
- 1Android studio如何更改应用程序的图标以及名称_android studio 使用系统图标,选哪个
- 2【flink脚本系列】 historyserver.sh功能用法示例源码解析_flink historyserver.sh
- 3前端数据可视化基础(折线图)_折线图前端
- 4智能金融的三驾马车之机器学习_机器学习马车
- 5C#报错:未将对象设置到对象实例 Object reference not set to an instance of an object
- 6SSL/TLS协议信息泄露漏洞(CVE-2016-2183)【原理扫描】远程桌面 3389 Windows 2016_cve-2016-2183 windows
- 7vue build 优化_viet build 加源码
- 8阿里云视频点播视频播放出现network timeout问题处理_阿里云视频 network retry timeout for 2 times
- 9uploads-labs 21关通关攻略(上)_upload-labs 21关
- 10rocketmq一个消费者有多个服务器_RocketMQ消息消费概览
ElasticSearch核心基础之映射_es elasticsearch 字段 映射 类型
赞
踩
一 mapping相关的概念
1.1 映射类型
映射类型也就是我们所谓的type,一个索引可以一个或者多个类型。每一个映射类型包括:
# 元数据字段:用来定义如何处理文档的元数据。元数据字段包括文档的_index字段、_type、_id、_source字段等
# 字段或者属性,每一个类型都包括一些字段
注意:相同索引,但是类型不同,而名字相同的字段的数据类型必须一致,即拥有相同的映射
1.2 字段数据类型
字符串类型:string(2.x系列) text(5.x)
日期类新:date
长整型:long
双精度浮点:double
布尔类型:boolean
IP类型
1.3 动态映射
字段和属性不需要预先事先定义。在你添加文档的时候,就会自动添加到索引,这个过程不需要事先在索引进行字段数据类型匹配之类,他会自己推断数据类型,动态映射是可以配置的。
1.4 显示映射
和动态映射相反,显示映射需要我们在索引映射中进行预先定义
1.5 更新当前映射
一般我们不会改变当前的索引的映射类型和字段,因为这样,意味着废弃已经索引的文档。我们应该根据映射创建新的索引并重新索引数据
1.6 DocValues和 FieldData
我们知道什么是倒排索引和正排索引:前者适合搜索,后者适合排序和聚合等。故DocValues 和 FieldData列式存储做分析。
因为聚合分析和搜索有很大的不同。典型的场景,比如计算某个文档中每个关键词的出现次数,反向索引就无能为力了,需要先扫描整个关键词映射表,才能找到该文档包含的所有关键词,然后再进行聚合统计,也就是要对整个反向索引做全扫描,在数据量大的时候,性能当然好不到哪里去。
所以,Elasticsearch为聚合计算引入了名为fielddata的数据结构,其实就是根据反向索引再次反向出来的一个正向索引,也就是文档到关键词的映射。
那么无论排序还是聚合我们只需要在fielddata选择对应的docId,然后对某列进行排序或者聚合就好,而且fielddata是保存在内存中的。
因为内存是有限的,所以不可能预先为所有的字段都建立fielddata,只能是由具体的搜索需求来触发
现在fielddata的问题我们已经知道了,就是对内存的要求较高,如果数据量太大,对于JVM来说垃圾回收也存在不稳定的影响。所以在这种场景下,提出来DocValues。从数据结构来讲,DocValues和fielddata一样都是正向索引,但是实现方式不同,DocValues是需要持久化到存储文件中的,并且是预先构建,也就是数据生成反向索引的同时,就会生成DocValues,这会消耗额外的存储空间,但是对于JVM的内存需求就会减少。总体来看,DocValues只是比fielddata慢一点,大概10-25%,则带来了更多的稳定性。
二 字段数据类型
核心数据类型
# 字符串类型:string
# 数字型数据类型:long、integer、short、byte、double、float
# 日期类型:date
# 布尔类型:boolean
# 二进制数据类型:binary
复杂数据类型
# 数组:无需专门的数据类型
# 对象数据类型:object,单独的JSON对象
# 嵌套数据类型:nested,关于JSON对象的数组
地理数据类型:
# 地理点数据类型:geo_point,经纬点
# 地理形状数据类型:geo_shape
专门数据类型:
# IPv4数据类型
# 完成数据类型:completion
# 单词计数数据类型:token_counts
2.1数据类型可以接收的参数
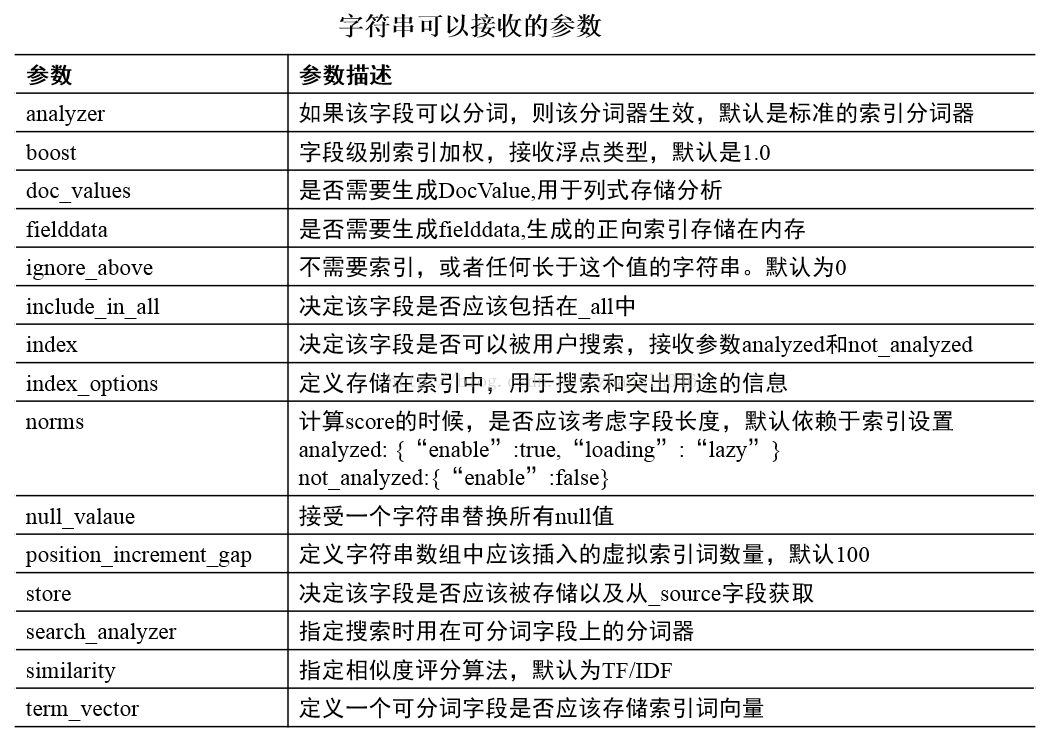
2.1.1 字符串可以接收的参数
2.1.2 数字型可以接收的参数

