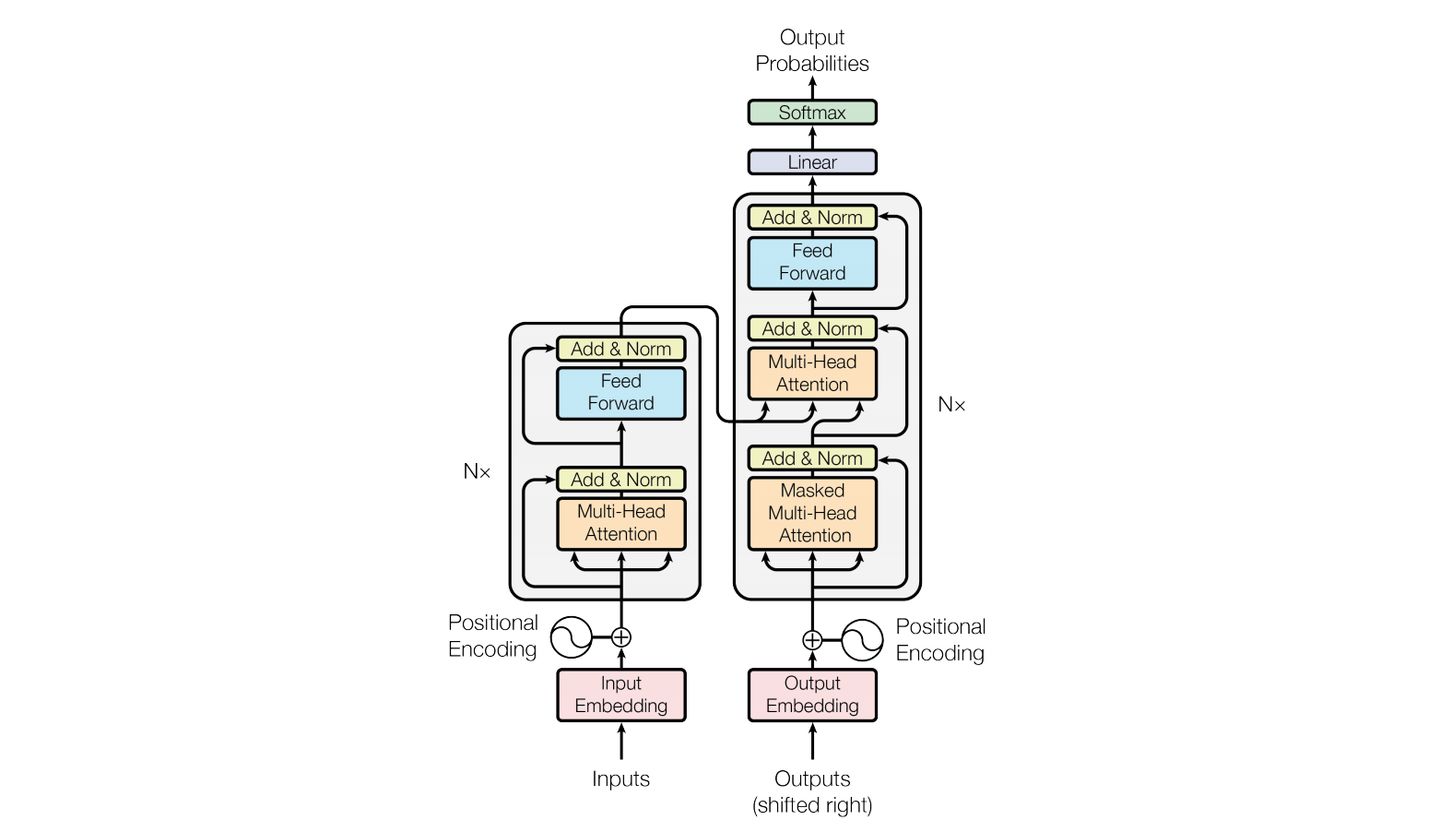
整个架构图看起来有点复杂,里面核心就是展示了 Encoder-Decoder(编码器-解码器)的主要工作内部机制。
对于GPT来说,能够让一个回复非常准确有效,最核心的就是在文本训练的时候整个“注意力机制”,保证了整个词与词之间的计算更能够知道谁跟谁关系度最紧密,才知道每次生成文本的时候都是挑选相关性最好的文本生成。
从上面整个Transformer模型中核心主要就是用一个 Encoder - Decoder 的主链路,其中Encoder和Decode核心基本都是类似的,所以,为了方便理解,我们核心看看Encoder部分:

上面整个架构图,我们可以把这些部分简单拆解为:
- Inputs - 输入分词层(Tokenize)
- Input Token Embedding - 输入词向量嵌入化(Word Embedding)
- Transformer Block - 中间Encoder层可以简单把这个盒子理解为一个Block
- 整个 Transformer Block中可以在分解为四层:
- self-attention layer - 自注意力计算层
- normalization layer - 归一化层
- feed forward layer - 前馈层
- another normalization layer - 另一个归一化层
Transformer 的输入层
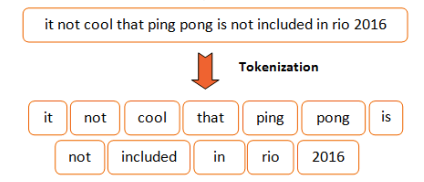
Inputs 层
主要处理可以认为就是Tokenize,把文字进行切分成为token:
Input Token Embedding层
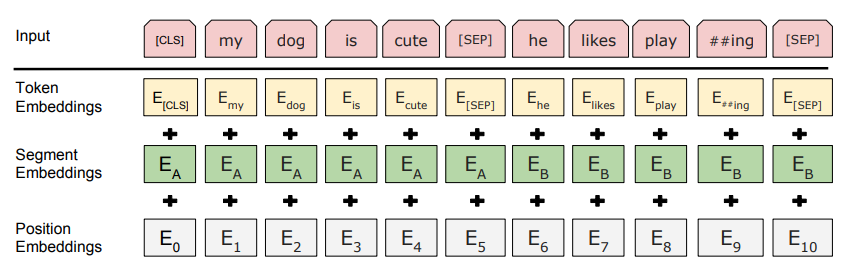
Token Embedding中的embedding 一般是指将一个内容实体映射为低维向量,从而可以获得内容之间的相似度。OpenAI 提供的 embedding 是计算文本与维度的相关性,默认的 ada-002 模型会将文本解析为 1536 个维度。用户可以通过文本之间的 embedding 计算相似度。embedding 的使用场景是可以根据用户提供的语料片段与 prompt 内容计算相关度,然后将最相关的语料片段作为上下文放到 prompt 中,以提高 completion 的准确率。Embedding有很多库,比如传统的word2vec和新一点的FastText、GIoVe等等。

