
- 1Python解析和嵌入媒体资源的工具库之micawber使用详解
- 2Android Studio 配置国内镜像源、HTTP代理(详细步骤)_androidstudio配置国内镜像源
- 32022年天梯赛比赛真题,L1基础题,C语言,没有算法的那种_pta天梯l1-83谁能进图书馆
- 42021前端几大UI主流框架排行榜_比element更好的ui
- 5数据湖浅析(以hudi为例)_hudi 是解决数据湖的什么问题的?
- 6最大子序列和问题的求解_完成最大序列和问题的求解。
- 7SQLServer if判断与删除临时表_sqlserver if drop table
- 8Gitee(码云)项目构建,初始化!只需两步。_gitee初始化仓库
- 9人大金仓数据库KingbaseES 高可用介绍_kingbasees 集群高可用
- 10如何在电脑桌面设置并实时显示倒计时:实现高效时间管理与事件提醒的全方位指南_怎么让电脑显示倒计时桌面
Linux 常用命令与教程_linux命令 l -follow 2>/dev/null
赞
踩
http://c.biancheng.net/view/705.html C语言编程网的教程很好
还有菜鸟教程的
还有这个 https://mp.weixin.qq.com/s/7bSwKiPmtJbs7FtRWZZqpA 讲的也不错
https://baike.baidu.com/item/PS/8850709 百度百科 搜索一个linux命令 会出来这个
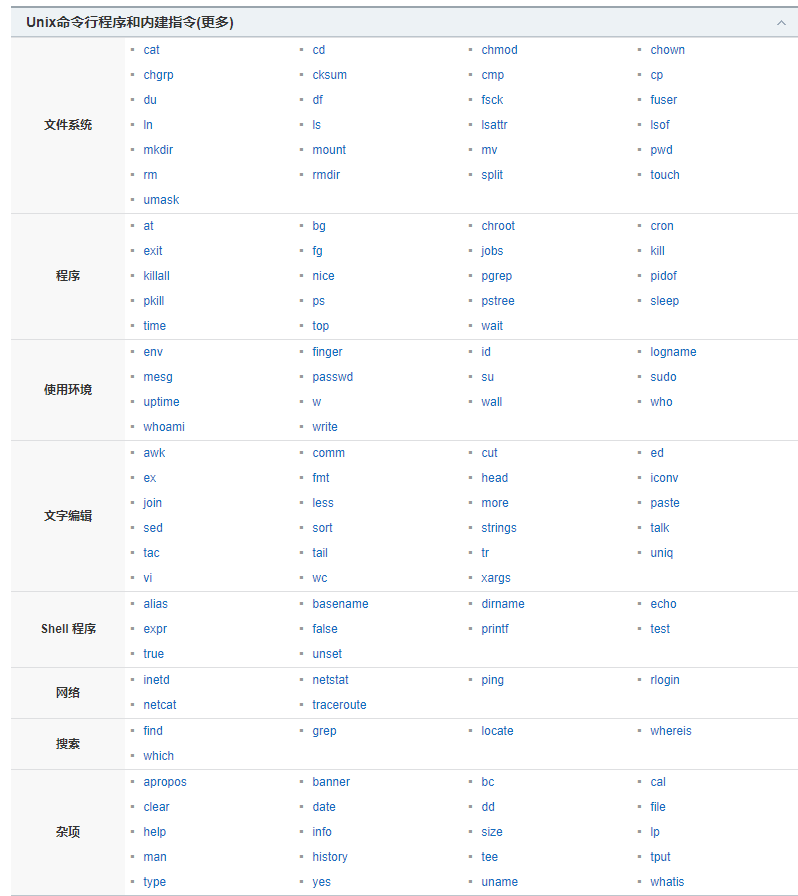
〇、序言:命令基本格式
Linux中命令格式为:command [options] [arguments]
中括号代表是可选的,即有些命令不需要选项也不需要参数
登录系统后,第一眼看到的内容是:
[root@localhost ~]#
- 1
这就是 Linux 系统的命令提示符。那么,这个提示符的含义是什么呢?
[]:这是提示符的分隔符号,没有特殊含义。
root:显示的是当前的登录用户,笔者现在使用的是 root 用户登录。
@:分隔符号,没有特殊含义。
localhost:当前系统的简写主机名(完整主机名是 localhost.localdomain)。
~:代表用户当前所在的目录,此例中用户当前所在的目录是家目录。
\#:命令提示符,Linux 用这个符号标识登录的用户权限等级。如果是超级用户,提示符就是 #;如果是普通用户,提示符就是 $。
家目录(又称主目录)是什么? Linux 系统是纯字符界面,用户登录后,要有一个初始登录的位置,这个初始登录位置就称为用户的家:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
选项:options
选项分为长选项和短选项。
短选项
比如-h,-l,-s等。(- 后面接单个字母)
-
短选项都是使用
-引导,当有多个短选项时,各选项之间使用空格隔开。 -
有些命令的短选项可以组合,比如
-l–h可以组合为–lh -
有些命令的短选项可以不带
-,这通常叫作BSD风格的选项,比如ps aux -
有些短选项需要带选项本身的参数,比如
-L 512M
长选项
比如--help,--list等。(-- 后面接单词)
-
长选面都是完整的单词
-
长选项通常不能组合
-
如果需要参数,长选项的参数通常需要
=,比如--size=1G
参数arguments:
参数是指命令的作用对象。
如ls命令,不加参数的时候显示是当前目录,也可以加参数,如ls /dev, 则输出结果是/dev目录。
参数是传递到脚本中的真实的参数
以上简要说明了选项及参数的区别,但具体Linux中哪条命令有哪些选项及参数,需要我们靠经验积累或者查看Linux的帮助了。
命令尾部描述符的作用
大部分来自 https://huaweicloud.csdn.net/638db1cddacf622b8df8c6fb.html
;
注意:用;号隔开每个命令, 每个命令按照从左到右的顺序执行, 但是彼此之间不关心是否失败, 所有命令都会执行。
()
把多个命令,当做一个整体执行,同时增强了可读性。
单竖线 |
竖线|,在linux中是作为管道符的,将|前面命令的输出作为|后面的输入。举个例子
ps -ef | grep java #使用正则grep命令寻找java进程
- 1
实际上似乎可以理解成 grep java (ps -ef)
而且 管道符可以多次使用,如 ps -aux|grep xxxx|grep -v grep可以过滤掉查找进程的自身这条命令;
# 有两条命令
[root@ev003v ~]$ ps -aux|grep python
root 329 0.0 0.0 112828 984 pts/11 S+ 16:06 0:00 grep --color=auto python
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
#只剩下一条了
[root@ev003v ~]$ ps -aux|grep python|grep -v grep
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
双竖线 ||
双竖线||,用双竖线||分割的多条命令,执行的时候遵循如下规则,如果前一条命令为真,则后面的命令不会执行,如果前一条命令为假,则继续执行后面的命令。
[[ 1 -lt 2 ]]||echo b
- 1
判断文件是否存在 不存在则创建
[[ -f 1.txt ]] || touch 1.txt
- 1
& 和 && 与nohub
&
- 如果放到语句最后 那么代表把命令放到后台去执行
- 同时执行多条命令,不管命令是否执行成功 (实际上是上面那条??)
- 有时代表引用 看下面的 0 1 2 & >那
&&
- 可同时执行多条命令,当碰到执行错误的命令时,将不再执行后面的命令。如果一直没有错误的,则执行完毕。
&和nohub的区别和常见使用场景
nohub的意义
全称 no hangup 即不挂起,即使关掉shell,依然会继续执行。
&代表后台执行,免疫SIGINT信号(Ctrl+C),但是不免疫SIGHUP信号(关闭shell);nohub相反,关闭shell仍会执行,但是Ctrl+C可以中断执行。因此可以将这两个联合使用,让进程既不受Ctrl+C影响,也不受shell关闭影响,类似守护进程。
输入输出重定向 >和>>与<
输出重定向
>把正常信息(剔除错误信息)重定向到另一个文件内
>和>>其实都属于输出重定向,都可以输出内容到指定文件。
那具体的区别是什么呢?
