
- 1Git常见问题记录:Git 管理代码开发中敲git status时,会发现有很多untracked files文件该怎么办?_untracked files怎么处理
- 2js获取指定时间范围内指定间隔天数的所有日期_js通过开始时间和结束时间、间隔时间计算出中间的所有日期
- 3sql数据库的csv导入报错:Columns in table defination are 11, columns in file are 14:sjsysc-hh405-zbhx783w
- 4数据库之MHA高可用集群部署及故障切换_mha4mysql
- 5身份证识别系统(安卓)
- 6鸿蒙样例项目部署到真机上时出现No signature is configured. Configure a signature by referring to the following link.
- 7移动云智能算力调度平台,谱写算力互联互通新篇章
- 8python计算bmi指数_python 练习题:计算的BMI指数,并根据BMI指数条件选择
- 9Python爬虫学习( 二 )——会话和Cookies_蜘蛛抓取会读取网站cookie
- 10yolov8---predict实验_yolov8 predict
chinese_llama_aplaca训练和代码分析_split=f"train[:{data_args.validation_split_percent
赞
踩
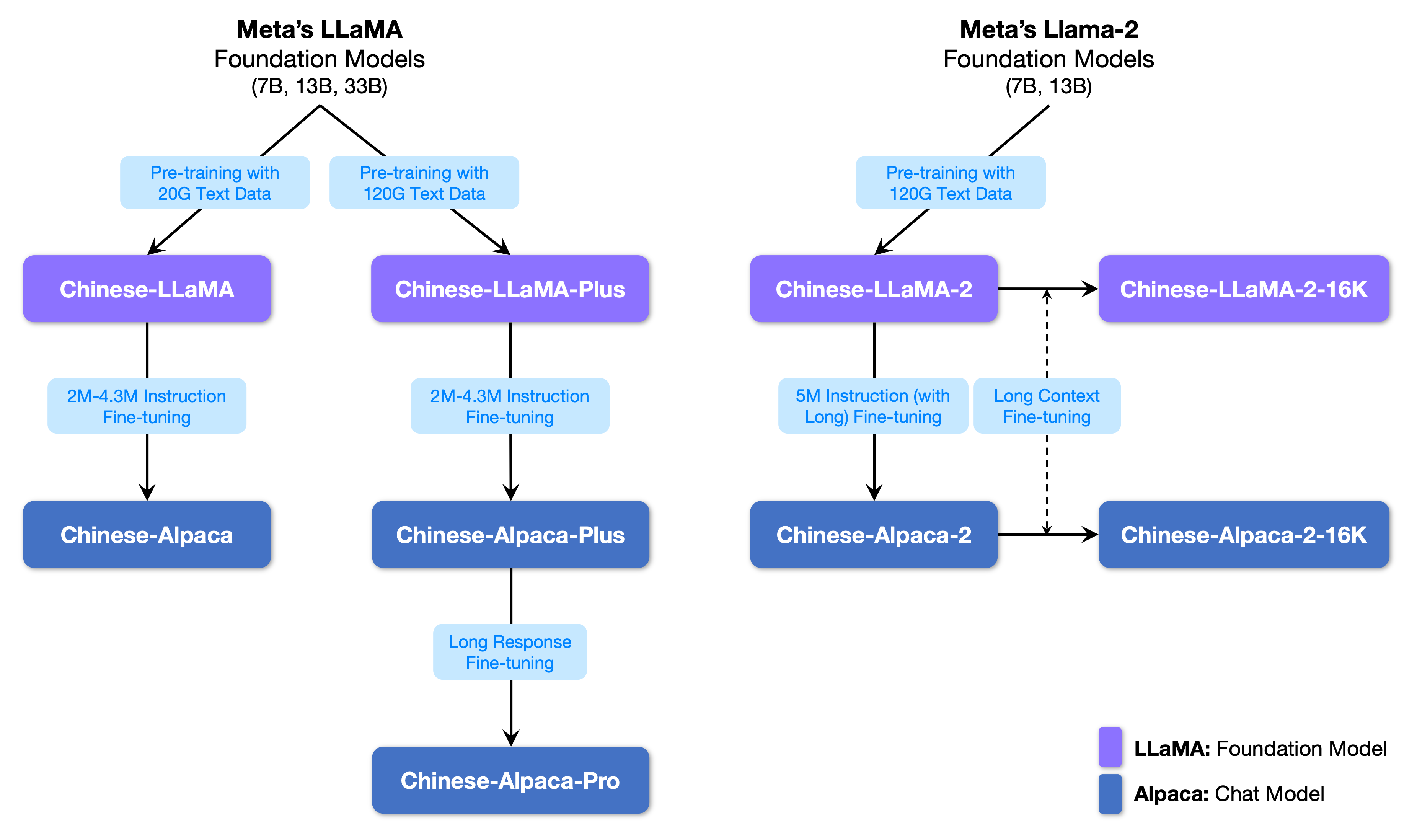
训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki · GitHub中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs) - 训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki![]() https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E8%8A%82中文LLaMA&Alpaca大语言模型词表扩充+预训练+指令精调 - 知乎在 大模型词表扩充必备工具SentencePiece一文中,我们提到了在目前开源大模型中,LLaMA无疑是最闪亮的星。但是,与 ChatGLM-6B 和 Bloom 原生支持中文不同。 LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支…