2.1.3 日期型可以接收的参数

2.1.4 布尔型可以接收的参数

三 元数据字段
每一个文档都有与之关联的元数据,元数据字段是为了保证系统正常运行内置字段,比如_index表示索引字段,_type表示映射类型,_id表示文档主键,这些字段都是以下划线开始的。当映射类型被创建,可以自定义一些元数据中字段。
3.1_all
_all是一个包含全部内容字段,常用场景:
# 获取所有文档
GET /_all
但是没有:
GET /ecommerce/_all
GET /ecommerce/product/_all
# 利用_all字段进行搜索
在ecommerce索引中针对所有字段搜索Guitar
GET /ecommerce/_search
{
"query": {"match": {"_all":"Guitar"}}
}
_all字段一般需要耗费更多的时间和资源,如果没有必要的话,可以完全禁用
3.2 _field_names
它索引文档中所有包含非空值的字段名称。_field_names用于存在查询和缺失查询的情况下,查找指定字段拥有非空值文档是否存在
PUT /secisland/secilog/1
{
"title":"This is a document"
}
PUT /secisland/secilog/2
{
"title":"This is another document",
"body":"This document has a body"
}
GET /secisland/secilog/_search
{
"query": {
"terms": {"_field_names":["body"]}
}
}
由于第一个文档,不存在body字段,所以只返回第二个文档
3.3_id
每一个被索引的文档都会关联一个_type字段和_id字段。_id字段没有索引,他的值可以从_uid字段自动生成
_id可以你在查询中访问
GET /secisland/secilog/_search
{
"query":{"terms":{"_id":["1","2"]}}
}
3.4_index
在多个索引中执行查询的时候,有时候需要添加查询子句来关联特定的索引文档。_index字段可以匹配包含某个文档的索引。在term或者terms查询,聚合或者排序的时候,可以访问_index字段的 值
PUT web/blog/1
{
"text": "Document in index 1"
}
PUT site/blog/2
{
"text": "Document in index 2"
}
GET web,site/_search
{
"query": {"terms": {"_index":["web", "site"] }
},
"aggs": {"indices": {"terms":{"field": "_index", "size": 10}}
},
"sort": [{"_index": { "order":"asc"}}
],
"script_fields": {
"index_name": {"script": {"lang":"painless","inline": "doc['_index']" }
}
}
}
3.5_parent
父类型和子类型必须是不同的,即父子关系不能建立在相同类型的文档之间。_parent的type设置只能指向一个当前不存在的类型,这意味着一个类型被创建后无法成为父类型
父子文档必须索引在相同的分片上
PUT secislands
{
"mappings": {
"my_parent": {},
"my_child": {"_parent": {"type":"my_parent" }}
}
}
PUT secislands/my_parent/1
{
"text": "This is a parent document"
}
PUT secislands/my_child/1?parent=1
{
"text": "This is a child document"
}
PUT secislands/my_child/2?parent=1&refresh=true
{
"text": "This is another child document"
}
3.6_routing字段
文档索引中利用如下公式路由到特定的分片:
shard_num = hash(_routing) % num_primary_shards
如果我们不指定_routing的值,默认就使用文档的_id字段,如果存在父文档则使用_parent编号
可以通过为梅雨歌文档指定一个自定义的路由值来实现自定义的路由方式:
PUT /web/blog/1?routing=xxx
_routing字段可以在查询、聚合排序时候访问;
比如搜索的时候,可以直接指定路由值,然后根据这个值进行hash
GET ecommerce/_search
{
"query": {
"terms": {"_routing": [ "Guitar" ] }
}
}
GET my_index/_search?routing=bestseller,onsale
{
"query": {
"match": {
"title": "document"
}
}
}
3.7 _source
存储的文档的原始值。默认_source字段是开启的,也可以关闭:
# 我们还可以禁止返回原始数据即_source
GET http://127.0.0.1:9200/ecommerce/product/1? _source=false
# 如果你只想获取source一部分内容,可以使用_source_include或者_source_exclude参数
GET /ecommerce/product/4?_source_exclude=desc,type
GET /ecommerce/product/4?_source_include=name,price,reviews
3.8_type
即映射类型,每一个索引文档都包含_type和_id字段,索引_type字段的目的是通过类型名加快搜索进度
_type字段可以在查询,聚合排序时访问
3.9_uid
_uid和_type和_id的组合。和_type一样,可用于查询、聚合、脚本和排序。例子如下:
PUT my_index/my_type/1
{
"text": "Document with ID 1"
}
PUT my_index/my_type/2?refresh=true
{
"text": "Document with ID 2"
}
GET my_index/_search
{
"query": {"terms": {"_uid": ["my_type#1", "my_type#2" ] }},
"aggs": {"UIDs": {"terms":{"field": "_uid", "size": 10}}},
"sort": [{"_uid": { "order": "desc"}}],
"script_fields": {"UID": {"script":{"lang": "painless", "inline":"doc['_uid']" }}
}
}
四 映射参数
4.1 anylyzer
指定分词器(分析器更合理),对索引和查询都有效。如下,指定ik分词的配置:

每一个查询,字段或者索引都可以指定分析器,在
创建索引的时候,ES会下面的顺序查找分析器:
# 在字段映射中定义的分析器
# 在索引设置中的分析器
# 标准分析器
查询的时候,ES会下面的顺序查找分析器:
# 在全文查询中定义的分析器
# 在字段映射中的搜索分析器(search_analyzer)
# 在字段映射中的分析器
# 在索引设置中名为default_search分析器
# 在索引设置中名为default分析器
# 标准分析器
4.2 boost参数
在索引的时候可以对一个字段进行加权,在查询的也需要指定boost

4.3 normalizer
normalizer用于解析前的标准化配置,比如把所有的字符转化为小写等

4.4coerce
数据不一定都是干净的,强制尝试清理脏值来匹配字段的数据类型
# 字符串会被强制转换成数字
# 浮点型数据会被截取为整形数据等

以上例子第二个put会报错,因为要求是integer,但是提供了一个string类型,但是coerce又给禁用了,所以就会报错
我们也可以全局设置index.mapping.coerce
4.5copy_to
我们可以利用copy_to创建自定义的字段,即复制到一个字段中:

4.6 doc_values
doc_values: 是否需要建立该字段的可存储在磁盘上的正排索引

4.7 fielddata
fielddata:是否需要建立该字段的可存储在内存上的正排索引。大多数字段可以使用索引时存储在磁盘上的doc_values值来实现正向索引访问的需求。但是分析过的字符串字段不支持doc_values。分词的字符串会在查询的时候利用fielddata的数据结构,fielddata不是预加载的,默认是关闭的,所以确实是需要才需要打开这个字段,比如该字段需要聚合排序等。因为加载字段数据是一个昂贵的过程,一旦被加载,就会在分片的生命周期内驻留内存。
# format: 对于分词字符串字段,format用于控制fielddata是否被启用,接收参数为disabled和page_types(默认启用)。如果要禁用fielddata,可以使用下面的设置:
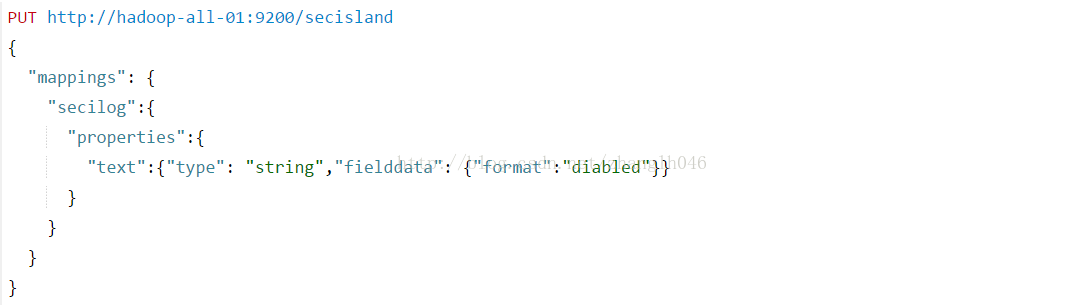
如果一旦禁用,该字段就不能进行排序,聚合或者脚本引用
# loading: 控制什么时候字段数据会被加载到内存,接收三个参数:
lazy: 字段数据仅在需要的时候加载到内存,默认就是这个
eager: 饿汉式预先加载
当一个新的段形成时,无论是刷新还是合并,可以预先加载的字段提前把段的fielddata加载到内存,当你第一次查询的时候,如果碰到在这个段上,你不需要再触发加载fielddata的操作,它们已经在内存中了
eager_global_ordinals: 饿汉式(预先加载)全局序数。
就像预先加载fielddata一样,全局序数会在一个新的段可进行搜索之前进行构建。
注意:序数只用于字符串类型的field,数值类型(整型,地理位置,时间等)都不需要一个序数映射,因为他们自身就是一个内存的序数映射。
什么是全局序数?
一项用于减少string类型的fielddata占用内存的技术叫做序数。

