
- 1PyCharm安装教程和激活详细讲解(全网最快捷、最靠谱的方式)_pycharm激活
- 2VSCode断点调试(ROS)
- 3ERROR: Cannot determine archive format of C:\Users\hello\AppData\Local\Temp\pip-req-build-cz2gbroe
- 4sherpa-ncnn 参数介绍_sherpa_ncnn
- 5常见的SQL面试题:经典50例,java面试项目经验_java sql案例面试题
- 6STM32 HAL库 ADC配置_hal_statustypedef hal_adc_pollforconversion(adc_ha
- 7大数据StarRocks(一) StarRocks概述
- 8如何学习C++?_c++怎么学
- 9使用matplotlib绘制图标时,图例plt.legend()的使用_plt.legend()参数功能
- 10后端开发为什么选择Go语言:了解Go的优势和适用场景_go 语言 优势及 主要用途
重磅丨国产数据库到底行不行?人大金仓KINGBASE数据库与主流开源数据库性能实测...
赞
踩

近年来,人大金仓的数据库产品受到了外界诸多的关注。做产品,免不了要接受用户的对比和选择,数据库因其行业的自身特点,还有很多开源的技术产品同台比拼,用户因此也会产生诸多疑问,国产数据库相比开源数据库到底如何,今天我们选择数据库的一项核心能力——性能,将金仓KingbaseES和目前业界主流的两种开源数据库MySQL、PostgreSQL进行该能力层面的对比,以期为用户创造更丰富、公平的视角来解读国产数据库当前的发展现状。
为了更易理解和比较,我们采用数据库业界性能评测常用的标准模型TPCC,分别对MySQL、PostgreSQL、KingbaseES在同一环境下进行测试,并对其进行全面极致调优,进而对比其最终的性能表现。TPCC主要用于评测数据库的联机交易处理(偏向OLTP能力),这类系统具有比较鲜明的特点,这些特点主要表现如下:
1、多种事务处理并发执行,充分体现了事务处理的复杂性;
2、在线与离线的事务执行模式;