https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E8%8A%82中文LLaMA&Alpaca大语言模型词表扩充+预训练+指令精调 - 知乎在 大模型词表扩充必备工具SentencePiece一文中,我们提到了在目前开源大模型中,LLaMA无疑是最闪亮的星。但是,与 ChatGLM-6B 和 Bloom 原生支持中文不同。 LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支…![]() https://zhuanlan.zhihu.com/p/631360711GitHub - liguodongiot/llm-action: 本项目旨在分享大模型相关技术原理以及实战经验。本项目旨在分享大模型相关技术原理以及实战经验。. Contribute to liguodongiot/llm-action development by creating an account on GitHub.
https://zhuanlan.zhihu.com/p/631360711GitHub - liguodongiot/llm-action: 本项目旨在分享大模型相关技术原理以及实战经验。本项目旨在分享大模型相关技术原理以及实战经验。. Contribute to liguodongiot/llm-action development by creating an account on GitHub.![]() https://github.com/liguodongiot/llm-action大模型词表扩充必备工具SentencePiece - 知乎背景随着ChatGPT迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:ChatGLM衍生的大模型(wenda、 ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera…
https://github.com/liguodongiot/llm-action大模型词表扩充必备工具SentencePiece - 知乎背景随着ChatGPT迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:ChatGLM衍生的大模型(wenda、 ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera…![]() https://zhuanlan.zhihu.com/p/630696264经过了一次预训练和一次指令精调,预训练使用扩充后的tokenizer,精调使用chinese_llama_aplaca的tokenizer。
https://zhuanlan.zhihu.com/p/630696264经过了一次预训练和一次指令精调,预训练使用扩充后的tokenizer,精调使用chinese_llama_aplaca的tokenizer。
1.词表扩充
为什么要扩充词表?直接在原版llama上用中文预训练不行吗?
