
- 1iptables高性能前端优化-无压力配置1w+条规则_iptables 内核参数调优
- 2超参数权值初始化问题_训练初始化超参数
- 3甲基化芯片Beta值意义详解,以及minfi包使用_minfi β值
- 4Navicat for mysql破解
- 52022年度总结|我的CSDN成长历程_2022年终总结 csdn
- 6大数据---29. hive的常用函数(一(最全的函数操作))_hive 方差函数
- 7基于SpringBoot的旅游管理系统设计与实现_基于springboot旅游管理系统设计与实现
- 8VSCode远程连接Gitee_vscode gitee
- 9bash逻辑取反技巧(bool_not函数)
- 10Unity 工具“常用插件九大分类汇总”(UI/VR/AR/建模/Shader/动画/网络/AI/资源/数据/区块链等)_volumetric fog & mist 2
ES数据存储与查询基本原理
赞
踩
Elasticsearch(ES)简介
Elasticsearch(ES)是一个分布式、可扩展、近实时的搜索和分析引擎,它基于Lucene,设计用于云计算中,处理大规模文档检索和数据分析任务,常用于实现内部搜索引擎和推荐算法的粗排流程。
ES基于Lucene,基于Lucene做索引和搜素,隐藏了Lucene本身的的复杂性,提供了简单易用的RESTful api。
ES具有如下特点:
- 开箱即用:提供简单易用的API,,服务的搭建、部署和使用都很容易操作
- 分布式:分片机制下同一个索引被分为多个分片(Shard),利用分而治之的思想提升处理效率
- 横向可扩展:作为大型分布式搜索引擎, 很容易就能扩展新的服务器到ES集群中;也可运行在单机上作为轻量级搜索引擎使用
- 高可用:提供副本(Replica)机制,一个分片可以设置多个副本,即使在某些服务器宕机后,集群仍能正常工作
- 更丰富的功能:与传统关系型数据库相比, ES提供了全文检索、同义词处理、相关度排名、复杂数据分析、海量数据的近实时处理等功能