除了上面两部分,其实还有就是位置信息,因为位置信息会觉得相关性,所以在输入处理,还会包含 Position Embedding 这部分,就是把位置信息页进行嵌入处理,所以在进入Encoder之前会有这么几层:
Transformer Block 层(Encoder部分)
Transformer Block架构图

整个可以理解为主要就是Encoder的环节,这里面主要的环节包括:
绿色的输入的是两个单词的embedding。这个模块想要做的事情就是想把x转换为另外一个向量r ,这两个向量的维度是一样的。然后就一层层往上传。
第一个步骤就是Self-Attention,第二个步骤就是普通的全连接神经网络。第一个步骤就是Self-Attention,第二个步骤就是普通的全连接神经网络。
Self-Attention 自注意力计算
Self-Attention就是一个句子内的单词,互相看其他单词对自己的影响力有多大。比如单词it,它和句子内其他单词最相关的是哪个,如果颜色的深浅来表示影响力的强弱,那显然我们看到对it影响力最强的就是The和Animal这两个单词了。所以Self-Attention就是说,句子内各单词的注意力,应该关注在该句子内其他单词中的哪些单词上。

Attention和Self-Attention的区别
以Encoder-Decoder框架为例,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention发生在Target的元素Query和Source中的所有元素之间。
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
两者具体计算过程是一样的,只是计算对象发生了变化而已。
Self-Attention 计算过程
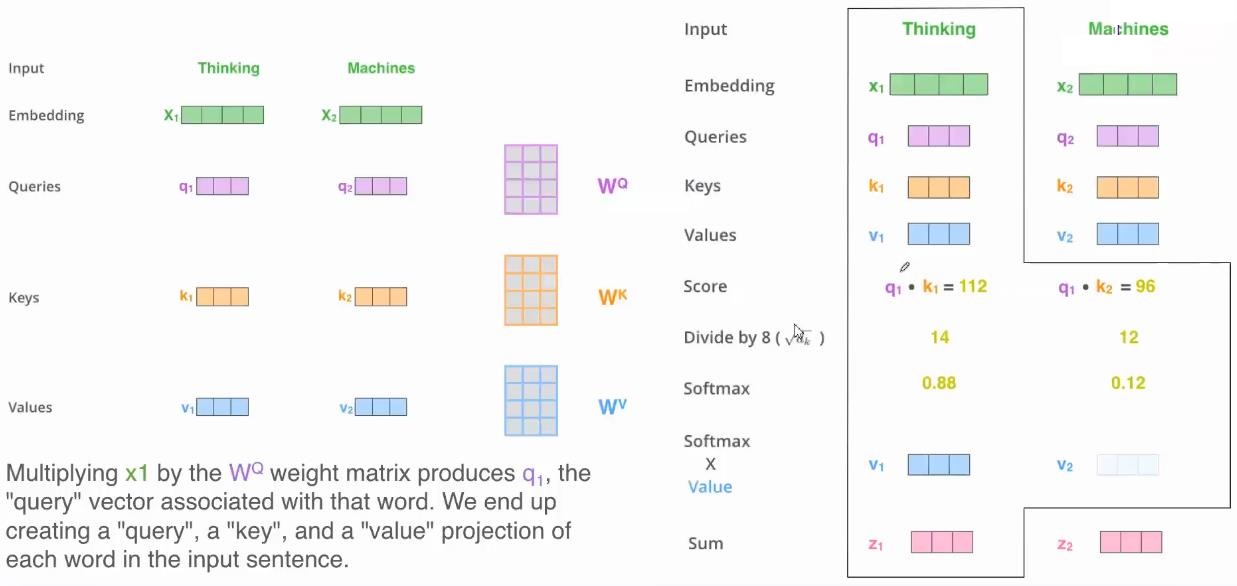
上面整个链路是从input输入到后面的整个计算过程,可以注意到,上述过程中,不同的x分享了同一个Q、K、V,通过这个操作,x1和x2和已经发生了某种程度上的信息交换。也就是说,单词和单词之间,通过共享权值,已经相互发生了信息的交换。通过上述的整个流程,就可以把输入的x1和x2转换成了z1和z2。这就是Self-Attention机制。有了z1和z2,再通过全连接层,就能输出该Encoder层的输出r1和r2。