原版LLaMA模型的词表大小是32K,其主要针对英语进行训练(具体详见LLaMA论文),对多语种支持不是特别理想(可以对比一下多语言经典模型XLM-R的词表大小为250K)。通过初步统计发现,LLaMA词表中仅包含很少的中文字符,所以在切词时会把中文切地更碎,需要多个byte token才能拼成一个完整的汉字,进而导致信息密度降低。比如,在扩展词表后的模型中,单个汉字倾向于被切成1个token,而在原版LLaMA中可能就需要2-3个才能组合成一个汉字,显著降低编解码的效率。
Chinese-LLaMA-Alpaca是在通用中文语料上训练了基于 sentencepiece 的20K中文词表并与原版LLaMA模型的32K词表进行合并,排除重复的token后,得到的最终中文LLaMA词表大小为49953。在模型精调(fine-tune)阶段 Alpaca 比 LLaMA 多一个 pad token,所以中文Alpaca的词表大小为49954。合并中文扩充词表并与原版LLaMA模型的32K词表,这里直接使用官方训练好的词表chinese_sp.model。
1.1 sentencepiece训练:
spm_train --input=/workspace/data/book/hongluomeng_clean.txt --model_prefix=/workspace/model/book/hongluomeng-tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe
- --input: 训练语料文件,可以传递以逗号分隔的文件列表。文件格式为每行一个句子。 无需运行tokenizer、normalizer或preprocessor。 默认情况下,SentencePiece 使用 Unicode NFKC 规范化输入。
- --model_prefix:输出模型名称前缀。 训练完成后将生成 <model_name>.model 和 <model_name>.vocab 文件。
- --vocab_size:训练后的词表大小,例如:8000、16000 或 32000
- --character_coverage:模型覆盖的字符数量,对于字符集丰富的语言(如日语或中文)推荐默认值为 0.9995,对于其他字符集较小的语言推荐默认值为 1.0。
- --model_type:模型类型。 可选值:unigram(默认)、bpe、char 或 word 。 使用word类型时,必须对输入句子进行pretokenized。
1.2 训练得到的model和原词表进行合并
- 转换格式
- ```
- python convert_llama_weights_to_hf.py --input_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base/ --model_size 7B --output_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/
- ```
-
- 词表合并
- ```
- python merge_tokenizers.py --llama_tokenizer_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --chinese_sp_model_file /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/scripts/merge_tokenizer/chinese_sp.model
- ```
- merged_tokenizer_sp:为训练好的词表模型
- merged_tokenizer_hf:HF格式训练好的词表模型
2.训练:
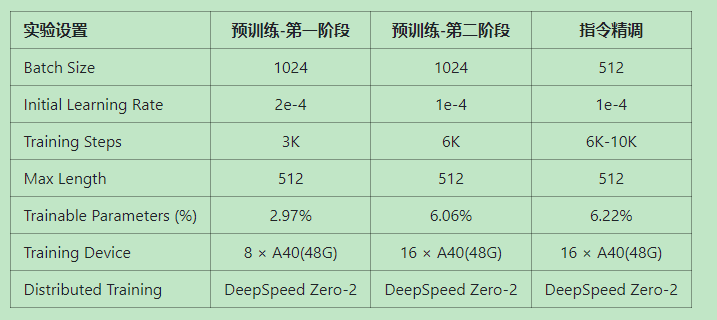
训练分三个阶段,第一和第二阶段属于预训练阶段,第三阶段属于指令精调。
2.1 第一阶段
冻结transformer参数,仅训练embedding,在尽量不干扰元模型的情况下适配新增的中文词向量。收敛速度较慢,如果不是有特别充裕的时间和计算资源,官方建议跳过该阶段,同时,官网并没有提供该阶段的代码,如果需要进行该阶段预训练,需要自行修改。
第一步:在训练之前,将除了Embedding之外的层设置为param.requires_grad = False,如下所示:
- for name, param in model.named_parameters():
- if "model.embed_tokens" not in name:
- param.requires_grad = False
第二步:在训练的时候,在优化器中添加过滤器filter把requires_grad = False的参数过滤掉,这样在训练的时候,不会更新这些参数,如下所示:
optimizer = AdamW(filter(lambda p: p.requires_grad, model.parameters()))2.2 第二阶段
使用lora,为模型添加lora权重,训练embedding的同时更新lora权重
- lr=2e-4
- lora_rank=8
- lora_alpha=32
- lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
- modules_to_save="embed_tokens,lm_head"
- lora_dropout=0.05
-
- pretrained_model=/home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/
- chinese_tokenizer_path=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/scripts/merge_tokenizer/merged_tokenizer_hf/
- dataset_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/
- data_cache=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data_cache/
- per_device_train_batch_size=1
- per_device_eval_batch_size=1
- gradient_accumulation_steps=1
- training_step=100
- output_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/
-
- deepspeed_config_file=ds_zero2_no_offload.json
-
- torchrun --nnodes 1 --nproc_per_node 3 run_clm_pt_with_peft.py \
- --deepspeed ${deepspeed_config_file} \
- --model_name_or_path ${pretrained_model} \
- --tokenizer_name_or_path ${chinese_tokenizer_path} \
- --dataset_dir ${dataset_dir} \
- --data_cache_dir ${data_cache} \
- --validation_split_percentage 0.001 \
