
- 1基于 Lagrange分布式算法的电动汽车充电调度模型-matlab代码_拉格朗日分布算法的电动汽车充放电调度
- 2如何从命令行在Linux和Windows中打印当前日期和时间?
- 3Unity中UI方案。IMGUI、UIElement、UGUI、NGUI_ngui如何可视化编辑
- 4【jetson笔记】torchaudio报错_导入torchaudio报错
- 5经典机器学习算法:逻辑斯谛回归
- 6简单又实用java爬虫超快入门
- 7如何在C#中调用Python程序_c# 调用powershell 执行python程序
- 82022前端工程师面试过程分享_前端开发电话面试流程
- 9基于FPGA的数据采集系统设计总结(dds和ad)_fpga 的频率采集模块
- 10git&github自学(8):发起Pull Request_pull requests
IPFS系列02-IPFS 与 web3.0_用了ipfs还需要web3吗
赞
踩
IPFS 将对互联网协议进行一次重塑,互联网将进入 web3.0 时代。
本文我们聊一聊 ipfs 如何能助力让互联网进入 web3.0 时代。
1. web3.0 的特点
尽管现在业界对 web3.0 没有明确的定义,但是业界一些大神提出了 web3.0 应该具有以下特点:
- web3.0 应该是一个分布式的,去中心化的可信网络,它是一个真正的公共载体
- web3.0 时代整个互联网将变成一个巨大公共数据库
- web1.0 是机器与机器互联,web2.0 是人与人互联,web3.0 应该是万物互联
2. http 的缺陷
http 是 web1.0 以及 web2.0 的基础协议,互联网的本意是要开放,互联,去中心化,它基于 http 协议,
但是 http 一个脆弱的、高度集中的、低效的、过度依赖于骨干网的协议。
2.1 http 非常脆弱
我们首先来看一张图片:

据说这是史上第一台 http 服务器,上面贴的纸条是不是特别眼熟,“这台机器是服务器,不要关机!”。这将 http 服务器的脆弱性完美的呈现出来。
为什么不能关机,因为这台服务器关闭之后整个服务就瘫痪了。
你也许经常看到这样的结果:

如果你对 http 协议稍有了解的话,你都会知道这代表你要访问的资源被删除了。
发生这种情况的原因很简单:中心化管理的 Web 服务器不可避免地会关闭。域名更改所有权,或者运行它的公司破产。或者计算机崩溃,没有备份来恢复内容。
前段时间我清理了自己的网页收藏夹,发现居然有 30% 的收藏页面现在居然打不开了。
2.2 http 鼓励中心化
不管我们是否承认,现在几乎我们使用的 90% 的互联网服务都来自不到 1% 网站提供,甚至数十亿的用户不得不依赖少数几个公司提供的服务。http 使得 web
越来越中心化。
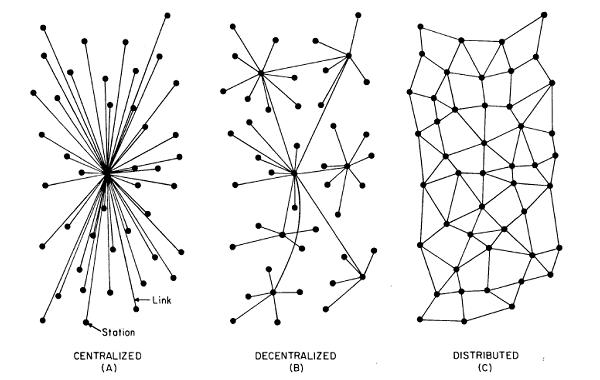
http 对主干网的过度依赖,使得对互联网的监听和审查变得非常低,只需要拦截几个主干网就可以轻松实现。
而且 Internet 骨干网并不健全,其很容易被攻击,同时一些重要的光纤线路被切断时服务很容易遭受影响。
随着互联网的影响力越来越大,政府和企业都开始撬开 http 的缺陷,利用它们来监视用户,并阻止用户访问任何对他们构成威胁的内容。
2011年1月28日,埃及切断了全国的互联网。
从下图可以看到,1月27日午夜,埃及的国际数据流量一下子跌到了接近零。
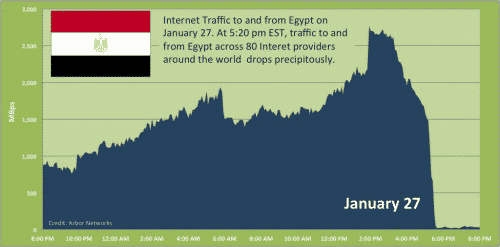
骨干网上,埃及与外界连通的3500个路由器,都没有回应。对于埃及民众来说,互联网已经彻底无法使用了,任何网站都打不开;
对于国外访问者来说,不仅打不开埃及网站,甚至连IP地址也找不到,好像它们根本不存在一样。
国际路由表(global routing table)上,凡是与埃及有关的表项都失效了。埃及政府成功地使本国在一夜之间脱离了互联网,“把自己从世界地图上抹去了”。
中心化带来的另一风险就是,使我们的通信面临被 DDoS 攻击中断的风险。
2.3 http 效率低下,成本高昂
首先我们来说说效率问题,假设你正在腾讯视频看《复仇者联盟4》的 4K 视频,你的坐标在北京,而腾讯的服务器却在深圳(先不考虑 CDN),
这样你不得不等待视频从深圳传输到北京,如果你的网速足够快,而且此时只有一个人在看,你可能感觉不到卡顿的情况。但是如果此时北京还有 1000 个用户跟你一样也在
看《复仇者联盟4》,这个时候相当于腾讯的服务器需要从深圳同时传输 1000 视频到北京,这个时候你的观影体验就会极速下降,变成"缓冲五分钟,观影三分钟"。
于此同时,腾讯将要向 ISP 服务商付出高昂的成本来分发这些视频数据,假设《复仇者联盟4》这部电影的 4K 视频是 2GB,那么 1000 用户总共需要分发接近 2TB 的数据。
假设按照每1GB 0.1RMB 算,总共需要支付 200 RMB,好像也不多,但是事实上像《复仇者联盟4》这种热门电影的观看次数一般都过亿的,
这样算来腾讯需要支付 2000 万来完成数据分发。
如果我们可以将 ISP 网络上的每台计算机变成流式 CDN,而不是总是从数据中心提供这些内容,那该怎么办?