>会覆盖目标的原有内容,当文件存在时,会先删除原文件,再重新创建文件,然后把内容写入该文件,否则直接创建文件。
>>会在目标原有内容后追加内容,当文件存在时直接在文件末尾进行内容追加,不会删除原文件,否则直接创建文件。
# 示例:
# 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
cat -n textfile1 > textfile2
- 1
- 2
- 3
| 命令符号格式 | 作用 |
|---|---|
| 命令 > 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据。 |
| 命令 2> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,会清空原有数据,再写入新数据。 |
| 命令 >> 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面。 |
| 命令 2>> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,新数据将写入到原有内容的后面。 |
| 命令 >> 文件 2>&1 或者 命令 &>> 文件 | 将标准输出或者错误输出写入到指定文件,如果该文件中已包含数据,新数据将写入到原有内容的后面。注意,第一种格式中,最后的 2>&1 是一体的,可以认为是固定写法。 |
后面讲cat命令会更多示例
输入重定向
| 命令符号格式 | 作用 |
|---|---|
| 命令 < 文件 | 将指定文件作为命令的输入设备 |
| 命令 << 分界符 | 表示从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),这里的分界符其实就是自定义的字符串 |
| 命令 < 文件 1 > 文件 2 | 将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中。 |
[root@localhost ~]# cat /etc/passwd
#这里省略输出信息,读者可自行查看
[root@localhost ~]# cat < /etc/passwd
#输出结果同上面命令相同
注意,虽然执行结果相同,但第一行代表是以键盘作为输入设备,而第二行代码是以 /etc/passwd 文件作为输入设备。
【例 2】
[root@localhost ~]# cat << 0
\>linuxyz.cn
\>Linux
\>0
linuxyz.cn
Linux
可以看到,当指定了 0 作为分界符之后,只要不输入 0,就可以一直输入数据。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
【例 3】
首先,新建文本文件 a.tx,然后执行如下命令:
[root@localhost ~]# cat a.txt
[root@localhost ~]# cat < /etc/passwd > a.txt
[root@localhost ~]# cat a.txt
\#输出了和 /etc/passwd 文件内容相同的数据
可以看到,通过重定向 /etc/passwd 作为输入设备,并输出重定向到 a.txt,最终实现了将 /etc/passwd 文件中内容复制到 a.txt 中。
- 1
- 2
- 3
- 4
- 5
-
减号- 代表标准输入还是标准输出,视具体命令而定
如果命令是往外输出的,则减号- 代表标准输出stdout
如果命令是等待输入的,则减号- 代表标准输入stdin
以下面复制文件的列子进行讲解
# "-" 代替标准输入stdin 或标准输出stdout,视具体命令而定
# 在输出内容添加一行
cat - file.txt <<< "line num 1"
## <<< 是heredoc,这里"-"接收<<< 的输入,以匿名文件的形式供cat 读取
## cat 将"-"代表的匿名文件和file.txt 的内容连接在一起,执行结果为
### line num 1
### file.txt 第一行内容
### file.txt 第二行内容
### ......
# 只取文件的一列并与另一文件做diff
awk '{ print $1 }' a | diff - b
## 管道"|"左边的输出就是右边的输入,这里管道左边是awk 的输出,管道右边用"-"接收
## "-"再以匿名文件的形式供diff 读取,所以,这里的"-"既有输入也有输出
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
0 1 2 与& >
nohup python3 /home/main.py 2>&1 &
- 1
1 和 2 在 shell 命令中代表什么?
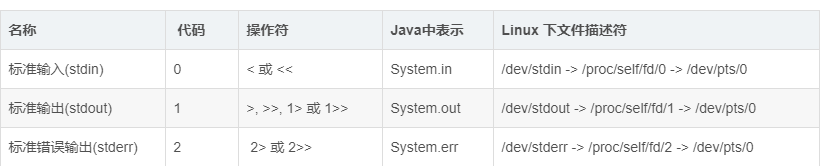
0 是标准输入stdin,一般是从键盘获得输入
1 是标准输出stdout,一般是输出到屏幕了
2 是标准错误输出stderr,一般是输出到屏幕,重定向到文件中后,屏幕就看不到它了
dev 是device
我们平时使用的
echo "hello"> t.log
其实也可以写成
echo "hello”1> t.log
- 1
- 2
- 3
- 4
符号的意义
语法: file_descriptor > file_name
所以2>&1代表将标准错误输出重定向到标准输出中,为什么不能用2>1?
答:这代表将错误日志输出到1这个文件中。&可以理解为C语言的指针,加了&1,代表这是一个引用(引用的标准输出)
& 的意义
放在命令最后,代表这条命令放到后台去执行,此时可以执行新的命令了。
2>&1为什么要放最后
分别分析这两行命令的逻辑:
nohup java -jar app.jar >log 2>&1 &
nohup java -jar app.jar 2>&1 >log &
- 1
- 2
第一条命令的逻辑是:
本来1----->屏幕 (1指向屏幕)
执行>log后, 1----->log (1指向log)
执行2>&1后, 2----->1 (2指向1,而1指向log,因此2也指向了log)
- 1
- 2
- 3
第二条命令的逻辑是
本来1----->屏幕 (1指向屏幕)
执行2>&1后, 2----->1 (2指向1,而1指向屏幕,因此2也指向了屏幕)
执行>log后, 1----->log (1指向log,2还是指向屏幕)
- 1
- 2
- 3
“&>”、“>” 作用和区别
或1> 作用: 仅将正常信息(非异常信息,非报错信息),重定向输出到指定文件;
2>作用:仅将错误信息重定向输出到指定文件中;
&>或2>&1作用:同时将错误信息、普通信息一并重定向输出到指定文件。
[root@CentOs7]# lll
-bash: lll: command not found //由于Linux没有lll这个命令所以会显示错误信息,这个就是stderr输出的错误信息
[root@CentOs7]# lll >test.txt
-bash: lll: command not found //由于这个是错误信息 所以不能使用标准输出>将信息重定向到test.txt文件中
[root@CentOs7]# lll&>test.txt //使用&>重定向 ,会一并把错误信息、正确信息,一并重定向到了test.txt文件
[root@CentOs7]# cat test.txt
-bash: lll: command not found //通过cat命令确实看到了 保存的错误信息
注意:如果每次都是重定向到同一个文件,以上两个命令的效果都是覆盖原文件信息,不是内容追加!
说明:可把错误、异常信息同时输出到两个不同的文件。
make xxx 1> normal.txt 2> error.txt
简而言之,&>和>&的作用相同,都是把标准信息+错误信息重定向到指定位置,它们都是2>&1的简写写法。
但是在日常开发、学习过程中,习惯上更偏向于使用&>。
虽然它们的效果相同,然而在使用上,还是略有差异的,强烈建议直接使用&>即可。
9.2、常用的重定向符号
将正常的信息,重定向到某个文件/设备中(会覆盖文件原有信息)
将正常的信息,重定向到某个文件/设备中(不会覆盖文件原有信息,只会追加)
&> 将正常+异常信息,一并重定向到某个文件/设备中(会覆盖文件原有信息)
&>>将正常+异常信息,一并重定向到某个文件/设备中(不会覆盖文件原有信息,只会追加)
2> 只输出错误信息到某个文件/设备中
还有一些较少会用到的,比较烧脑,n<&- 和>&n以及<&-感兴趣,可以单独去了解一下。
记忆小妙招:
看到有两个尖括号的,代表是内容追加,单个尖括号,之前的内容都会被覆盖!!!
9.3、/dev/null 黑洞
/dev/null 是一个特殊的设备文件,这个文件接收到任何数据都会被丢弃,俗称“黑洞”
它非常等价于一个只写文件,所有写入它的内容都会永远丢失,而尝试从它那儿读取内容则什么也读不到,然而,/dev/null对命令行和脚本都非常的有用。
黑洞的使用场景:
如果不想把正确/错误信息,输出到屏幕时,就可以把这部分信息输出到黑洞中。
1> /dev/null 经将正常信息出入到黑洞
echo “httpd server is running” >> /dev/null #如果不希望将信息打印到屏幕,可以输出到黑洞复制
2> /dev/null意思就是把错误输出到“黑洞” ,不会显示在屏幕上。
脚本示例
CI_ENV=testing;/usr/local/bin/php /home/app/system/xxx/application/script/crontab/xxx.php &>> /tmp/xxx.log
php " . BASEPATH . "../application/script/xxxx.php -w " . $args['w'] . " -> /tmp/xxxxx.txt
- 1
- 2
- 3
停止和挂起
停止是ctrl+c 挂起是 ctrl+z
[root@localhost ~]# find / -name demo.jpg <--在根目录下查找 demo.jpg 文件,比较耗时
#此处省略了该命令的部分输出信息
#按“CTRL+Z”组合键,即可将该进程挂起
[root@localhost ~]# ps <--查看正在运行的进程
PID TTY TIME CMD
2573 pts/0 00:00:00 bash
2587 pts/0 00:00:01 find
2588 pts/0 00:00:00 ps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
命令执行过程
Linux命令的执行过程是怎样的?(新手必读)
2022-05-07 228举报
简介: 前面讲过,在 Linux 系统中“一切皆文件”,Linux 命令也不例外。那么,当编辑完成 Linux 命令并回车后,系统底层到底发生了什么事情呢?
前面讲过,在 Linux 系统中“一切皆文件”,Linux 命令也不例外。那么,当编辑完成 Linux 命令并回车后,系统底层到底发生了什么事情呢?