讲到这里,你肯定很困惑为什么要有Q、K、V向量,因为这个思路来自于比较早的信息检索领域,Q就是query,K就是key,V就是值,(k,v)就是键值对、也就是用query关键词去找到最相关的检索结果。
举个例子,假设query是5G,然后k-v键值对有:
k-v: 5G : Huawei
k-v: 4G : Nokia
那query(5G)和key(5G)的相关性是100%,和key(4G)的相关性是50%。这就是为什么用query,key,value这种概念。
为了得到query,key,value,一个就得做3次乘法,那n个x就得做3n次乘法。为了比较高效的实现矩阵乘法,要进行类似matlab中的向量化操作,因为因为GPU中矩阵运算的复杂度是O(1)不是O(N^2)。如果我们能把上面的操作变为矩阵操作,那我们就能很好的利用GPU做并行计算。具体的矩阵操作公式表示:
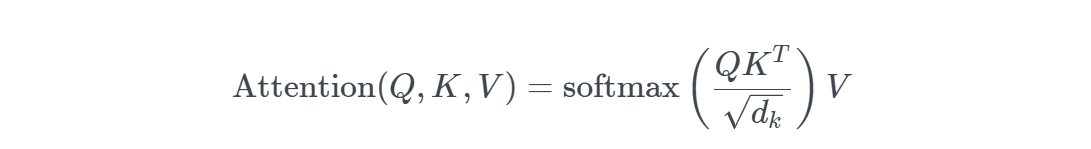
为什么这里要用矩阵而不是神经网络呢?因为矩阵运算能用GPU加速,会更快,同时参数量更少,更节省空间。
Multi-headed Attention 多头注意力
先看多头注意力(Mulit-head self-attentio)计算全整个链路:
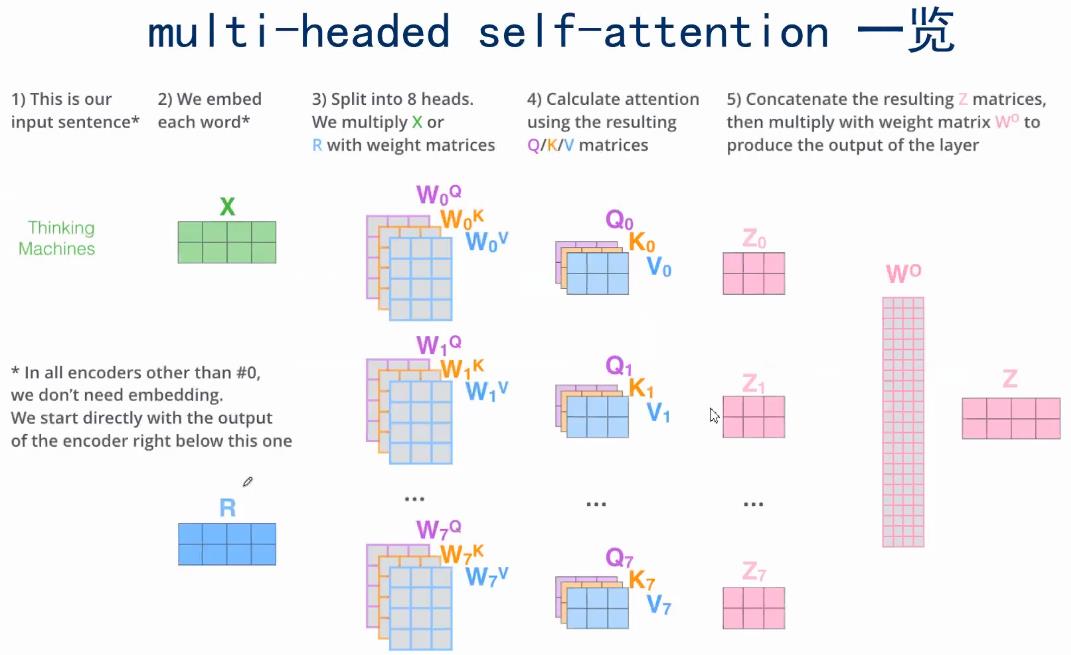
multi-headed Attention就是指用了很多个不同的 Q、K、V,那这样的好处是什么呢?可以让Attention有更丰富的层次。有多个Q、K、V的话,可以分别从多个不同角度来看待Attention。这样的话,输入x,对于不同的multi-headed Attention,就会产生不同的z。
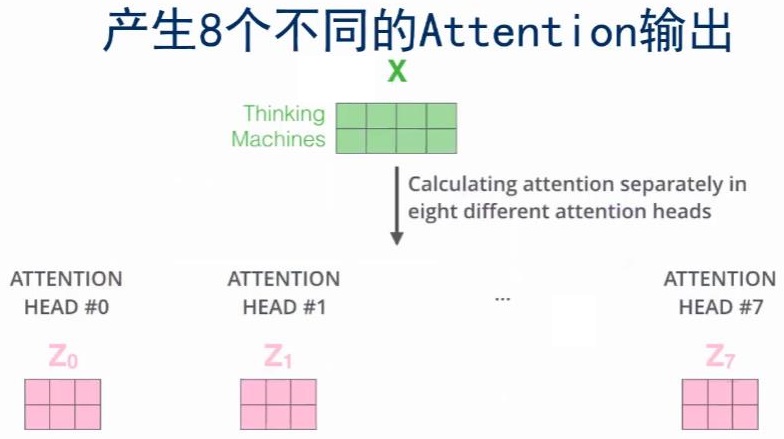
那现在一个x就有了多个版本的z,那该怎么结合为一个呢z?那就将多个版本的拼接称为一个长向量,然后用一个全连接网络,即乘以一个矩阵,就能得到一个短的x向量。

把multi-headed输出的不同的z,组合成最终想要的输出的z,这就是multi-headed Attention要做的一个额外的步骤。