- --per_device_train_batch_size ${per_device_train_batch_size} \
- --per_device_eval_batch_size ${per_device_eval_batch_size} \
- --do_train \
- --seed $RANDOM \
- --fp16 \
- --num_train_epochs 1 \
- --lr_scheduler_type cosine \
- --learning_rate ${lr} \
- --warmup_ratio 0.05 \
- --weight_decay 0.01 \
- --logging_strategy steps \
- --logging_steps 10 \
- --save_strategy steps \
- --save_total_limit 3 \
- --save_steps 200 \
- --gradient_accumulation_steps ${gradient_accumulation_steps} \
- --preprocessing_num_workers 8 \
- --block_size 512 \
- --output_dir ${output_dir} \
- --overwrite_output_dir \
- --ddp_timeout 30000 \
- --logging_first_step True \
- --lora_rank ${lora_rank} \
- --lora_alpha ${lora_alpha} \
- --trainable ${lora_trainable} \
- --modules_to_save ${modules_to_save} \
- --lora_dropout ${lora_dropout} \
- --torch_dtype float16 \
- --gradient_checkpointing \
- --ddp_find_unused_parameters False
2.3 将lora模型合并到基础模型中
python merge_llama_with_chinese_lora.py --base_model /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --lora_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/pt_lora_model/ --output_type huggingface --output_dir /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/2.4 第三阶段:指令精调
训练数据是alpaca_data_zh_51k.json,词表扩充阶段得到的词表是49953,但是sft阶段,alpaca的词表比llama多一个pad token,所以是49954,注意这个chinese_llama_alpaca的词表直接从作者的项目中拉取。
- lr=1e-4
- lora_rank=8
- lora_alpha=32
- lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
- modules_to_save="embed_tokens,lm_head"
- lora_dropout=0.05
-
- pretrained_model=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/
- chinese_tokenizer_path=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/chinese_alpaca_tokenizer/
- dataset_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/
- per_device_train_batch_size=1
- per_device_eval_batch_size=1
- gradient_accumulation_steps=8
- output_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/
- #peft_model=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/
- validation_file=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/alpaca_valid.json
-
- deepspeed_config_file=ds_zero2_no_offload.json
-
- torchrun --nnodes 1 --nproc_per_node 3 run_clm_sft_with_peft.py \
- --deepspeed ${deepspeed_config_file} \
- --model_name_or_path ${pretrained_model} \
- --tokenizer_name_or_path ${chinese_tokenizer_path} \
- --dataset_dir ${dataset_dir} \
- --validation_split_percentage 0.001 \
- --per_device_train_batch_size ${per_device_train_batch_size} \
- --per_device_eval_batch_size ${per_device_eval_batch_size} \
- --do_train \
- --do_eval \
- --seed $RANDOM \
- --fp16 \
- --num_train_epochs 1 \
- --lr_scheduler_type cosine \
- --learning_rate ${lr} \
- --warmup_ratio 0.03 \
- --weight_decay 0 \
- --logging_strategy steps \
- --logging_steps 10 \
- --save_strategy steps \
- --save_total_limit 3 \
- --evaluation_strategy steps \
- --eval_steps 100 \
- --save_steps 2000 \
- --gradient_accumulation_steps ${gradient_accumulation_steps} \
- --preprocessing_num_workers 8 \
- --max_seq_length 512 \
- --output_dir ${output_dir} \
- --overwrite_output_dir \
- --ddp_timeout 30000 \
- --logging_first_step True \
- --lora_rank ${lora_rank} \
- --lora_alpha ${lora_alpha} \
- --trainable ${lora_trainable} \
- --modules_to_save ${modules_to_save} \
