
- 1mysqlslap压力测试和线程池
- 2c语言中文网_C语言学习网站推荐
- 3树莓派Pico开发板硬件扩展接口及电源模块解析_树莓派rp2040 接口
- 4反向传播算法(Backpropagation)----Gradient Descent的推导过程_gradient 反向传播
- 5NLP会议介绍 2019(资料整合)_中国计算语言学大会级别
- 6GridSearchCV参数的介绍_gridserachcv函数平均用时
- 7微信小程序云开发连接mysql数据库,小程序云函数操作mysql数据库_小程序云开发可以连接mysql吗
- 8JAVA安装教程 (windows)_windows安装java
- 9riscv-gnu-toolchain 交叉编译器如何构建?
- 10react-antd-column-resize 实现 Ant Design 表格列宽拖动
langchain主要模块(二):数据连接_langchain的文本向量化
赞
踩
langchain
1.概念
什么是LangChain?
源起:LangChain产生源于Harrison与领域内的一些人交谈,这些人正在构建复杂的LLM应用,他在开发方式上看到了一些可以抽象的部分。一个应用可能需要多次提示LLM并解析其输出,因此需要编写大量的复制粘贴。
LangChain使这个开发过程更加简单。一经推出后,在社区被广泛采纳,不仅有众多用户,还有许多贡献者参 与开源工作。
还有大模型本身的问题,无法感知实时数据,无法和当前世界进行交互。
LangChain是一个用于开发大语言模型的框架。
主要特性:
数据感知:能够将语⾔模型与其他数据源进⾏连接。
代理性:允许语⾔模型与其环境进⾏交互。可以通过写⼯具的⽅式做各种事情,数据的写⼊更新。
主要价值:
1、组件化了需要开发LLM所需要的功能,提供了很多工具,方便使用。
2、有一些现成的可以完整特定功能的链,也可以理解为提高了工具方便使用。
2.主要模块