multi-headed Attention用公式表示就是:

skip connection和Layer Normalization
Add & Norm模块接在Encoder端和Decoder端每个子模块的后面,其中Add表示残差连接,Norm表示LayerNorm,残差连接来源于论文Deep Residual Learning for Image Recognition,LayerNorm来源于论文Layer Normalization,因此Encoder端和Decoder端每个子模块实际的输出为:
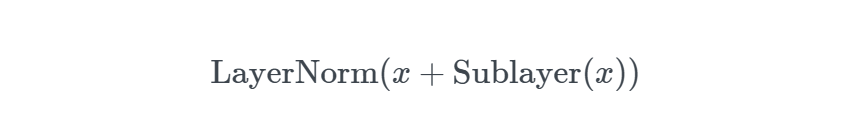
kip connection最早是在计算机视觉的ResNet里面微软亚洲研究院何凯明老师提到的,主要是想解决当网络很深时,误差向后传递会越来越弱,训练就很困难,那如果产生跳跃连接,如果有误差,可以从不同路径传到早期的网络层,这样的话误差就会比较明确地传回来。这就是跳跃层的来历。
跳跃层不是必须的,但在Transformer中,作者建议这样做,在Selft-Attention的前后和每一个Feed Forwar前后都用了跳跃层。在Transformer中,用了Normalize,用的是一种新的Layer Normalize,不是常用的Batch Normalize。是一种正则化的策略,避免网络过拟合。Layer Normalize和Batch Normalize唯一的区别就是不考虑其他数据,只考虑自己,这样就避免了不同batch size的影响。
Layer Normalization的方法可以和Batch Normalization对比着进行理解,因为Batch Normalization不是Transformer中的结构,这里不做详解Layer Normalization的方法可以和Batch Normalization对比着进行理解,因为Batch Normalization不是Transformer中的结构,这里不做详解
Transformer Block(Decoder模块)
Transformer Decoder模块,论文中Decoder也是N=6层堆叠的结构。被分为3个SubLayer,ncoder与Decoder有三大主要的不同:
1.Decoder SubLayer-1使用的是“Masked” Multi-Headed Attention机制,防止为了模型看到要预测的数据,防止泄露。