总而言之,ES是:
- 一个分布式的实时文档存储引擎,每个字段都可以被索引与搜索
- 一个分布式实时分析搜索引擎,支持各种查询和聚合操作
- 一个大型分布是引擎,能胜任上百个服务节点的扩展,并可以支持PB级别的结构化或者非结构化数据
ES在很多场景发挥关键作用,这里列举了一些常见的用例:
- 应用程序搜索
- 搜索引擎
- 企业内部搜索
- 日志分析和处理
- 基础设计指标和容器监测
- 应用程序性能监测
- 业务分析
此外,在海量文本内容的推荐场景下,可以使用ES来实现粗排流程,提升召回效果和性能。
ES核心概念
近实时(Near Realtime)
ES的近实时,表现在2个方面:
- 从数据写入到可被检索延迟大概在1s(实现原理决定,下文有进一步说明)
- 基于ES执行搜索和分析可以再秒级完成
集群(Cluster)
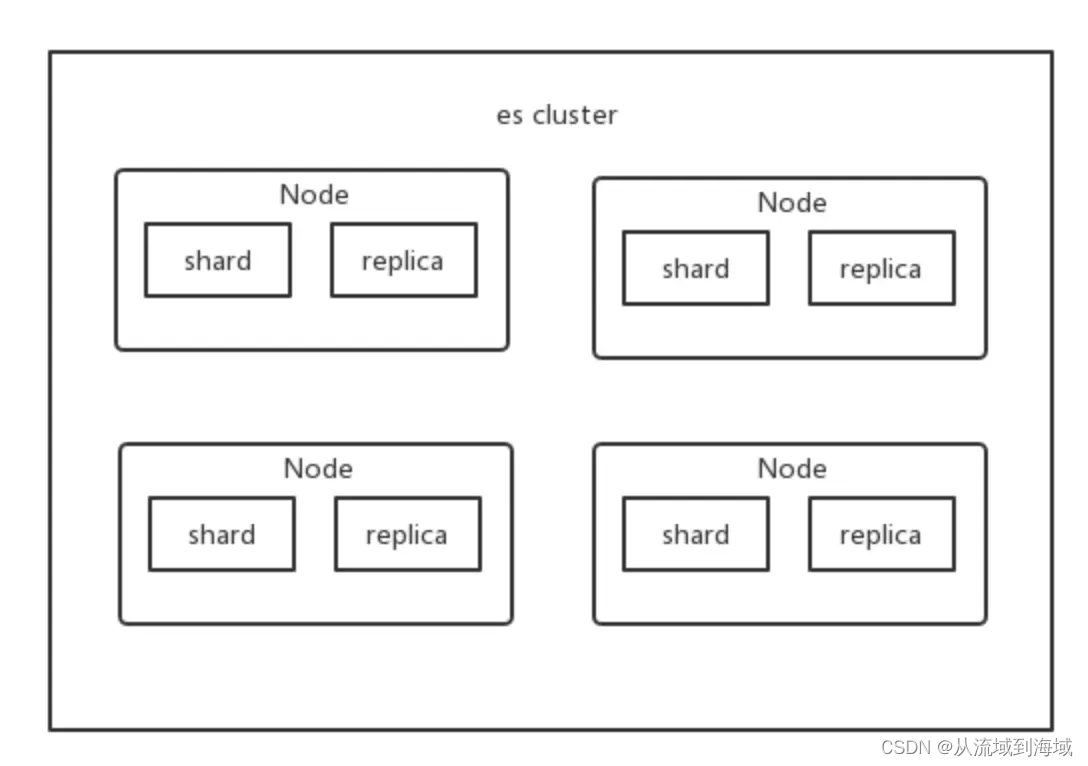
一个集群由多个节点组成,通过所有节点实现全部数据的存储、索引和搜索功能。每个集群有唯一的名称标识,默认是“elasticsearch”。默认集群非常重要,一个节点只有设置了这个名称才能加入这个集群,成为该集群的一部分。
每个节点属于哪个集群通过配置的集群名称来决定,初始条件下一个集群也可能仅有一个节点,随集群扩展不断加入新的节点。
节点(Node)
节点(Node)指的是运行单个实例的服务器,它是集群的一个成员,可以存储数据,参与集群的索引和搜索过程,节点也是用名称进行标识,默认为启动时自动生成的随机Marvel字符名称,也可以自定义名称。节点通过配置的集群名称确定要加入的集群,默认节点会加入到默认的elasticsearch的集群。
节点可以分为以下类型:
- master节点
负责集群层面的操作,如创建或者删除索引,跟踪哪些节点是集群的一部分,决定哪些分片分配给哪些几点,保存和更新集群的元数据信息,之后同步到所有节点,因此每个节点都会保存全量的元数据信息。当master节点挂掉时,会从可用的节点中选举出新的master节点。 - dataNode节点