简单来说,Linux 命令的执行过程分为如下 4 个步骤。
-
判断路径
判断用户是否以绝对路径或相对路径的方式输入命令(如 /bin/ls),如果是的话直接执行。 -
检查别名
Linux 系统会检查用户输入的命令是否为“别名命令”。要知道,通过 alias 命令是可以给现有命令自定义别名的,即用一个自定义的命令名称来替换原本的命令名称。
例如,我们经常使用的 rm 命令,其实就是 rm -i 这个整体的别名:
[root@localhost ~]# alias rm
alias rm=‘rm -i’
这使得当使用 rm 命令删除指定文件时,Linux 系统会要求我们再次确认是否执行删除操作。例如:
[root@localhost ~]# rm a.txt <-- 假定当前目录中已经存在 a.txt 文件
rm: remove regular file ‘a.txt’? y <-- 手动输入 y,即确定删除
[root@localhost ~]#
这里可以使用 unalias 命令,将 Linux 系统设置的 rm 别名删除掉,执行命令如下:
[root@localhost ~]# alias rm
alias rm=‘rm -i’
[root@localhost ~]# unalias rm
[root@localhost ~]# rm a.txt
[root@localhost ~]# <–直接删除,不再询问
注意,这里仅是为了演示 unalisa 的用法,建议读者删除 rm 别名之后,再手动添加到系统中,执行如下命令即可再次成功添加:
[root@localhost ~]# alias rm=‘rm -i’
3) 判断是内部命令还是外部命令
Linux命令行解释器(又称为 shell)会判断用户输入的命令是内部命令还是外部命令。其中,内部命令指的是解释器内部的命令,会被直接执行;而用户通常输入的命令都是外部命令,这些命令交给步骤四继续处理。
内部命令由 Shell 自带,会随着系统启动,可以直接从内存中读取;而外部命令仅是在系统中有对应的可执行文件,执行时需要读取该文件。
判断一个命令属于内部命令还是外部命令,可以使用 type 命令实现。例如:
[root@localhost ~]# type pwd
pwd is a shell builtin <-- pwd是内部命令
[root@localhost ~]# type top
top is /usr/bin/top <-- top是外部命令
4) 查找外部命令对应的可执行文件
当用户执行的是外部命令时,系统会在指定的多个路径中查找该命令的可执行文件,而定义这些路径的变量,就称为 PATH 环境变量,其作用就是告诉 Shell 待执行命令的可执行文件可能存放的位置,也就是说,Shell 会在 PATH 变量包含的多个路径中逐个查找,直到找到为止(如果找不到,Shell 会提供用户“找不到此命令”)。
PATH 环境变量的改变,会直接影响 Shell 查找 Linux 命令的过程,有关 PATH 环境变量(是什么、如何查看、如何修改等),可阅读《Linux PATH环境变量》一文做详细了解。
环境变量
Linux 系统中环境变量的名称一般都是大写的,这是一种约定俗成的规范。
我们可以使用 env 命令来查看到 Linux 系统中所有的环境变量,执行命令如下:
[root@localhost ~]# env
ORBIT_SOCKETDIR=/tmp/orbit-root
HOSTNAME=livecd.centos
GIO_LAUNCHED_DESKTOP_FILE_PID=2065
TERM=xterm
shell =/bin/bash
…
Linux 系统能够正常运行并且为用户提供服务,需要数百个环境变量来协同工作,但是,我们没有必要逐一学习每个变量,这里给大家列举了 10 个非常重要的环境变量,如表 1 所示。
环境变量名称 作用
HOME 用户的主目录(也称家目录)
SHELL 用户使用的 Shell 解释器名称
PATH 定义命令行解释器搜索用户执行命令的路径
EDITOR 用户默认的文本解释器
RANDOM 生成一个随机数字
LANG 系统语言、语系名称
HISTSIZE 输出的历史命令记录条数
HISTFILESIZE 保存的历史命令记录条数
PS1 Bash解释器的提示符
MAIL 邮件保存路径
Linux 作为一个多用户多任务的操作系统,能够为每个用户提供独立的、合适的工作运行环境,因此,一个相同的环境变量会因为用户身份的不同而具有不同的值。
例如,使用下述命令来查看 HOME 变量在不同用户身份下都有哪些值:
[root@localhost ~]# echo KaTeX parse error: Expected 'EOF', got '#' at position 30: …ot@localhost ~]#̲ su - user1 <--… echo $HOME
/home/user1
这里的 su 命令可以临时切换用户身份,此命令的具体用法会在后续章节做详细介绍。
其实,环境变量是由固定的变量名与用户或系统设置的变量值两部分组成的,我们完全可以自行创建环境变量来满足工作需求。例如,设置一个名称为 WORKDIR 的环境变量,方便用户更轻松地进入一个层次较深的目录,执行命令如下:
[root@localhost ~]# mkdir /home/work1
[root@localhost ~]# WORKDIR=/home/work1
[root@localhost ~]# cd $WORKDIR
[root@localhost work1]# pwd
/home/work1
但是,这样的环境变量不具有全局性,作用范围也有限,默认情况下不能被其他用户使用。如果工作需要,可以使用 export 命令将其提升为全局环境变量,这样其他用户就可以使用它了:
[root@localhost work1]# su user1 <-- 切换到 user1,发现无法使用 WORKDIR 自定义变量
[user1@localhost ~]$ cd
W
O
R
K
D
I
R
[
u
s
e
r
1
@
l
o
c
a
l
h
o
s
t
]
WORKDIR [user1@localhost ~]
WORKDIR[user1@localhost ] echo $WORKDIR
[user1@localhost ~]$ exit <–退出user1身份
[root@localhost work1]# export WORKDIR
[root@localhost work1]# su user1
[user1@localhost ~]$ cd
W
O
R
K
D
I
R
[
u
s
e
r
1
@
l
o
c
a
l
h
o
s
t
w
o
r
k
1
]
WORKDIR [user1@localhost work1]
WORKDIR[user1@localhostwork1] pwd
/home/work1
path环境变量与which
在讲解 PATH 环境变量之前,首先介绍一下 which 命令,它用于查找某个命令所在的绝对路径。例如:
[root@localhost ~]# which rm
/bin/rm
[root@localhost ~]# which rmdir
/bin/rmdir
[root@localhost ~]# which ls
alias ls=‘ls --color=auto’
/bin/ls
注意,ls 是一个相对特殊的命令,它使用 alias 命令做了别名,也就是说,我们常用的 ls 实际上执行的是 ls --color=auto。
通过使用 which 命令,可以查找各个外部命令(和 shell 内置命令相对)所在的绝对路径。学到这里,读者是否有这样一个疑问,为什么前面在使用 rm、rmdir、ls 等命令时,无论当前位于哪个目录,都可以直接使用,而无需指明命令的执行文件所在的位置(绝对路径)呢?其实,这是 PATH 环境变量在起作用。
首先,执行如下命令:
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin:/root/bin
这里的 echo 命令用来输出 PATH 环境变量的值(这里的 $ 是 PATH 的前缀符号),PATH 环境变量的内容是由一堆目录组成的,各目录之间用冒号“:”隔开。当执行某个命令时,Linux 会依照 PATH 中包含的目录依次搜寻该命令的可执行文件,一旦找到,即正常执行;反之,则提示无法找到该命令。
如果在 PATH 包含的目录中,有多个目录都包含某命令的可执行文件,那么会执行先搜索到的可执行文件。
从执行结果中可以看到,/bin 目录已经包含在 PATH 环境变量中,因此在使用类似 rm、rmdir、ls等命令时,即便直接使用其命令名,Linux 也可以找到该命令。
为了印证以上观点,下面举个反例,如果我们将 ls 命令移动到 /root 目录下,由于 PATH 环境变量中没有包含此目录,所有当直接使用 ls 命令名执行时,Linux 将无法找到此命令的可执行文件,并提示 No such file or directory,示例命令如下:
[root@localhost ~]# mv /bin/ls /root
[root@localhost ~]# ls
bash: /bin/ls: No such file or directory
此时,如果仍想使用 ls 命令,有 2 种方法,一种是直接将 /root 添加到 PATH 环境变量中,例如:
[root@localhost ~]# PATH=$PATH:/root
[root@localhost ~]# echo KaTeX parse error: Expected 'EOF', got '#' at position 95: …ot@localhost ~]#̲ ls Desktop …PATH 就恢复成了默认值。
另一种方法是以绝对路径的方式使用此命令,例如:
[root@localhost ~]# /root/ls
Desktop Downloads Music post-install Public Videos
Documents ls Pictures post-install.org Templates
为了不影响系统的正常使用,强烈建议大家将移动后的 ls 文件还原,命令如下:
[root@localhost ~]# mv /root/ls /bin
注意事项
PS linux复制粘贴可能提示命令不正确 由于乱码 所以可手动敲
好像也有解决方法
一、文档
cat
和vim的区别在于 这个仅仅是打开 而不编辑
-
含义:cat(英文全拼:concatenate)命令用于连接文件并打印到标准输出设备上。
-
语法格式
cat [-AbeEnstTuv] [--help] [--version] fileName
- 1
- 参数说明:
-n 或 --number:由 1 开始对所有输出的行数编号。
-b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
-E 或 --show-ends : 在每行结束处显示 $。
-T 或 --show-tabs: 将 TAB 字符显示为 ^I。
-A, --show-all:等价于 -vET。
-e:等价于"-vE"选项;
-t:等价于"-vT"选项;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 实例:
# 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
cat -n textfile1 > textfile2
#把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)
#之后将内容附加到 textfile3 文档里:
cat -b textfile1 textfile2 >> textfile3
#清空 /etc/test.txt 文档内容:
cat /dev/null > /etc/test.txt
#cat 也可以用来制作镜像文件。
#例如要制作软盘的镜像文件(软盘-》文件),将软盘放好后输入:
cat /dev/fd0 > OUTFILE
#相反的,如果想把 image file 写到软盘(文件-》网盘),输入:
cat IMG_FILE > /dev/fd0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

注意,cat 命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。不过 Linux 可以使用PgUp+上箭头组合键向上翻页,但是这种翻页是有极限的,如果文件足够长,那么还是无法看全文件的内容。
因此,cat 命令适合查看不太大的文件。当然,在 Linux 中是可以使用其他的命令或方法来查看大文件的,我们以后再来学习。
笔记:dev/null
在类 Unix 系统中,/dev/null 称空设备,是一个特殊的设备文件,它丢弃一切写入其中的数据(但报告写入操作成功),读取它则会立即得到一个 EOF。
而使用 cat $filename > /dev/null 则不会得到任何信息,因为我们将本来该通过标准输出显示的文件信息重定向到了 /dev/null 中。
使用 cat $filename 1 > /dev/null 也会得到同样的效果,因为默认重定向的 1 就是标准输出。 如果你对 shell 脚本或者重定向比较熟悉的话,应该会联想到 2 ,也即标准错误输出。
如果我们不想看到错误输出呢?我们可以禁止标准错误 cat $badname 2 > /dev/null。
grep(文本处理三剑客之一)
介绍
全拼:Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行.