3、多个在线会话终端;
4、适中的系统运行时间和应用程序运行时间;
5、大量的磁盘I/O数据流;
6、强调事务的完整性要求(ACID);
7、对于非一致的数据库分布,使用主键和从键进行访问;
8、数据库由许多大小不一、属性多样,而又相互关联的数据表组成;
9、存在较多数据访问和更新之间的资源争夺。
采用的测试环境、测试工具和选测版本如下:
硬件配置
类型 | 配置 |
数据库服务器 | CPU:56核,Intel(R) Xeon(R) Platinum 8280L CPU @ 2.60GHz 内存:187GB 磁盘:1*500GB SSD,2*2T NVMe 操作系统:CentOS Linux release 7.5.1804 (Core) |
选测的软件版本及采用的测试工具
软件 | 版本 |
MySQL | 8.0.26 |
PostgreSQL | 13.1 |
KingbaseES | V8R6 |
BenchmarkSQL(测试工具) | 5.0 |
壹
MySQL、PostgreSQL、KingbaseES
调优及评测
我们对MySQL、PostgreSQL、KingbaseES这3个数据库在实际运行中反映出的性能问题,均进行相关性能瓶颈分析,并采用了针对性的调优手段,以使其能够展现最优的性能表现。
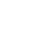
01
MySQL调优及评测
优化1,调整IO相关配置
分析:初始默认配置下,CPU利用率只有45%左右,大概在8万TPMC,通过分析资源等待情况,判断是IO问题。
优化点:增加数据文件、日志文件的缓存大小,增加配置如下:
key_buffer_size=2G max_allowed_packet=5G read_buffer_size=2G read_rnd_buffer_size=2G sort_buffer_size=2G join_buffer_size=2G net_buffer_length=5G tmp_table_size=16G thread-cache-size =100 innodb-thread-sleep-delay=0 |