负责数据存储、索引、查询。 - client节点
协调节点,负责查询的聚合/查询的请求解析和最终阶段的工作,协调节点的存在可以减轻dataNode压力,让其专注于数据的写入及查询。
分片(Shard)
单个节点无法存储大量数据,ES将一个索引中的数据切分为多个分片(Shard),分布式地存储在多个节点上。因此,ES基于shard的概念来横向扩展,以存储更多的数据,并且让存储、索引和分析等操作分布到多个节点上执行,分而治之,进而提升吞吐量和性能。
是线上,每一个分片都是一个lucene的index。
副本(replica)
任何一个节点都有可能故障或者宕机,此时该节点的shard无法存储或查询,为保证高可用,ES为每个shard创建多个replica副本,分布在不同节点上。replica可被看做是一种灾备机制,在shard故障时提供备用服务,保证数据不丢失,多个replica分布式可以提升搜索操作的吞吐量和性能。
shard分为两种,primary shard和replica shard,primary shard一般简称为shard,replica shard一般简称replica。
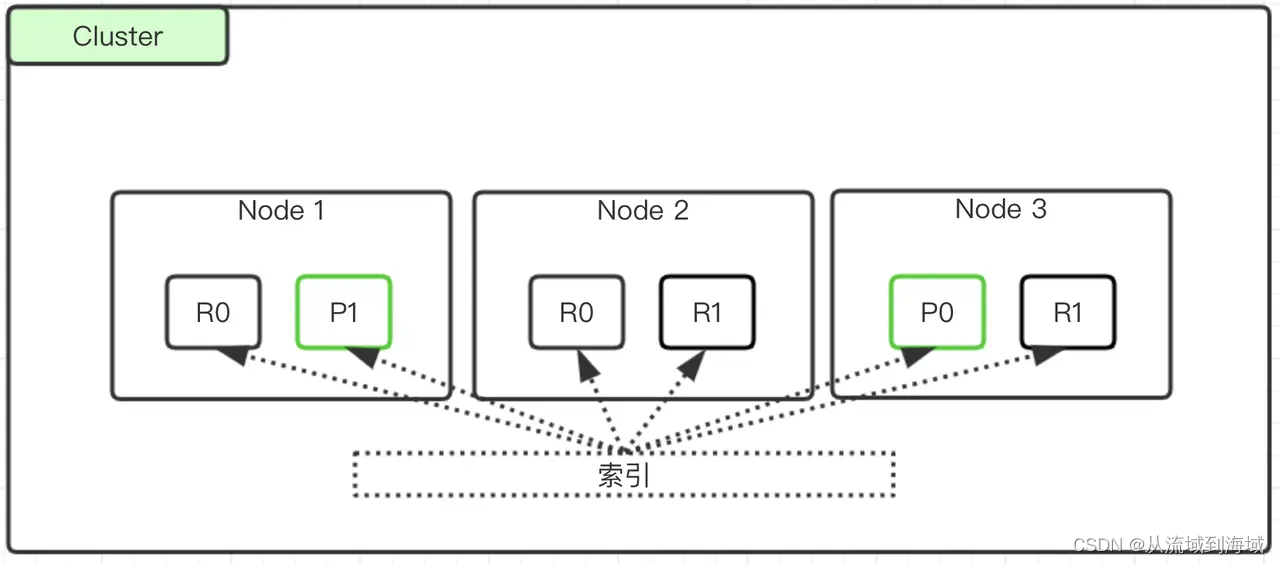
上图中R代表replica,P代表Primary。
段(Segment)
ES中每一个分片都是一个lucene引擎,那么每一个segment本质上就是分片中的一个倒排索引。
ES每秒会生成一个segment文件,当segment文件过多时会触发merge操作,将多个segment文件合并成同一个,同时将标记为删除的文档真正删除。
提交点(commit point)
每一个分片都有一个提交点文件,每隔30min或者segment达到512M后,会将os cache中的segment写入磁盘,这个过程称为flush,因为commit point保存了当前分片中已经成功落盘的全部segment。同时会维护一个.del文件,用来记录被删除的doc。
