
- 12024年Q1季度冰箱行业线上市场销售数据分析
- 22021爱分析·云计算厂商全景报告_博云谐云
- 3快速入门 KBQA问答系统的实现_neo4j kbqa
- 4Node.js 开发者需要知道的 13 个常用库
- 5Yolov8优化:融合注意力机制与卷积的最新移动端高效网络架构_cloformer速度
- 6开源模型应用落地-解锁大语言模型的无限潜能
- 7记一次虚拟机CentOs设置静态IP_虚拟机centos设置ip地址
- 8HDFS的Java API操作_hdfs的java apl 操作
- 9verilog I2C_eeprom 手册分析及代码编写思路_eeprom代码
- 10GPIO模拟I2C通信协议(二)_摸拟24c08页读写
【C题解题思路】2023年第九届数维杯国际大学生数学建模挑战赛_ai生成文本的智能识别与检测数学模型
赞
踩
c问题C:人工智能生成文本的智能识别与检测
近年来,随着信息技术的飞速发展,人工智能的各种应用层出不穷。典型的应用包括机器人导航、语音识别、图像识别、自然语言处理和智能推荐等。在这些应用中,以ChatGPT为代表的大型语言模型(large language models, llm)在全球范围内得到了广泛的推广和使用。同时,我们充分认识到这些模型给人们带来的丰富、智能和便捷的体验。同样重要的是要意识到与AI文本生成等工具相关的许多风险。
首先,这些大型语言模型是基于文本进行训练的。不同类型的语言和不同领域的文化背景会对生成的结果产生重大影响。其次,基于数据的人工智能生成的结果可能存在语义偏差,缺乏逻辑一致性,缺乏创造力。最后,隐私保护、版权保护以及学生使用人工智能生成论文所导致的相关学术不端行为的定义等问题,对本科生和研究生的教学和培训过程构成了重大的困难和挑战。为了防止人工智能生成文本的滥用,保证生成内容的质量,并讨论如何解决人工智能生成论文所带来的问题,有必要根据主题要求,识别和检测人工智能生成文本的模式,包括字段、模型、图像和公式。
判断文本是否为人工智能生成,除了考虑满足字数要求、生成次数、是否为汉英翻译等因素外。同样值得注意的是,人工智能目前缺乏人类的情感和判断。这可能会导致文本生成中的现象或风格,例如“更多的短语缺乏示例,缺乏情感,结构,例如单个”。
请用数学建模解决以下四个问题:
问题一: 请根据附录1提供的Web of Science上20个博客的链接,使用AI重写文章的部分内容。并寻找人工智能文本生成的基本规律,可以从人工智能生成的字数(如200字、500字等)、生成的次数(第一次生成 后点击“再生”按钮)、是否是中文和英文的翻译、生成文本的风格等要求进行统计推断。
解题步骤:
(1)建立数据集:从文章中,可以根据题目和关键字对每个文章的摘要进行重写,构建数据集。
Ps:分别生成1、2、3、4、5次,中翻英、英翻中 、限制次数
可用chatgpt生成“假如您是一位图书馆学领域的知名学者,我请您协助 我撰写一篇中文学术论文的摘要,我将提供一个学术论文题目和关键字,希望您根据这些题目为我撰写相应的论文摘要。 第一个论文题目是:XXX。””
(2)从长度、句子数量、词汇特征、常用搭配等维度对文本进行对比分析和可视化。
采用高频词统计法、N-gram、共词分析法等文本分析与挖掘方法。用均值方差图表示:
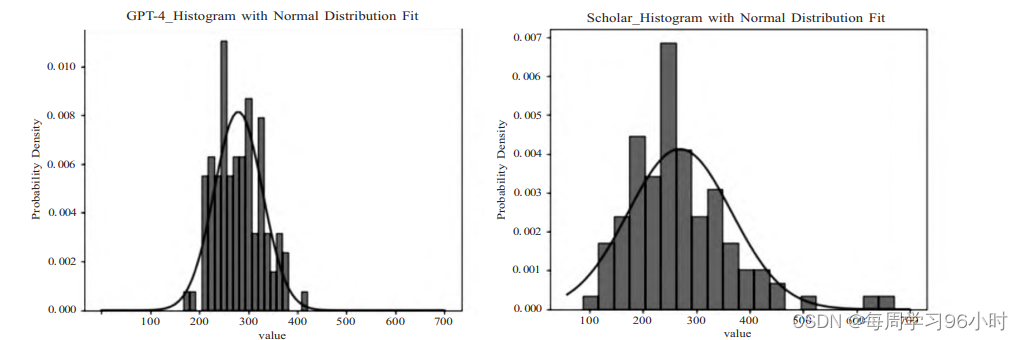
(3)对生成的数据集统计词频
更多内容请见如下内容

