
- 1ARM架构安全特性之隔离技术
- 2SAP面试全过程(已拿offer)_sap顾问群面是英文还是中文
- 3【SpringCloud】这一次终于使用MQ解决了Eureka服务下线延迟感知问题_用eureka还需要mq吗
- 4树莓派装系统以及Windows远程连接_windows连接树莓派
- 5linux 配置ssh免密码登陆本机
- 6[数据集][目标检测]纸箱子检测数据集VOC+YOLO格式8375张1类别
- 7新版一键AI视频图片换脸神器来了!目前最强的AI视频换脸工具Swapface!_ai视频图片换脸大师
- 8Visual Paradigm 下载安装及使用
- 9HTTP协议安全性分析_http安全吗
- 10深度解析 Spring 源码:三级缓存机制探究_spring三级缓存源码解析
自然语言处理:Transformer与GPT_gpt和transformer的关系
赞
踩
Transformer和GPT(Generative Pre-trained Transformer)是深度学习和自然语言处理(NLP)领域的两个重要概念,它们之间存在密切的关系但也有明显的不同。
1 基本概念
1.1 Transformer基本概念
Transformer是一种深度学习架构,最初在2017年由Google的研究人员在论文《Attention is All You Need》中提出。它为处理序列数据(尤其是在自然语言处理领域)带来了革命性的变化。Transformer的核心特征是其对自注意力(Self-Attention)机制的使用,这使得模型能够有效地处理长距离依赖关系。它主要用于处理序列数据,如文本。
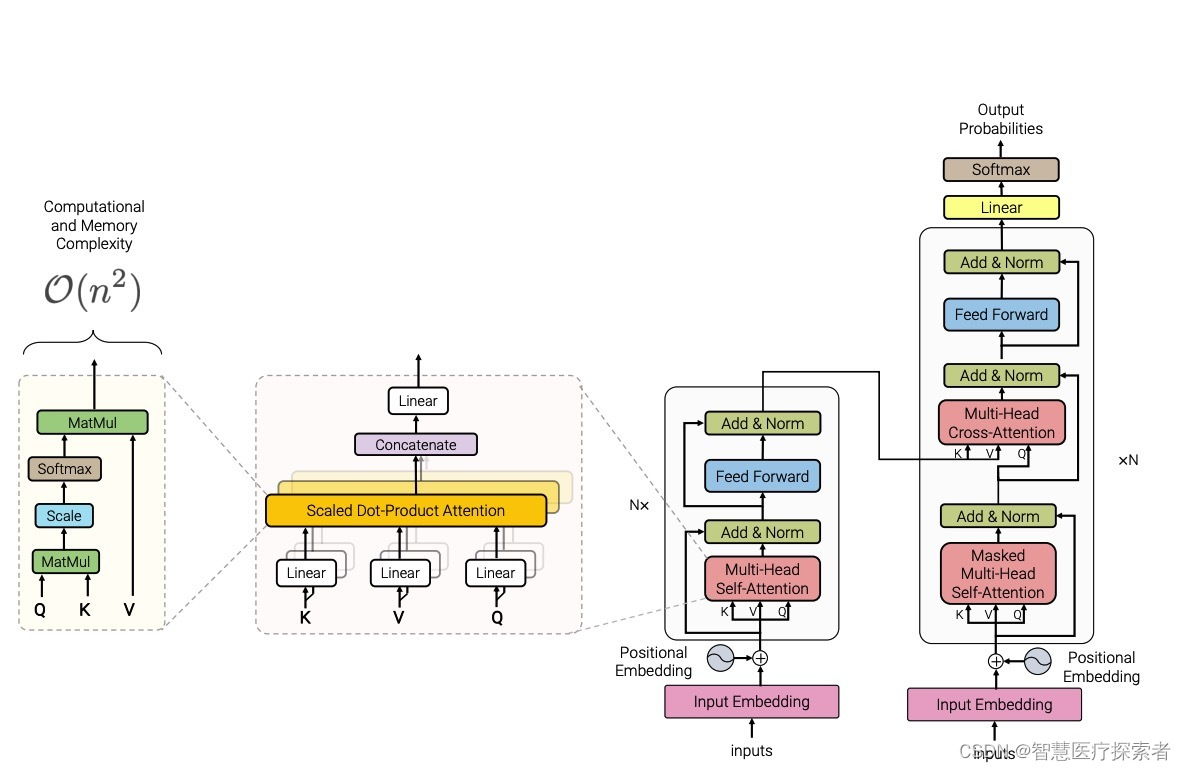
Transformer架构的提出是深度学习和自然语言处理领域的一个重大突破,它极大地推动了这些领域的发展。
1.2 GPT基本概念
GPT(Generative Pre-trained Transformer)是一个由OpenAI开发的,基于Transformer架构的,先进的自然语言处理模型系列。GPT模型通过在大量文本数据上进行预训练,学习到丰富的语言知识。GPT专注于生成任务和语言理解任务。

2 关键特征
2.1 Transformer关键特征
Transformer的核心是自注意力(Self-Attention)机制,它使得模型能够同时关注序列中的所有位置,从而有效地捕捉序列内的长距离依赖关系。
-
自注意力机制:自注意力允许模型在处理一个序列的每个元素时同时考虑序列中的所有其他元素。这种机制提供了一种捕捉序列内各位置之间复杂关系的方式。
-