2.SubLayer-2是一个Encoder-Decoder Multi-head Attention。
3.LinearLayer和SoftmaxLayer作用于SubLayer-3的输出后面,来预测对应的word的probabilities 。
Decoder的Mask-Multi-Head-Attention输入端
模型训练阶段:
Decoder的初始输入:训练集的标签Y,并且需要整体右移(Shifted Right)一位
Shifted Right的原因:T-1时刻需要预测T时刻的输出,所以Decoder的输入需要整体后移一位
举例说明:我爱中国 → I Love China
位置关系:
0-“I”
1-“Love”
2-“China”
操作:整体右移一位(Shifted Right)操作:整体右移一位(Shifted Right)
0-</s>【起始符】目的是为了预测下一个Token
1-“I”
2-“Love”
3-“China”
用简单的动态图来理解Decoder环节:

Transformer Decoder的输入:
初始输入:前一时刻Decoder输入+前一时刻Decoder的预测结果 + Positional Encoding
中间输入:Encoder Embedding
以上这个过程有点难以理解,需要多阅读几遍,然后再参考一些其他资料和代码。在Decoder除了上面这些,中还有几个掩码的机制。
什么是Mask(掩码)
mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer模型里面涉及两种mask,分别是 padding mask和sequence mask。 其中,padding mask在所有的scaled dot-product attention 里面都需要用到,而sequence mask只有在Decoder的Self-Attention里面用到。
Decoder Padding Mask
什么是padding mask呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的Attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过softmax,这些位置的概率就会接近0! 而我们的padding mask 实际上是一个张量,每个值都是一个Boolean,值为false的地方就是我们要进行处理的地方。