- --lora_dropout ${lora_dropout} \
- --torch_dtype float16 \
- --validation_file ${validation_file} \
- --gradient_checkpointing \
- --ddp_find_unused_parameters False
- # --peft_path ${peft_model}
2.5 将预训练权重lora和精调lora合并到基础模型上
python merge_llama_with_chinese_lora.py --base_model /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --lora_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/pt_lora_model/,"/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/sft_lora_model/" --output_type huggingface --output_dir /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_all/2.6 前向推理
python inference_hf.py --base_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_all/ --with_prompt --interactivetransformer==4.31.0
3.代码分析
3.1 预训练代码
- parser = HfArgumentParser((ModelArgument,DataTrainArguments,MyTrainingArgument))
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- set_seed(training_args.seed)
- config = AutoConfig.from_pretrained(model_args.model_name_or_path,...)
- tokenizer = LlamaTokenizer.from_pretrained(model_args.tokenizer_name_or_path,...)
-
- block_size = tokenizer.model_max_length
-
- with training_args.main_process_first():
- files = [file.name for file in path.glob("*.txt")]
- for idx,file in enumerate(files):
- raw_dataset = load_dataset("text",data_file,cache_dir,keep_in_memory=False)
- tokenized_dataset = raw_dataset.map(tokenize_function,...)
- grouped_dataset = tokenized_dataset.map(group_texts,...)
- - tokenize_function->output = tokenizer(examples["text"])
- processed_dataset.save_to_disk(cache_path)
- lm_datasets = concatenate_datasets([lm_datasets,processed_dataset['train']])
- lm_datasets = lm_datasets.train_test_split(data_args.validation_split_percentage)
-
- train_dataset = lm_datasets['train']
- model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,..)
- model_vocab_size = model.get_output_embeddings().weight.size(0)
- model.resize_token_embeddings(len(tokenizer))
-
- target_modules = training_args.trainable.split(',')
- modules_to_save = training_args.module_to_save
- lora_rank = training_args.lora_rank
- lora_dropout = training_args.lora_dropout
- lora_alpha = training_args.lora_alpha
- peft_config = LoraConfig(TasskType.CAUSAL_LM,target_modules,lora_rank,lora_alpha,lora_dropout,lora_dropout,modules_to_save)
- model = get_peft_model(model,peft_config)
- old_state_dict = model.state_dict()
- model.state_dict = (
- lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
- ).__get__(model, type(model))
-
- trainer = Trainer(
- model,
- training_args,
- train_dataset,
- eval_dataset,
- tokenizer,
- fault_tolerance_data_collator,
- compute_metrics,preprocess_logits_for_metrics)
- trainer.add_callback(SavePeftModelCallback)
-
- checkpoint = training_args.resume_from_checkpoint
- train_result = trainer.train(checkpoint)
- metrics = train_result.metrics
- trainer.log_metrics("train",metrics)
- trainer.save_metrics("train",metrics)
- trainer.save_state()
3.2 指令精调代码
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, MyTrainingArguments))
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- set_seed(training_args.seed)
- config = AutoConfig.from_pretrained(model_args.model_name_or_path,...)
- tokenizer = LlamaTokenizer.from_pretrained(model_args.tokenizer_name_or_path,...)
