- 1git常用回滚命令_git rollback命令
- 2工作记录------PostMan自测文件导入、导出功能_postman 导出pdf
- 3Linux 环境配置 VScode copilot_linux copilot
- 4FPGA-图像处理-仿真_vivado图像处理仿真
- 5Windows下常用的DOS命令_windows dos命令
- 6【主色提取】模糊C均值(FCM )聚类算法和彩色图像快速模糊C均值( CIQFCM )聚类算法_什么是fcm聚类
- 7WebUI自动化学习(Selenium+Python+Pytest框架)002_pyhton使用pytest框架写webui自动化
- 8Golang中的字符串迭代与索引_go 字符索引
- 9未来10年云计算发展前景如何?云计算的优势在哪里?_云计算在未来5-10年对商业和社会产生的影响和变化
- 109.4.k8s的控制器资源(job控制器,cronjob控制器)
Pytest+Request+Allure+Jenkins实现接口自动化_jenkins+pytest实现接口自动化
赞
踩
- 利用
Pytest+Request+Allure+Jenkins实现接口自动化; - 实现一套脚本多套环境执行;
- 利用参数化数据驱动模式,实现接口与测试数据分离
- 使用
logger定制实现自动化测试日志记录
实现步骤:
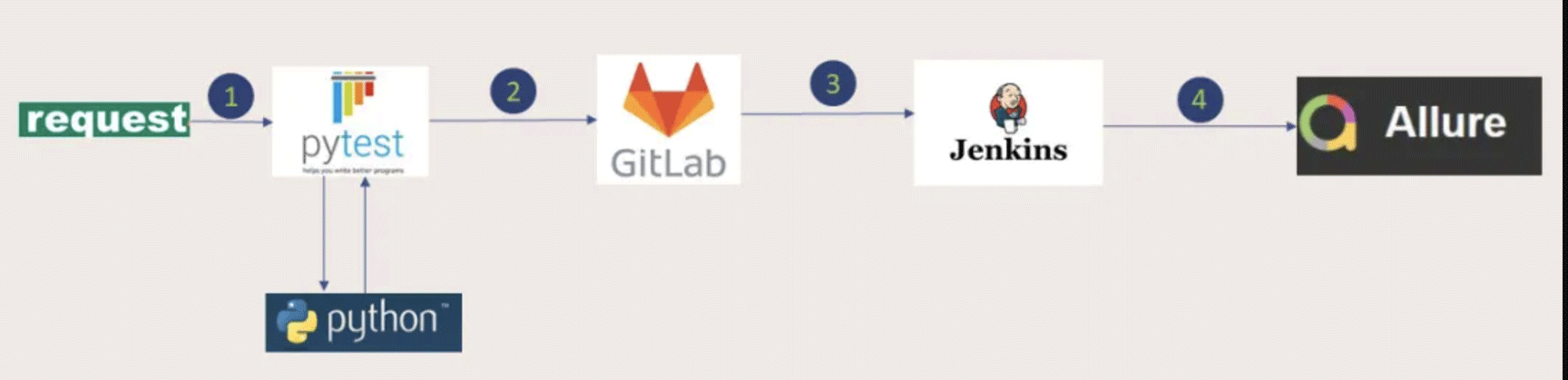
框架结构:
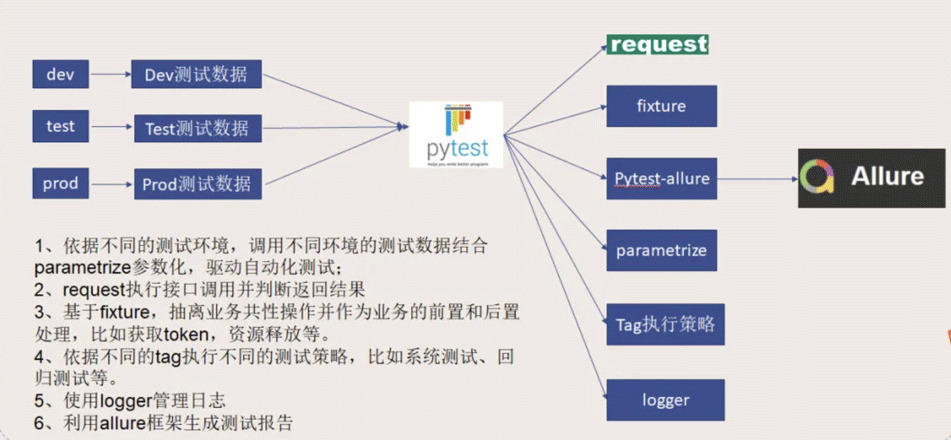
1、接口自动化项目代码编写(先在window实现)
1.1 项目准备
先在window安装响应的环境依赖
- 安装python3.7(要保证pip能用,一般安装python3.7会自动安装pip)
- 安装pytest框架---- pip install pytest
- 安装request库---- pip install request
- 安装openpyxl库(测试数据保存在excel中,需要依赖读取excel的库)---- pip install openpyxl
- 安装pycharm(编写python脚本工具)
注意:可能还需要一些依赖的东西,项目步骤里会依据需要进行安装
- 现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
- 如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
- 可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
- 分享他们的经验,还会分享很多直播讲座和技术沙龙
- 可以免费学习!划重点!开源的!!!