grep 命令的由来可以追溯到 UNIX 诞生的早期,在 UNIX 系统中,搜索的模式(patterns)被称为正则表达式(regular expressions),为了要彻底搜索一个文件,有的用户在要搜索的字符串前加上前缀 global(全面的),一旦找到相匹配的内容,用户就像将其输出(print)到屏幕上,而将这一系列的操作整合到一起就是 global regular expressions print,而这也就是 grep 命令的全称。
格式
grep [options] [pattern] [file ...]
- 1
operations
-a --text # 不要忽略二进制数据。 -A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。 -b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。 -B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。 -c --count # 计算符合范本样式的列数。 -C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。 -d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。 -e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。 -E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。 -f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。 -F --fixed-regexp # 将范本样式视为固定字符串的列表。 -G --basic-regexp # 将范本样式视为普通的表示法来使用。 -h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。 -H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。 -i --ignore-case # 忽略字符大小写的差别。 -l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。 -L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。 -n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。 -P --perl-regexp # PATTERN 是一个 Perl 正则表达式 -q --quiet或–silent # 不显示任何信息。 -R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。 -s --no-messages # 不显示错误信息。 -v --revert-match # 反转查找。 -V --version # 显示版本信息。 -w --word-regexp # 只显示全字符合的列。 -x --line-regexp # 只显示全列符合的列。 -y # 此参数效果跟“-i”相同。 -o # 只输出文件中匹配到的部分。 -m --max-count= # 找到num行结果后停止查找,用来限制匹配行数

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
patten
详见正则表达式
实例
查找进程
> ps -ef | grep java
root 16934 1 0 Feb25 ? 00:12:23 java -jar demo.jar
root 6891 2151 0 21:42 pts/2 00:00:00 grep --color=auto java
- 1
- 2
- 3
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。补显示grep本身可使用
ps -ef | grep redis | grep -v grep
# 有两条命令
[root@ev003v ~]$ ps -aux|grep python
root 329 0.0 0.0 112828 984 pts/11 S+ 16:06 0:00 grep --color=auto python
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
#只剩下一条了
[root@ev003v ~]$ ps -aux|grep python|grep -v grep
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查找进程个数
> ps -ef | grep -c java
10
> ps -ef | grep java -c
10
- 1
- 2
- 3
- 4
查找文件关键词
> grep "linux" rumenz.txt
linux123
linuxxxx
// -n 显示行号
> grep -n "linux" rumenz.txt
6:linux123
7:linuxxxx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
从文件中读取关键词进行搜索
## k中是要搜寻的关键词
> cat rumenz.txt | grep -f k.txt
redis
linux123
linuxxxx
//显示行号
> cat rumenz.txt | grep -nf k.txt
5:redis
6:linux123
7:linuxxxx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
多文件找关键词
> grep "linux" rumenz.txt rumenz123.txt
rumenz.txt:linux123
rumenz.txt:linuxxxx
rumenz123.txt:linux123
rumenz123.txt:linuxxxx
rumenz123.txt:linux100
- 1
- 2
- 3
- 4
- 5
- 6
通配符文件搜索
// 查找当前目录下所有以rumenz开头的文件 > grep "linux" rumenz* rumenz123.txt:linux123 rumenz123.txt:linuxxxx rumenz123.txt:linux100 rumenz.txt:linux123 rumenz.txt:linuxxxx // 查找当前目录下所有以.txt结尾的文件 > grep "linux" *.txt k.txt:linux rumenz123.txt:linux123 rumenz123.txt:linuxxxx rumenz123.txt:linux100 rumenz.txt:linux123 rumenz.txt:linuxxxx ———————————————— 版权声明:本文为CSDN博主「入门小站」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_37335761/article/details/122682881
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在关键字的显示上,grep可以用—color=auto来将关键字用特殊颜色显示。但是每次使用grep都得加上这个信息很麻烦,于是可以用alias进行一下处理就OK了。
可以在~/.bashrc内加上这一行:alias grep=‘grep –color=auto’。
grep默认显示的似乎是一个段落(回车分割的内容),如果你想搜索,包含a,b的,
可以 xxx |grep a|grep b
more
more和cat有点区别,more用于分屏显示文件内容。可以用空格键向下翻页,b键向上翻页
more 命令可以分页显示文本文件的内容,使用者可以逐页阅读文件中内容,此命令的基本格式如下:
[root@localhost ~]# more [选项] 文件名
more 命令比较简单,一般不用什么选项,对于表 1 中所列的选项,读者只需看到认识即可。
选项 含义
-f 计算行数时,以实际的行数,而不是自动换行过后的行数。
-p 不以卷动的方式显示每一页,而是先清除屏幕后再显示内容。
-c 跟 -p 选项相似,不同的是先显示内容再清除其他旧资料。
-s 当遇到有连续两行以上的空白行时,就替换为一行的空白行。
-u 不显示下引号(根据环境变量 TERM 指定的终端而有所不同)。
+n 从第 n 行开始显示文件内容,n 代表数字。
-n 一次显示的行数,n 代表数字。
more 命令的执行会打开一个交互界面,因此读者有必要了解一些交互命令,常用的交互命令如表 2 所示。
交互指令 功能
h 或 ? 显示 more 命令交互命令帮助。
q 或 Q 退出 more。
v 在当前行启动一个编辑器。
:f 显示当前文件的文件名和行号。
!<命令> 或 :!<命令> 在子Shell中执行指定命令。
回车键 向下移动一行。
空格键 向下移动一页。
Ctrl+l 刷新屏幕。
= 显示当前行的行号。
’ 转到上一次搜索开始的地方。
Ctrf+f 向下滚动一页。
. 重复上次输入的命令。
/ 字符串 搜索指定的字符串。
d 向下移动半页。
b 向上移动一页。
【例 1】用分页的方式显示 anaconda-ks.cfg 文件的内容。
[root@localhost ~]# more anaconda-ks.cfg
# Kickstart file automatically generated by anaconda.
#version=DEVEL
install
cdrom
…省略部分内容…
–More–(69%)
#在这里执行交互命令即可
【例 2】显示文件 anaconda-ks.cfg 的内容,每 10 行显示一屏,同时清楚屏幕,使用以下命令:
[root@localhost ~]# more -c -10 anaconda-ks.cfg
#省略输出内容。
less
和more类似,less用于分行显示
less 命令的作用和 more 十分类似,都用来浏览文本文件中的内容,不同之处在于,使用 more 命令浏览文件内容时,只能不断向后翻看,而使用 less 命令浏览,既可以向后翻看,也可以向前翻看。
不仅如此,为了方面用户浏览文本内容,less 命令还提供了以下几个功能:
使用光标键可以在文本文件中前后(左后)滚屏;
用行号或百分比作为书签浏览文件;
提供更加友好的检索、高亮显示等操作;
兼容常用的字处理程序(如 Vim、Emacs)的键盘操作;
阅读到文件结束时,less 命令不会退出;
屏幕底部的信息提示更容易控制使用,而且提供了更多的信息。
less 命令的基本格式如下:
[root@localhost ~]# less [选项] 文件名
此命令可用的选项以及各自的含义如表 1 所示。
选项 选项含义
-N 显示每行的行号。
-S 行过长时将超出部分舍弃。
-e 当文件显示结束后,自动离开。
-g 只标志最后搜索到的关键同。
-Q 不使用警告音。
-i 忽略搜索时的大小写。
-m 显示类似 more 命令的百分比。
-f 强迫打开特殊文件,比如外围设备代号、目录和二进制文件。
-s 显示连续空行为一行。
-b <缓冲区大小> 设置缓冲区的大小。
-o <文件名> 将 less 输出的内容保存到指定文件中。
-x <数字> 将【Tab】键显示为规定的数字空格。
在使用 less 命令查看文件内容的过程中,和 more 命令一样,也会进入交互界面,因此需要读者掌握一些常用的交互指令,如表 2 所示。
交互指令 功能
/字符串 向下搜索“字符串”的功能。
?字符串 向上搜索“字符串”的功能。
n 重复*前一个搜索(与 / 成 ? 有关)。
N 反向重复前一个搜索(与 / 或 ? 有关)。
b 向上移动一页。
d 向下移动半页。
h 或 H 显示帮助界面。
q 或 Q 退出 less 命令。
y 向上移动一行。
空格键 向下移动一页。
回车键 向下移动一行。
【PgDn】键 向下移动一页。
【PgUp】键 向上移动一页。
Ctrl+f 向下移动一页。
Ctrl+b 向上移动一页。
Ctrl+d 向下移动一页。
Ctrl+u 向上移动半页。
j 向下移动一行。
k 向上移动一行。
G 移动至最后一行。
g 移动到第一行。
ZZ 退出 less 命令。
v 使用配置的编辑器编辑当前文件。
[ 移动到本文档的上一个节点。
] 移动到本文档的下一个节点。
p 移动到同级的上一个节点。
u 向上移动半页。
【例 1】使用 less 命令查看 /boot/grub/grub.cfg 文件中的内容。
[root@localhost ~]# less /boot/grub/grub.cfg
#
#DO NOT EDIT THIS FILE
#
#It is automatically generated by grub-mkconfig using templates from /etc/grub.d and settings from /etc/default/grub
#
### BEGIN /etc/grub.d/00_header ###
if [ -s
p
r
e
f
i
x
/
g
r
u
b
e
n
v
]
;
t
h
e
n
s
e
t
h
a
v
e
g
r
u
b
e
n
v
=
t
r
u
e
l
o
a
d
e
n
v
f
i
s
e
t
d
e
f
a
u
l
t
=
"
0
"
i
f
[
"
prefix/grubenv ]; then set have_grubenv=true load_env fi set default="0" if [ "
prefix/grubenv];thensethavegrubenv=trueloadenvfisetdefault="0"if[" {prev_saved_entry}" ]; then
set saved_entry=“${prev_saved_entry}”
save_env saved_entry
set prev_saved_entry= save_env prev_saved_entry
set boot_once=true
fi
function savedefault {
if [ -z “${boot_once}” ]; then
:
可以看到,less 在屏幕底部显示一个冒号(:),等待用户输入命令,比如说,用户想向下翻一页,可以按空格键;如果想向上翻一页,可以按 b 键。
tail与head
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail [参数] [文件]
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
tail notes.log # 默认显示最后 10 行
tail -f filename #会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
tail -n 100 /etc/cron #显示最后100行数据
tail -n +20 notes.log #显示文件 notes.log 的内容,从第 20 行至文件末尾
tail -fn 100 xx.log #查看最后的100行内容
- 1
- 2
- 3
- 4
- 5
head 命令可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。
#显示 notes.log 文件的开头 5 行,请输入以下命令:
head -n 5 runoob_notes.log #不输-n 默认10行
- 1
- 2
- 3
vim