存储概念
类比MySQL仅仅用来帮助理解,是不同的概念,不能完全等价
| 名称 | 说明 | 类比MySQL |
|---|---|---|
| index(索引) | 一堆数据结构相似的docment组成的集合 | database 数据库 |
| type (类型) | 每个索引里可以有一个或者多个type,是index的逻辑分类,每个type下的document的field可能不完全相同 | table 数据表 |
| document (文档) | 文档是es中的最小数据单元 | record 一行数据 |
| field(字段) | document的一个字段 | record的field(列) |
注: mapping types 这个概念在 ElasticSearch 7. X 已被完全移除,详细说明可以参考官方文档
ES分布式架构原理
ES作为分布式搜索引擎,底层基于lucene,它的核心思想是在多台机器上启动多个ES进程实例,组成一个ES分布式集群。
ES存储数据的基本单位是索引,回想第一节简介里的介绍,索引的结构大致如下:
index -> type -> mapping -> document -> field
- 1
一个索引可以拆分为多个shard,每个shard存储部分数据,分布在不同的节点上。shard的拆分有2个好处:
- 支持横向扩展
- 并行分布式执行提高吞吐量和性能
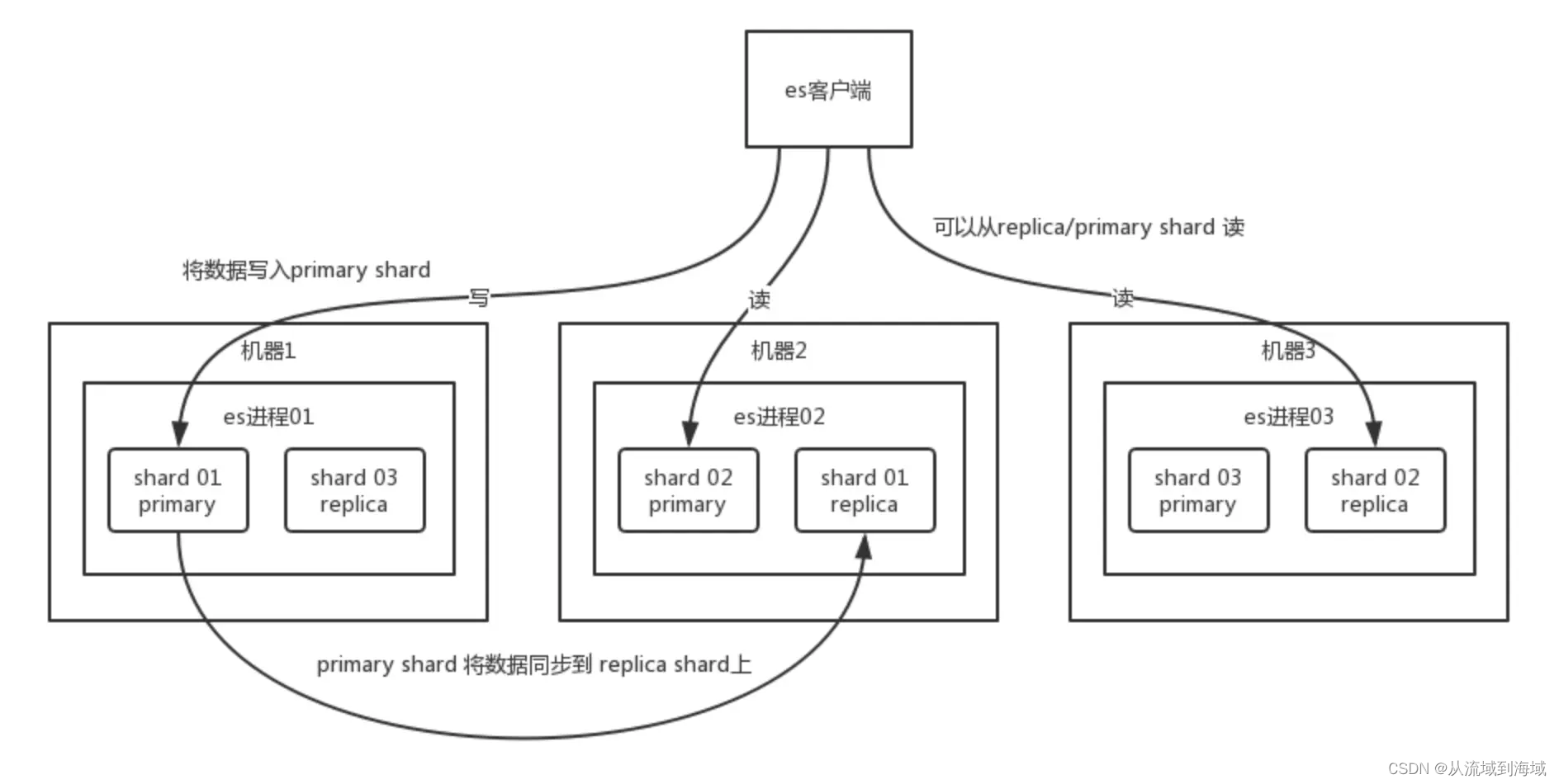
每个shard都有一个primary shard,负责写入数据和同步,同时有多个replica shard作为数据备份。primary shard写入数据后,会将数据同步给所有的replica shard,大致过程如下图:
ES查询过程
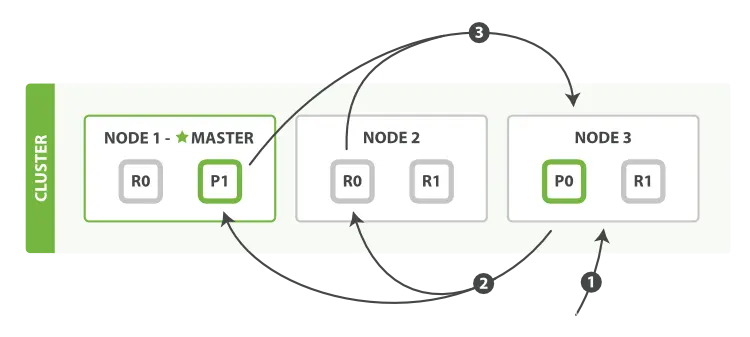
已上图为例,ES查询阶段大致包含以下三个步骤:
- 客户端发送一个