效果:通过增加缓存优化了磁盘读写数据,性能提升两倍。
优化2:缓解binlog资源等待
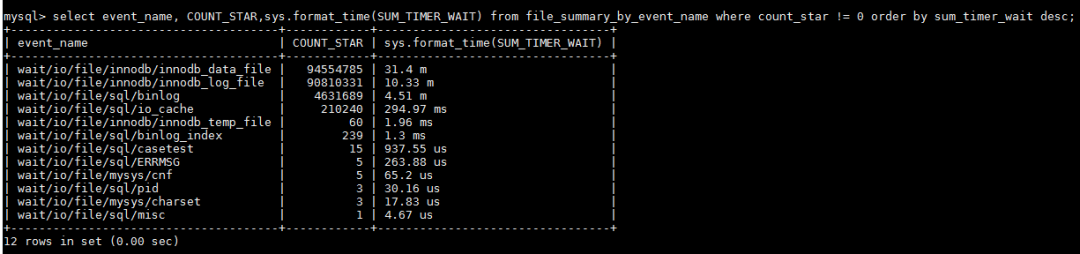
分析:再次观察系统资源情况,CPU利用率上升到50%左右,IO和网络没有压力,怀疑关键瓶颈是数据库内部的资源等待。检查MySQL当前等待事件:
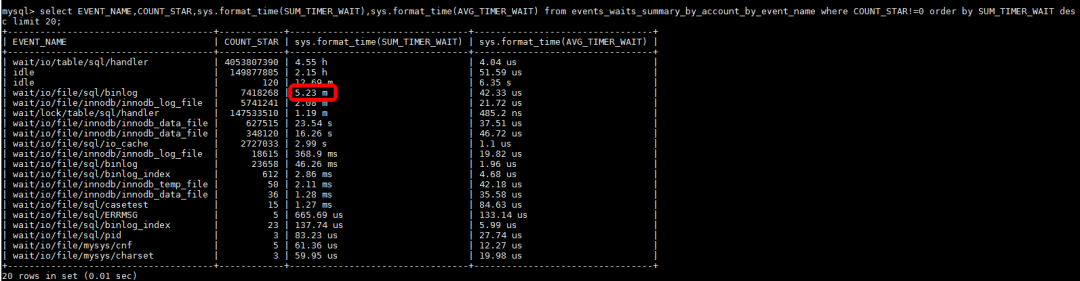
发现等待事件中最长的是binlog,虽然其时间比例在总时间中占比较低,但是数据库内部的等待视图看不到其他明显的问题,所以我们决定调整binlog相关的配置。
优化点:基于上述分析,我们将binglog设置为异步刷新,并且将日志级别设置为row来降低写入量。
效果:执行测试后重新检查等待事件,binlog等待已得到明显改善,tpmC也有了一定的提升。
优化3:自旋锁优化
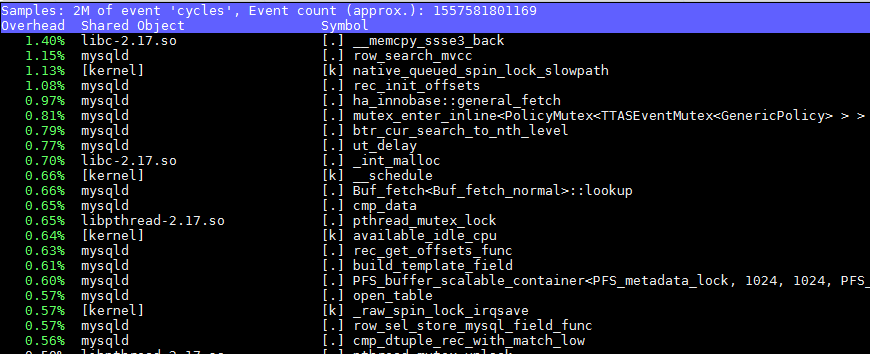
分析:再次观察系统资源情况,CPU利用率依然在50%左右,IO和网络没有压力,怀疑关键瓶颈是数据库内部的资源等待。但是数据库内部的等待事件列表已经看不出明显的问题,我们转而通过perf来继续查找根因,发现存在ut_delay的热点函数,所以判断是自旋锁相关的使用存在问题:

优化:重新调整自旋锁相关的delay以及loops等参数。
innodb-spin-wait-delay=2 innodb-sync-array-size=1024 innodb-sync-spin-loops=30 innodb-spin-wait-pause-multiplier=5 innodb-log-spin-cpu-pct-hwm=100 innodb-log-spin-cpu-abs-lwm=100 |
效果:再次测试后发现,ut_delay的热点函数已经消失,tpmc有了大幅提升。
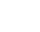
02
PostgreSQL调优及评测
针对PostgreSQL主要采用了调优手段:
优化1,调整IO相关配置