Decoder Sequence mask
文章前面也提到,sequence mask是为了使得Decoder不能看见未来的信息。也就是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。 那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
sequence mask的目的是防止Decoder “seeing the future”,就像防止考生偷看考试答案一样。
Decoder的Encode-Decode注意力层
Attention的预测流程和和普通的Encoder-Decoder的模式是一样的,只是用Self-Attention替换了RNN,这里就不展开描述了。

从上图可以看出,Decoder和Encoder唯一的区别就是多了一个Encode-Decode注意力层,然后最后一层接了个linear+softmax层,损失函数就是交叉熵损失。从上图可以看出,Decoder和Encoder唯一的区别就是多了一个Encode-Decode注意力层,然后最后一层接了个linear+softmax层,损失函数就是交叉熵损失。
Decoder的最后一个部分是过一个linear layer将decoder的输出扩展到与vocabulary size一样的维度上。经过softmax 后,选择概率最高的一个word作为预测结果。假设我们有一个已经训练好的网络,在做预测时,步骤如下:
- 给Decoder输入Encoder对整个句子embedding的结果和一个特殊的开始符号 </s>。Decoder 将产生预测,在我们的例子中应该是 ”I”。
- 给Decoder输入Encoder的embedding结果和 </s> I, 在这一步Decoder应该产生预测 am。
- 给Decoder输入Encoder的embedding结果和 </s> I am,在这一步Decoder应该产生预测 a。
- 给Decoder输入Encoder的embedding结果和 </s> I am a,在这一步Decoder应该产生预测student 。