search请求到Node 3,Node 3创建一个大小为from+size(查询时指定,有默认值)的空优先队列 Node 3将查询请求转发到索引的每个主分片或副本分片中(如图Node 1的P1和Node 2的R0)。每个分片在本地执行查询并添加结果到同样大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的ID个排序值给协调节点
Node 3,Node 3合并所有的值到自己的优先队列中产生一个全局排序的结果。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,随后将结果集合返回给客户端。
协调节点首先广播查询请求到索引中每一个节点的分片拷贝,随后该查询请求可以被某个主分片或某个副本分片处理, 因而更多的副本(更多的节点)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载(有一定的负载均衡机制)。
ES写数据过程

- 客户端选择一个node发送写数据请求过去,收到请求的node将作为
coordinating node(协调节点)执行后续步骤。 coordinating node对document进行路由,转发请求到对应的node(包含primary shard的那个node)- 收到请求后,node上的
primary shard处理该请求,写入数据,并将数据同步所有含有其对应replica shard的node coordinating node在primary shard和所有的replica shard都写入完毕后,返回结果给客户端
ES读数据过程
ES支持通过doc_id查询数据(写入时指定,未指定默认生成),大致过程如下:
- 客户端发送请求到任意一个 node,该node收到请求后成为
coordinate node coordinate node对doc id进行哈希路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica shard中随机选择一个,让读请求负载均衡- 实际接收到请求的
