
- 1总结 | 常用文本特征选择
- 2Spring Cloud Gateway + Spring Security OAuth2 + JWT 实现统一认证授权和网关鉴权_gateway oauth2+jwt+security
- 3【NLP】Doc2vec原理解析及代码实践
- 4AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.20-2024.03.25
- 5【AI视野·今日NLP 自然语言处理论文速览 第四十三期】Thu, 28 Sep 2023_ragas: automated evaluation of retrieval augmented
- 6ChatGPT助力科研项目_chatgpt帮助科研
- 7VS2013 IDE C#生成CodeMap_66ma4b.top
- 8人工智能何时传入中国?_渠川璐
- 9手把手教你使用Segformer训练自己的数据
- 10Ubuntu下配置samba实现文件夹的共享_ubuntu 文件共享 255
hadoop安装以及配置_hadoop.proxyuser
赞
踩
大数据技术之Hadoop(入门)
版本:V3.0
第1章 完全分布式运行模式(开发重点)
分析:
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
1.1 Hadoop部署
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
|
| hadoop102 | hadoop103 | hadoop104 |
| HDFS
| NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN |
NodeManager | ResourceManager NodeManager |
NodeManager |
2)用SecureCRT工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
切换到sftp连接页面,选择Linux下编译的hadoop jar包拖入,如图2-32所示
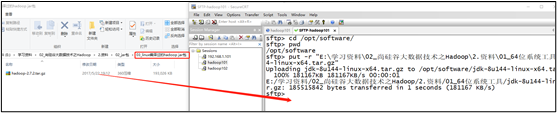
图 拖入hadoop的tar包

图2-33 拖入Hadoop的tar包成功
3)进入到Hadoop安装包路径下
[atguigu@hadoop102 ~]$ cd /opt/software/
4)解压安装文件到/opt/module下面
[atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
5)查看是否解压成功
[atguigu@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3
6)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
在profile文件末尾添加JDK路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
:wq
(4)分发环境变量文件
[atguigu@hadoop102 hadoop-3.1.3]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
(5)source 是之生效(3台节点)
[atguigu@hadoop102 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
1.2 配置集群
1)核心配置文件
配置core-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
</configuration>
2)HDFS配置文件
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3)YARN配置文件
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
4)MapReduce配置文件
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5)配置workers
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
1.3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
[atguigu@hadoop102 hadoop]$vi mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
1.4 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
1.5 分发Hadoop
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/
1.6 群起集群
1)启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format
(2)启动HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(4)Web端查看HDFS的Web页面:http://hadoop102:9870/

(5)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop104:9868/status.html
(b)查看SecondaryNameNode信息

1.9 Hadoop群起脚本
[atguigu@hadoop102 bin]$ pwd
/home/atguigu/bin
[atguigu@hadoop102 bin]$ vim hdp.sh
输入如下内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
[atguigu@hadoop102 bin]$ chmod 777 hdp.sh
1.10 集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。

配置时间同步具体实操:
1)时间服务器配置(必须root用户)
(0)查看所有节点ntpd服务状态和开机自启动状态
[atguigu@hadoop102 ~]$ sudo systemctl status ntpd
[atguigu@hadoop102 ~]$ sudo systemctl is-enabled ntpd
(1)在所有节点关闭ntp服务和自启动
[atguigu@hadoop102 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop102 ~]$ sudo systemctl disable ntpd
(2)修改hadoop102的ntp.conf配置文件
[atguigu@hadoop102 ~]$ sudo vim /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改hadoop102的/etc/sysconfig/ntpd 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
(5)设置ntpd服务开机启动
[atguigu@hadoop102 ~]$ sudo systemctl enable ntpd
2)其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudo crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[atguigu@hadoop103 ~]$ sudo date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[atguigu@hadoop103 ~]$ sudo date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。