- 给Decoder输入Encoder的embedding结果和 </s> I am a student , Decoder应该生成句子结尾的标记,Decoder 应该输出 </eos>。
- 然后Decoder生成了</eos>,翻译完成。
Transformer 总体工作动态图
经过上面针对Transformer整个各个组件层次的学习,感觉有点迷糊了,中间对于一些细节做了忽略,整个Transformer过程我们通过动图来了解一下全流程。
Encoder通过处理输入序列开启工作。Encoder顶端的输出之后会变转化为一个包含向量
K(键向量)和V(值向量)的注意力向量集 ,这是并行化操作。这些向量将被每个Decoder用于自身的“Encoder-Decoder注意力层”,而这些层可以帮助Decoder关注输入序列哪些位置合适:
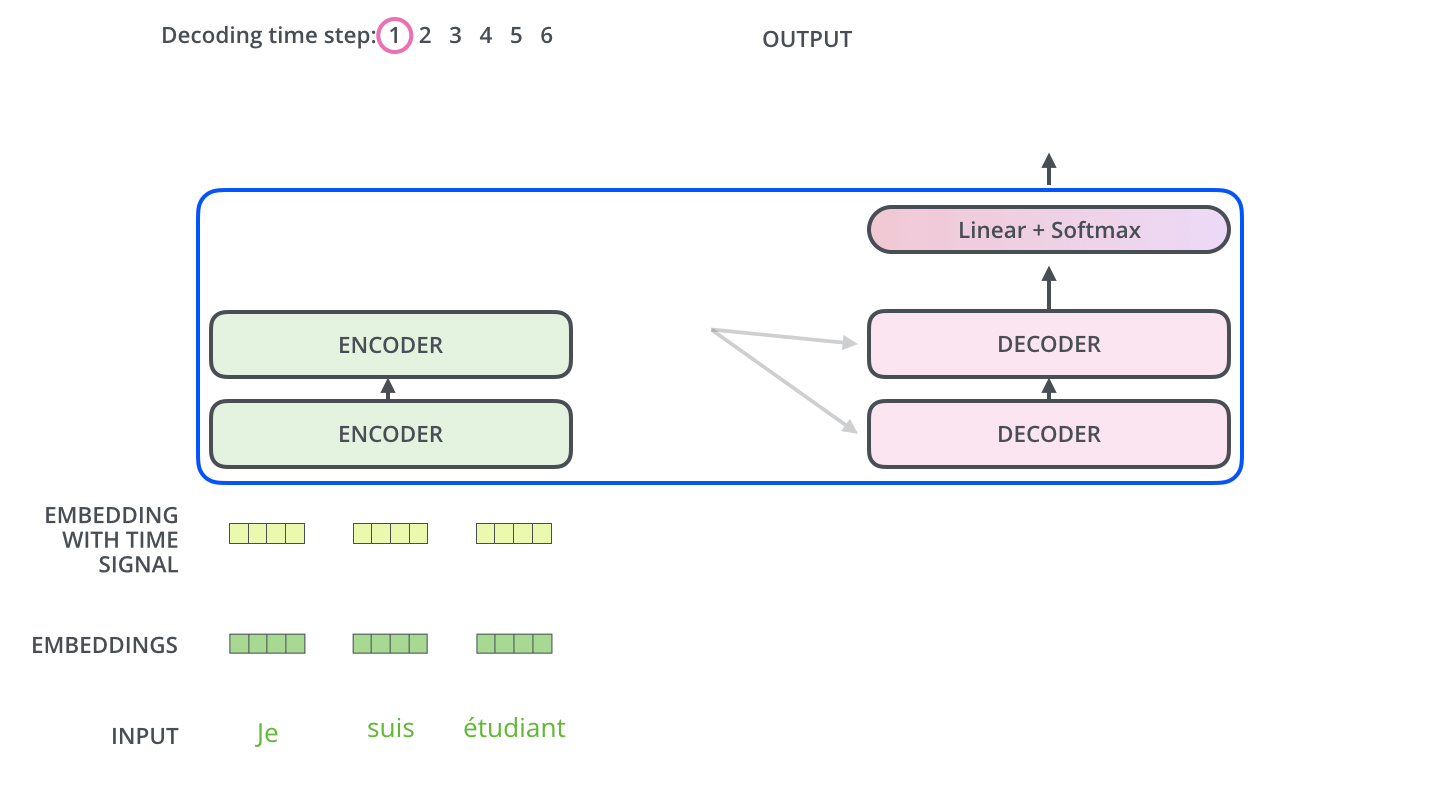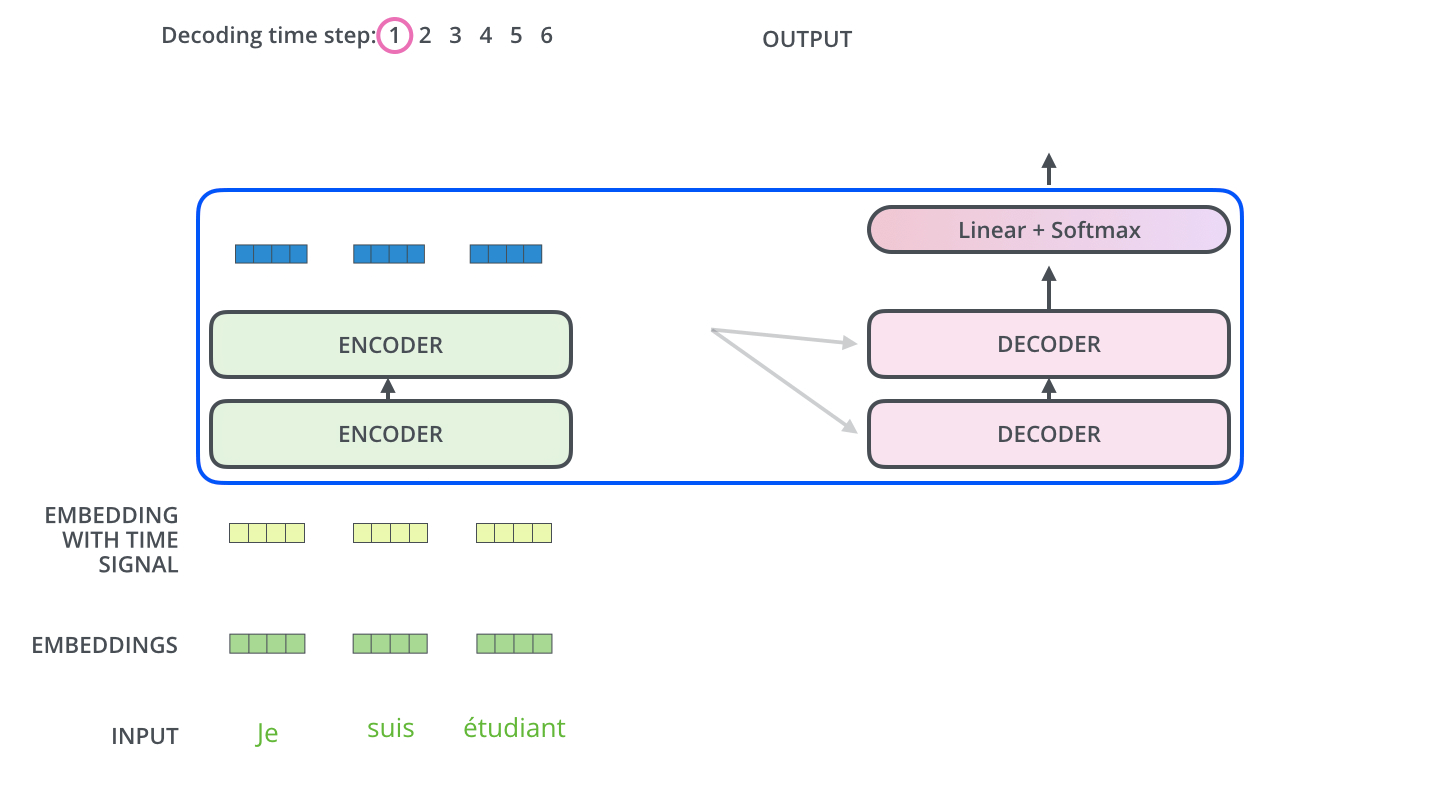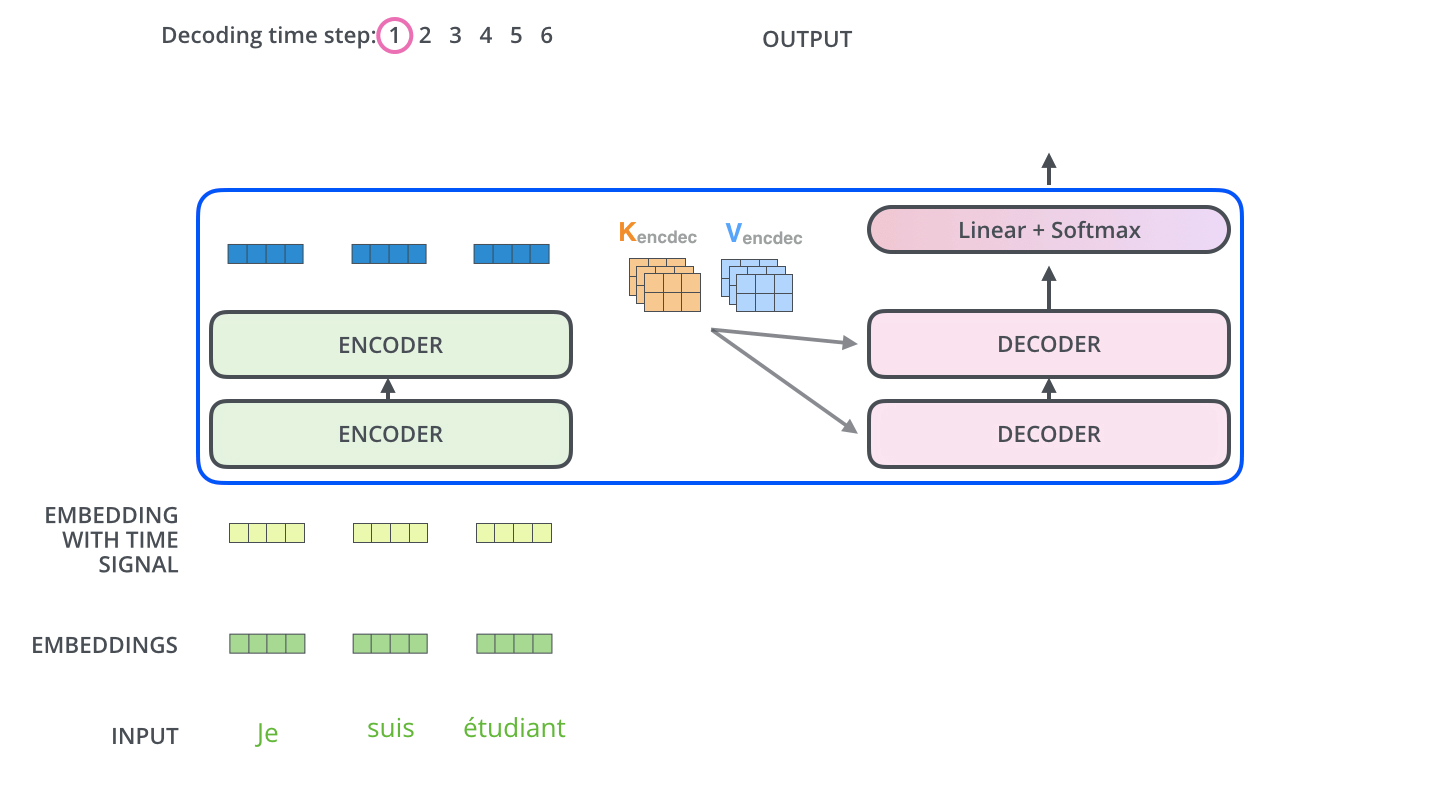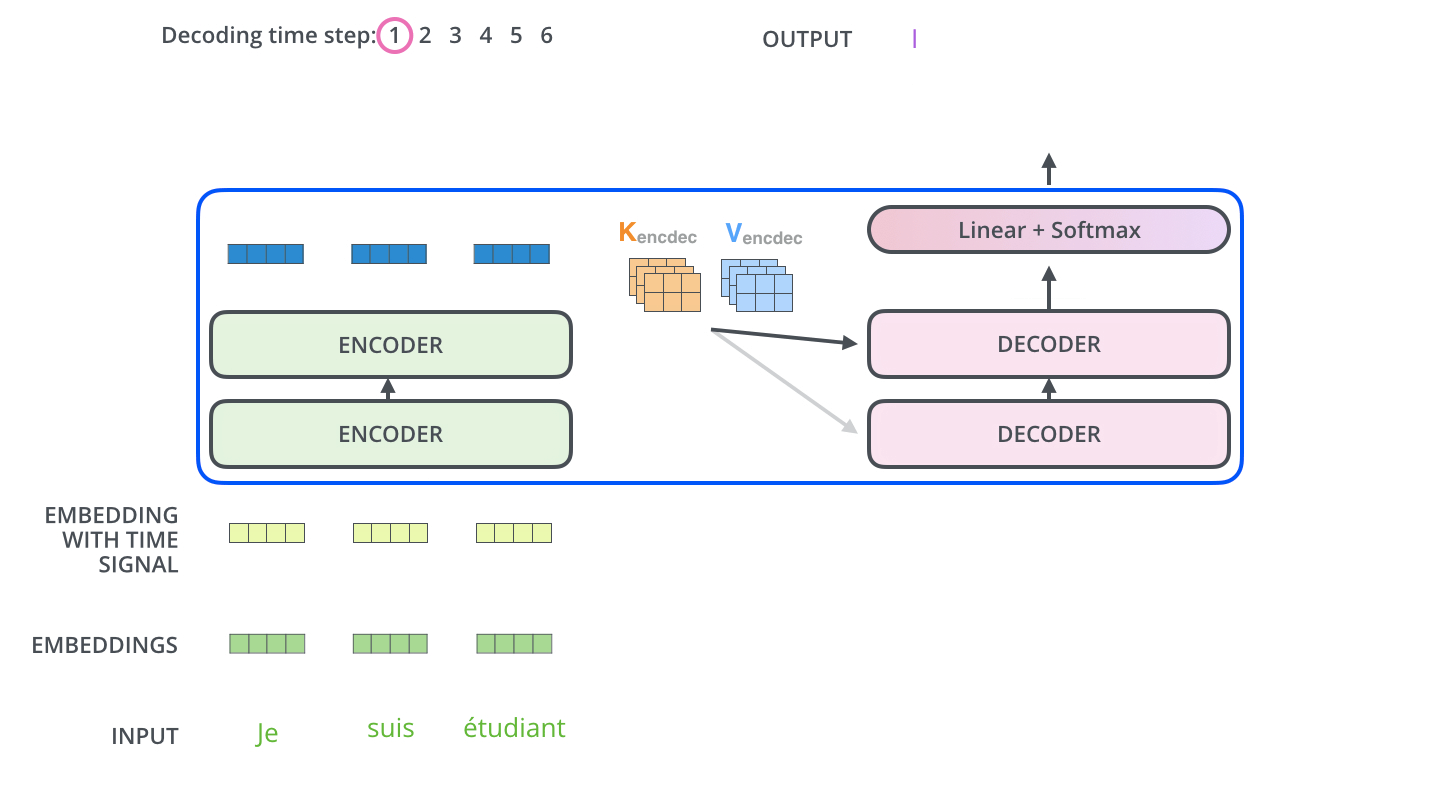
在完成Encoder阶段后,则开始Decoder阶段。Decoder阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示Transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端Decoder,并且就像Encoder之前做的那样,这些Decoder会输出它们的Decoder结果 。在完成Encoder阶段后,则开始Decoder阶段。Decoder阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示Transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端Decoder,并且就像Encoder之前做的那样,这些Decoder会输出它们的Decoder结果 。
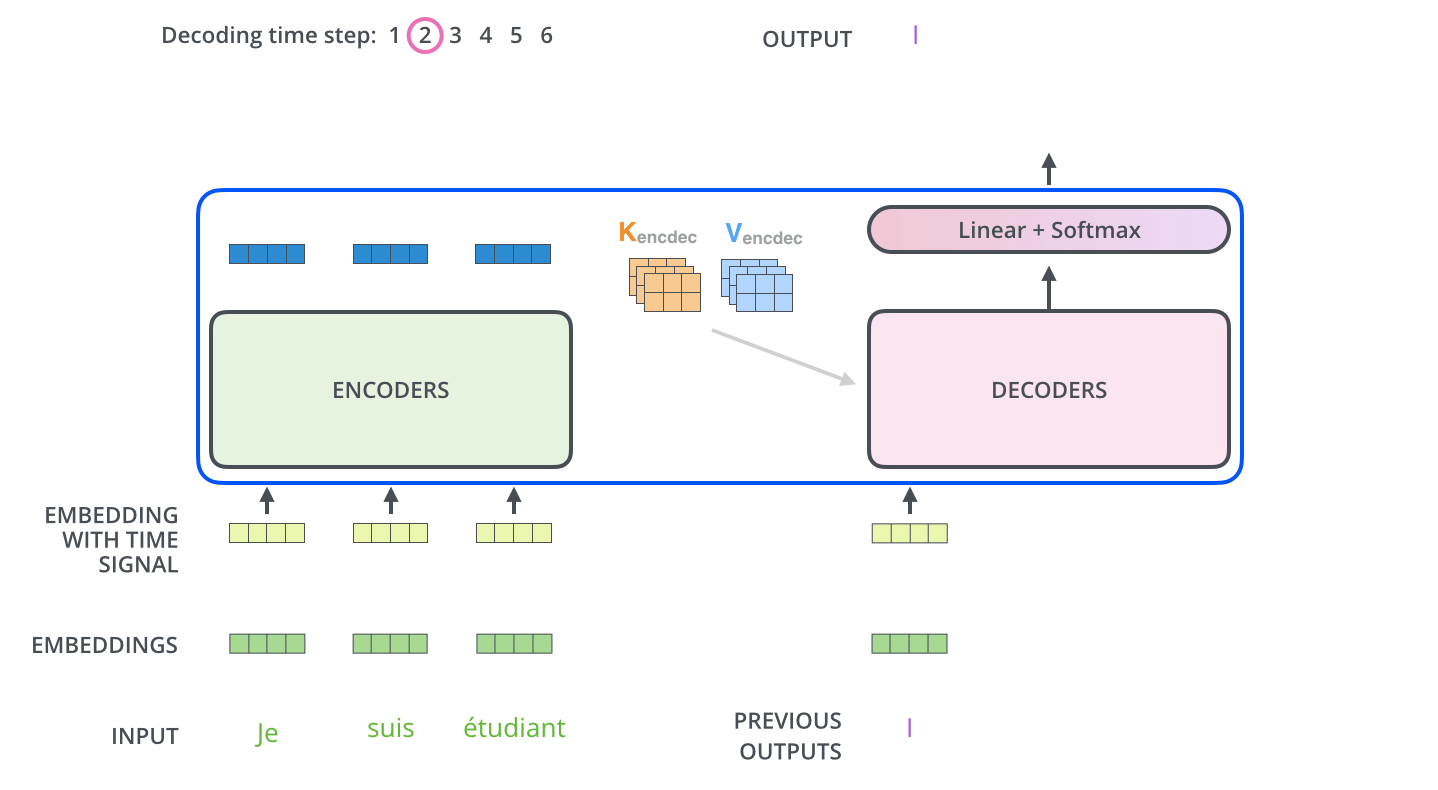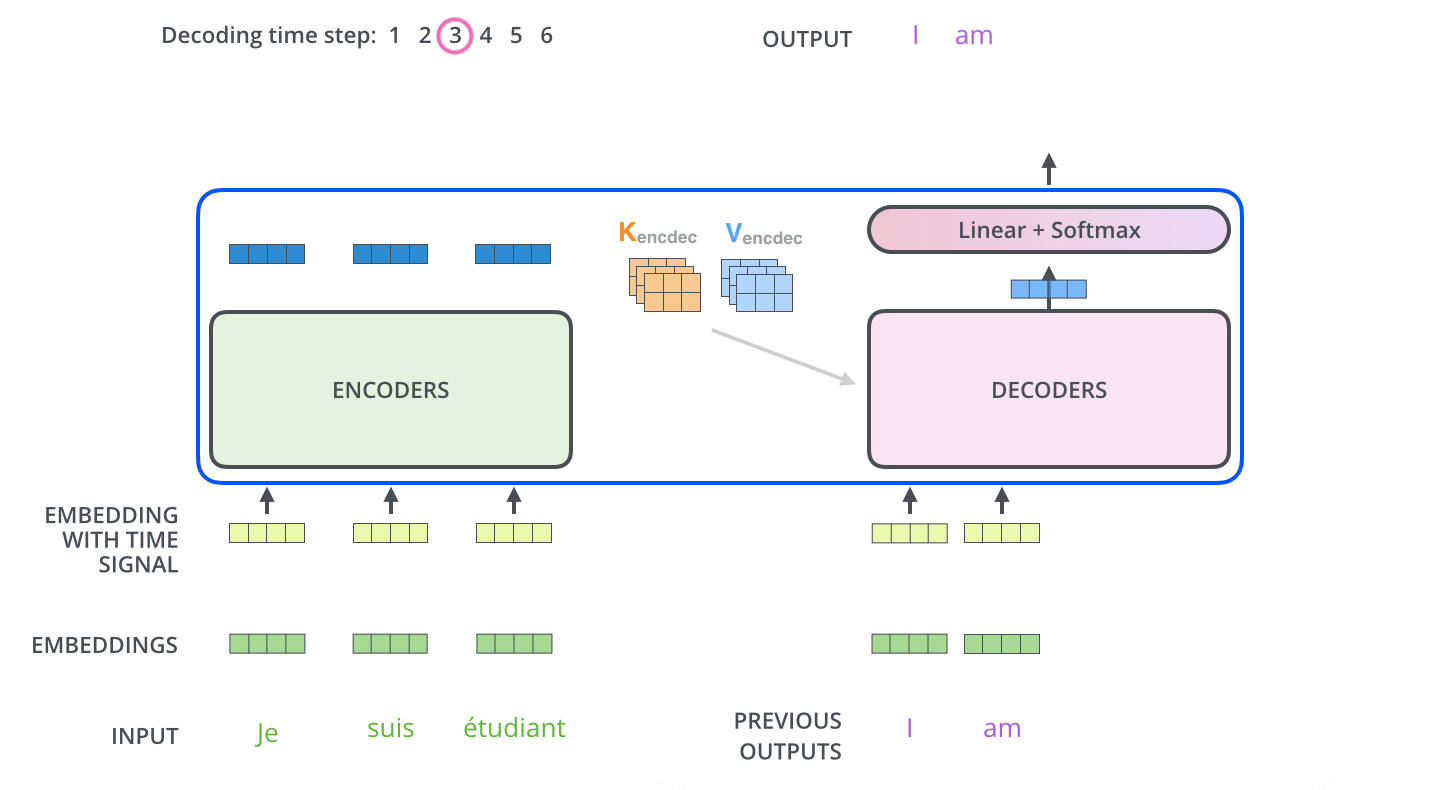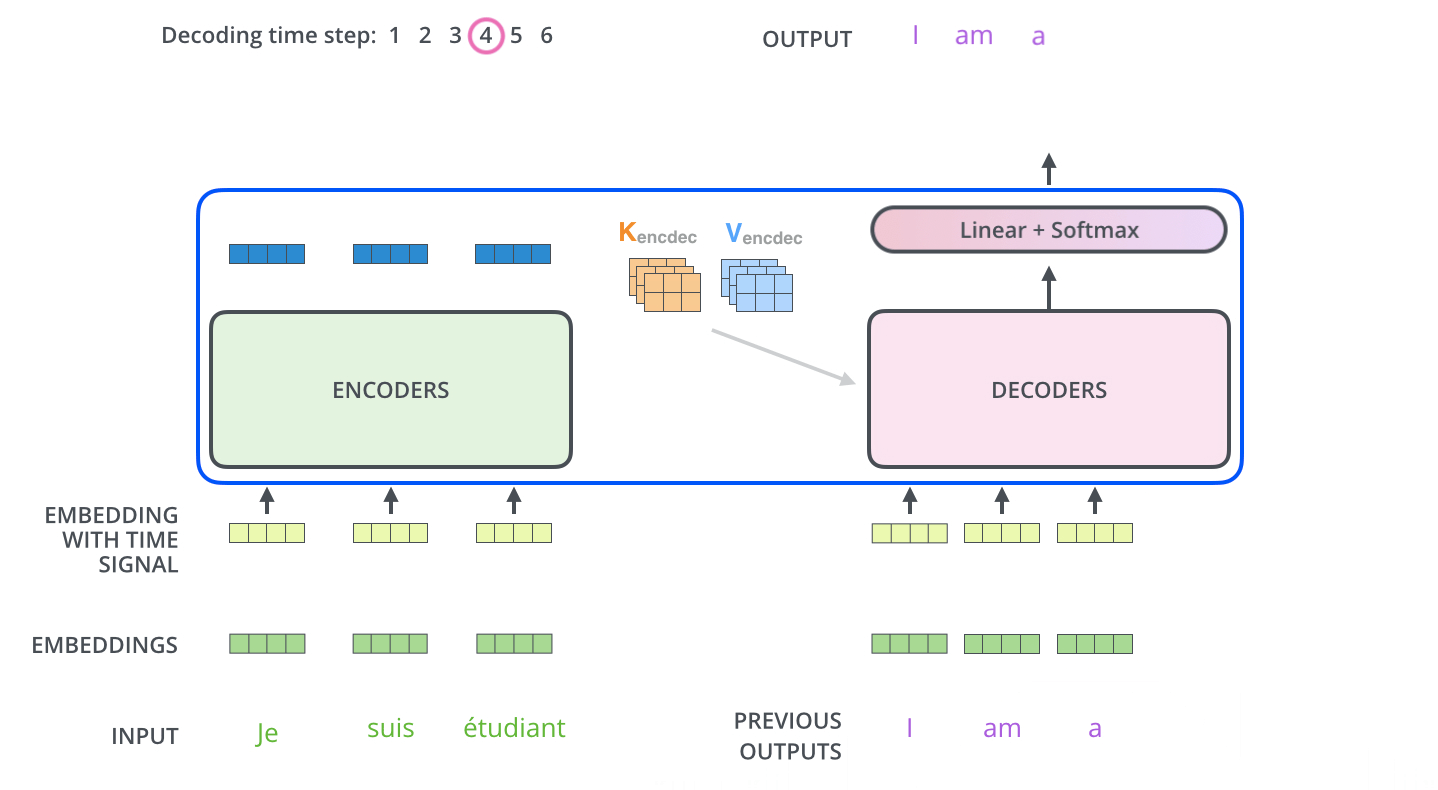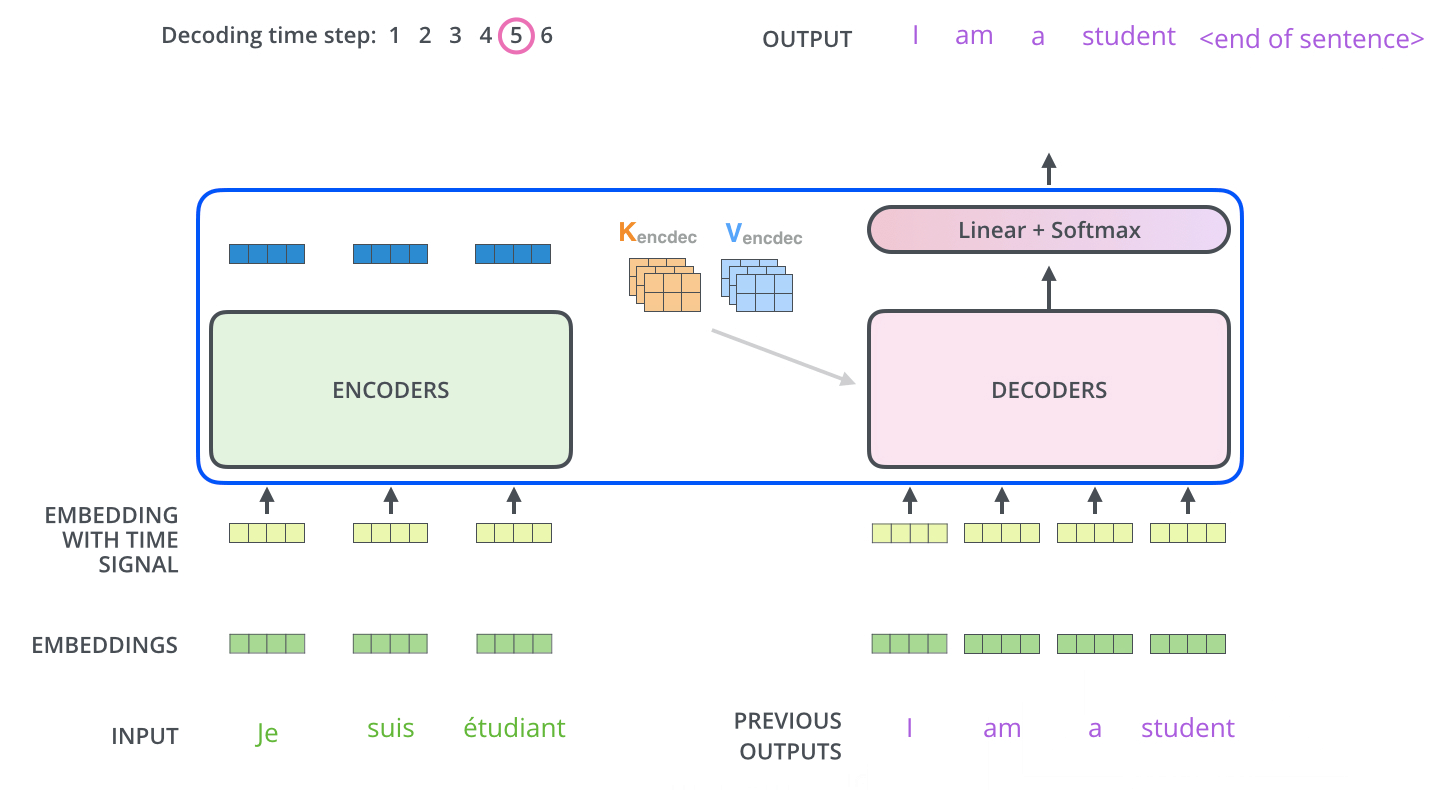