-
- tokenizer.add_special_tokens(dict(pad_token="[PAD]"))
- data_collator = DataCollatorForSupervisedDataset(tokenizer)
- - input_ids,labels = tuple([instance[key] for instance in instances] for key in ("input_ids","labels"))
- - input_ids = torch.nn.utils.rnn.pad_sequence(input_ids,batch_first=True,padding_value=self.tokenizer.pad_token_id)
- - labels = torch.nn.utils.rnn.pad_sequence(labels,batch_first=True,padding_values=-100)
-
- with training_args.main_process_first():
- files = [os.path.join(path,filename) for file in path.glob("*.json")]
- train_dataset = build_instruction_dataset(files,tokenizer,data,max_seq_length,...)
- - for file in data_path:
- raw_dataset = load_dataset("json",data_file=file,..)
- tokenized_dataset = raw_dataset.map(tokenization,...)
- -- for instruction,input,output in zip(examples['instruction'],examples['input'],examples['output']):
- if input is not None and input != "":
- instruction = instruction+"\n"+input
- source = prompt.format_map({'instruction':instruction})
- target = f"{output}{tokenizer.eos_token}"
- tokenized_sources = tokenizer(sources,return_attention_mask=False)
- tokenized_targets = tokenizer(targets,return_attention_mask=False,add_special_tokens=False)
- for s,t in zip(tokenized_sources['input_ids'],tokenized_targets['input_ids']):
- input_ids = torch.LongTensor(s+t)[:max_seq_length]
- labels = torch.LongTensor([IGNORE_INDEX]*len(s) + t)[:max_seq_length]
- return results = {'input_ids':all_input_ids,'labels':all_labels}
-
- model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,config,...)
- embedding_size = model.get_input_embeddings().weight.shape[0]
- model.resize_token_embeddings(len(tokenizers))
-
- target_modules = training_args.trainable.split(',')
- modules_to_save = training_args.modules_to_save
- if modules_to_save is not None:
- modules_to_save = modules_to_save.split(',')
- lora_rank = training_args.lora_rank
- lora_dropout = training_args.lora_dropout
- lora_alpha = training_args.lora_alpha
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM,
- target_modules=target_modules,
- inference_mode=False,
- r=lora_rank, lora_alpha=lora_alpha,
- lora_dropout=lora_dropout,
- modules_to_save=modules_to_save)
- model = get_peft_model(model, peft_config)
-
- old_state_dict = model.state_dict
- model.state_dict = (
- lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
- ).__get__(model, type(model))
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset,
- eval_dataset=eval_dataset,
- tokenizer=tokenizer,
- data_collator=data_collator,
- )
- trainer.add_callback(SavePeftModelCallback)
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- metrics = train_result.metrics
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
3.3 推理代码
- apply_attention_patch(use_memory_efficient_attention=True)
- apply_ntk_scaling_path(args.alpha)
-
- generation_config = dict(
- temperature=0.2,
- topk=40,
- top_p=0.9,
- do_sample=True,
- num_beams=1,
- repetition_penalty=1.1,
- max_new_tokens=400)
-
- tokenizer = LlamaTokenizer.from_pretrained(args.tokenizer_path)
- base_model = LlamaForCausalLM.from_pretrained(args.base_model,load_in_8bit,torch.float16,low_cpu_mem_usage=True)
- model_vocab_size = base_model.get_input_embeddings().weight.size(0)
- base_model.resize_token_embeddings(tokenzier_vocab_size)
- model = base_model
- model.eval()
-
- with torch.no_grad():
- while True:
- raw_input_text = input("Input:")
- input_text = generate_prompt(instruction=raw_input_text)
- inputs = tokenizer(input_text,return_tensors="pt")
- generation_output = model.generate(
- input_ids=inputs["input_ids"].to(device),
- attention_mask=inputs['attention_mask'].to(device),
- eos_token_id=tokenizer.eos_token_id,
- pad_token_id=tokenizer.pad_token_id,
- **generation_config)
- s = generate_output[0]
- output = tokenizer.decode(s,skip_special_tokens=True)
- response = output.split("### Response:")[1].strip()

