
- 1数据结构:顺序表的基本操作!(C语言)
- 2Java面试之数据库篇(offer 拿来吧你)_java 面试 数据库
- 3带你用Python制作一个经典必收藏的游戏:地铁跑酷(含完整代码)_python地铁跑酷
- 4Android(1) 渐变色背景设置_android studio 如何设置从上到下的渐变
- 5python 实现排序方法,常见排序方法,快速排序,归并排序,谢尔排序,堆排序,冒泡排序,选择排序,插入排序_python堆排序vs归并vs快速排序
- 6CentOS7安装postgresql_centos7 安装postgresql
- 7MAC 电脑安装并配置Tomcat 服务器_mac电脑给远程的阿里云服务器安装tomcat
- 8Mendix 使用OIDC组件实现SSO|Azure Microsoft Entra ID 集成(原名:AD)_azure ad oidc
- 9Windows 安装Redis(图文详解)_windows安装redis
- 10《爱你就像爱生命》你好哇,陌生人_你好哇,陌生人
【爬虫2】——聚焦爬虫
赞
踩
目录
二、聚焦爬虫
在通用爬虫基础上,爬取特定内容
所以,
步骤:
- 网址
- 请求
- 获取数据
- 数据解析
- 存数据
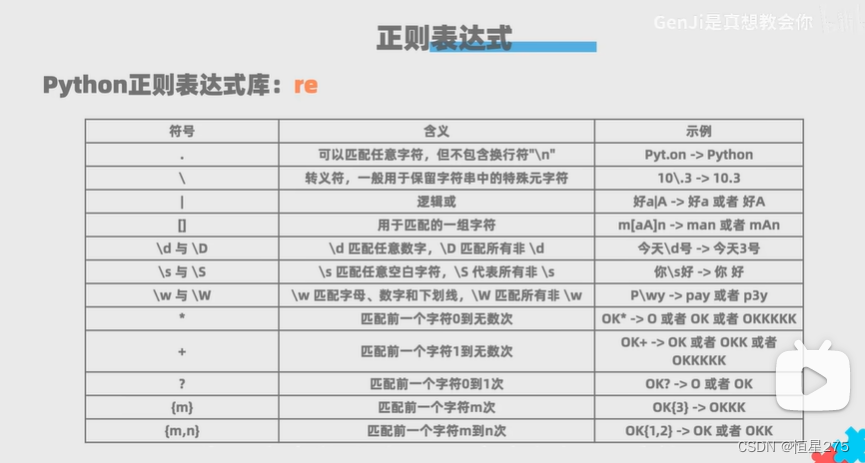
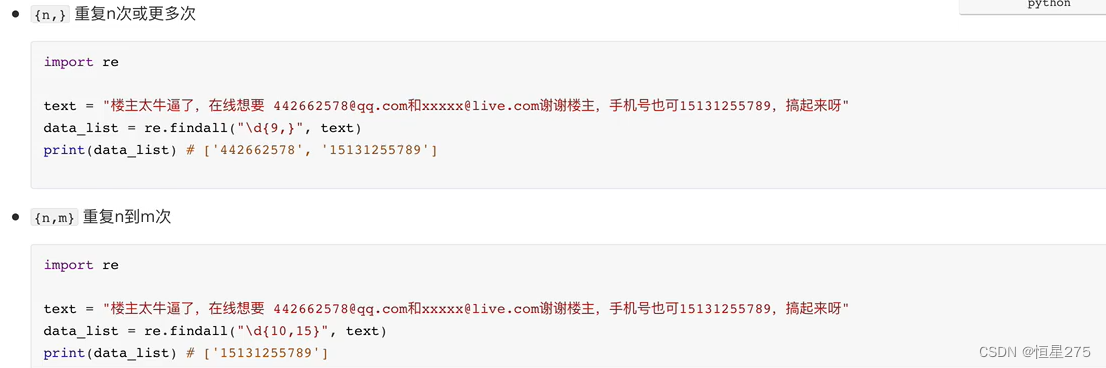
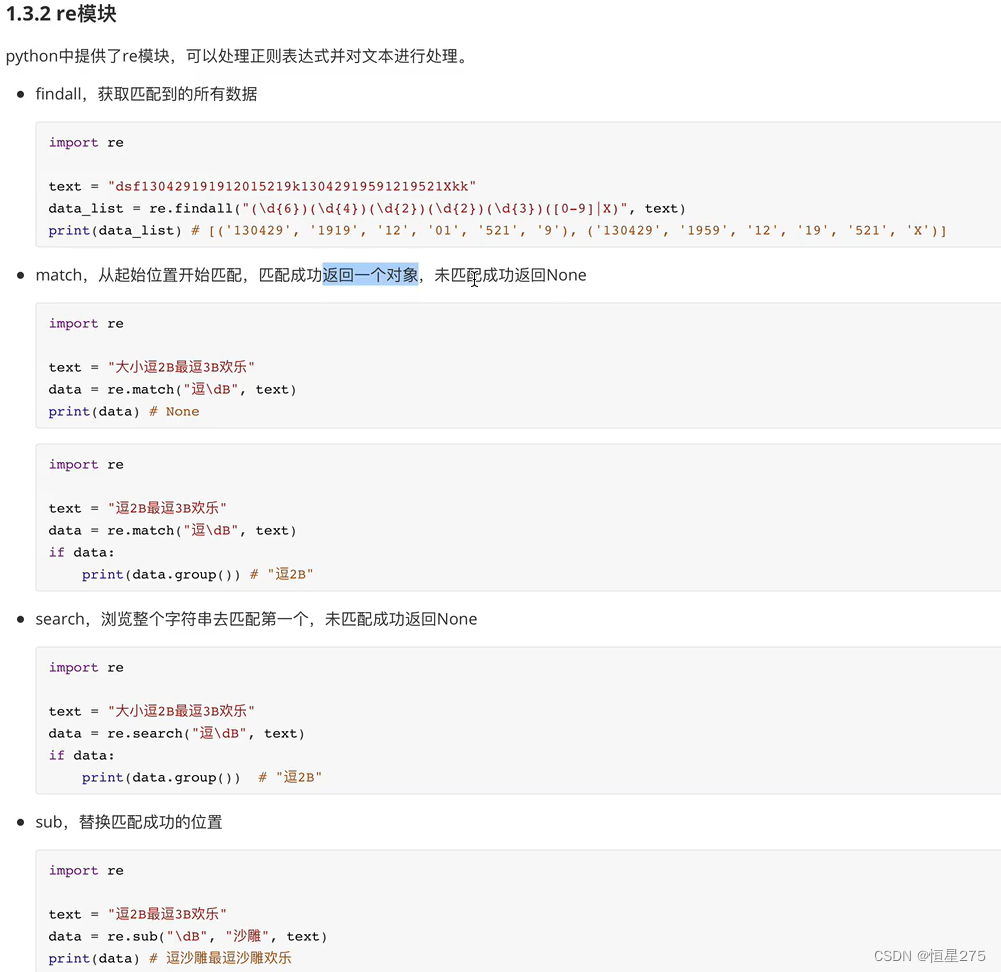
主要技术——数据解析:
解析的局部文本内容都在标签之间或者属性中存储
所以,大象塞冰箱里,2步:
- 定位标签
- 标签内容或者属性中存储的数据进行提取(解析)
分类:
- 正则
- bs4
- xpath
编码实践
基础知识
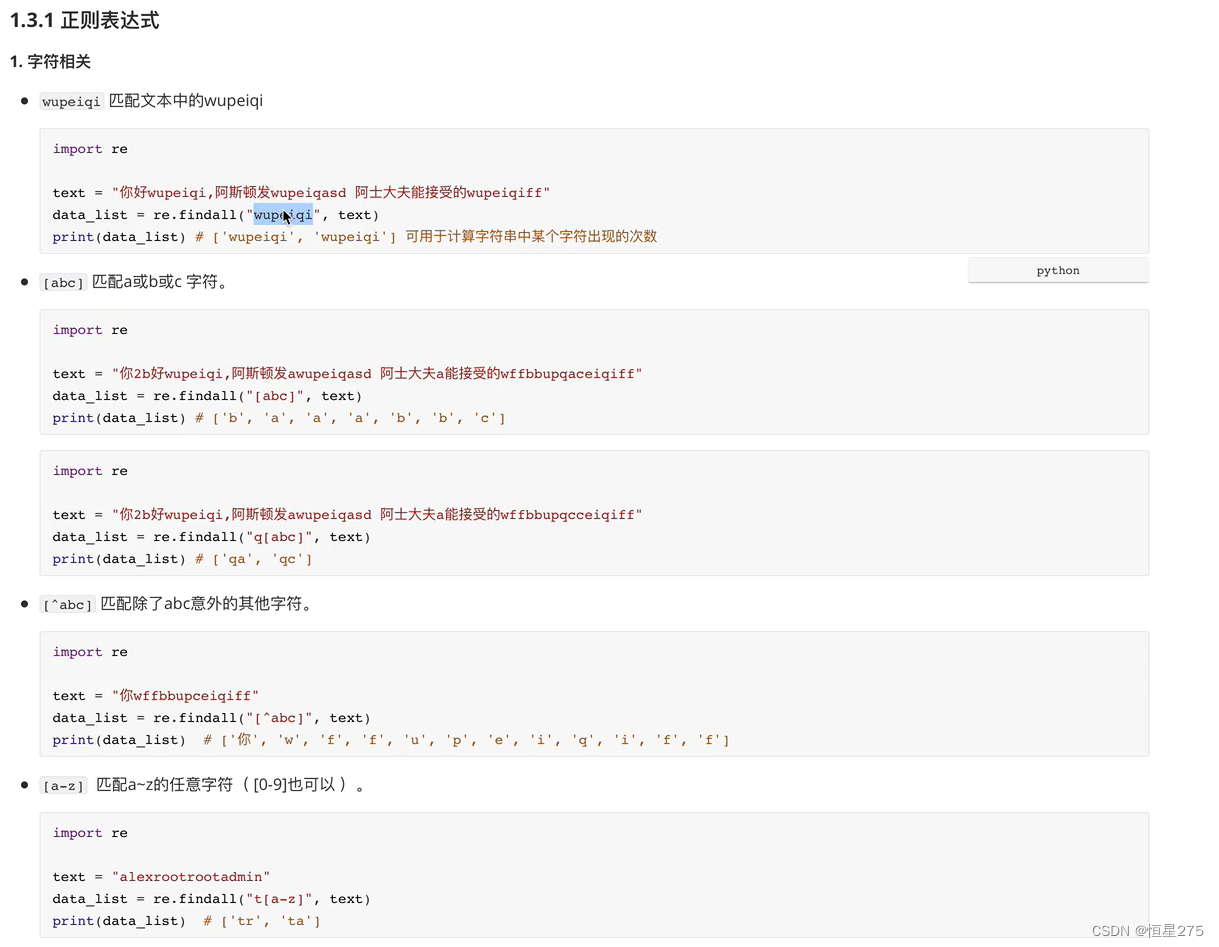
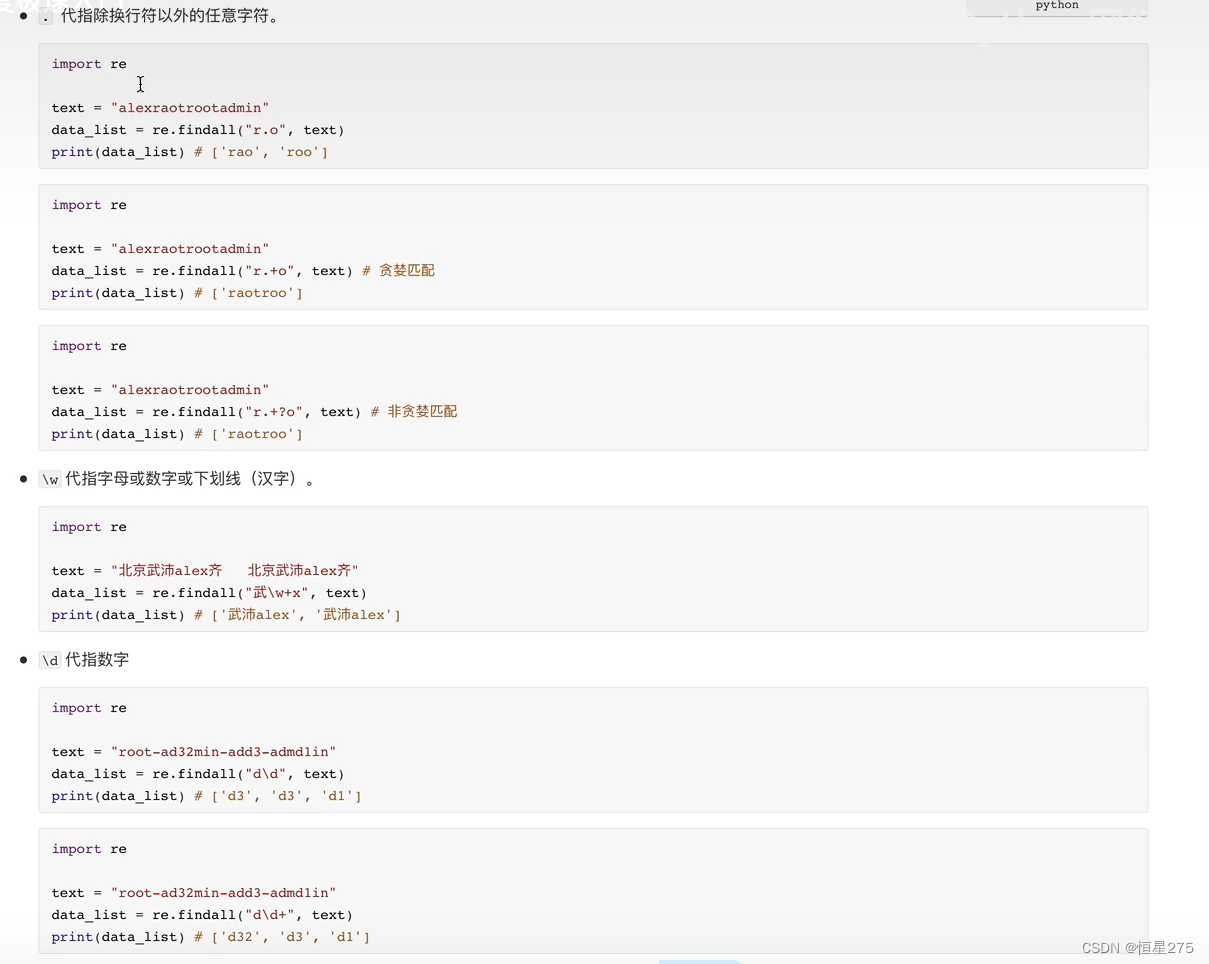