Transformer 总结
上面详细的学习了Transformer 整个核心组成部分和核心工作原理,任何一个模型或者框架不能是十全十美的,就概要梳理一下优缺点。
Transformer模型的主要优点如下:
1. 并行计算。Transformer可以并行计算所有时间步,计算速度很快,这是其相比RNN和LSTM的最大优势。
2. 学习长期依赖。Transformer通过Attention机制可以直接建模任意两个时间步之间的依赖关系,可以很好地学习长期依赖,不容易出现梯度消失问题。
3. 训练更稳定。Transformer的非循环结构使其训练过程更加稳定,不容易出现梯度爆炸问题,参数选择也更加灵活。
4. 参数更少。相比RNN和LSTM,Transformer需要的参数更少,尤其在更长序列的任务中参数量的差距更加明显。
5. 无需标定的输入输出。Transformer无需在序列两端添加特殊的开始和结束标记。
Transformer主要缺点如下:
1. Transformer contains no recurrence. 形式上Transformer没有循环结构,丢失了RNN的一些特征。例如,Transformer无法很好地建模周期时间序列。
2. Transformer可能不适合较短序列。对于较短的序列,Transformer的参数相对较多,并不一定优于RNN和LSTM。
3. 计算复杂度较高。Transformer中的Attention计算成本比较大,在一些计算资源受限的情况下可能会出现瓶颈。
4. 缺乏韵律和时域信息。Transformer不像RNN和LSTM中包含循环结构和隐状态,无法很好地建模时域和韵律信息。
总体来说,Transformer的主要优势在于并行计算、学习长期依赖以及训练稳定性,但也存在一定的缺点,如无循环结构、处理短序列时效果可能不佳、计算复杂度高以及建模时域和韵律信息的能力较弱等。选用什么样的模型还需要根据具体任务的需求和数据特征进行权衡。
但是Transformer在ChatGPT下面大放异彩,也给整个AI的LLM(大语言模型)领域发光发热!
取代你的不是AI,而是比你更了解AI和更会使用AI的人!
##End##
想关注更多技术信息,可以关注"黑夜路人技术” 公众号,后台发送“加群”,加入GPT和AI技术交流群