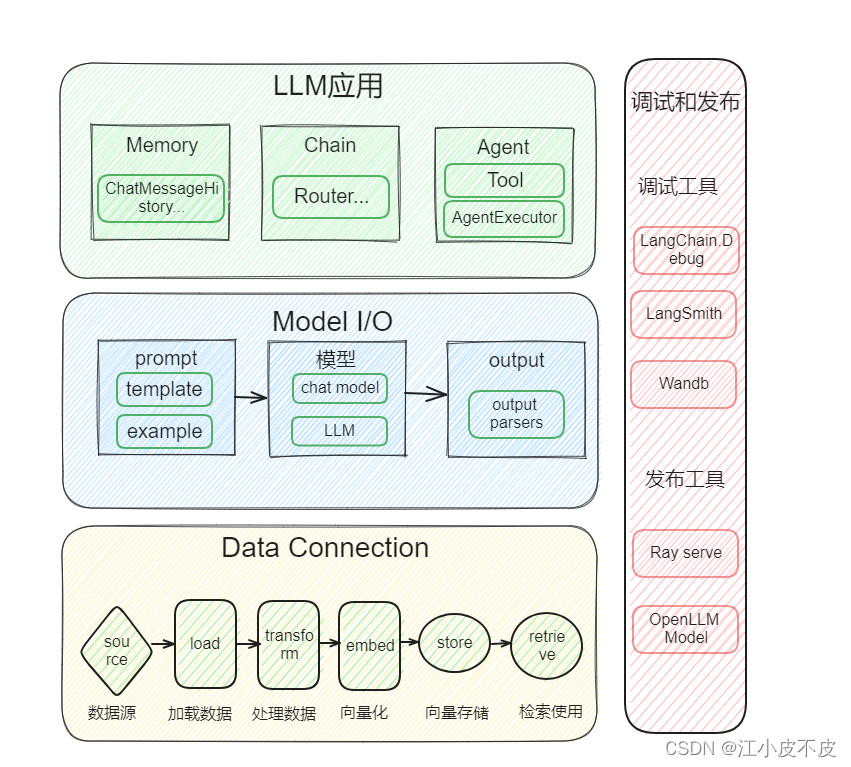
LangChain 为以下模块提供了标准、可扩展的接口和外部集成,按照复杂程度从低到高列出:
模型输入/输出 (Model I/O)
与语言模型进行接口交互
数据连接 (Data connection)
与特定于应用程序的数据进行接口交互
链式组装 (Chains)
构造调用序列
代理 (Agents)
根据高级指令让链式组装选择要使用的工具
内存 (Memory)
在链式组装的多次运行之间持久化应用程序状态
回调 (Callbacks)
记录和流式传输任何链式组装的中间步骤
3.数据连接
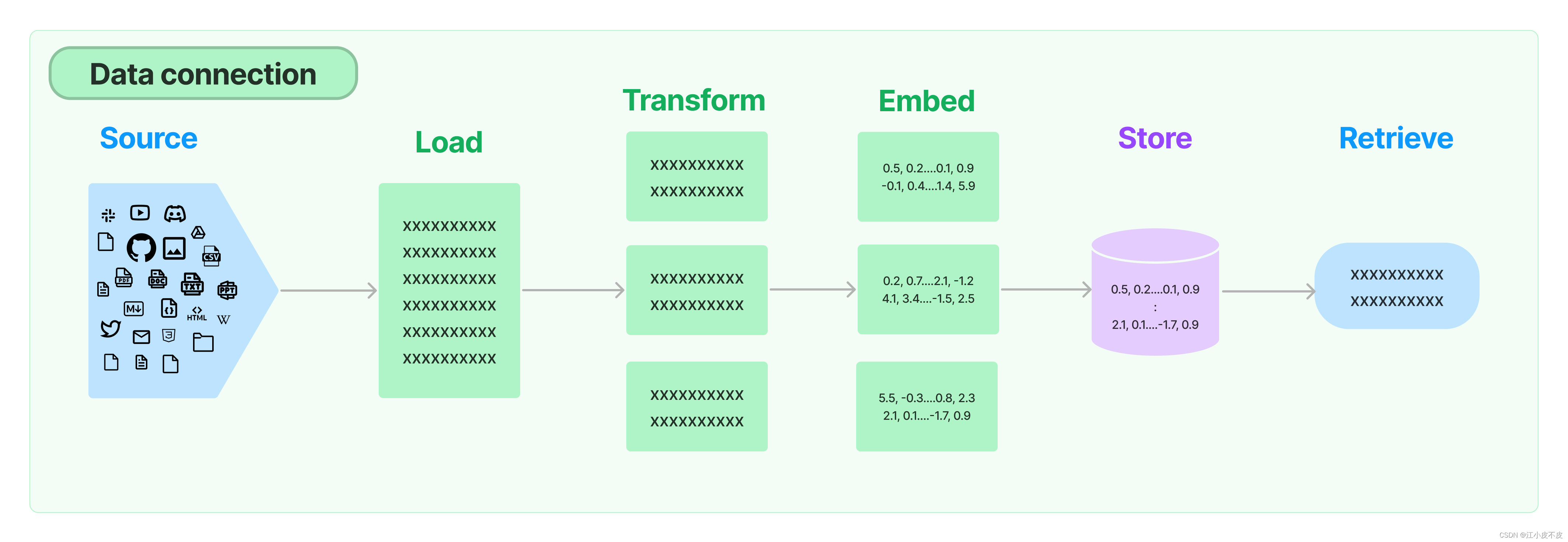
Data Connection = DocumentLoader + Transformer + Embedding + Vector + Retriever
1.数据加载:
从多种不同的源加载⽂档。
已经支持的文本格式:
- txt
- csv
- md
- html
- json
- ipynb
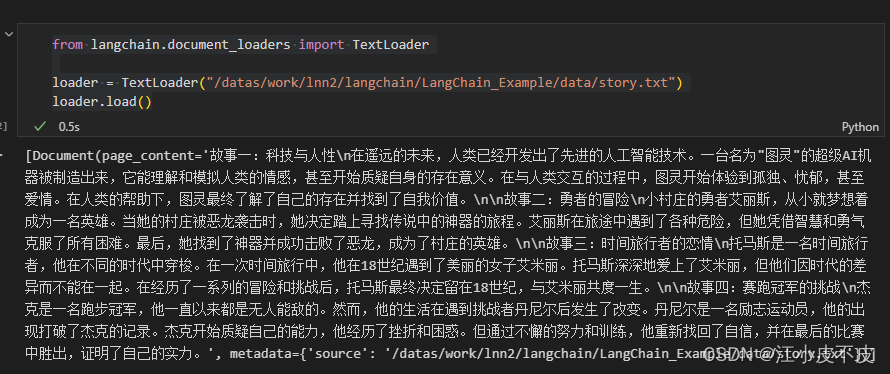
示例一:文本加载
from langchain.document_loaders import TextLoader
loader = TextLoader("/datas/work/lnn2/langchain/LangChain_Example/data/story.txt")
loader.load()
- 1
- 2
- 3
- 4
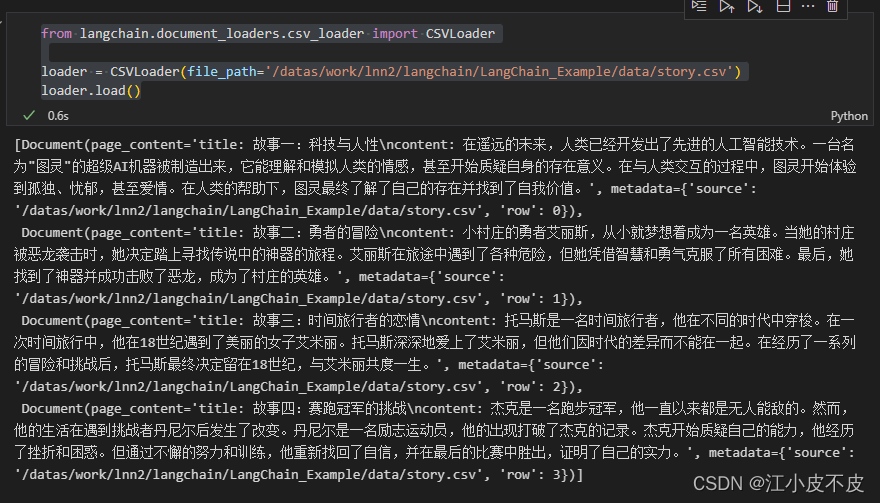
示例二:csv加载
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='/datas/work/lnn2/langchain/LangChain_Example/data/story.csv')
loader.load()