- qq群号:485187702【暗号:csdn11】

1.2 设计基于pytest的测试框架结构
在pycharm中开发构建项目结构

common:存放公共方法
config:存放环境配置信息
lib:存放第三方库
main:框架主入口
report:存放allure测试报告
test_case:存放测试用例
test_data:存放测试数据
1.3 实现接口公共请求发送能力
从这一步开始正式编写代码
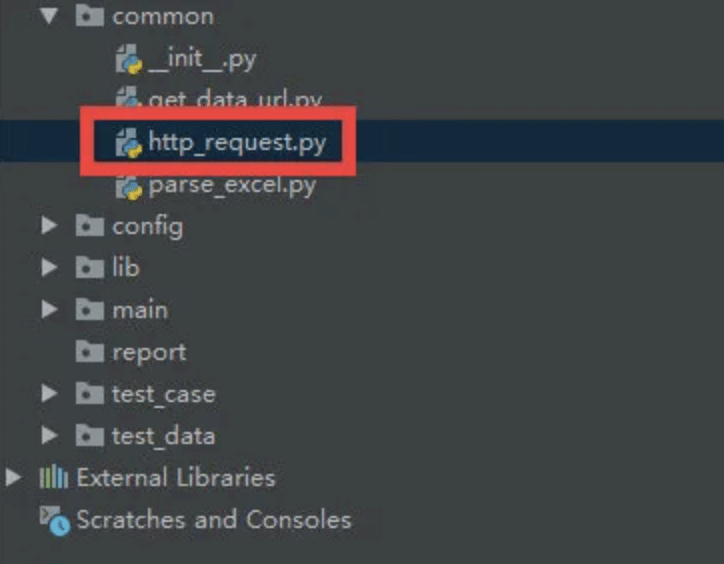
封装http请求的公共能力(封装request库,变成自己的公共处理能力),放到common目录下。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
1.4 抽离测试环境配置信息
这个步骤的目的有三个
- 为了配置三个不同环境(测试、开发、生产)的URL,每个环境接口测试的URL是不一样的,设置这样一个枚举类,方便后面的程序根据不同的环境,获取不同环境的URL,里面的URL依据自己公司的地址修改,放到config目录
- 获取token需要登录,这里可以设置一个全局的账号密码,这个账号密码获取的token可以给整个接口自动化使用