像一些热门视频甚至可以从ISP的网络中完全下载,不需要通过互联网骨干网进行大量跳跃。这就是 ipfs 要解决的问题。
3. IPFS 如何实现目标
我们已经讨论了http 的缺陷(以及超中心化的问题),现在让我们谈谈IPFS如何以及如何帮助改进网络。
首先 ipfs 从根本上改变了我们搜索互联网文件的方式,它是一种基于内容寻址、版本化、点对点超媒体的分布式存储、传输协议。
我们通过 http 去访问一个文件时,首先需要通过 IP 地址定位文件所在的服务器,然后还需要知道文件的路径,才能正确的访问到一个文件,
这种模式叫做IP和路径寻址。
而在 ipfs 网络里,当文件被添加到 ipfs 节点时候,ipfs 会根据文件的内容生成一个加密哈希值(以 Qm 开头),你只要知道这个哈希值,
就可以根据哈希值定位道这个文件,这种模式叫做内容寻址。密码学保证该哈希值始终只表示该文件的内容。哪怕只在文件中修改一个比特的数据,哈希都会完全不同。
4. IPFS 工作原理
当我们往 IPFS 节点添加一个文件时,如果文件大小超过 256K(这个值可以设置),IPFS 会自动将文件分片,每个分片 256K,然后将切片分散存储到网络的各个节点中
(不过笔者测试发现目前实现的版本还只是将所有分片存储在当前节点)。每个分片都会生成唯一的哈希,然后把所有的分片的哈希值拼接之后在计算得到该文件哈希。
每个 IPFS 节点都会保存一张分布式的哈希表(DHT),包含数据块与目标节点的映射关系。无论哪个节点新增了数据,都会同步更新 DHT。
当我们需要访问这个文件的时候,IPFS 通过使用一个分布式哈希表,可以快速(在一个拥有 10,000,000 个节点的网络中只需要 20 跳)
地找到拥有数据的节点,获取文件的所有分片哈希,然后重新组合成完整的文件,并使用哈希验证这是否是正确的数据。
如果你启动了 IPFS 的守护进程,
可以通过 http://127.0.0.1:5001/api/v0/object/get?arg={hash} 这个 API 很方便的获取整个文件的所有分片:
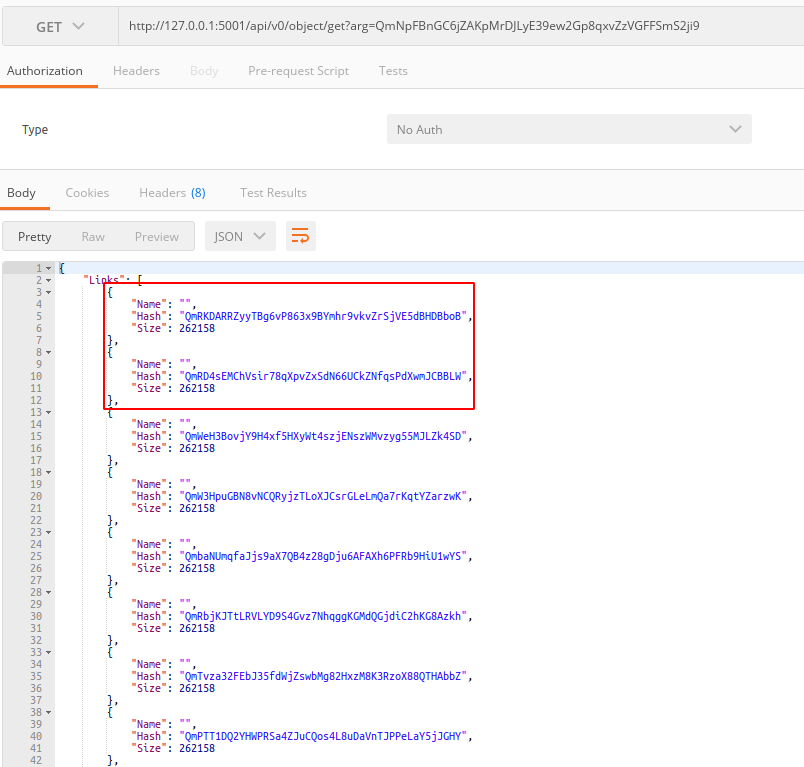
而且 IPFS 不需要每个节点存储所有发布到 IPFS 上的内容。相反,每个节点只存储自己想要的数据。只有当访问某个文件的时候,节点才会去下载(同步)它。
从 IPFS 的原理我们可以看出 IPFS 是可以解决现有 http 协议的一些缺陷的:
- 使网站脱机变得很困难,如果有人攻击维基百科的网络服务器或维基百科的工程师犯了一个大错误,导致他们的服务器着火,你仍然可以从其他节点获得相同的页面。
- IPFS 节点的上面的文件只能添加,无法删除,确保不会出现 http 404 这样的错误,并且如果你修改一个文件重新添加,IPFS 会重新生成跟原文件不同的哈希值,
篡改后的文件在 IPFS 网络里面是新的文件,你通过原来的哈希访问的一定是你添加的的那个文件,而不是篡改后的文件。 - 使主管部门审查内容变得更加困难,因为 IPFS 上的文件可能来自很多地方,并且因为其中一些地方可能就在附近,