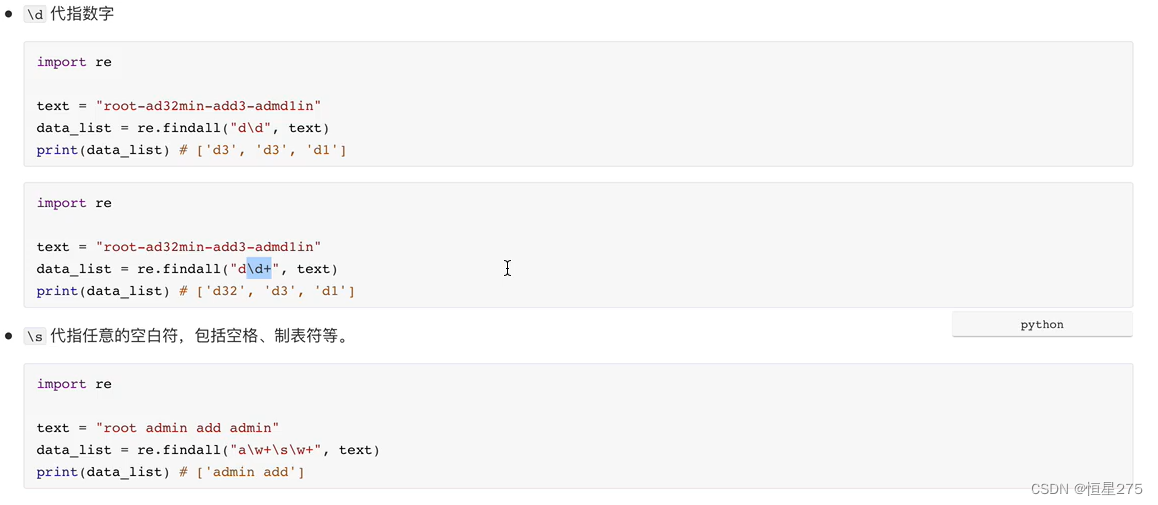





1.简单的爬取图片
- import requests
-
- if __name__ == "__main__":
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
-
- url = 'https://img-blog.csdnimg.cn/88f0581db75245a198deba3b1bad2e60.png'
- # content返回二进制形式的图片数据
- # json()对象 text字符串 content二进制
- img_content = requests.get(url=url,headers=headers).content
- with open('./img1.jpg','wb') as fp:
- fp.write(img_content)
2.正式爬取图片
- import re
-
- import requests
-
- if __name__ == "__main__":
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
- # 1.确定网址
- url = 'https://books.toscrape.com/'
-
- # 2.发请求,得到html
- html = requests.get(url=url,headers=headers).text
-
- # 3.分析html结构,用正则进行数据解析
- # < div class ="image_container" >
- # < a href = "catalogue/tipping-the-velvet_999/index.html" >
