
- 1BERT-BiLSTM-CRF命名实体识别应用
- 2jenkins 部署springboot 项目
- 3连接Azure Blob_azure blob的连接方式
- 4Hping3 拒绝服务攻击手册_ping of death攻击
- 5SpringCloudConfig使用ssh方式连接GitHub报错JSchException: Auth fail_ssh连接失败jschexception auth fail
- 6基于YOLOv5的头盔检测模型训练与系统开发(YOLOv5s训练模型文件,qt开发可视化界面,pyinstaller打包成桌面应用程序)_安全帽 yolov5 pt模型文件
- 73Dmax-Vray动画渲染参数预设_vray卡通 参数
- 8图解LeetCode——138. 复制带随机指针的链表_复制带有随机 random 的链表
- 9SpringBoot 源码解读与原理分析_springboot源码解读与原理分析 码农pdf
- 10自然语言处理基础详解入门_自然语言处理相关理论和知识
CVPR 2022 | 字节跳动论文精选丨附开源链接
赞
踩
本文来源 字节跳动技术范儿
计算机视觉领域的学术会议 CVPR 2022 已经公布了论文中选结果。
作为计算机视觉领域三大顶级学术会议之一,CVPR 每年都吸引了各大高校、科研机构与科技公司的论文投稿,许多当年十分重要且有巨大突破的计算机视觉技术工作都在 CVPR 上发布,供全球研究者阅读研习。
我们精选了 16 篇字节跳动技术团队发表在本届 CVPR 上的论文,分享其中的核心贡献与突破,学习计算机视觉领域的最前沿研究。
接下来,我们一起来读论文吧。

目标检测的重点与全局知识蒸馏
Focal and Global Knowledge Distillation for Detectors
这篇工作由字节跳动商业化技术团队与清华大学合作完成。
针对学生与教师注意力的差异,前景与背景的差异,我们提出了重点蒸馏 Focal Distillation:分离前背景,并利用教师的空间与通道注意力作为权重,指导学生进行知识蒸馏,计算重点蒸馏损失。Focal Distillation 将前景与背景分开进行蒸馏,割断了前背景的联系,缺乏了特征的全局信息的蒸馏。为此,我们提出了全局蒸馏 Global Distillation:利用 GcBlock 分别提取学生与教师的全局信息,并进行全局蒸馏损失的计算。
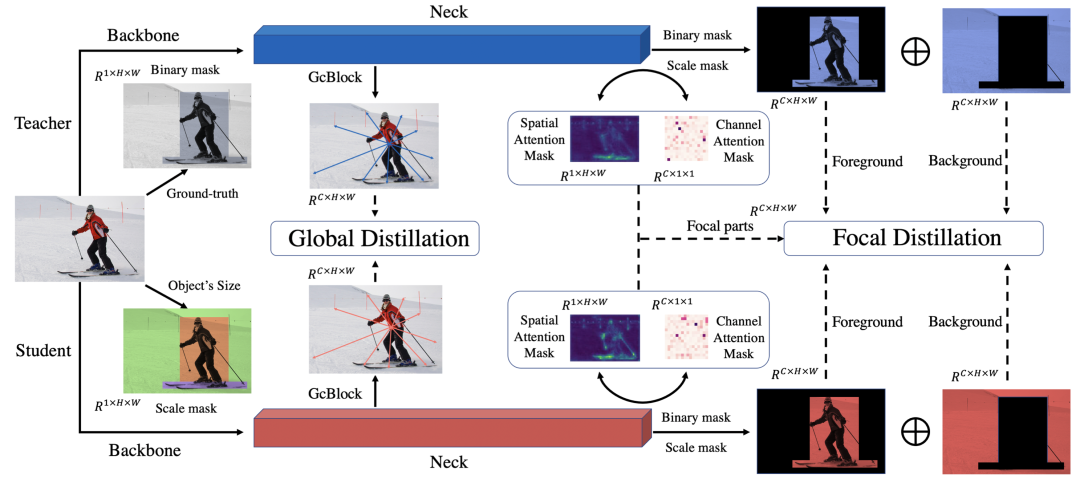
本文对 anchor-based 与 anchor-free 的单阶段与二阶段检测器进行了实验,在 COCO2017 上学生检测器均获得了大幅的 AP 和 AR 提升。例如对 FasterRCNN-R50 使用 FGD 蒸馏,mAP 由 38.4 提升到了 42.0,mAR 由 52.0 提升到了 55.4。
arXiv: https://arxiv.org/abs/2111.11837
github: https://github.com/yzd-v/FGD