多头注意力:Transformer采用多头注意力机制,即将注意力机制分割成多个头,每个头从不同的角度学习序列中的信息,提高了模型捕捉不同类型信息的能力。
-
位置编码:由于Transformer不使用循环网络结构,因此通过位置编码向模型输入位置信息,确保模型能够考虑到词语的顺序。
-
编码器和解码器的堆叠:标准的Transformer模型由编码器和解码器组成,每个部分都是由多层相同的层堆叠而成。编码器处理输入序列,解码器生成输出序列。
2.2 GPT关键特征
GPT模型采用了Transformer的自注意力机制,但特别专注于生成任务。主要特征如下:
-
自注意力机制:GPT利用了Transformer架构中的自注意力机制,允许模型在生成每个单词时考虑到整个文本序列。
-
大规模训练数据:GPT通过在大量文本数据上进行训练,学习到了丰富的语言知识和模式。
-
单向性:与一些其他基于Transformer的模型不同,GPT的结构是单向的,意味着在生成文本时,只考虑之前的上下文,而不是整个序列。
3 应用范围
3.1 Transformer应用范围
Transformer架构被广泛用于各种NLP任务,也被用于非NLP任务,比如计算机视觉,典型的应用如下:
- 机器翻译:Transformer最初是为机器翻译而设计的,但它迅速被应用到其他多种自然语言处理任务中。
- 文本生成:在文本生成领域,如语言模型预训练(例如GPT系列)和文本摘要等任务中,Transformer表现出色。
- 语言理解:Transformer也被用于语言理解任务,如情感分析、问答系统和命名实体识别等。
3.2 GPT应用范围
GPT主要用于文本生成任务,也在一些NLP下游任务中展现出了出色的性能,主要的应用如下:
-
文本生成:包括文章写作、故事生成、自动编写代码等。
-
语言理解:尽管以生成任务闻名,GPT模型也在诸如文本分类、情感分析等语言理解任务中表现出色。
-
问答系统:能够在问答任务中生成准确的回答。
-
机器翻译:尽管不是专为翻译设计,但GPT也可以应用于语言翻译任务。
4 Transformer与GPT的关系
-
架构关系:GPT是基于Transformer架构的。它实质上是Transformer的一个特定实例,专门用于语言模型预训练和生成任务。
-
应用差异:虽然两者都广泛用于NLP领域,但Transformer更像是一个通用架构,适用于多种任务,而GPT更专注于文本生成和某些类型的语言理解任务。
5 总结
Transformer提供了一种强大的架构,而GPT则是这种架构在特定领域(如文本生成)的一个成功应用。随着深度学习和NLP技术的发展,Transformer架构和基于它的各种模型(如GPT)将继续在多个领域发挥重要作用。