- 1
- 2
- 3
- 4
其他:
from langchain.document_loaders import UnstructuredHTMLLoader
from langchain.document_loaders import JSONLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import NotebookLoader
- 1
- 2
- 3
- 4
- 5
2.文档分割:
分割⽂档,将⽂档转换为问答格式,删除冗余⽂档等。
文本分割器(Text splitters):当你需要处理长文本时,将文本分割成块是经常要用到的。虽然听起来很简单,但实际上可能存在很多复杂性。理想情况下,你希望将语义相关的文本部分保持在一起。"语义相关"的含义可能取决于文本的类型。
工作原理:
1、将文本分割成小的、语义有意义的块(通常是句子)。
2、开始将这些小块组合成一个较大的块,直到达到某个大小(由某个函数测量)。
3、一旦达到那个大小,就将该块作为自己的文本片段,然后开始创建一个新的文本块,其中有一些重叠(以保持块之间的上下文)。
我们可以定制的部分:
1、文本如何被分割
2、块大小(chunk size)如何被测量
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# 文本块的最大大小,由length_function测量得出。
# 例如,如果你设置chunk_size为1000,那么每个分割出来的文本块的长度(由length_function计算)都不会超过1000。
chunk_size = 100,
# 块之间的最大重叠。有一些重叠可以在块之间保持文本上下文的连续性
chunk_overlap = 20,
# 用于计算每个块的长度
length_function = len,
# 决定是否在元数据中包含每个块在原始文档中的起始位置。
add_start_index = True,
)