# filter: 可以用来过滤加载到内存中的索引词的数量,这么做可以减少内存使用量。索引词可以通过频率或者正则表达式以及两者的配合进行过滤
使用频率过滤:
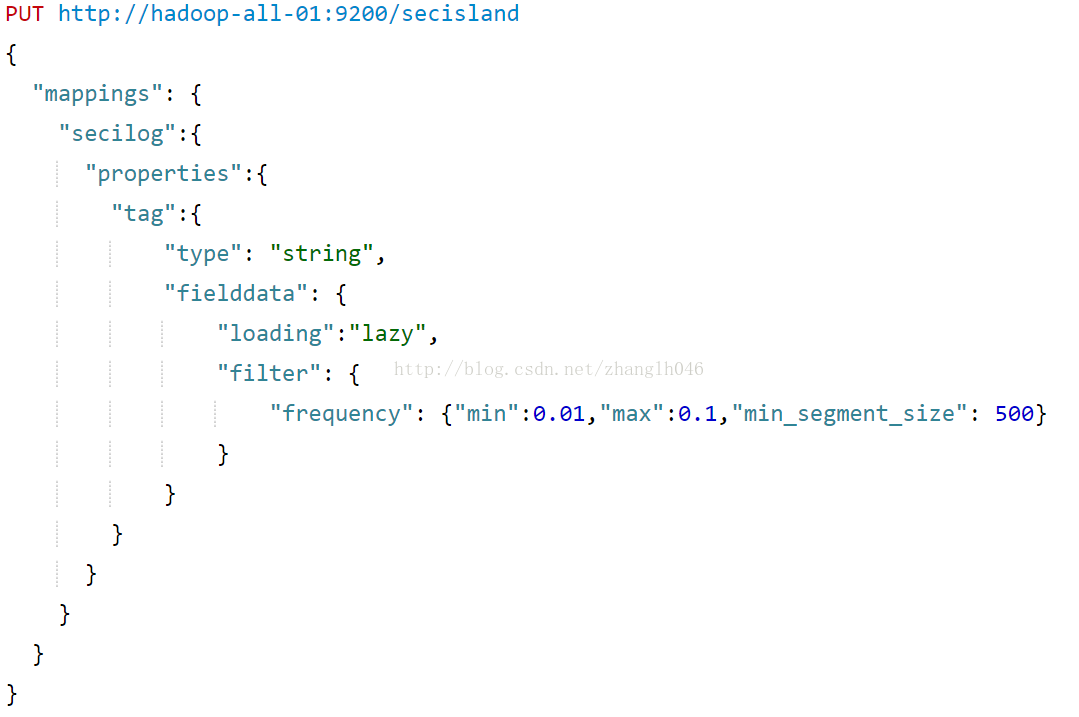
如上图所示:min表示最小频率,max表示最大频率,min_segment_size表示分片应该包含的最少文件来排除小容量分片
使用正则过滤:

4.8dynamic
dynamic属性用于检测新发现的字段,有三个取值:
true:新发现的字段添加到映射中。(默认)
flase:新检测的字段被忽略。必须显式添加新字段。
strict:如果检测到新字段,就会引发异常并拒绝文档。

4.9enabled
在有些情况下,仅仅需要存储字段而不是进行索引。enabled设为false的字段,ES会跳过字段内容,该字段只能从_source中获取,但是不可搜。而且字段可以是任意类型。