- 配置获取token的uri,这个uri三个环境的是一致的,登录的接口依据环境只是URL不同,URI还是一致的。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
1.5 创建conftest.py放置一些公共的fixture
1、pytest_addoption,设置了只允许输入dev/test/prod三个参数,以区分测试、开发、生产三个环境
2、get_env的fixture,它的作用是你在命令行执行接口自动化时,可以输入--env test将对应的环境信息传入进去
3、http的fixture,这里依据--env test传入的环境信息,去枚举类里获取对应环境的URL,然后返回一个http的session,供测试案例使用
4、get_token_head,依据--env test传入的环境信息,调用获取token方法,并将token放置到请求头head里返回(token一般放在请求头里,这里依据自己公司的请求,返回对应的token信息就可以了)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
|
1.6 将测试数据放到excel中
我们的测试数据是放在excel中,注意,这里有prod\test\dev三个目录,对应三个环境的测试数据,我这里只创建了test测试环境的测试数据。这里的测试数据需要包含两部分:
- 你调用接口传入的所有参数;
- 你要断言的所有信息,因为你传的参数不同,返回的内容就不同,你断言的内容也就不相同了。

那么这时候,就需要一个读取excel的公共方法了,放到common里
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
这里,还需要再test_data中,创建一个文件,为了获取前面test_data依据环境创建的dev/test或prod文件目录
1.7 开始编写自动化测试案例了
测试案例中有几个点,需要解释一下:
1、authBaseDir,这个就是根据test_data/test拼接出来的获取测试数据的目录
2、allure.feature,在测试报告中,会展现这个接口名称,这个名称最好与你公司的开发写的接口模块保持一致,方便后续查找问题
3、allure.story 这里也要与开发写的具体某个接口的名称保持一致。
4、pytest.mark.parametrize,这里就是运用的DDT数据驱动的模式,从excel中一条一条的获取数据,然后执行同一条接口测试用例,excel中比如有3条数据,那么就表示这个案例依据每一条数据的参数,总共执行了三次
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
1.8 集成allure