可供选择的编辑器不止一种,例如 Vim、emacs、pico、nano 等,很多人都找到了自己所喜爱的编辑器。综合考虑各种因素,本套 Linux 教程建议初学者学习 Vim 文本编辑器。
Vim文本编辑器,是由 vi 发展演变过来的文本编辑器,因其具有使用简单、功能强大、是 Linux 众多发行版的默认文本编辑器等特点,成功圈住了很多人成为其死忠粉丝。
https://www.runoob.com/linux/linux-vim.html
注意
1vim中 鼠标下滑不一定管用 得键盘上下才能看到全部内容
2 vim直接粘贴可能不全 解决方法搜下
相信大家都使用过带图形界面的操作系统中的文字编辑器,用户可以使用鼠标来选择要操作的文本,非常方便。在 Vim 编辑器中也有类似的功能,但不是通过鼠标,而是通过键盘来选择要操作的文本。
在 Vim 中,如果想选中目标文本,就需要调整 Vim 进入可视化模式,如表 1 所示,通过在 Vim 命令模式下键入不同的键,可以进入不同的可视化模式。
sed-文本处理(三剑客之一)
逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
看到再说 https://developer.aliyun.com/article/910308?spm=a2c6h.13262185.profile.64.6f69961fYrL5Vd
awk(三剑客)
和 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
awk 命令的基本格式为:
[root@localhost ~]# awk [选项] ‘脚本命令’ 文件名
https://developer.aliyun.com/article/910315?spm=a2c6h.13262185.profile.62.6f69961fYrL5Vd
二、进程管理
操作系统会给每个进程分配一个 ID,称为 PID(进程 ID)。
在操作系统中,所有可以执行的程序与命令都会产生进程。只是有些程序和命令非常简单,如 ls 命令、touch 命令等,它们在执行完后就会结束,相应的进程也就会终结,所以我们很难捕捉到这些进程。但是还有一些程和命令,比如 httpd 进程,启动之后就会一直驻留在系统当中,我们把这样的进程称作常驻内存进程。
某些进程会产生一些新的进程,我们把这些进程称作子进程,而把这个进程本身称作父进程。比如,我们必须正常登录到 Shell 环境中才能执行系统命令,而 Linux 的标准 Shell 是 bash。我们在 bash 当中执行了 ls 命令,那么 bash 就是父进程,而 ls 命令是在 bash 进程中产生的进程,所以 ls 进程是 bash 进程的子进程。也就是说,子进程是依赖父进程而产生的,如果父进程不存在,那么子进程也不存在了。
值得一提的是 一般来说新进程都是由当前 Shell 这个进程产生的,换句话说,是 Shell 创建了新进程,于是称这种关系为进程间的父子关系,其中 Shell 是父进程,新进程是子进程。
值得一提的是,一个父进程可以有多个子进程,通常子进程结束后才能继续父进程;当然,如果是从后台启动,父进程就不用等待子进程了。
我们再来说说僵尸进程。僵尸进程的产生一般是由于进程非正常停止或程序编写错误,导致子进程先于父进程结束,而父进程又没有正确地回收子进程,从而造成子进程一直存在于内存当中,这就是僵尸进程。
僵尸进程会对主机的稳定性产生影响,所以,在产生僵尸进程后,一定要对产生僵尸进程的软件进行优化,避免一直产生僵尸进程;对于已经产生的僵尸进程,可以在查找出来之后强制中止。
启动进程的三种方式
前台启动进程
这是手工启动进程最常用的方式,因为当用户输入一个命令并运行,就已经启动了一个进程,而且是一个前台的进程,此时系统其实已经处于一个多进程的状态(一个是 Shell 进程,另一个是新启动的进程)。
实际上,系统自动时就有许多进程悄悄地在后台运行,不过这里为了方便读者理解,并没有将这些进程包括在内。
假如启动一个比较耗时的进程,然后再把该进程挂起,并使用 ps 命令查看,就会看到该进程在 ps 显示列表中,例如:
[root@localhost ~]# find / -name demo.jpg <--在根目录下查找 demo.jpg 文件,比较耗时
#此处省略了该命令的部分输出信息
#按“CTRL+Z”组合键,即可将该进程挂起
[root@localhost ~]# ps <--查看正在运行的进程
PID TTY TIME CMD
2573 pts/0 00:00:00 bash
2587 pts/0 00:00:01 find
2588 pts/0 00:00:00 ps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将进程挂起,指的是将前台运行的进程放到后台,并且暂停其运行,有关挂起进程和 ps 命令用法,后续章节会做详细介绍。
通过运行 ps 命令查看进程信息,可以看到,刚刚执行的 find 命令的进程号为 2587,同时 ps 进程的进程号为 2588。
后台启动进程
进程直接从后台运行,用的相对较少,除非该进程非常耗时,且用户也不急着需要其运行结果的时候,例如,用户需要启动一个需要长时间运行的格式化文本文件的进程,为了不使整个 Shell 在格式化过程中都处于“被占用”状态,从后台启动这个进程是比较明智的选择。
从后台启动进程,其实就是在命令结尾处添加一个 " &" 符号(注意,& 前面有空格)。输入命令并运行之后,Shell 会提供给我们一个数字,此数字就是该进程的进程号。然后直接就会出现提示符,用户就可以继续完成其他工作,例如:
[root@localhost ~]# find / -name install.log &
[1] 1920
#[1]是工作号,1920是进程号
- 1
- 2
- 3
有关后台启动进程及相关的注意事项,后续章节会做详细介绍。
调度启动
在 Linux 系统中,任务可以被配置在指定的时间、日期或者系统平均负载量低于指定值时自动启动。
例如,Linux 预配置了重要系统任务的运行,以便可以使系统能够实时被更新,系统管理员也可以使用自动化的任务来定期对重要数据进行备份。
实现调度启动进程的方法有很多,例如通过 crontab、at 等命令,有关这些命令的具体用法,本章后续章节会做详细介绍。
进程优先级与nice命令
Linux 是一个多用户、多任务的操作系统,系统中通常运行着非常多的进程。但是 CPU 在一个时钟周期内只能运算一条指令(现在的 CPU 采用了多线程、多核心技术,所以在一个时钟周期内可以运算多条指令。 但是同时运算的指令数也远远小于系统中的进程总数),那问题来了:谁应该先运算,谁应该后运算呢?这就需要由进程的优先级来决定了。
另外,CPU 在运算数据时,不是把一个集成算完成,再进行下一个进程的运算,而是先运算进程 1,再运算进程 2,接下来运算进程 3,然后再运算进程 1,直到进程任务结束。不仅如此,由于进程优先级的存在,进程并不是依次运算的,而是哪个进程的优先级高,哪个进程会在一次运算循环中被更多次地运算。
这样说很难理解,我们换一种说法。假设我现在有 4 个孩子(进程)需要喂饭(运算),我更喜欢孩子 1(进程 1 优先级更高),孩子 2、孩子 3 和孩子 4 一视同仁(进程 2、进程 3 和进程 4 的优先级一致)。现在我开始喂饭了,我不能先把孩子 1 喂饱,再喂其他的孩子,而是需要循环喂饭(CPU 运算时所有进程循环运算)。那么,我在喂饭时(运算),会先喂孩子 1 一口饭,然后再去喂其他孩子。而且在一次循环中,先喂孩子 1 两口饭,因为我更喜欢孩子 1(优先级高),而喂其他的孩子一口饭。这样,孩子 1 会先吃饱(进程 1 运算得更快),因为我更喜欢孩子 1。
在 Linux 系统中,表示进程优先级的有两个参数:Priority 和 Nice。还记得 “ps -le” 命令吗?