node返回找到的document给coordinate node coordinate node返回document给客户端
ES搜索过程
ES最强大的功能在全文检索,检索过程大致如下:
- 客户端发送search请求到任意一个节点,该节点随后成为一个
coordinate node coordinate node请求转发到所有的 shard 对应的primary shard或replica shard(任意一种均可)- query phase:每个
shard将自己的搜索结果(doc_id)返回给coordinate node,由coordinate node进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase:然后协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
写请求是写入primary shard,然后同步给所有的replica shard;读请求可以从primary shard或replica shard`任意一个中读取,采用的是随机轮询算法。
写数据底层原理
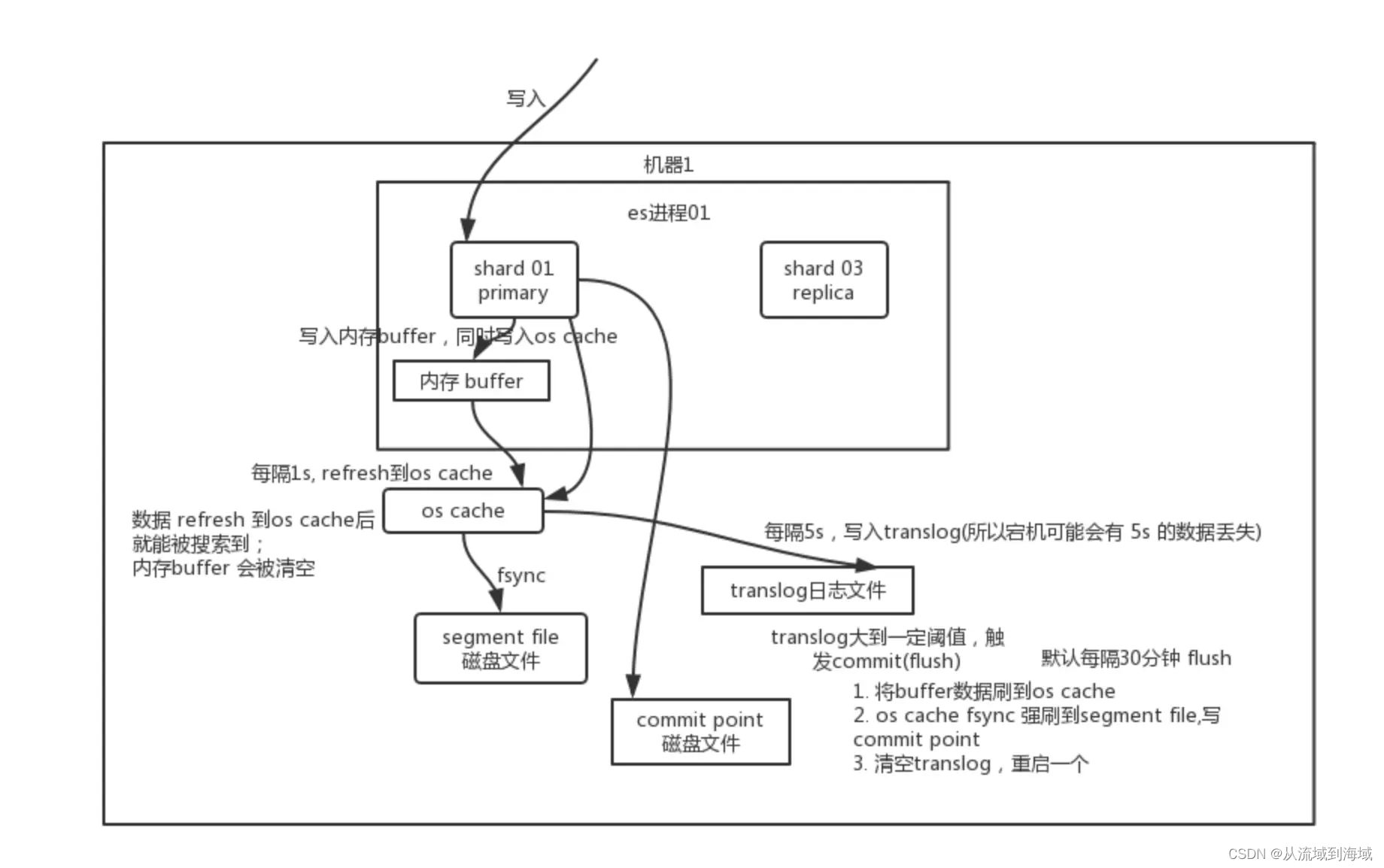
数据先写入内存buffer,然后每隔1s,将数据从buffer refresh到os cache,到了 os cache数据就能被搜索到(因而es从写入到能被搜索到中间有 1s 的延迟)。每隔5s,将数据写入translog文件(这样如果机器宕机,内存数据全没,最多也只会有5s的数据丢失),translog超过512M,或者默认每隔30min,会触发·commit·操作,将缓冲区的数据都flush到segment file磁盘文件中。数据写入segment file之后,同时就建立好了倒排索引。
删除和更新与上述操作类似,注意的是删除是在segment对应的.del文件中标记为已删除,真正删除发生在在segment file合并的时候。