分析:观察系统资源使用情况,发现有大量磁盘IO事件。当前磁盘读写已成为制约系统性能的首要瓶颈,考虑通过增大共享内存的方式尽量将数据放入内存中进行操作以减小磁盘IO压力。
优化点:增加系统缓存,调整参数配置如下
shared_buffers = 60GB work_mem = 1GB maintenance_work_mem = 2GB |
效果:TPCC性能指标大幅提升,IO已不再是系统瓶颈。测试过程nmon性能统计:
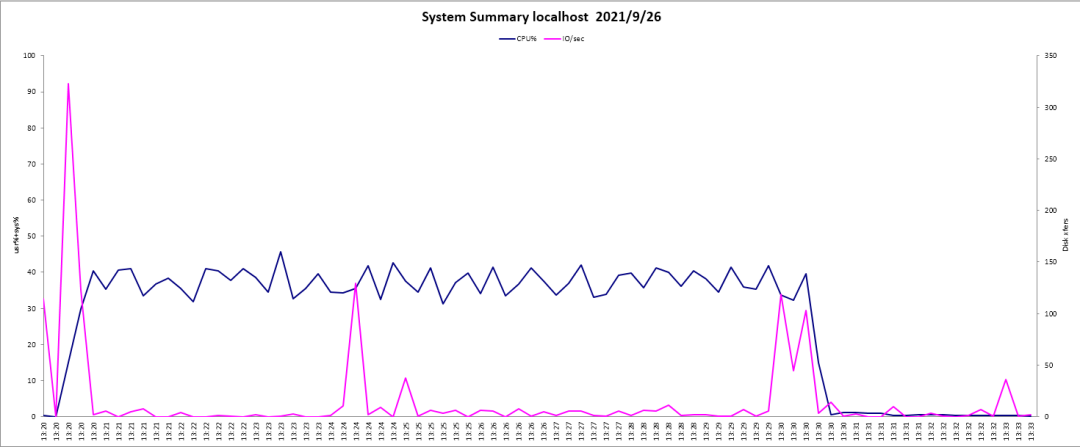
优化2,commit事务提交优化
分析:观察此时系统资源使用情况,磁盘使用率较高,依然存在优化空间
优化点:优化commit提交。PostgreSQL提供了两个参数commit_delay,commit_siblings。commit_delay是事务提交和日志刷盘的时间间隔。并发的非只读事务数目较多的场景可以适当增加该值,使日志缓冲区一次刷盘可以刷出较多的事务,减少IO次数,提高性能。需要和 commit_sibling配合使用。commit_siblings是触发commit_delay的并发事务数,只有系统的并发活跃事务数达到了该值,才会等待commit_delay的时间将日志刷盘。
调整参数如下:
commit_delay = 10 commit_siblings = 16 |
效果:调整之后,性能有一定的提升
优化3,数据刷盘优化
分析:此时观察系统资源,发现checkpoint进程持续占用CPU,分析日志发现数据库服务器checkpoint频率太高。

优化点:优化checkpoint,减少IO大量读写的次数。增加配置:
checkpoint_timeout = 120min checkpoint_completion_target = 0.8 |
效果:增加checkpoint配置后,checkpoint频率过高告警已消失。
优化4,autovacuum优化
分析:大量写入数据之后,发现vacuum进程持续占用CPU
优化点:PostgreSQL数据库自动清理机制,会自动清理过程中出现大量的数据扫描事件,频繁的清理过程反而会带来数据库过多的性能消耗,从而导致正常业务处理资源紧张。因此对自动清理过程进行限制可以在一定程度上提高业务处理性能。增加如下配置:
autovacuum = on autovacuum_max_workers = 5 autovacuum_naptime = 20s autovacuum_vacuum_cost_delay = 10 autovacuum_vacuum_scale_factor = 0.1 autovacuum_analyze_scale_factor = 0.02 vacuum_cost_limit = 2000 |
效果:vacuum进程长期占用CPU现象消失,性能有一定提升
03
KingbaseES调优及评测结果
优化1,IO优化
分析:在高并发场景下影响数据库处理能力性能主要因素有数据库IO消耗、服务器CPU使用效率等因素,且IO优化是数据库优化手段中最常见也是最常用的。KingbaseES数据库优化采用了共享内存优化、wal日志读写策略、IO频率、脏页刷盘策略等多种优化手段以提高高并发场景下的业务处理能力。
优化前性能统计:
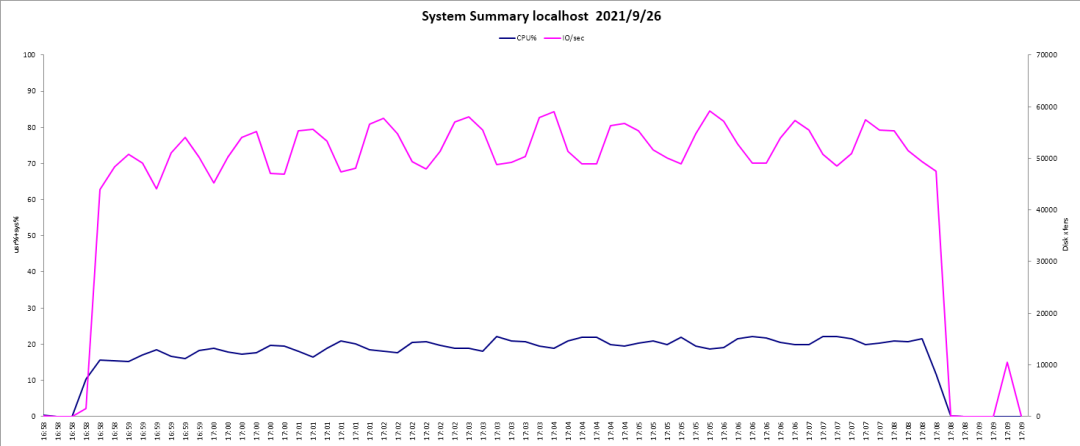
优化点:共享内存参数调整、wal日志策略调整、脏页存盘策略等
效果:CPU利用率极大的提升,TPMC也相应得到了提升。
优化后的性能统计:
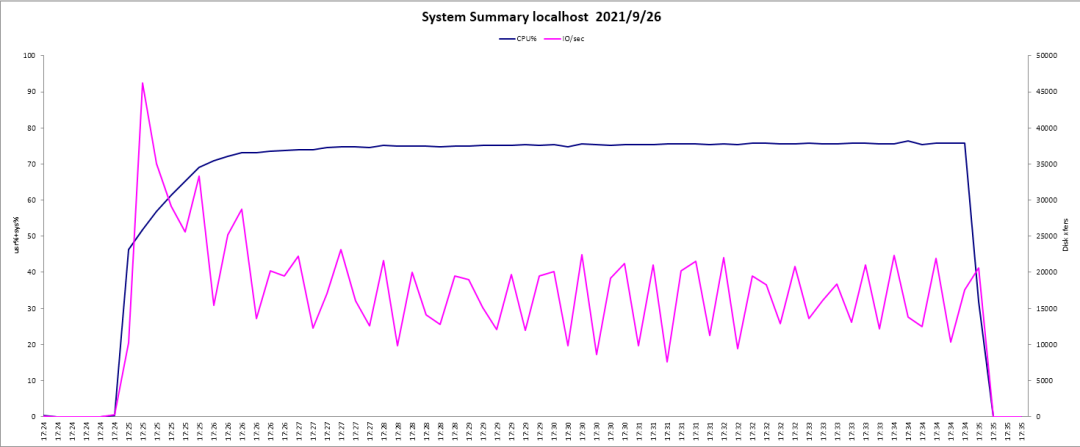
优化2,等待事件优化
分析:观察此时数据库系统等待事件, ProcArrayGroupUpdate等待事件占据了34%的数据库时间,存在较为严重的性能问题。
优化点:优化事务快照实现方式,提升数据库并发处理能力。
优化前系统top等待事件分析统计:

优化后系统top等待事件分析统计:
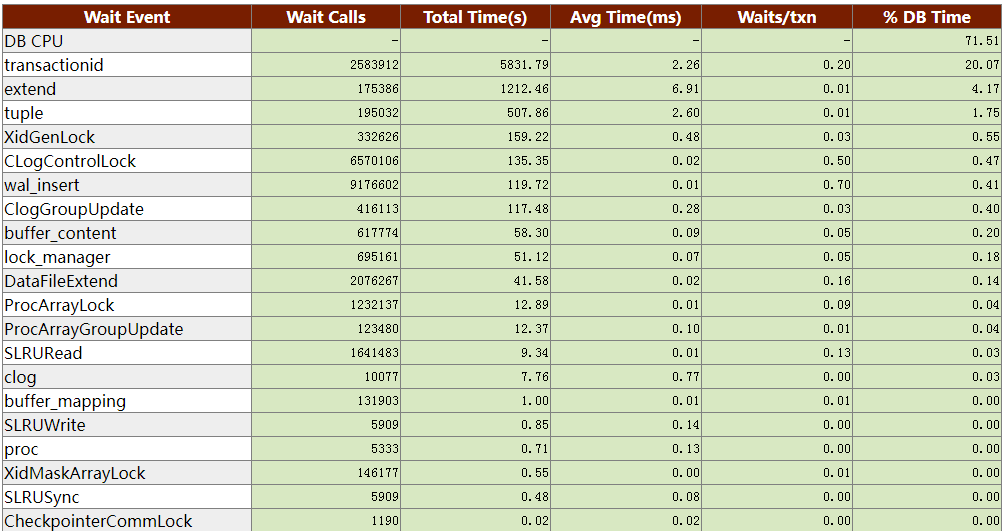
效果:通过以上优化前后系统等待事件对比,可以看出数据库系统中ProcArrayGroupUpdate 等待事件在优化前占所有等待事件的34.46%,优化后几乎不占用系统CPU太长事件,较大提升了整体性能。
优化3,绑核提升性能