- # < img src = "media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg" alt = "Tipping the Velvet" class ="thumbnail" >
- # < / a >
- # < / div >
- html=html.replace('\n',' ')
- ex = '<div class="image_container">.*?<img src="(.*?)" alt.*?'#注意这里不要有多余的空格,直接黏贴确实会有空格,所以还要手动改改
- img_list=re.findall(ex,html)
- print(img_list)
-
- #4.链接完整的网址
- # https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg
- # media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg
- for src in img_list:
- url='https://books.toscrape.com/'+src
- img_content=requests.get(url=url,headers=headers).content
-
- # 获取每个图片的名字
- # 通过/ 分割,并【-1】快速拿到最后一个 yyds
- fileName='./img/'+src.split('/')[-1]
- #./img/94b1b8b244bce9677c2f29ccc890d4d2.jpg
- with open(fileName,'wb') as fp:
- fp.write(img_content)
- print(fileName+'保存成功!!!')
-

3.正式爬取图片(2) 使用os
- import os
- import re
-
- import requests
-
-
-
- if __name__ == "__main__":
- # 新增了!!!!!!
- if not os.path.exists('./img'):
- os.mkdir('./img')
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
- # 1.确定网址
- url = 'https://books.toscrape.com/'
-
- # 2.发请求,得到html
- html = requests.get(url=url,headers=headers).text
-
- # 3.分析html结构,用正则进行数据解析
- html = html.replace('\n', ' ')#没有这个换行也不行,因为.不匹配换行啊!!!!!
- ex = '<div class="image_container">.*?<img src="(.*?)" alt.*?'#注意这里不要有多余的空格,直接黏贴确实会有空格,所以还要手动改改
- img_list=re.findall(ex,html)
- print(img_list)
-
- #4.链接完整的网址
- for src in img_list:
- url='https://books.toscrape.com/'+src
- img_content=requests.get(url=url,headers=headers).content
-
- fileName='./img/'+src.split('/')[-1]
-
- with open(fileName,'wb') as fp:
- fp.write(img_content)
- print(fileName+'保存成功!!!')
-
4.正式爬取图片(3) 分页爬取
- import os
- import re
-
- import requests
-
-
-
- if __name__ == "__main__":
- # os
- if not os.path.exists('./img'):
- os.mkdir('./img')
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
-
- # 我要分页爬取,所以重新确定网址
- # https://books.toscrape.com/catalogue/page-2.html
- # 分析出来,改参数就可以实现分页效果,所以,就循环喽
-
-
- for page_num in range(1,5):
- url = 'https://books.toscrape.com/catalogue/page-{:d}.html'.format(page_num)
- # print(url)
-
- # 2.发请求,得到html
- html = requests.get(url=url,headers=headers).text
-
- # 3.分析html结构,用正则进行数据解析
- html=html.replace('\n',' ')
- ex = '<div class="image_container">.*?<img src="(.*?)" alt.*?'#注意这里不要有多余的空格,直接黏贴确实会有空格,所以还要手动改改
- img_list=re.findall(ex,html)
- print(img_list)
-
- #4.链接完整的网址
- for src in img_list:
- url='https://books.toscrape.com/'+src
- img_content=requests.get(url=url,headers=headers).content
-
- fileName='./img/'+src.split('/')[-1]
-
- with open(fileName,'wb') as fp:
- fp.write(img_content)
- print(fileName+'保存成功!!!')