ES近实时特性的原因
-
写请求将数据写入
buffer中,此时数据是不能被搜索到的,此时会同时将写操作记录在translog中,translog的落盘如果配置成同步,此时就会落盘,如果配置成异步,会在配置间隔时间进行落盘。 -
默认1s一次的refresh操作,es会将
buffer里的数据存入os cache中,并把buffer中的数据转化成segment,此时document便可以被搜索到了。每次refresh都会生成一个segment,es会定期进行segment合并。refresh数据到os cache后,buffer会被清空。 -
每隔30min或者segment达到512M 后,会把
os cache中的segment写入到磁盘中,这个过程叫做flush。此时会生成一个commit point文件,用来唯一标识该segment。执行flush操作时,会把buffer和os cache里的数据都清空,此时translog也会被落盘。原有的translog会被删除,会在内存中创建一个新的translog。
倒排索引
倒排索引(inverted index,又称反向索引),是正向索引的一个相对的概念。一般的索引比如MySQL的主键索引,是id到数据的映射,这是一种正向索引,而ES使用的Lucene倒排索引,是文档内容数据到文档id的映射,因而被称作反向索引或倒排索引。
Lucene倒排索引倒排索引维护了关键词到文档id的映射,即通过一个关键词,可以找到所有包含该关键词的文档id。
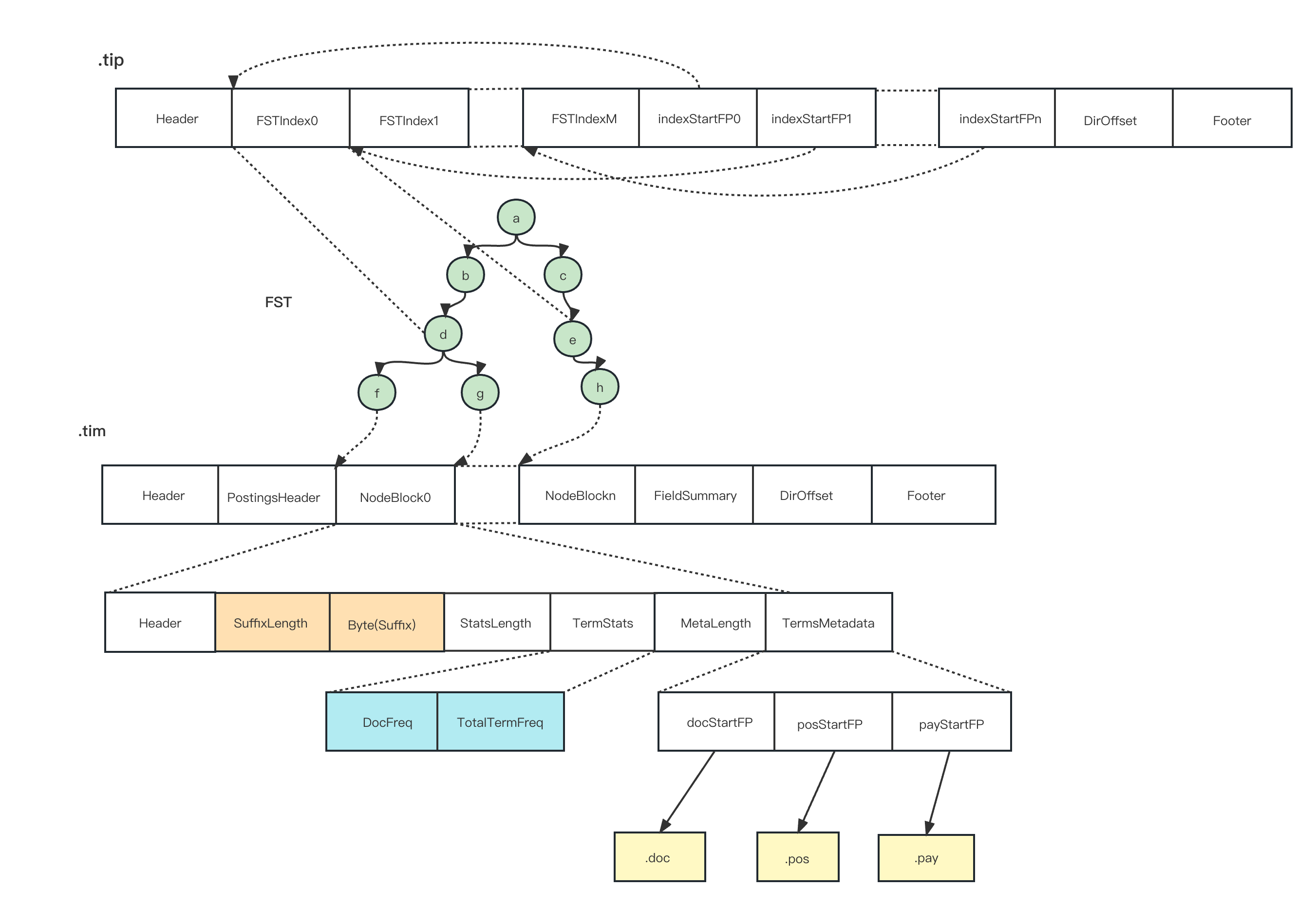
- 通过对查询语句的解析,得到需要查找的
term,找到该term对应的.tip文件和.tim文件。lucene会默认为每一个term都创建对应的索引 term index主要由FSTIndex和indexStartFP组成,FST(Finite State Transducer)有限状态转移机,可以理解为一个词语前缀索引。通过对前缀索引的搜索,就可以缩小搜索的范围,提高搜索的效率。