如果针对title搜索,不会搜索到任何记录
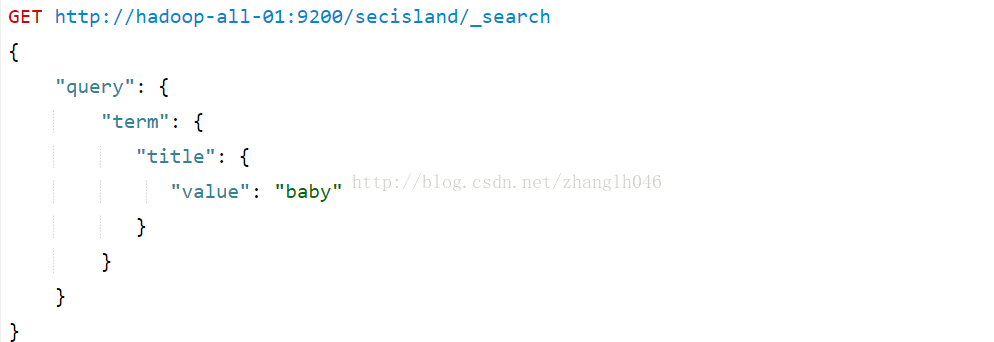
针对content是可以搜到的
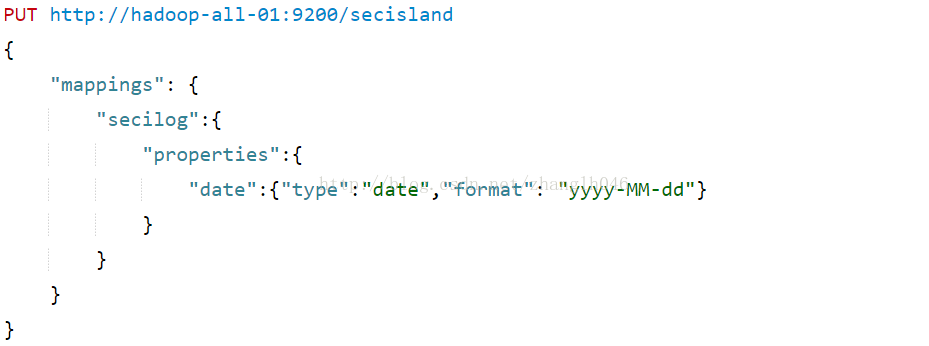
4.10 format
format属性主要用于格式化日期:
4.11ignore_above
比ignore_above设置的值更长的字符串不会被分词或者索引,主要用于不分词字符串字段,这些字符串通常用来过滤、聚合以及排序
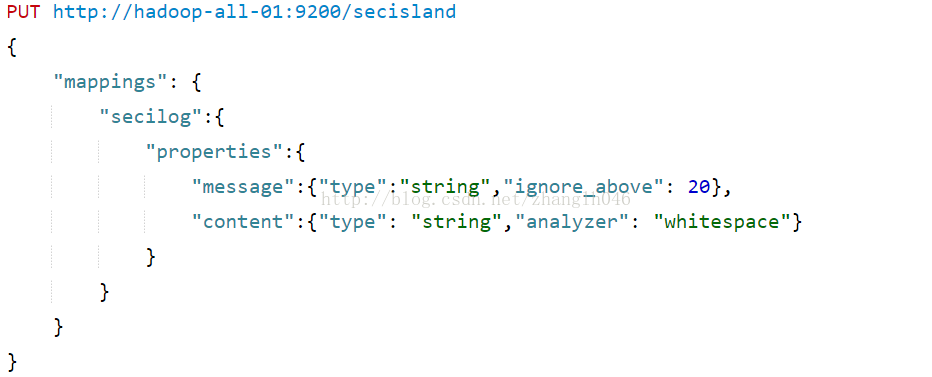
由于message字段如果大于20,虽然文档为被索引,但是该字段是不能搜索。这意味着下面的2个doc,如果搜索hadoop可以搜索出来,但是搜索spark时搜索不到的