[root@localhost ~]# ps -le
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 80 0 - 718 - ? 00:00:01 init
1 S 0 2 0 0 80 0 - 0 - ? 00:00:00 kthreadd
...省略部分输出...
- 1
- 2
- 3
- 4
- 5
其中,PRI 代表 Priority,NI 代表 Nice。这两个值都表示优先级,数值越小代表该进程越优先被 CPU 处理。不过,PRI值是由内核动态调整的,用户不能直接修改。所以我们只能通过修改 NI 值来影响 PRI 值,间接地调整进程优先级。
PRI 和 NI 的关系如下:
PRI (最终值) = PRI (原始值) + NI
其实,大家只需要记得,我们修改 NI 的值就可以改变进程的优先级即可。NI 值越小,进程的 PRI 就会降低,该进程就越优先被 CPU 处理;反之,NI 值越大,进程的 PRI 值就会増加,该进程就越靠后被 CPU 处理。
修改 NI 值时有几个注意事项:
NI 范围是 -20~19。
普通用户调整 NI 值的范围是 0~19,而且只能调整自己的进程。
普通用户只能调高 NI 值,而不能降低。如原本 NI 值为 0,则只能调整为大于 0。
只有 root 用户才能设定进程 NI 值为负值,而且可以调整任何用户的进程。
PS
ps (英文全拼:process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器。
ps 命令有多种不同的使用方法,这常常给初学者带来困惑。在各种 Linux 论坛上,询问 ps 命令语法的帖子屡见不鲜,而出现这样的情况,还要归咎于 UNIX 悠久的历史和庞大的派系。在不同的 Linux 发行版上,ps 命令的语法各不相同,为此,Linux 采取了一个折中的方法,即融合各种不同的风格,兼顾那些已经习惯了其它系统上使用 ps 命令的用户。
ps 命令的基本格式如下:
#查看系统中所有的进程,使用 BS 操作系统格式
[root@localhost ~]# ps aux
#查看系统中所有的进程,使用 Linux 标准命令格式
[root@localhost ~]# ps -le
- 1
- 2
- 3
- 4
ps [options] [--help]
- 1
选项:
a:显示一个终端的所有进程,除会话引线外;
u:显示进程的归属用户及内存的使用情况;
x:显示没有控制终端的进程;
-l:长格式显示更加详细的信息;
-e:显示所有进程;
- 1
- 2
- 3
- 4
- 5
可以看到,ps 命令有些与众不同,它的部分选项不能加入"-“,比如命令"ps aux”,其中"aux"是选项,但是前面不能带“-”。
大家如果执行 “man ps” 命令,则会发现 ps 命令的帮助为了适应不同的类 UNIX 系统,可用格式非常多,不方便记忆。所以,我建议大家记忆几个固定选项即可。比如下面的三个足以
ps 默认显示前台进程
ps aux 可以查看系统中所有的进程;
ps -le 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级;
ps -l 只能看到当前 Shell(或者说当前登录) 产生的进程;
- 1
- 2
- 3
- 4
只用ps 即使加了-a 也不会显示全部进程 要显示全部进程要加-e参数 -f用于显示详细信息(这个不是unix风格 是linux风格的命令吧)
USER PID %CPU %MEM VSZ(虚拟内存占用) RSS(记忆体 物理内存大小) TTY STAT(该行程的状态:) START TIME COMMAND(所执行的指令)
- 1
| 表头 | 含义 |
|---|---|
| USER | 该进程是由哪个用户产生的。 |
| PID | 进程的 ID。 |
| %CPU | 该进程占用 CPU 资源的百分比,占用的百分比越高,进程越耗费资源。 |
| %MEM | 该进程占用物理内存的百分比,占用的百分比越高,进程越耗费资源。 |
| VSZ | 该进程占用虚拟内存的大小,单位为 KB。 |
| RSS | 该进程占用实际物理内存的大小,单位为 KB。 |
| TTY | 该进程是在哪个终端运行的。其中,tty1 ~ tty7 代表本地控制台终端(可以通过 Alt+F1 ~ F7 快捷键切换不同的终端),tty1~tty6 是本地的字符界面终端,tty7 是图形终端。pts/0 ~ 255 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。 |
| STAT | 进程状态。常见的状态有以下几种:
|
| START | 该进程的启动时间。 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间。 |
| COMMAND | 产生此进程的命令名。 |
实例
ps -ef | grep 进程关键字 (最后一个进程是grep本身)
- 1
显示进程信息 ps -A
ps -u root //显示root进程用户信息
ps -ef //显示所有命令,连带命令行
top
ps 命令可以一次性给出当前系统中进程状态,但使用此方式得到的信息缺乏时效性,并且,如果管理员需要实时监控进程运行情况,就必须不停地执行 ps 命令,这显然是缺乏效率的。
为此,Linux 提供了 top 命令。top 命令可以动态地持续监听进程地运行状态,与此同时,该命令还提供了一个交互界面,用户可以根据需要,人性化地定制自己的输出,进而更清楚地了进程的运行状态。
top 命令的基本格式如下:
[root@localhost ~]#top [选项]
- 1
选项:
-d 秒数:指定 top 命令每隔几秒更新。默认是 3 秒;
-b:使用批处理模式输出。一般和"-n"选项合用,用于把 top 命令重定向到文件中;
-n 次数:指定 top 命令执行的次数。一般和"-"选项合用;
-p 进程PID:仅查看指定 ID 的进程;
-s:使 top 命令在安全模式中运行,避免在交互模式中出现错误;
-u 用户名:只监听某个用户的进程;
- 1
- 2
- 3
- 4
- 5
- 6
在 top 命令的显示窗口中,还可以使用如下按键,进行一下交互操作:
? 或 h:显示交互模式的帮助;
P:按照 CPU 的使用率排序,默认就是此选项;
M:按照内存的使用率排序;
N:按照 PID 排序;
T:按照 CPU 的累积运算时间排序,也就是按照 TIME+ 项排序;
k:按照 PID 给予某个进程一个信号。一般用于中止某个进程,信号 9 是强制中止的信号;
r:按照 PID 给某个进程重设优先级(Nice)值;
q:退出 top 命令;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[root@localhost ~]# top
top - 12:26:46 up 1 day, 13:32, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.7%id, 0.1%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 625344k total, 571504k used, 53840k free, 65800k buffers
Swap: 524280k total, 0k used, 524280k free, 409280k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19002 root 20 0 2656 1068 856 R 0.3 0.2 0:01.87 top
1 root 20 0 2872 1416 1200 S 0.0 0.2 0:02.55 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
····
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第一部分是前五行,显示的是整个系统的资源使用状况,我们就是通过这些输出来判断服务器的资源使用状态的;
第二部分从第六行开始,显示的是系统中进程的信息
第二行为进程信息
| 内 容 | 说 明 |
|---|---|
| Tasks: 95 total | 系统中的进程总数 |
| 1 running | 正在运行的进程数 |
| 94 sleeping | 睡眠的进程数 |
| 0 stopped | 正在停止的进程数 |
| 0 zombie | 僵尸进程数。如果不是 0,则需要手工检查僵尸进程 |
其他的 比如cpu啥的 看http://c.biancheng.net/view/1065.html
我们通过 top 命令的第一部分就可以判断服务器的健康状态。如果 1 分钟、5 分钟、15 分钟的平均负载高于 1,则证明系统压力较大。如果 CPU 的使用率过高或空闲率过低,则证明系统压力较大。如果物理内存的空闲内存过小,则也证明系统压力较大。
这时,我们就应该判断是什么进程占用了系统资源。如果是不必要的进程,就应该结束这些进程;如果是必需进程,那么我们该増加服务器资源(比如増加虚拟机内存),或者建立集群服务器。
我们还要解释一下缓冲(buffer)和缓存(cache)的区别:
- 缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取。
- 缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
实例
top 命令如果不正确退出,则会持续运行。在 top 命令的交互界面中按 “q” 键会退出 top 命令;也可以按 “?” 或 “h” 键得到 top 命令交互界面的帮助信息;还可以按键中止某个进程。
【例 5】如果在操作终端执行 top 命令,则并不能看到系统中所有的进程,默认看到的只是 CPU 占比靠前的进程。如果我们想要看到所有的进程,则可以把 top 命令的执行结果重定向到文件中。不过 top 命令是持续运行的,这时就需要使用 “-b” 和 “-n” 选项了。具体命令如下:
[root@localhost ~]# top -b -n 1 > /root/top.log
#让top命令只执行一次,然后把执行结果保存到top.log文件中,这样就能看到所有的进程了
pstree
pstree 命令是以树形结构显示程序和进程之间的关系(父子等)
lsof
我们知道,通过 ps 命令可以查询到系统中所有的进程,那么,是否可以进一步知道这个进程到底在调用哪些文件吗?当然可以,使用 lsof 命令即可。
lsof 命令,“list opened files”的缩写,直译过来,就是列举系统中已经被打开的文件。通过 lsof 命令,我们就可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。
kill与信号量(进程间通信)
这是进程管理中最不常用的手段。当需要停止服务时,会通过正确关闭命令来停止服务(如 apache 服务可以通过 service httpd stop 命令来关闭)。只有在正确终止进程的手段失效的情况下,才会考虑使用 kill 命令杀死进程。
kill [-s <信息名称或编号>][程序] 或 kill [-l <信息编号>]
- 1
-l <信息编号> 若不加<信息编号>选项,则 -l 参数会列出全部的信息名称。
-s <信息名称或编号> 指定要送出的信息。
[程序] [程序]可以是程序的PID或是PGID,也可以是工作编号
使用 kill -l 命令列出所有可用信号。
最常用的信号是:
1 (HUP):重新加载进程。
9 (KILL):杀死一个进程。
15 (TERM):正常停止一个进程。
- 1
- 2
- 3
# 杀死进程
kill 12345
#强制杀死进程
kill -KILL 123456
#发送SIGHUP信号,可以使用一下信号
kill -HUP pid
#彻底杀死进程
kill -9 123456
#杀死指定用户所有进程
kill -9 $(ps -ef | grep hnlinux) //方法一 过滤出hnlinux用户进程
kill -u hnlinux //方法二
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
linux 的 kill 命令是向进程发送信号,kill 不是杀死的意思,-9 表示无条件退出,但由进程自行决定是否退出,这就是为什么 kill -9 终止不了系统进程和守护进程的原因。
killall命令:终止特定的一类进程
killall 也是用于关闭进程的一个命令,但和 kill 不同的是,killall 命令不再依靠 PID 来杀死单个进程,而是通过程序的进程名来杀死一类进程,也正是由于这一点,该命令常与 ps、pstree 等命令配合使用。
killall 命令的基本格式如下:
[root@localhost ~]# killall [选项] [信号] 进程名
- 1
注意,此命令的信号类型同 kill 命令一样,因此这里不再赘述,此命令常用的选项有如下 2 个:
-i:交互式,询问是否要杀死某个进程;
-I:忽略进程名的大小写;
接下来,给大家举几个例子。
【例 1】杀死 httpd 进程。
[root@localhost ~]# service httpd start
#启动RPM包默认安装的apache服务
[root@localhost ~]# ps aux | grep “httpd” | grep -v “grep”
root 1600 0.0 0.2 4520 1696? Ss 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1601 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1602 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1603 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1604 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1605 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
#查看httpd进程
[root@localhost ~]# killall httpd
#杀死所有进程名是httpd的进程
[root@localhost ~]# ps aux | grep “httpd” | grep -v “grep”
#查询发现所有的httpd进程都消失了
【例 2】交互式杀死 sshd 进程。
[root@localhost ~]# ps aux | grep “sshd” | grep -v “grep”
root 1733 0.0 0.1 8508 1008? Ss 19:47 0:00/usr/sbin/sshd
root 1735 0.1 0.5 11452 3296? Ss 19:47 0:00 sshd: root@pts/0
root 1758 0.1 0.5 11452 3296? Ss 19:47 0:00 sshd: root@pts/1
#查询系统中有3个sshd进程。1733是sshd服务的进程,1735和1758是两个远程连接的进程
[root@localhost ~]# killall -i sshd
#交互式杀死sshd进程
杀死sshd(1733)?(y/N)n
#这个进程是sshd的服务进程,如果杀死,那么所有的sshd连接都不能登陆
杀死 sshd(1735)?(y/N)n
#这是当前登录终端,不能杀死我自己吧
杀死 sshd(1758)?(y/N)y
#杀死另一个sshd登陆终端
pkill命令:终止进程,按终端号踢出用户
后台基本管理原理与命令
工作管理指的是在单个登录终端(也就是登录的 Shell 界面)同时管理多个工作的行为。也就是说,我们登陆了一个终端,已经在执行一个操作,那么是否可以在不关闭当前操作的情况下执行其他操作呢?