3.indexStartFPn里存的是FSTIndexn的地址, 为啥要存indexStartFPn,是因为每个FSTIndexn的大小不一样,为了节省存储空间,密集存储FSTIndexn,但是这样就没办法快速查找FSTIndexn。因此使用空间换时间,存下每个FSTIndexn的起始地址,而indexStartFP的大小都一样,这样就可以通过indexStartFPn进行二分查找了。- 通过
term的前缀匹配定位到该term可能存在的block,此时就需要到.tim文件里去查找。可以看到.tim文件我们比较关注的是三部分。一是suffix;二是TermStats;三是TermsMetaData。其中suffix里存放的就是该term的后缀长度和suffix的内容。TermStats里包含的是该Term在文档中的频率以及所有Term的频率,这部分是为了计算相关性(计算相关性的过程,将在下一篇博文中介绍)。 - 第三部分
TermsMetaData里存放的是该Term在.doc、.pos、.pay中的地址。.doc文件中存放的是docId信息,包括这个term所在的docId、频率等信息。.pos文件里包含该term在每个文档里的位置。通过.tim文件里存放的这些地址,就可以去对应的文件里得出该term所在的文档id、位置、频率这些重要的信息了。
lucene同样也有正向索引,通过倒排索引拿到的docId后,就需要通过正向索引使用docId找到文档:
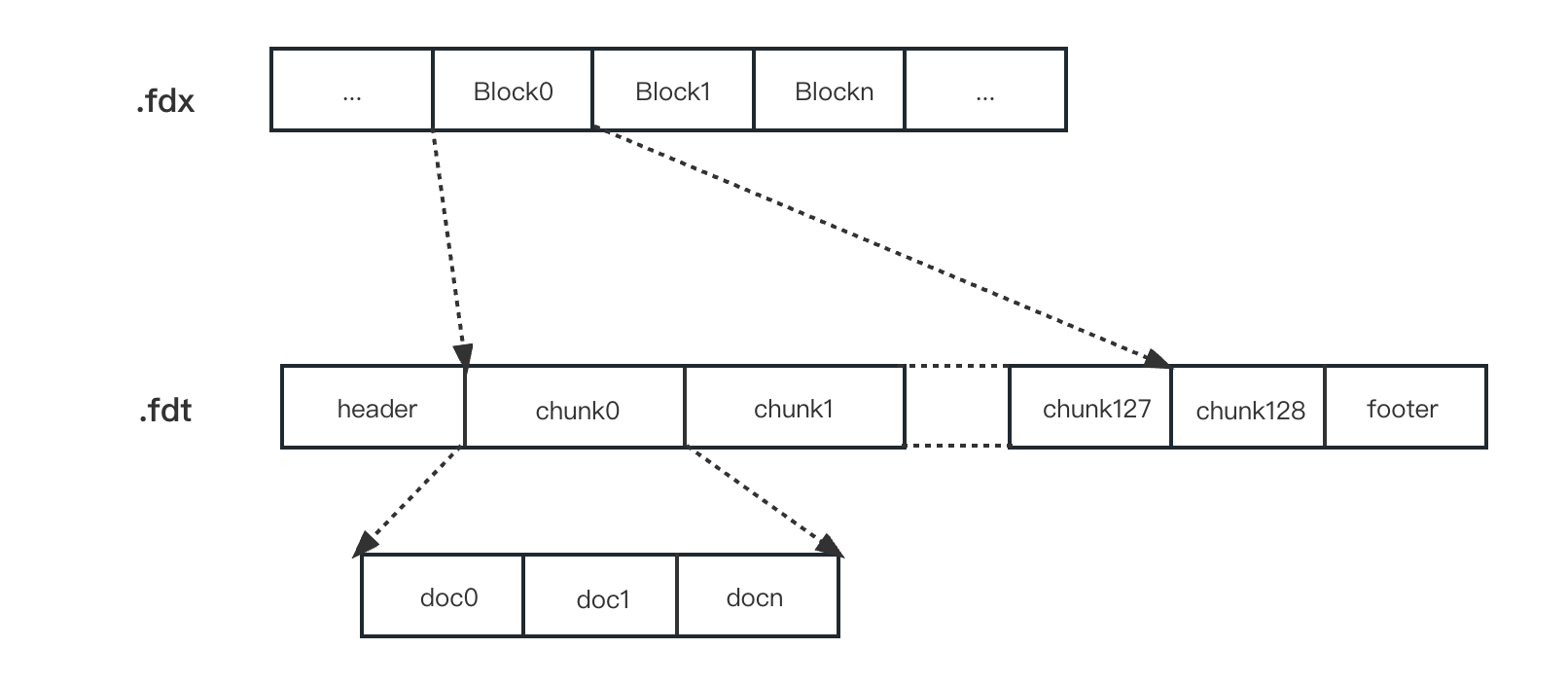
- fdx文件里存放的是每组chunk的起始地址
- fdt文件里每个chunk里包含压缩后的doc信息
- fdx文件较小,可以直接加载到内存
- 通过fdx文件拿到对应的docid所在chunk的地址,再通过chunk地址在fdt文件找到并加载doc的数据信息
通过正向索引拿到文档数据的过程,类似于MySQL的回表操作。
参考文献
参考了内网的几篇文章,图片来自这些文档,未列出