分析:CPU通用调度模式下,进程容易因为争抢时间片而在不同的CPU核心之间切换,由此带来上下文切换的开销问题,造成性能损耗。
优化点:KingbaseES通过将每个进程均匀的绑定到CPU核心上,在高并发业务压力下节省了进程在多CPU核之间切换带来的开销。
效果:调整之后,性能得到明显提升。
04
经验优化
以上讨论了对三个数据库主要的调优手段和结果,调优后期,分别观察各数据库所在资源情况,CPU利用率上升到70-80%左右,IO和网络无明显压力。评估瓶颈优化的方式投入产出比较低,进一步根据已有经验进行调优方式的确认和细节参数的微调优化。
参考如下确认点:
1. 所有的SQL执行计划都合理,无调整空间
2. 优化IO,使用异步IO、优化脏页刷盘方式
3. 优化热点函数、非必要处理事件
4. 关闭监控系统
效果:CPU利用率略有提升,tpmc也随之略有提高。
05
最终评测结果
基于综上描述的调优操作和评测,分别获得MySQL、PostgreSQL、KingbaseES优化后的性能指标,具体如下:

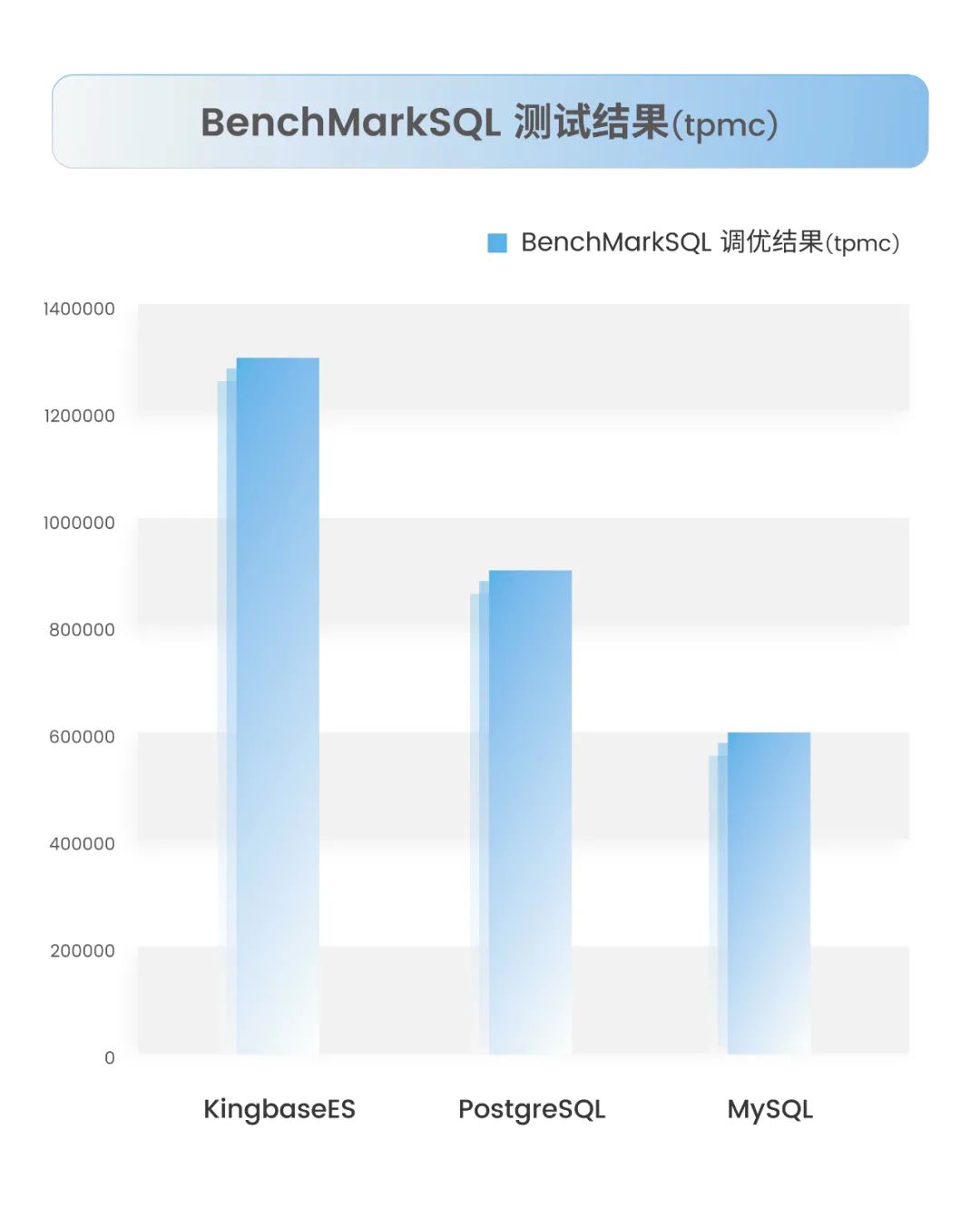
从结果上可见,在同样的基础环境和测试模型下,人大金仓KingbaseES产品的性能指标明显高于PostgreSQL和MySQL。KingbaseES为何性能上能够表现如此优异,让我们来探究下其内部的优化技术。
贰
浅谈KingbaseES“黑科技”
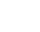
01
面向NUMA架构多核优化
NUMA的“前世今生”
为了寻求算力上不断新的突破,CPU先是朝着“频率”的方向高歌猛跟进,但随着逐渐受到物理极限的挑战,转为向核数越来越多发展,但由于所有CPU核都是通过共享一个北桥来读取内存,核数的不断增多带来了北桥响应时间的瓶颈问题。于是技术人员另辟蹊径,即将内存平均分配在各个die上,由此CPU核发展进入NUMA(Non-Uniform Memory Access)化时代,如此虽解决了原北桥读取内存的瓶颈问题,但由于NUMA架构下存在CPU访问本地内存的速度要比远端内存的访问速度快1.3--5倍,当CPU的核数越多,这种架构的内存访问的成本开销越大。