写到这里,是不是发现前面的allure.feature是不是用不了呢?这是因为我们还没有集成allure进去。
1、下载allure,放到lib目录下,使你的工程具备allure的能力。
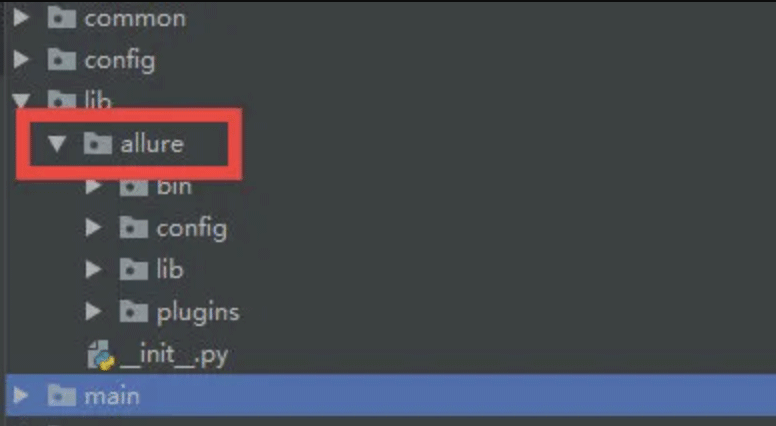
2、pip install allure-pytest安装pytest对应的allure包
1.9 这时候就可以创建一些执行策略了
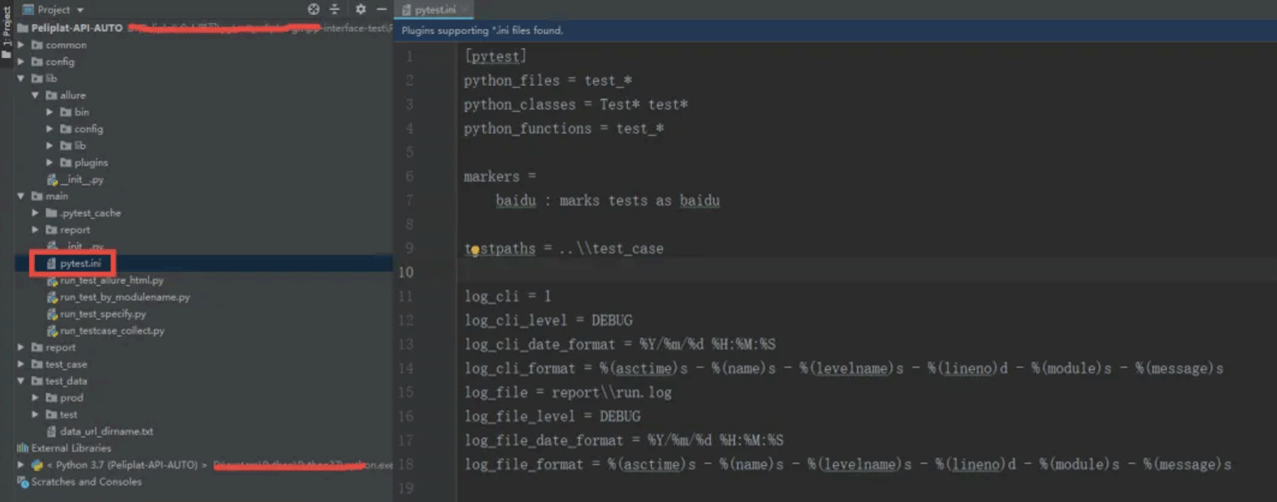
1、先在main中创建一个pytest.ini文件,设置一些执行参数
2、在main中创建执行策略
- 先在run_pytest方法中,执行案例并生成allure的json格式的报告文件,这里可以带--env prod将对应环境信息传入,这里没有传是因为默认是test环境,不传入的话就是执行的test环境测试数据
- general_report方法时将生成的json格式的报告,最终生成html文件放置到report下面的目录中
- 创建一个线程,先执行run_pytest,再执行general_report,避免json文件没有生成,这样生成html文件的报告数据可能不全,甚至没有。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