4.12ignore_malformed
是否忽略异常的字段,如果设置为true,异常会被忽略;如果设置为false,错误字段不会被处理,但是其他字段还是会正常处理

4.13include_in_all
include_in_all用于控制每一个字段是否包含在_all字段里,默认为true,除非显示设置为false

4.14index
控制字段值如何进行索引,指定字段是否索引,不索引也就不可搜索
no: 不要在索引中加入这个字段
not_analyzed:字段值原封不动的添加到索引中,作为单一索引词,除了字符串之外其他类型默认就是这个
analyzed:仅用于字符串字段中,会根据分词分为一组索引词,然后被索引
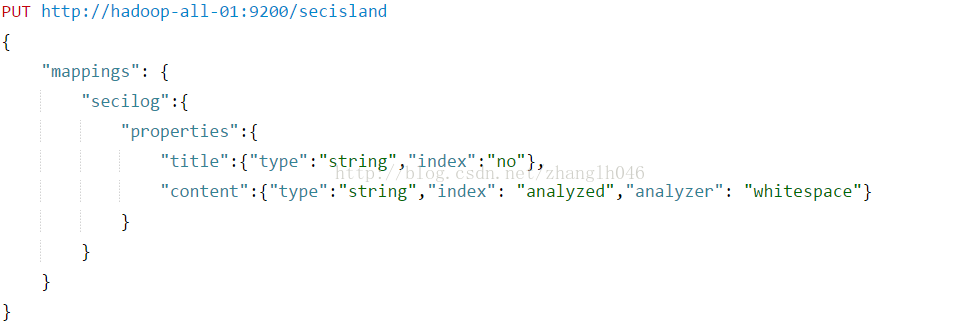


4.15index_options
index_options控制索引时存储哪些信息到倒排索引中,接受以下配置:


4.16fields
多字段的目的是基于不同目的用不同方法索引相同的字段,比如一个字符串字段可以作为分词字段被索引用于全文搜索,也可以作为不可分词字段用于排序或者聚合
而且还可以视同fields,作为多重分词器


4.17norms
norms参数用于标准化文档,以便查询时计算文档的相关性。norms虽然对评分有用,但是会消耗较多的磁盘空间,如果不需要对某个字段进行评分,最好不要开启norms。
4.18 null_value
我们知道,如果一个字段为空值,是不会被索引的,null_value可以指定将某些字符串吗,数字,日志挥着布尔值替换掉null值,以便可以被索引和搜索

4.19 position_increment_gap
为了支持近似或者短语查询,可分词字符串字段被解析的时候会考虑该分词的位置信息。一个虚拟间隙值会被加到各个值之间防止短语查询跨值匹配,间隙大小可以有position_increment_gap参数配置,默认100
# 指定position_increment_gap=10