NUMA架构发展对数据库的挑战
数据库是高并发,数据访问冲突严重的软件系统,其需要大量使用大规模共享内存,面对NUMA架构,就不可避免在运行过程中去访问远程内存了,在不干预情况下,数据库内部进程会在CPU的核之间飘移,当线程运行时从一个核飘移到一个新的核上运行时,原先访问的数据结构再次访问时就涉及远端访问,从而导致访问时延增加。
由此可见,虽然CPU的NUMA技术发展带来了自身能力的大幅提升,但上层软件能否有效利用,才能真正决定算力释放的效果,纵观IT技术栈,只有硬件、操作系统、数据库软件都要深度适配 NUMA架构,才能充分发挥出NUMA的优势。因此人大金仓数据库产品KingbaseES作为企业级的商用数据库,为了帮助用户更高效地利用多核算力,提升数据库的响应速度,进行了针对性的优化。
线程绑核,降低访问时延
防止线程飘移,让其实现CPU核的就近访问,这是降低访问时延的关键,因此采用将线程能够固定到具体的核上运行的方法。KingbaseES利用配置参数设定,利用操作系统设置亲和性接口达到将线程绑定到具体NUMA节点上的效果。
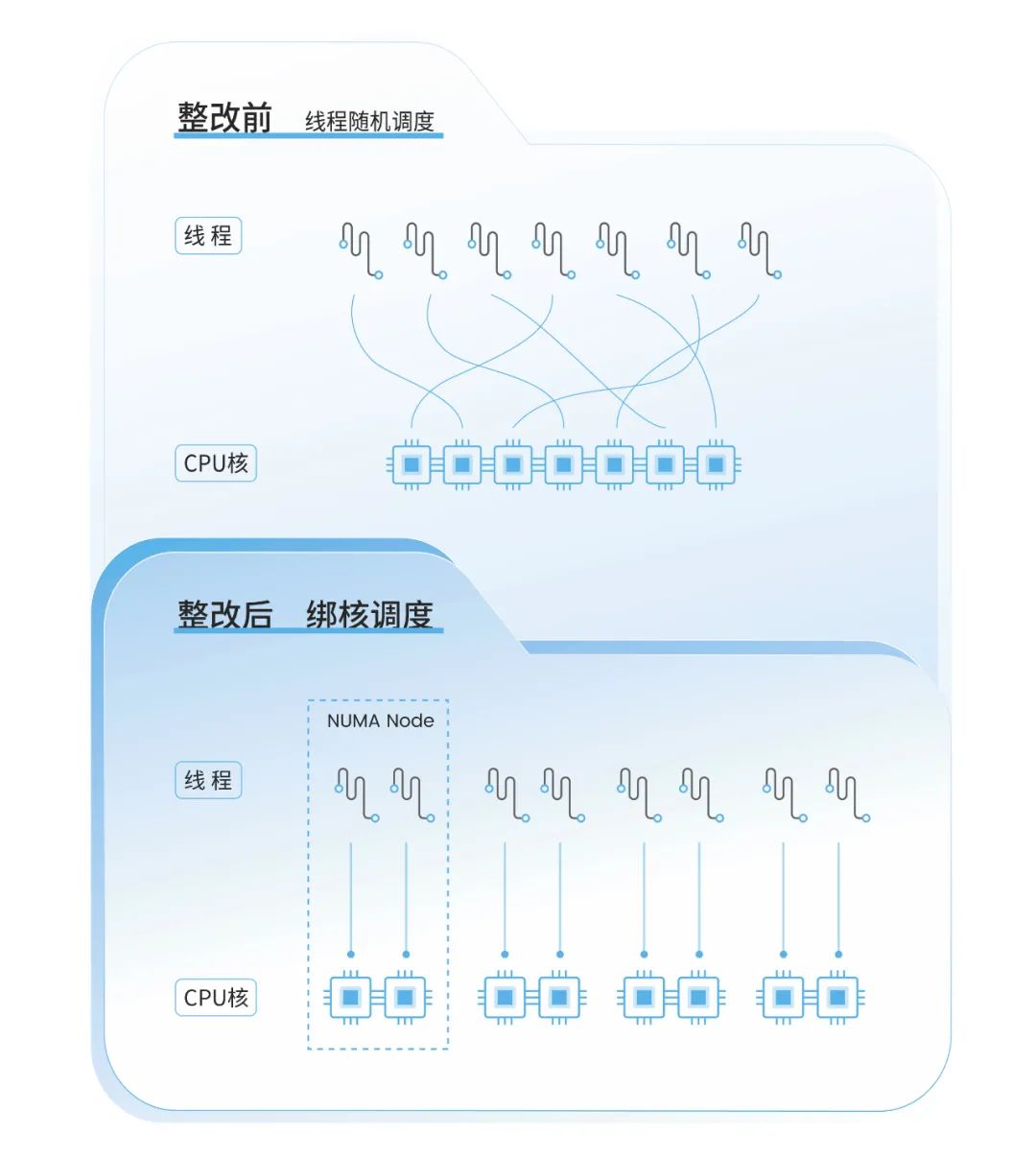
同时,KingbaseES是一个客户端服务器结构,客户端和服务器是通过网络通信来进行交互,网络是一个频繁的操作,并也会占用CPU,因此还需考虑将网络中断和业务处理进行区隔避免相互干扰,所以也对网络中断进行了绑核操作,并和后台业务线程绑核进行区分,这样能进一步提升利用效率,降低内耗。
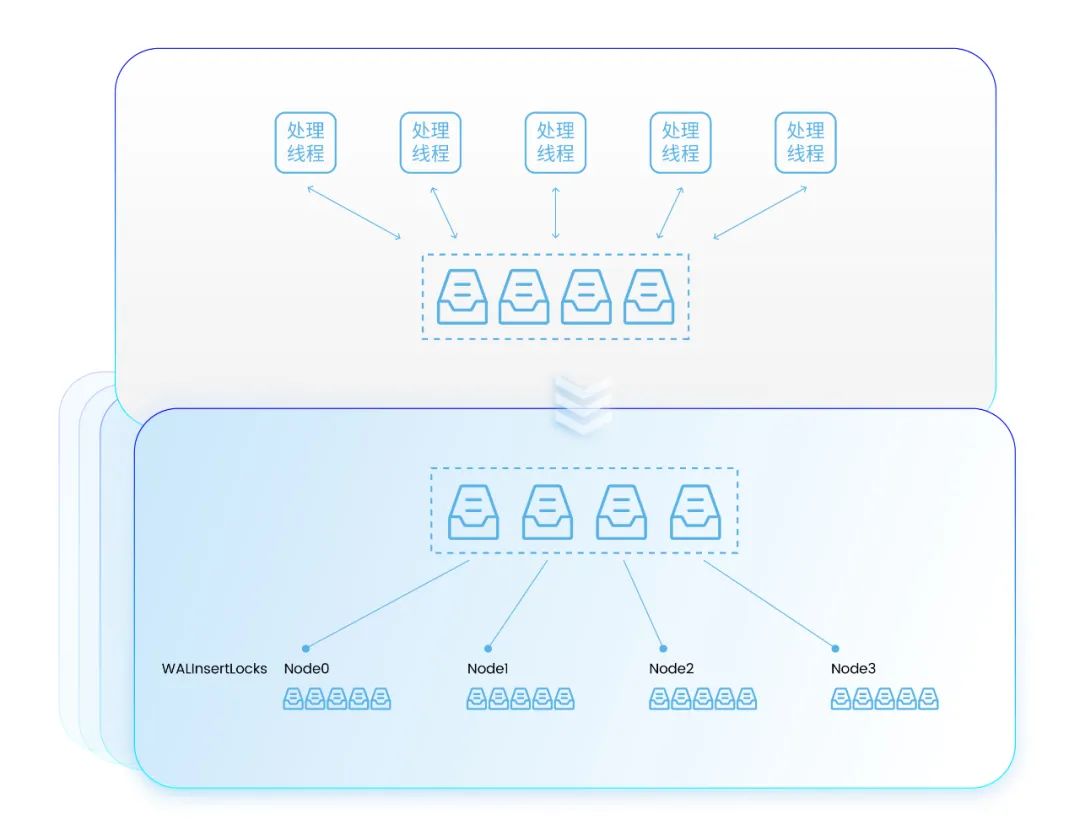
NUMA化数据结构改造,减少跨核访问
KingbaseES因业务处理需要,涉及很多对全局性数据结构的操作,如WALInsertLock、PGPROC等,在NUMA架构下,优化前,此类数据结构存放在共享内存中,当出现高并发访问,访问竞争激烈时,就会存在对其跨核访问,形成访问远端内存的局面,造成性能消耗。