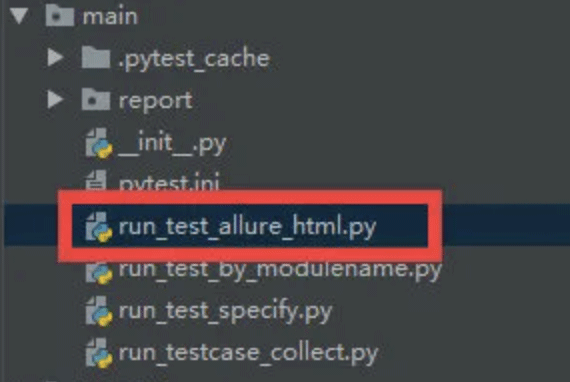
1.10 自动化执行生成结果
在windows下,右键执行main下面的run_test_allure_html.py(就是上一个步骤的python文件),然后打开report/allure_report/index.html看看报告是否生成成功

2. jenkins环境搭建(linux环境)
好了,到这一步,在windows下我们已经执行成功,现在我们要集成到jenkins环境去,并搭建在linux环境下。
1、将代码上传到公司的git(没有git的自己搭建一套吧)
2、找一台linux机器(自己去自己公司找资源)
3、在linux下安装jenkins(我是放到tomcat中)、python3、pytest、allure、openpyxl(这些步骤在网上可以搜索到,这里不赘述了)
4、启动linux下的tomcat,然后在window下打开jenkins的服务地址
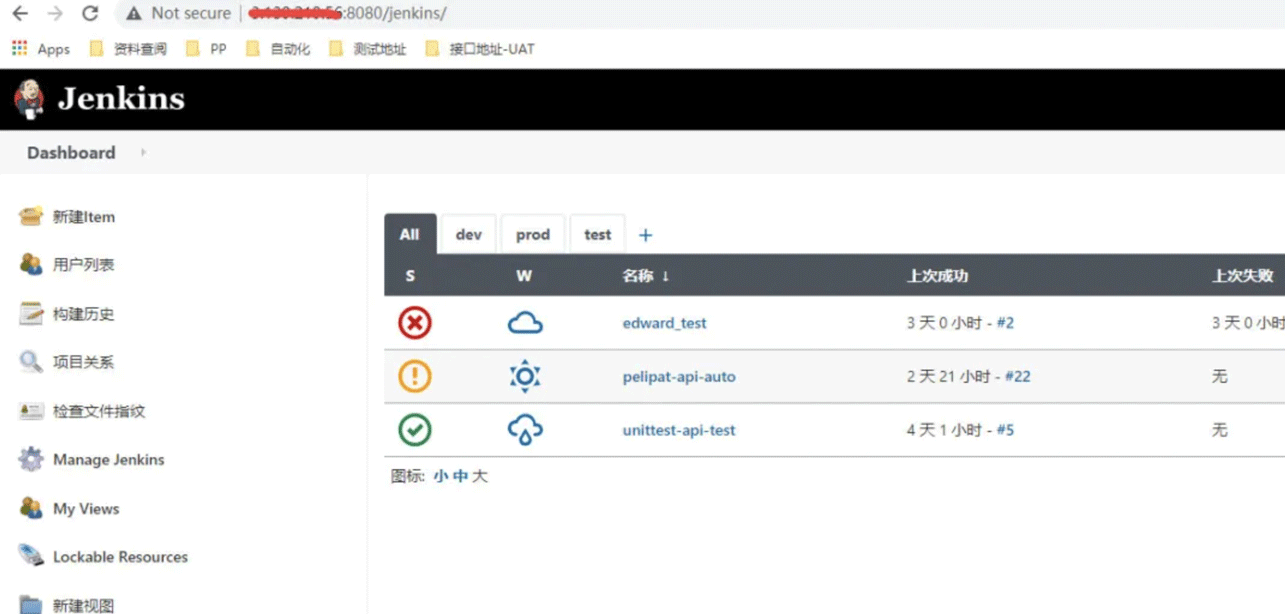
5、创建一个自由风格的job
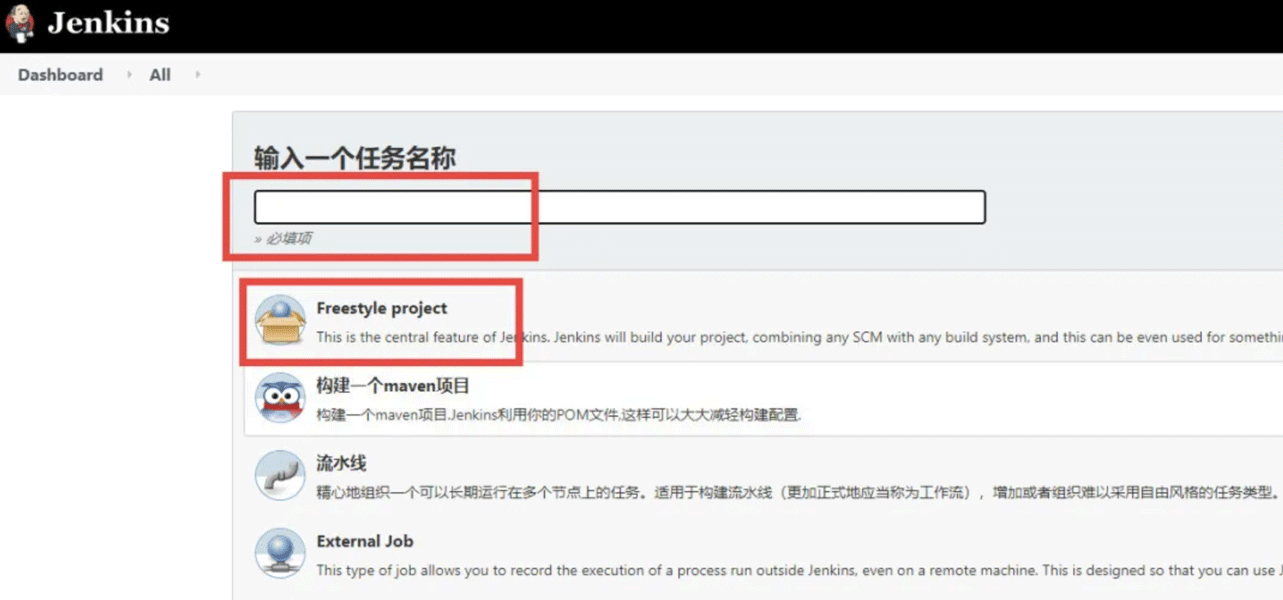
6、Job需要填写的具体内容有:
A、选择丢弃旧的构建(保留的构建天数依据自己的情况选择)

B、“限制项目的运行节点”依据自己的情况选择(我这里给我的jenkins主服务器取了一个叫linux的标签,我的机器也是linux机器)

C、git--将git上的代码拉下来

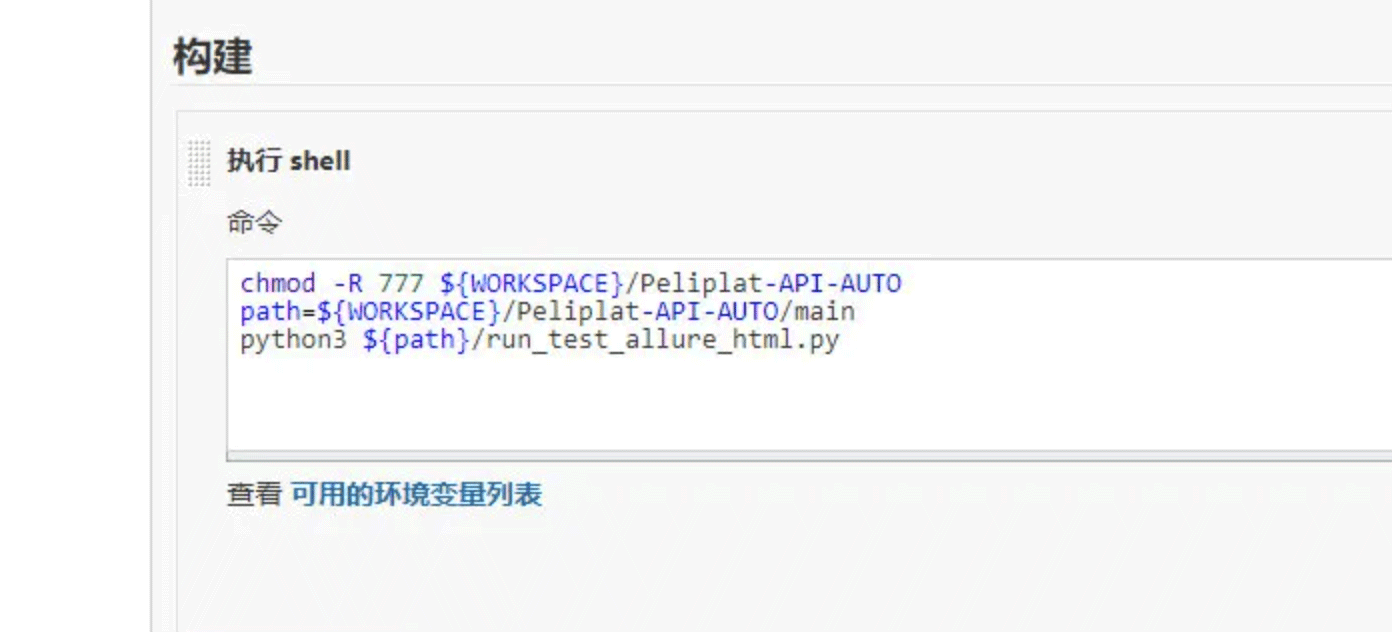
D、“执行shell”,这里把代码从git拉到了jenkins的执行目录里,一般在linux下的root/.jenkins里,在执行shell时,最好chmod修改下整个工程的目录权限,因为有可能因权限问题执行不了
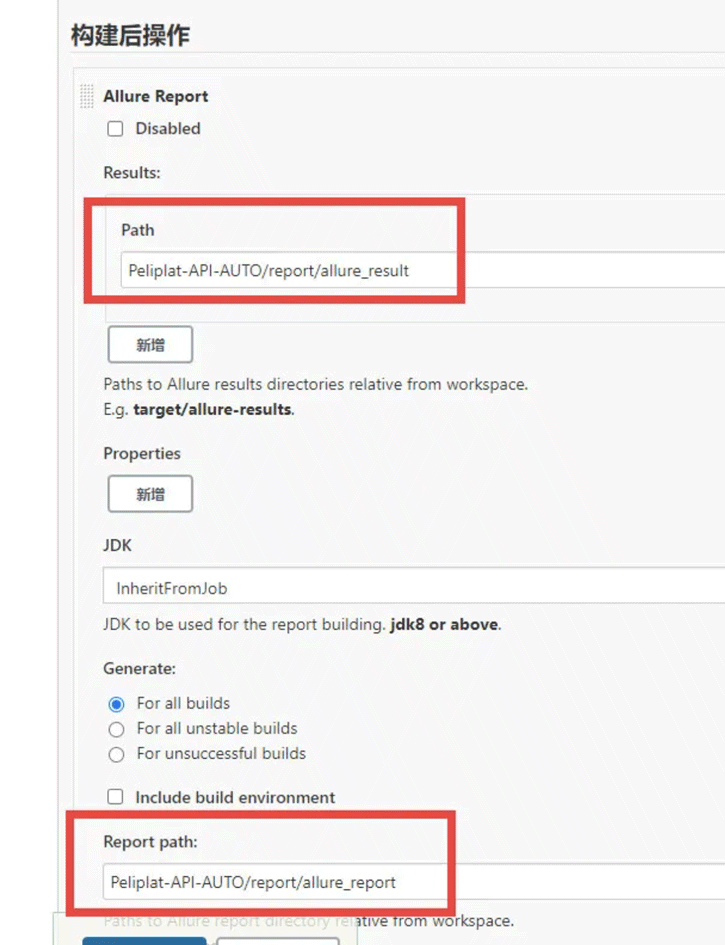
E、构建后的操作:这里需要再jenkins里安装allure插件才能看到allure Report,第一个Path,这里写的是allure生成的json文件的目录,所以是report/allure_result,第二个Report path指的是生成的index.html文件的目录,所以是report/allure_report
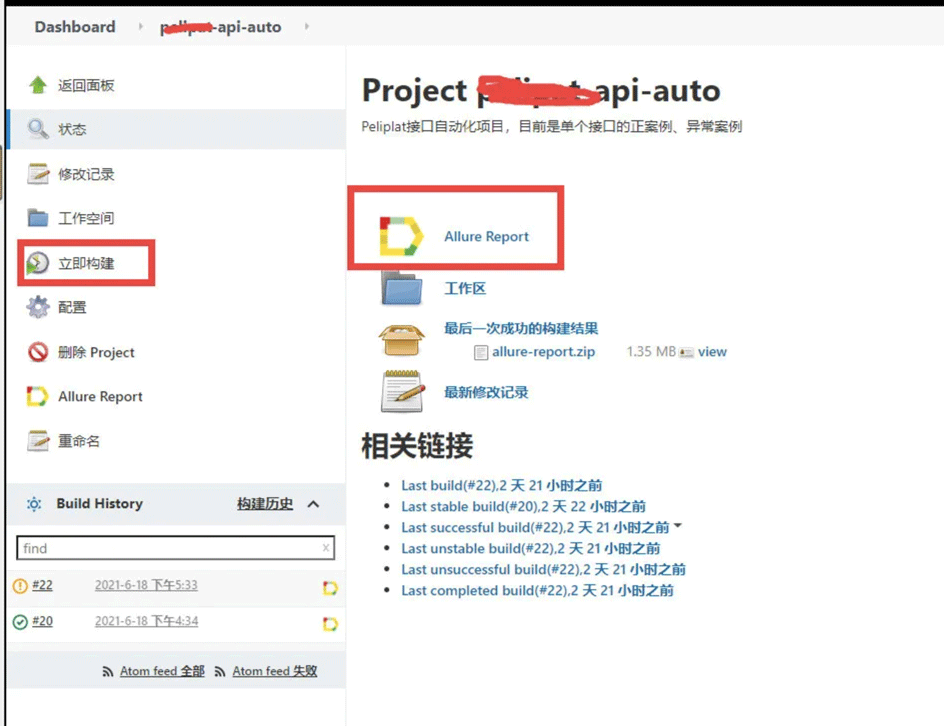
立即构建并查看报告
上面的job建成后,就可以点击立即构建,执行了。执行完后,点击allure Report查看最终的报告。

最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】