# 默认短语查询是匹配不到bule glasess

# 但是只要间隙大于position_increment_gap指定的值,就可以查询到

4.20 search_analyzer
一般情况下,索引的时候和搜索的时候应该使用一样的分词,确保查询的索引词和反向索引词有相同格式;但有些时候在搜索时使用不同的分词器是有意义的。
默认情况下,查询会使用映射字段中定义的分词器,但是可以利用
search_analyzer设置来重写配置

4.21 similarity
ES允许对每一个字段配置得分算法或者相似算法,similarity就可以让我们选择不同于TF/IDF的相似算法.BM25
BM25 :ES和Lucene默认的评分模型
classic :TF/IDF评分
boolean:布尔模型评分

4.22store
首先我们需要了解一下_source字段:保留的是源数据,当你索引文档的时候ES会保存一份源文档到 _source中,如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储。
什么意思呢?
也就说_source和store都是可以存储源数据的,区别在于默认_source是存储所有字段,那么取得时候也就1次I/O;store只是应用于单个字段,如果一个doc有N个字段,设置了store=yes,那么就会发生N次I/O.单从目前为止,我们可以知道_source效率更高
但是为什么需要store呢?
# 如果禁用了_source,那么我们又想获取原始数据,那么可以使用store
# 如果只是想获取源文档部分字段,而不是所有字段
方案一:_source中过滤掉不需要的字段
方案二:需要返回的字段设置store=yes



4.23 term_vector
索引词向量包含分析过程中产生的索引词信息,主要是:
# 索引词列表
# 每一个索引词的位置
# 映射索引词原始字符串的原始位置中开始位置和结束位置等


4.24 precision_step
大多数的数字型数据类型,可能会索引额外的索引词,表示数字的范围,使得范围查询更加便捷

五 动态映射
ES可以事先不定义好索引结构,在使用的时候直接插入文档到索引中,系统会根据文档的内容自动进行索引结构的动态映射,即自动检测新添加字段和类型
我们还可以禁用动态类型:
index.mapper.dynamic: false
我们可以自己定义动态映射规则:
5.1 _default_映射
用于创建新映射的类型的基础映射

user继承了_default字段的配置,而secilog却重写了默认配置
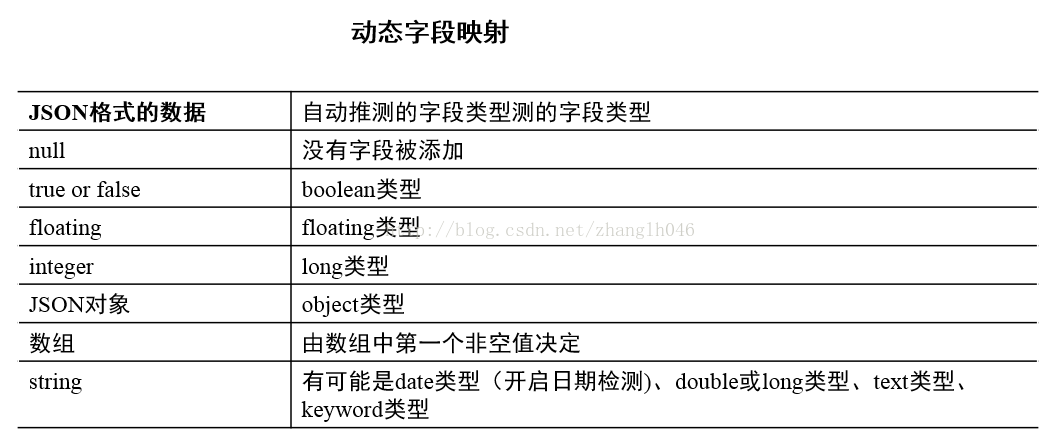
5.2 动态字段映射
5.3 动态模板
动态模板可以自定义映射用来添加字段,基于以下参数:
# 利用match_mapping_type进行数据类型检查
# 字段名,利用match and unmatch或者match_pattern
5.3.1 match_mapping_type

5.3.2 match和 unmatch
match:匹配某个字段
unmatch: 排除match匹配的字段
举个例子,比如所有字符串类型字段以long_开始的并排除以_text结尾的字段,索引这些字段为长整形字段:

5.3.3 match_pattern 正则表达式匹配(略)
5.4 重写默认模板
可以重写所有索引的默认模板,也可以通过在索引模板中指定_default_类型参数重写映射类型:


