
- 1Pyqt5-tools(安装失败解决方法)_pyqt5-tools安装失败
- 2Linux系统中利用MQTT连接腾讯云的方法_腾讯设备三元组
- 3python安装anyjson模块报错_error in anyjson setup command: use_2to3 is invali
- 4【java】JUC:java.util.concurrent理解与使用示例
- 5程序员年纪大了能做什么?想转行需要怎么准备?_程序员转行做什么好 程序员转行建议
- 6phoenix安装以及启动过程中出现的报错_inconsistent namespace mapping properties. ensure
- 7区块链常识
- 8【一周安全资讯0413】工信部部署做好2024年信息通信业安全生产和网络运行安全工作;美国环境保护局遭黑客攻击,850万数据泄露
- 9谈谈工业通信协议的采集和转换-如modbus opc profinet ethernetIP 61850等_opc协议转换映射
- 10【转】Docker 生产环境之安全性 - 适用于 Docker 的 Seccomp 安全配置文件_--security-opt seccomp=unconfined
一文走进 SQL 编译-语义解析_sql语义分析
赞
踩
一、概述
SQL 引擎主要由三大部分构成:解析器、优化器和执行器。解析器的主要作用是将客户端传来的命令解析编译成数据库能识别运行的命令,其主要由词法解析、语法解析和语义解析三部分构成,如下图所示。
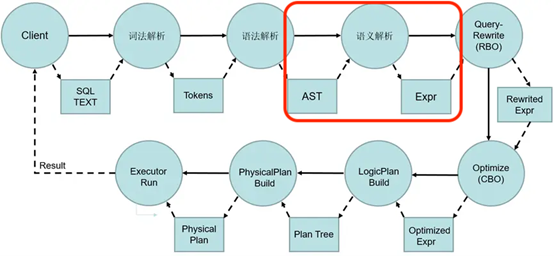
本文将重点介绍 KaiwuDB 语义解析部分,其输入为 AST 语法树,输出为可供优化器使用的 Expr 表达式。KaiwuDB 中的语义解析主要包括:
-
检查数据库或表是否存在
-
检查语句所需的特定权限
-
对语句中的表达式进行语义解析
-
检查 DDL 语句所请求的 schema change 的有效性
二、语义解析

KaiwuDB 中的语义解析主要包括以下流程:
-
检查查询是否为 SQL 语言中的有效语句
-
解析名称,例如表名或变量名的值
-
消除不必要的中间计算,例如用 1.0 替换 0.6 + 0.4,这也被称为常数折叠
-
确定用于中间结果的数据类型
其代码流程介于 parser 和 memo 构建之间,将 parser 输出的 AST 中的对象进行语义解析,语义解析的输出作为 memo 构建的输入。
接下来,将重点介绍查询语句的语义解析流程:
-
Source and target analysis (目标解析)
-
Permission check (权限校验)
-
Semantic decomposition & validation (表达式拆分及其语义解析)

1. 目标解析及权限校验
1)接口路径:
buildStmt() -> buildSelectStmtWithoutParent() -> buildSelectClause() -> builtFrom() -> buildDataSource()
2)核心接口为:
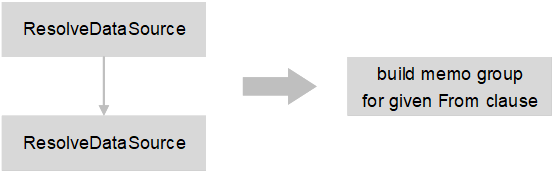
ResolveDataSource 通过 object name 解析出对象描述符(元数据),Privilege check 使用 current username 来校验当前用户对该对象是否有相应权限。
在完成目标解析和权限校验后,会为 select stmt 中的 from clause 构建 memo 表达式。这个行为看似不是语义解析应该做的,出现在这里的原因是 KaiwuDB 的语义解析和部分逻辑计划优化是相互融合的。
2. 表达式拆分及其语义解析
1)接口路径:
buildStmt() -> buildSelectStmtWithoutParent() -> buildSelectClause()
KaiwuDB 将 select stmt 中的各个部分拆分为表达式,并对其进行标量表达式的语义解析,从而完成 scalarExpr 的构建。例如:

2)标量表达式语义解析:
ROLE:检查表达式是否合法,为其做一些初步的优化,为其赋予类型。
INTERFACE:
in : Expr
out : TypedExpr
实质上是检查并赋予类型 + 简化表达式
AnalyzeExpr()
HOW:
i. Name Resolution
ii. TypeCheck
iii. Normalize Expr
这些子任务实现几乎是纯粹的函数,唯一的缺陷是, TypeCheck 将 SQL 占位符($1、$2 等)的类型以一种对顺序敏感的方式,输出到通过递归传递的语义环境对象上。
注意:可以使用 EXPLAIN(EXPRS, TYPES) 来检查表达式,而不进行解构和简化。
i. Name Resolution
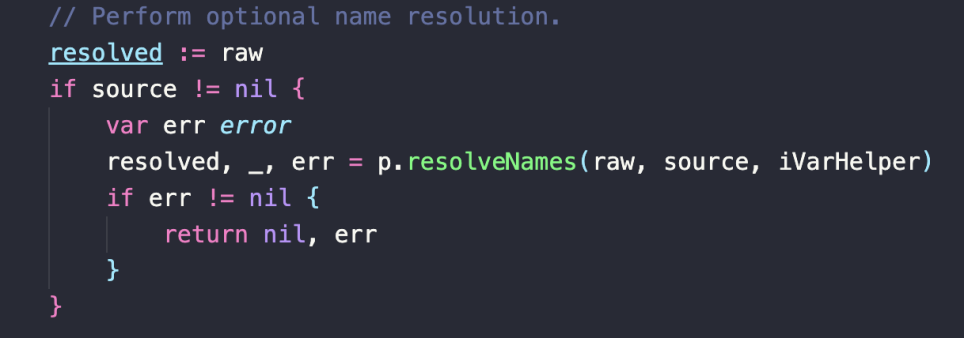

参数 sources 和 IndexedVars,如果都不是 nil,则表示 resolveNames 应该被执行。IndexedVars map 将被填充并且作为结果返回。
-
用 parser.IndexedVar 实例替换列名
-
用 parser.FuncDef 引用替换函数名
ii. TypeCheck
parser.TypeCheck() / parser.TypeCheckAndRequire():
-
常数折叠
-
类型推断
-
类型检查
-
在 ComparisonExpr 节点上记忆比较器函数
-
用其类型来注释表达式和占位符
实现 Expr 接口的表达式有很多:AndExpr, OrExpr, CastExpr, CaseExpr 等。
每个表达式都实现了 TypeCheck 接口,在被调用时返回结果表达式的类型,包括 bool, string, int 等。
iii. Normalize
parser.NormalizeExpr():
注意:此处的 normalize 有点不太准确,因为他并没有进行标准的 normalize,这里只是将除变量名以外的东西都放到比较符号的右侧,从而达到简化的目的。
Normalize Example:
-
(a+1) < 3 is transformed to a < 2
-
-(a - b) is transformed to (b - a)
-
a between c and d is transformed to a >= c and a <= d

Normalize 的实现主要依靠 WalkExpr 函数。WalkExpr 会横穿 Expr,其通过传入对应的 visitor 来定义 WalkExpr 的具体行为,前面讲到的 name resolution 也是通过传入 name resolution visitor 实现的。
上述就是 KaiwuDB 关于语义解析的介绍,欢迎大家关注我们的公众号,后续将陆续为大家介绍更多关于 SQL 编译的相关内容。