当然可以,我们可以再启动一个终端,然后执行其他的操作。不过,是否可以在一个终端执行不同的操作呢?这就需要通过工作管理来实现了。
例如,我在当前终端正在 vi 一个文件,在不停止 vi 的情况下,如果我想在同一个终端执行其他的命令,就应该把 vi 命令放入后台,然后再执行其他命令。把命令放入后台,然后把命令恢复到前台,或者让命令恢复到后台执行,这些管理操作就是工作管理。
后台管理有几个事项需要大家注意:
前台是指当前可以操控和执行命令的这个操作环境;后台是指工作可以自行运行,但是不能直接用 Ctrl+C 快捷键来中止它,只能使用 fg/bg 来调用工作。
当前的登录终端只能管理当前终端的工作,而不能管理其他登录终端的工作。比如 tty1 登录的终端是不能管理 tty2 终端中的工作的。
放入后台的命令必须可以持续运行一段时间,这样我们才能捕捉和操作它。
放入后台执行的命令不能和前台用户有交互或需要前台输入,否则只能放入后台暂停,而不能执行。比如 vi 命令只能放入后台暂停,而不能执行,因为 vi 命令需要前台输入信息;top 命令也不能放入后台执行,而只能放入后台暂停,因为 top 命令需要和前台交互。
命令放入后台运行方法(&和Ctrl+Z)
Linux 命令放入后台的方法有两种,分别介绍如下。
“命令 &”,把命令放入后台执行
第一种把命令放入后台的方法是在命令后面加入 空格 &。使用这种方法放入后台的命令,在后台处于执行状态。
注意,放入后台执行的命令不能与前台有交互,否则这个命令是不能在后台执行的。例如:
[root@localhost ~]#find / -name install.log &
[1] 1920
#[工作号] 进程号
#把find命令放入后台执行,每个后台命令会被分配一个工作号。命令既然可以执行,就会有进程产生,所以也会有进程号
这样,虽然 find 命令在执行,但在当前终端仍然可以执行其他操作。如果在终端上出现如下信息:
[1]+ Done find / -name install.log
则证明后台的这个命令已经完成了。当然,命令如果有执行结果,则也会显示到操作终端上。其中,[1] 是这个命令的工作号,"+"代表这个命令是最近一个被放入后台的。
命令执行过裎中按 Ctrl+Z 快捷键,命令在后台处于暂停状态
使用这种方法放入后台的命令,就算不和前台有交互,能在后台执行,也处于暂停状态,因为 Ctrl+Z 快捷键就是暂停的快捷键。
【例 1】
[root@localhost ~]#top
#在top命令执行的过程中,按下Ctrl+Z快捷键
[1]+ Stopped top
#top命令被放入后台,工作号是1,状态是暂停。而且,虽然top命令没有结束,但也能取得控制台权限
【例 2】
[root@localhost ~]# tar -zcf etc.tar.gz /etc
#压缩一下/etc/目录
tar:从成员名中删除开头的"/"
tar:从硬链接目标中删除开头的"/"
^Z
#在执行过程中,按下Ctrl+Z快捷键
[2]+ Stopped tar-zcf etc.tar.gz/etc
#tar命令被放入后台,工作号是2,状态是暂停
每个被放入后台的命令都会被分配一个工作号。第一个被放入后台的命令,工作号是 1;第二个被放入后台的命令,工作号是 2,以此类推。
jobs命令:查看当前终端放入后台的工作
jobs 命令可以用来查看当前终端放入后台的工作,工作管理的名字也来源于 jobs 命令。
jobs 命令的基本格式如下:
[root@localhost ~]#jobs [选项]
表 1 罗列了 jobs 命令常用的选项及含义。
表 1 jobs 命令常用选项及含义、
| 选项 | 含义 |
|---|---|
| -l | (L 的小写) 列出进程的 PID 号。 |
| -n | 只列出上次发出通知后改变了状态的进程。 |
| -p | 只列出进程的 PID 号。 |
| -r | 只列出运行中的进程。 |
| -s | 只列出已停止的进程。 |
| 例如: |
[root@localhost ~]#jobs -l
[1]- 2023 Stopped top
[2]+ 2034 Stopped tar -zcf etc.tar.gz /etc
- 1
- 2
- 3
可以看到,当前终端有两个后台工作:一个是 top 命令,工作号为 1,状态是暂停,标志是"-“;另一个是 tar 命令,工作号为 2,状态是暂停,标志是”+“。”+“号代表最近一个放入后台的工作,也是工作恢复时默认恢复的工作。”-"号代表倒数第二个放入后台的工作,而第三个以后的工作就没有"±"标志了。
一旦当前的默认工作处理完成,则带减号的工作就会自动成为新的默认工作,换句话说,不管此时有多少正在运行的工作,任何时间都会有且仅有一个带加号的工作和一个带减号的工作。
fg命令:把后台命令恢复在前台执行
前面所讲,都是将工作丢到后台去运行,那么,有没有可以将后台工作拿到前台来执行的办法呢?答案是肯定的,使用 fg 命令即可。
fg 命令用于把后台工作恢复到前台执行,该命令的基本格式如下:
[root@localhost ~]#fg %工作号
注意,在使用此命令时,% 可以省略,但若将% 工作号全部省略,则此命令会将带有 + 号的工作恢复到前台。另外,使用此命令的过程中, % 可有可无。
例如:
[root@localhost ~]#jobs
[1]- Stopped top
[2]+ Stopped tar-zcf etc.tar.gz/etc
[root@localhost ~]# fg
#恢复“+”标志的工作,也就是tar命令
[root@localhost ~]# fg %1
#恢复1号工作,也就是top命令
- 1
- 2
- 3
- 4
- 5
- 6
- 7
top 命令是不能在后台执行的,所以,如果要想中止 top 命令,要么把 top 命令恢复到前台,然后正常退出;要么找到 top 命令的 PID,使用 kill 命令杀死这个进程。
bg命令:把后台暂停的工作恢复到后台执行
nohup命令:后台命令脱离终端运行
在前面章节中,我们一直在说进程可以放到后台运行,这里的后台,其实指的是当前登陆终端的后台。这种情况下,当我们以远程管理服务器的方式,在远程终端执行后台命令,如果在命令尚未执行完毕时就退出登陆,那么这个后台命令还会继续执行吗?
当然不会,此命令的执行会被中断。这就引出一个问题,如果我们确实需要在远程终端执行某些后台命令,该如何执行呢?有以下 3 种方法:
把需要在后台执行的命令加入 /etc/rc.local 文件,让系统在启动时执行这个后台程序。这种方法的问题是,服务器是不能随便重启的,如果有临时后台任务,就不能执行了。
使用系统定时任务,让系统在指定的时间执行某个后台命令。这样放入后台的命令与终端无关,是不依赖登录终端的。
使用 nohup 命令。
本节重点讲解 nohup 命令的用法。nohup 命令的作用就是让后台工作在离开操作终端时,也能够正确地在后台执行。此命令的基本格式如下:
[root@localhost ~]# nohup [命令] &
注意,这里的‘&’表示此命令会在终端后台工作;反之,如果没有‘&’,则表示此命令会在终端前台工作。
例如:
[root@localhost ~]# nohup find / -print > /root/file.log &
[3] 2349
#使用find命令,打印/下的所有文件。放入后台执行
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
#有提示信息
接下来的操作要迅速,否则 find 命令就会执行结束。然后我们可以退出登录,重新登录之后,执行“ps aux”命令,会发现 find 命令还在运行。
如果 find 命令执行太快,我们就可以写一个循环脚本,然后使用 nohup 命令执行。例如:
[root@localhost ~]# vi for.sh
#!/bin/bash
for ((i=0;i<=1000;i=i+1))
#循环1000次
do
echo 11 >> /root/for.log
#在for.log文件中写入11
sleep 10s
#每次循环睡眠10秒
done
[root@localhost ~]# chmod 755 for.sh
[root@localhost ~]# nohup /root/for.sh &
[1] 2478
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
#执行脚本
接下来退出登录,重新登录之后,这个脚本仍然可以通过“ps aux”命令看到。
others
12.19 Linux定时执行任务(at命令)
12.20 Linux循环执行定时任务(crontab命令)
12.21 Linux检测长期未执行的定时任务(anacron命令)
12.25 Linux查看登陆用户信息(w和who命令)
12.26 Linux查看过去登陆的用户信息(last和lastlog命令)
源码包服务的启动管理
源码包服务的启动管理
源码包服务中所有的文件都会安装到指定目录当中,并且没有任何垃圾文件产生(Linux 的特性),所以服务的管理脚本程序也会安装到指定目录中。源码包服务的启动管理方式就是在服务的安装目录中找到管理脚本,然后执行这个脚本。
问题来了,每个服务的启动脚本都是不一样的,我们怎么确定每个服务的启动脚本呢?还记得在安装源码包服务时,我们强调需要査看每个服务的说明文档吗(一般是 INSTALL 或 READEM)?在这个说明文档中会明确地告诉大家服务的启动脚本是哪个文件。
我们用 apache 服务来举例。一般 apache 服务的安装位置是 /usr/local/apache2/ 目录,那么 apache 服务的启动脚本就是 /usr/local/apache2/bin/apachectl 文件(查询 apache 说明文档得知)。启动命令如下:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start|stop|restart|…
#源码包服务的启动管理
例如:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start
#会启动源码包安装的apache服务
注意,不管是源码包安装的 apache,还是 RPM 包默认安装的 apache,虽然在一台服务器中都可以安装,但是只能启动一因为它们都会占用 80 端口。
源码包服务的启动方法就这一种,比 RPM 包默认安装的服务要简单一些。
源码包服务的自启动管理
源码包服务的白启动管理也不能依靠系统的服务管理命令,而只能把标准启动命令写入 /etc/rc.d/rc.local 文件中。系统在启动过程中读取 /etc/rc.d/rc.local 文件时,就会调用源码包服务的启动脚本,从而让该服务开机自启动。命令如下:
[root@localhost ~]# vi /etc/rc.d/rc.local
#修改自启动文件
#!/bin/sh
#This script will be executed after all the other init scripts.
#You can put your own initialization stuff in here if you don11
#want to do the full Sys V style init stuff.
touch /var/lock/subsys/local /usr/local/apache2/bin/apachectl start
#加入源码包服务的标准启动命令,保存退出,源码包安装的apache服务就被设为自启动了
让源码包服务被服务管理命令识别
在默认情况下,源码包服务是不能被系统的服务管理命令所识别和管理的,但是如果我们做一些设定,则也是可以让源码包服务被系统的服务管理命令所识别和管理的。不过笔者并不推荐大家这样做,因为这会让本来区别很明确的源码包服务和 RPM 包服务变得容易混淆,不利于系统维护和管理。
我们做一个实验,看看如何把源码包安装的 apache 服务变为和 RPM 包默认安装的 apache 服务一样,可以被 service、chkconfig、ntsysv 命令所识别。实验如下:
- 卸载RPM包默认安装的apache服务
[root@localhost ~]# yum -y remove httpd
#卸载RPM包默认安装的apache服务,避免对实验产生影响(在生产服务器上慎用yum卸载,因为这有可能造成服务器崩溃)
[root@localhost ~]# service httpd start httpd:未被识别的服务
#因为服务被卸载,所以service命令不能识别httpd服务 - 安装源码包的apache服务,并启动
#安装源码包的apache服务
[root@localhost ~]# /usr/local/apache2/bin/apachect1 start
[root@localhost ~]# netstat -tlun | grep 80
tcp 0 0 :::80 ::声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/404222


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