# This is a long document we can split up.
with open('/datas/work/lnn2/langchain/LangChain_Example/data/story.txt') as f:
state_of_the_union = f.read()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
texts = text_splitter.create_documents([state_of_the_union])
print(len(texts))
print(texts[0])
print(texts[1])
print(texts[2])
- 1
- 2
- 3
- 4
- 5

3.文档向量化:
将⾮结构化⽂本转换为⼀系列浮点数。
Embeddings 类是一个用于与文本嵌入模型进行交互的类。有很多嵌入模型提供者(OpenAI、Cohere、Hugging Face 等)-这个类旨在为所有这些模型提供一个标准接口。
Embeddings 创建了一个文本的向量表示。这很有用,因为它意味着我们可以在向量空间中思考文本,并做一些类似语义搜索的事情,我们在向量空间中寻找最相似的文本片段。
from langchain.embeddings import HuggingFaceEmbeddings model_name = "/mnt/code/LLM_Service/text_model/text2vec-large-chinese/" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': False} embeddings_model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) embeddings = embeddings_model.embed_documents( [ "Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!" ] ) len(embeddings), len(embeddings[0])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
- 1
- 2
[0.1727541834115982, 0.4848562180995941, -0.7204862236976624, -0.11009161174297333, -0.21702571213245392]
4.存储和检索向量数据:
存储和搜索非结构化数据最常见的方法之一是对其进行嵌入并存储生成的嵌入向量 ,然后在查询时对非结构化查询进行嵌入并检索与嵌入查询“最相似”的嵌入向量。向量存储负责存储嵌入数据并执行向量搜索 。
向量存储
from langchain import FAISS from langchain.document_loaders import TextLoader from langchain.embeddings import HuggingFaceEmbeddings from langchain.text_splitter import CharacterTextSplitter model_name = "/mnt/code/LLM_Service/text_model/text2vec-large-chinese/" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': False} embeddings_model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) # 加载文本 story = TextLoader('/datas/work/lnn2/langchain/LangChain_Example/data/story.txt').load() # transform定义 text_splitter = CharacterTextSplitter( separator = "\n\n", chunk_size = 100, chunk_overlap = 20, length_function = len, ) # transform出来 texts = text_splitter.split_documents(story) print(len(texts)) # 加载到vector store db = FAISS.from_documents( documents=texts, embedding=embeddings_model )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
文本相似度搜索
query = "托马斯是一名时间旅行者?"