根据以上问题,结合KingbaseES内部操作逻辑特点,并基于前文所述的线程绑核优化,我们进行了更深层更针对性的优化,即将操作频繁的的全局性数据结构按照NUMA节点的数量切分为多组,并分别在对应的NUMA节点上申请内存,当某线程需要操作相关数据结构,可访问自己所绑定的NUMA节点上本地内存的相关数据结构内容,减少了跨核的远端访问,提升了访问效率。

02
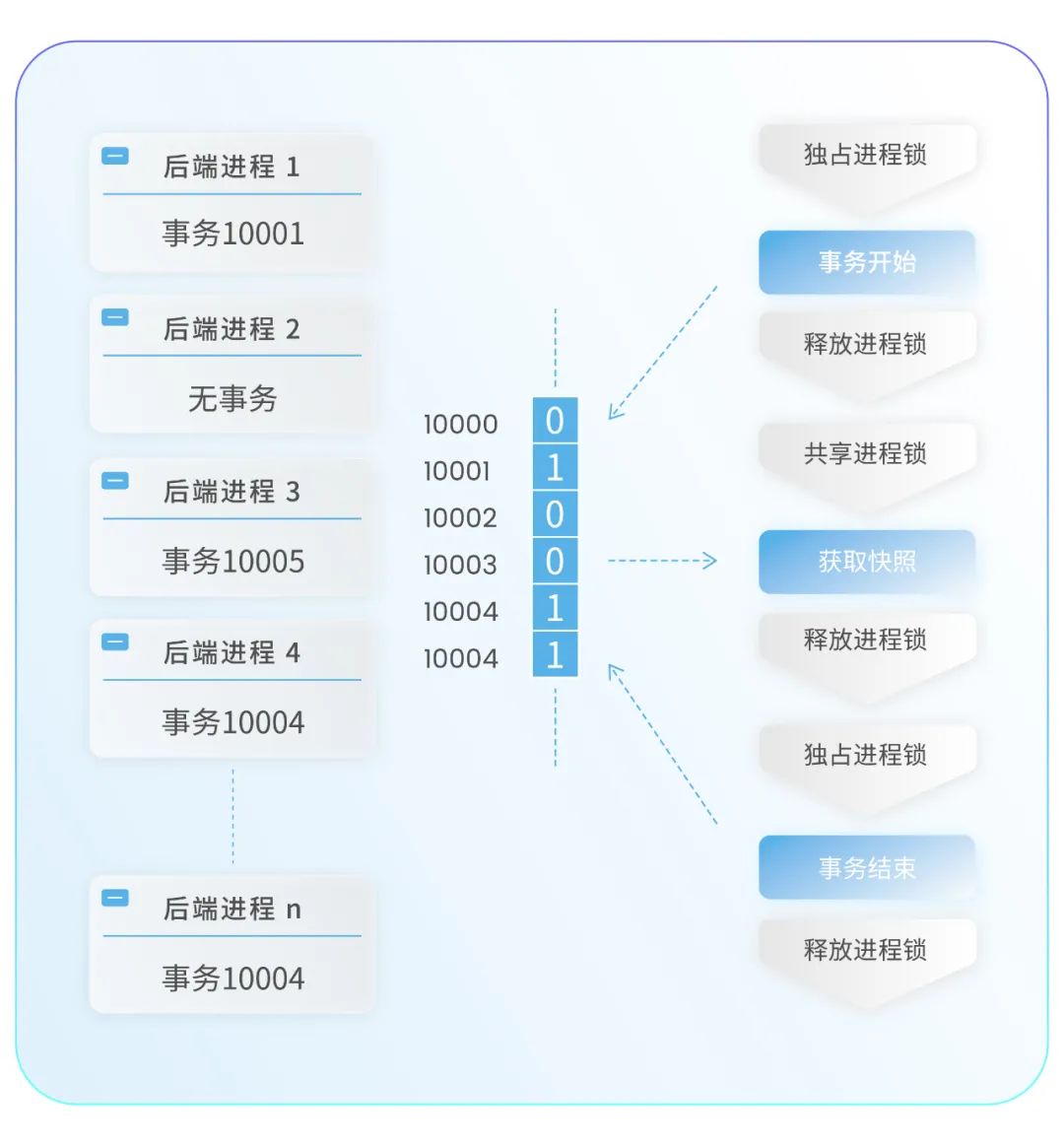
高并发冲突环境下的并发控制算法调整,减少单点瓶颈原模式下,每个数据库链接都会维护几个存储当前状态的结构,每当事务需要获得快照时,申请共享进程锁,遍历所有进程。快照需要记录包括当前正在运行的最大事务id、下一个将要开始的事务id,以及这二者之间正在运行的所有事务和子事务id列表。基于此,在可见性判断时可知,低于最小事务id的事务已结束,而大于最大事务id的事务视为正在运行,二者之间的事务态则需要根据列表判断。在高并发时,对所有进程进行遍历的时间变长,并且由于进程锁在很多场景下需要独占,例如下图所示的事务结束,大量并发进程相互之间的干扰愈加不可忽视,快照获取过程成为占比最高的部分。有鉴于此,如何最大程度的减少锁,成为解决问题的关键。

根据内核事务管理系统状态信息的分布特点,我们重新设计了数据结构,采用事务位图方式展现事务状态。如下图所示,在事务开始时使用独占进程锁设置事务状态位图,结束时仍然使用独占进程锁消除事务状态位图,而在获取快照时也仍然使用共享事务锁,但此时不再需要遍历进程状态。此设计使状态数据变得非常紧凑,能够快速获取事务状态,大幅降低共享锁的持有时间。
TPCC测试中,使用200并发终端压测,单独验证跟踪查看该方案最终测试结果,快照获取过程在整个运行期间的从占比6%以上,降低到0.2%以下。在不同平台上,tpmC均有不同幅度的提升,其中Intel平台大约20%,鲲鹏920平台约有5-6%。
叁
寄语
国产数据库蛰伏40年,人大金仓从第一代创办人坚信“中国也应有自己的数据库”之初心,到如今第三代金仓人面对国内外社会形势的变化,能扛起国产数据库承载核心业务应用的大旗,这一路走来,我们克服了很多困难,也得到了诸多客户的支持与肯定。未来,人大金仓将继续砥砺前行,不断提升用户对我们的信心,为中国数据库正名。