-
原理:
- 实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中
- 调用该对象的属性或方法,进行标签定位和数据提取
BeautifulSoup(content, 'lxml')` 和 `BeautifulSoup(content, 'html.parser')` 都是使用 BeautifulSoup 库来解析 HTML 或 XML 内容的方式,但使用了不同的解析器。
区别如下:
1. 解析器:`lxml` 使用了第三方库 lxml 来解析 HTML 或 XML,而 `html.parser` 则使用 Python 内置的标准库 html.parser 来解析。
2. 性能:`lxml` 解析器通常比 `html.parser` 解析器更快,因为 lxml 是 C 语言编写的,而 html.parser 是纯 Python 实现的。因此,处理大型文档时,`lxml` 解析器可能更高效。
3. 容错性:`html.parser` 解析器在处理不规范的 HTML 或 XML 时更具容错性,能够处理一些不完全闭合标签或其他错误的情况。而 `lxml` 解析器对于不规范的文档可能会报错或产生不可预测的结果。
4. 功能:`lxml` 解析器提供了更多的功能和选项,例如 XPath 查询、CSS 选择器等。而 `html.parser` 解析器的功能较为简单,不支持这些高级功能。
选择使用哪个解析器取决于具体的需求和情况。如果处理的是规范的 HTML 或 XML,且需要更高的性能和功能,可以选择 `lxml` 解析器。如果处理的是不规范的文档,或者只需要基本的解析功能,可以选择 `html.parser` 解析器。
需要注意的是,使用 `lxml` 解析器需要先安装 lxml 库,可以通过 `pip install lxml` 命令进行安装。而 `html.parser` 解析器是 Python 的标准库,在大多数情况下无需额外安装。
基础知识
- # 一、对象的实例化
- # 本地实例化
- from bs4 import BeautifulSoup
- fp= open('./test.html','r',encoding='utf-8')
- soup=BeautifulSoup(fp,'html.parser')
- # 网上实例化
- # page_text=response.text
- # soup=BeautifulSoup(page_text,'html.parser')
-
- # 二、数据解析的方法和属性
- # 1.soup.tagName返回html中第一次出现的tagName标签
- print(soup.a)
-
- # 2.soup.find("tagName)等同于soup.div
- print(soup.find('a'))
- print(soup.find('div',class_='left'))
-
- # 3.返回符合要求的所有标签(列表)
- print(soup.findAll('a'))
-
- # 4.选择器,返回列表 id class 标签 ……
- print(soup.select('.left'))
-
- # >表示一个层级
- #空格表示多个层级
- print(soup.select('.left>ul>li'))
-
- # 三、获取标签之间文本数据
- soup.a.text soup.xxx.get_text()#获得所有内容,不是直系的内容也可以获得
- soup.xxxx.string #只能直系内容
-
- # 四、获取标签属性值
- # soup.select('.left a')['href'] 不可以
- print(soup.a['href'])
爬虫实践
1.爬目录
-
- import requests
- from bs4 import BeautifulSoup
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
- url='https://www.shicimingjv.com/bookindex/75.html'
- response=requests.get(url=url,headers=headers)
- print(response)
- html=response.text
- soup=BeautifulSoup(html,'html.parser')
- all_ul=soup.findAll('ul',class_='book-tags')
- all_title=soup.findAll('h4')
- # print(all_title)
- # print(all_ul)
- # for ul in all_ul:
- # all_li=ul.findAll('li')
- # # print(all_li)
- # for li in all_li:
- # print(li.text )
- # print("*****************")
- for i in range(len(all_ul)):
- print(all_title[i].text)
- # print(all_ul[i].text)
- # print(all_ul[i].findAll('li'))
- all_li=all_ul[i].findAll('li')
- for li in all_li:
- a=li.a
- #a=li.find('a')也可以
- print(a.text)
-
- print("________________________________________")
-
- #其实直接ul.text也行的 反正文字也没有别的了
2.爬目录+详细内容
这有点鸡肋,在详情页也可以爬到标题啊
-
- import requests
- from bs4 import BeautifulSoup
- headers = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- }
- url='https://www.shicimingjv.com/bookindex/78.html'
- response=requests.get(url=url,headers=headers)
- print(response)
- html=response.text
- soup=BeautifulSoup(html,'html.parser')
-
- # print(soup.a)
- # 1.爬取标题和超链接
- # 通过超链接再爬取详情页内容
- all_titles=soup.select('.book-tags li a')
- # print(all_titles)
- i=0
- for item in all_titles:
- url2=item['href']
- # print(url2)
- response2=requests.get(url=url2,headers=headers)
- html2=response2.text
- soup2=BeautifulSoup(html2,'html.parser')
- all_p = soup2.findAll('p')
-
- # 获取详细内容
- content=""
- for p in all_p:
- p = p.text.strip()
- content+=p+'\n'
-
- # print(content)
-
- #优化 一步搞定获取内容
- #content=soup2.find('div',class_='entry-content').text
-
- fileName=str(all_titles[i].text)
- filePath='./shangjunshu/'+fileName+'.txt'
- with open(filePath,'w',encoding='utf-8' ) as fp:
- fp.write(content)
-
- i+=1
- print(fileName+'succeed')
-
-
- xpath
最常用、最便捷、通用性最好
解析原理:
- 实例化etree对象,讲页面源码数据加载到该对象中
- 调用该对象的xpath方法,结合xpath表达式,实现标签定位和内容捕获
基础知识
- # 实例化etree对象
- from lxml import etree
- # 本地
- etree.parse(filePath)
-
- # 互联网
- etree.HTML('page_text')
- from lxml import etree
-
- tree = etree.parse("hhh.html", etree.HTMLParser())
- # print(tree)
-
- # / 表示从根节点开始定位,表示一个层级
- r = tree.xpath('/html/head/title')
-
- # // 表示多个层级
- r = tree.xpath('/html//title')
-
- # // 表示从任意位置开始定位
- r = tree.xpath('//title')
-
- # 属性定位 tagName[@attrName="attrValue"
- r = tree.xpath('//div[@class="left"] ')
-
- # 索引定位 下标从1开始
- r = tree.xpath('//div[@class="left"]/ul[1] ')
-
- # 取出文本
- r = tree.xpath('//div[@class="left"]/ul[1]/li[2]/a/text() ') # ['love']
- r = tree.xpath('//div[@class="left"]/ul[1]/li[2]/a/text() ')[0] # love
-
- # /text()获取标签中直系的内容
- r = tree.xpath('//div[@class="left"]/ul[1]/li[2]/text() ') # 空,啥也没有,因为不是直系的文字
-
- # //text()非直系 所有文字
- r = tree.xpath('//div[@class="left"]/ul[1]/li[2]//text() ') #
- r = tree.xpath('//div[@class="left"]/ul[1]//text() ') #['wwwwww', 'love', '\r\n ']
-
- # 取属性 /@sttrName
- r = tree.xpath('//div[@class="right"]/img/@src ')
-
-
- 局部解析是./
-
- #或
- r = tree.xpath('//div[@class="left"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
- print(r)
【实战1】——58同城二手房爬取
- from lxml import etree
- import requests
- # 1.爬取页面源码数据
- url = "https://dl.58.com/ershoufang/"
- headers = {
- # "User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
-
- }
- # response=requests.get(url=url,headers=headers)
- # html=response.text
- # print(html)
- # with open('./58.html','w',encoding='utf-8') as fp:
- # fp.write(html)
-
- # 加上utf-8就不会是乱码了
- tree=etree.parse('./58.html',etree.HTMLParser(encoding='utf-8'))
-
- all_title=tree.xpath('//h3[@class="property-content-title-name"]/@title')
-
- all_detail=tree.xpath('//p[@class="property-content-info-text property-content-info-attribute"]//text()')
-
- all_totalPrice=tree.xpath('//p[@class="property-price-total"]//text()')
- fp=open('./house58.txt','w',encoding='utf-8')
- for i in range(0,len(all_title)):
- all_str=all_title[i]+"\n详情:"+str(all_detail[i*11:11+i*11])+"\n总价:"+str(all_totalPrice[i*3:3+i*3])
- all_str=all_str.replace('[','').replace(']','').replace('\'','').replace(" ",'').replace(",",'')
- all_str+='\n____________________________________________________________________________________\n'
- fp.write(all_str)
-
【实战2】——图片爬取
- from lxml import etree
- import requests
- headers = {
- # "User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
-
- }
-
- for i in range(1,4):
- if i==1:
- url='http://pic.netbian.com/4kdongman'
- else:
- url='http://pic.netbian.com/4kdongman/index_{:d}.html'.format(i)
- print(url)
- response=requests.get(url=url,headers=headers)
- # 解决乱码 【方法一】 不好用
- response.encoding='utf-8'
-
- # 解决乱码 【方法二】 好用
- response.encoding='gbk'
-
- print(response)
- html=response.text
-