由于它不需要主干网,所以政府或者组织想要拦截数据进行审查几乎做不到。像土耳其阻止维基百科和西班牙阻止访问加泰罗尼亚独立网站这种事情将不会再发生。 - 理论上只要网络足够大,IPFS 分布式网络将很快成为世界上最快、最可用、以及最大的数据存储网络。任何节点宕机都不会影响 IPFS 网络对外提供服务,
没有人有能力关闭所有的节点,所以数据永远不会丢失。 - 由于 IPFS 网络是基于内容寻址的,所以它天然就抗 DDoS 攻击,因为你不知道数据存储在哪,无法找到攻击目标。
- IPFS 采用分片存储,而相同的分片哈希值是相同的,因此 IPFS 网络中不会存储两个相同的分片,既节省了存储空间,又节省了带宽。
5. IPNS
IPFS 哈希代表不可变的数据,这意味着它们是不能被更改的,否则会导致哈希值的变更。这是一件好事,因为它鼓励数据的持久性,
但如果一个网站内容每天都有更新的话,意味着这个网站的地址每天都在改变,作为用户来说,这是无法接受的。
IPFS 提供了一个特殊的解决方案 IPNS (Inter-Planetary Naming System),它允许用户使用公钥作为代表网站根目录的哈希的引用,然后使用私钥对引用进行签名。
由于公钥是保持不变的,所以用户不需要每次更改地址,每次站点更新只需要重新生成新的引用然后签名就好了。
可以简单理解为通过节点 ID 对项目根目录的 IPFS 哈希进行绑定,以后我们访问网站时直接通过节点 ID 访问就好了。
虽然解决了站点更新的问题,但是 IPFS 的哈希值毫无规律,很难记忆,可读性极低。因此 IPNS 允许你使用现有的 DNS 来提供人类可读的网站地址,
它通过允许您将哈希值插入名称服务器上的 TXT 记录来实现此目的:
dig TXT www.r9it.com
- 1
接下来我们就可以通过 http://ipfs.io/ipns/www.r9it.com/ 来访问站点了。
5. IPFS 网关,新旧网络之间的桥梁
想要访问 IPFS 网络中的文件,你有三种方式:
- 通过 IPFS 客户端命令行工具
- 通过 IPFS 的浏览器插件,IPFS 伴侣
- 通过 IPFS 节点内置的 http 网关(http://127.0.0.1:8080)
前两个中方式访问起来比较麻烦,但是 IPFS 网关允许用户实现 http 和 IPFS 的无缝对接,用户可以开始慢慢的把他们的服务迁移到 IPFS 网络了。
7. IPFS 与 web3.0
鉴于上面我们对于 IPFS 的分析,IPFS 最终的目标是取代 http 协议,成为第三代互联网的基础协议。结合 web3.0 网络的特点,我们可以预见,
IPFS 对 web3.0 的到来起到了一定的铺路作用。
- 首先,IPFS 结合区块链可以实现一个分布式的,可信的网络。
- 其次,IPFS 可以把整个互联网改造成一个巨大的存储系统。
- 再次,IPFS 提出的点对点超媒体协议,为万物互联提供了底层协议解决方案。
8. 参考链接
本文首发于 小一辈无产阶级码农