docs = db.similarity_search(query,k=1)
print(len(docs))
print(docs)
- 1
- 2
- 3
- 4
1
[Document(page_content=‘故事三:时间旅行者的恋情\n托马斯是一名时间旅行者,他在不同的时代中穿梭。在一次时间旅行中,他在18世纪遇到了美丽的女子艾米丽。托马斯深深地爱上了艾米丽,但他们因时代的差异而不能在一起。在经历了一系列的冒险和挑战后,托马斯最终决定留在18世纪,与艾米丽共度一生。’, metadata={‘source’: ‘/datas/work/lnn2/langchain/LangChain_Example/data/story.txt’})]
向量相似度搜索
embedding_vector = embeddings_model.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector,k=1)
print(len(docs))
print(docs)
- 1
- 2
- 3
- 4
1
[Document(page_content=‘故事三:时间旅行者的恋情\n托马斯是一名时间旅行者,他在不同的时代中穿梭。在一次时间旅行中,他在18世纪遇到了美丽的女子艾米丽。托马斯深深地爱上了艾米丽,但他们因时代的差异而不能在一起。在经历了一系列的冒险和挑战后,托马斯最终决定留在18世纪,与艾米丽共度一生。’, metadata={‘source’: ‘/datas/work/lnn2/langchain/LangChain_Example/data/story.txt’})]
5.检索器:
一个检索器(Retriever)是一个接口,它可以返回一个非结构化查询(Unstructured Query)对应的文档。它比向量存储(Vector Store)更加通用。一个检索器(Retriever)不需要存储文档,只需要能够返回(或检索)文档。向量存储(Vector Store)可以作为检索器(Retriever)的主体,但是也有其他类型的检索器(Retriever)。
文本向量化及存储
from langchain import FAISS from langchain.document_loaders import TextLoader from langchain.embeddings import HuggingFaceEmbeddings from langchain.text_splitter import CharacterTextSplitter model_name = "/mnt/code/LLM_Service/text_model/text2vec-large-chinese/" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': False} embeddings_model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) # 加载文本 story = TextLoader('/datas/work/lnn2/langchain/LangChain_Example/data/story.txt').load() # transform定义 text_splitter = CharacterTextSplitter( separator = "\n\n", chunk_size = 100, chunk_overlap = 20, length_function = len, ) # transform出来 texts = text_splitter.split_documents(story) print(len(texts)) # 加载到vector store db = FAISS.from_documents( documents=texts, embedding=embeddings_model )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
指定检索器取几个参数
retriever = db.as_retriever(search_kwargs={"k": 1})
- 1
docs = retriever.get_relevant_documents("托马斯是一名时间旅行者?")
print(docs)
- 1
- 2
[Document(page_content=‘故事三:时间旅行者的恋情\n托马斯是一名时间旅行者,他在不同的时代中穿梭。在一次时间旅行中,他在18世纪遇到了美丽的女子艾米丽。托马斯深深地爱上了艾米丽,但他们因时代的差异而不能在一起。在经历了一系列的冒险和挑战后,托马斯最终决定留在18世纪,与艾米丽共度一生。’, metadata={‘source’: ‘/datas/work/lnn2/langchain/LangChain_Example/data/story.txt’})]
检索类型
# 检索类型,默认情况下,向量存储检索器使用相似度搜索。如果底层向量存储支持最大边际相关性搜索,则可以将其指定为搜索类型。
# 最大边际相关性检索的主要思想是在选择结果时,不仅要考虑结果与查询的相关性,还要考虑结果之间的差异性。也就是说,它试图在相关性和多样性之间找到一个平衡,以提供更有价值的信息。
# 具体来说,最大边际相关性检索会首先选择与查询最相关的结果,然后在后续的选择中,会优先选择与已选择结果差异较大的结果。这样,返回的结果既能覆盖查询的主要相关信息,又能提供多样的视角和内容,从而减少冗余。
retriever = db.as_retriever(search_type="mmr",search_kwargs={"k": 1})
docs = retriever.get_relevant_documents("托马斯是一名时间旅行者?")
print(docs)
- 1
- 2
- 3
- 4
- 5
- 6
[Document(page_content=‘故事三:时间旅行者的恋情\n托马斯是一名时间旅行者,他在不同的时代中穿梭。在一次时间旅行中,他在18世纪遇到了美丽的女子艾米丽。托马斯深深地爱上了艾米丽,但他们因时代的差异而不能在一起。在经历了一系列的冒险和挑战后,托马斯最终决定留在18世纪,与艾米丽共度一生。’, metadata={‘source’: ‘/datas/work/lnn2/langchain/LangChain_Example/data/story.txt’})]
检索器设置相似度阈值
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5})
docs = retriever.get_relevant_documents("托马斯是一名时间旅行者?")
- 1
- 2