- # tree=etree.parse('./img_4k.html',etree.HTMLParser(encoding='utf-8'))
-
-
-
- tree=etree.HTML(html)
- all_src = tree.xpath('//ul[@class="clearfix"]/li/a/img/@src')
- all_name = tree.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
- # print(all_name)
- # print(all_src)
- for j in range(len(all_src)):
- # http://pic.netbian.com/uploads/allimg/230602/002954-16856369943b94.jpg
- src="http://pic.netbian.com/"+all_src[j]
- fileName=str(i)+str(all_name[j])
- print(fileName)
- filePath = "./dongman_img/" + fileName + '.jpg'
-
- # 解决乱码 【方法三】 不好用
- # fileName=fileName.encode('iso-8859-1').decode('gbk')
-
-
- print(fileName)
- response2= requests.get(url=src,headers=headers)
-
- # 要用content返回二进制数据,别i+的都不行
- content=response2.content
- with open(filePath, 'wb') as fp:
- fp.write(content)
- print(fileName+'succeed!!!!')
- print("______________________________________________________")
【实战3】——爬取免费简历模板
- from lxml import etree
- import requests
- import re
- headers = {
- # "User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
- }
- fp=open('./jianli.txt','w',encoding='utf-8')
- url="https://sc.chinaz.com/jianli/free.html"
- response=requests.get(url=url,headers=headers)
- response.encoding='utf-8'
- print(response)
- html=response.text
-
- # 'gbk' 'utf-8' 'iso-8859-1'
- # with open('./jianli.html','w',encoding='iso-8859-1') as fp:
- # fp.write(html)
-
- # encoding='gbk'就什么都解析不出来
-
- # iso-8859-1 就是乱码
- # 响应内容的实际编码与 response.encoding 不匹配,可能会导致乱码问题
- # tree=etree.parse('./jianli.html',etree.HTMLParser(encoding='utf-8'))
-
- tree=etree.HTML(html)
-
- # 获取总页数
- all_page=tree.xpath('//div[@class="pagination fr clearfix clear"]/a/@href')
- print(all_page)
- page_li=[]
- for i in all_page:
- page_num=re.findall("free_(\d{1,}).html",i)
- # print(page_num)
- page_li.append(page_num)
- max_page_num=max(page_li)
- print(max_page_num)
- # 为了避免内存爆了,就先爬3页
- page=3
-
-
- # 爬每一页
- for page in range(1,4):
- if page==1:
- url="https://sc.chinaz.com/jianli/free.html"
- else:
- url="https://sc.chinaz.com/jianli/free_{:d}.html".format(page)
- print(url)
- response_page = requests.get(url=url, headers=headers)
- response_page.encoding = 'utf-8'
- # print(response_page)
- page_html = response_page.text
- page_tree=etree.HTML(page_html)
- all_href=page_tree.xpath('//div[@class="box col3 ws_block"]/a/@href')
-
-
- # 爬取详情页面
- for i in range(len(all_href)):
- url2=all_href[i]
- response_detail=requests.get(url=url2,headers=headers)
- response_detail.encoding='utf-8'
- # print(response_detail)
- detail_html=response_detail.text
- # with open('./detailHTML.html','w',encoding='iso-8859-1') as fp:
- # fp.write(detail_html)
- detail_tree=etree.HTML(detail_html,etree.HTMLParser(encoding='utf-8'))
- all_download_href=detail_tree.xpath('//div[@class="clearfix mt20 downlist"]/ul/li/a/@href')
- download_name= str(detail_tree.xpath('//div[@class="ppt_tit clearfix"]/h1/text()')[0] )
- # print(download_name)
- content=download_name+" 福建电信下载链接:"+all_download_href[0]+'\n\n'
- fp.write(content)
- print(download_name+" 福建电信下载链接:"+all_download_href[0])
- print("\n___________________________________________________________________________\n")
- fp.close()
Pycharm快捷键:
ctrl+Alt+L 代码格式化
shift+tab 取消缩进