基于跳舞视频的通用虚拟换装
Dressing in the Wild by Watching Dance Videos
这篇工作由字节跳动智能创作团队和中山大学共同完成,利用模型自动实现人物的全身&局部换装。
论文作者提出了 2D 3D 相结合的视频自监督训练模型 wFlow,在有挑战性的宽松服装与复杂姿态上有明显的效果提升。
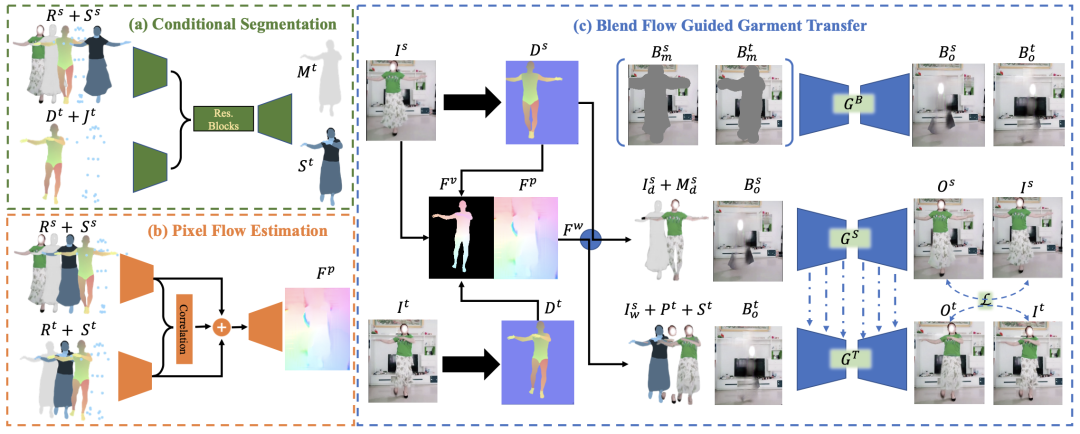
由于缺乏人体潜在的 3D 信息感知能力及相应的多样化姿态&衣服数据集,现有的虚拟换装工作仅仅能应用在贴身衣物或者人体姿态较为简单的情况下。
因此,本文作者提出了一个全新的真实世界视频数据集 Dance50k,并结合引入 2D 像素流与 3D 顶点流,形成更通用的外观流预测模块(即 wFlow),在解决宽松服装变形的同时,提升对复杂人体姿势的适应力。
通过在本数据集上进行跨帧自监督训练并对复杂例子进行在线环式优化,相较现有的单一像素或者顶点外观流方法,wFlow 在真实世界图片上泛化性更高,优于其他 SOTA 方法。
网站: https://awesome-wflow.github.io/
arXiv: https://arxiv.org/abs/2203.15320

语言作为查询的参考视频目标分割框架
Language as Queries for Referring Video Object
这篇工作由字节跳动商业化技术团队与香港大学合作完成。
文章提出了在参考视频目标分割(Referring Video Object Segmentation, RVOS)领域进行端到端分割的解决方案。
参考视频目标分割(RVOS)任务需要在视频中将文本所指代的参考对象进行实例分割,与目前得到广泛研究的参考图像分割(RIS)相比,其文本描述不仅可以基于目标的外观特征或者空间关系,还可以对目标所进行的动作进行描述,这要求模型有着更强的时空建模能力,且保证分割目标在所有视频帧上的一致性;与传统的视频目标分割(VOS)任务相比,RVOS 任务在预测阶段没有给定分割目标的真值,从而增加了对目标进行正确精细分割的难度。
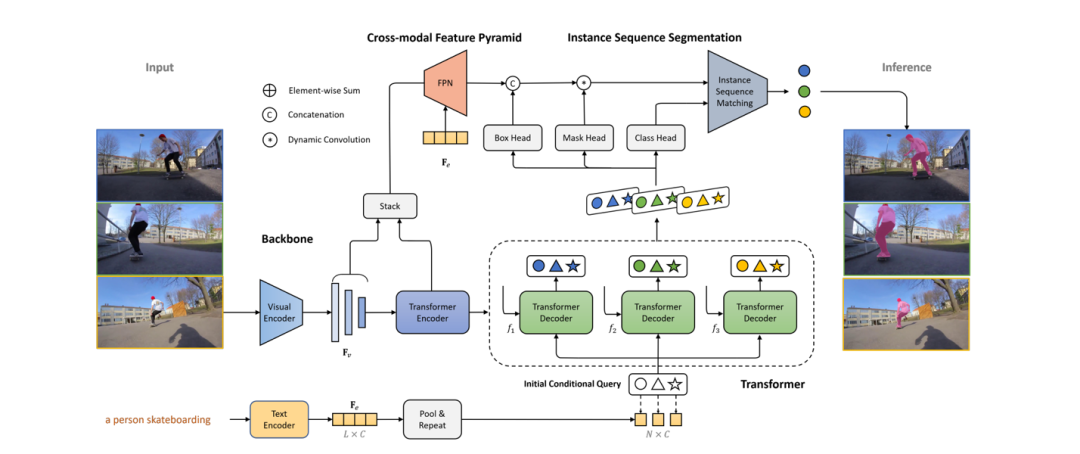
现有的 RVOS 方法往往都依赖于复杂的多阶段框架,以保证分割目标的一致性。为了解决以上问题,本文提出了一种基于 Transformer 的端到端 RVOS 框架 —— ReferFormer,其将语言描述作为查询条件,在视频中仅仅关注于参考目标,并采用动态卷积对目标进行分割;除此之外,通过连接不同帧上相对应的查询进行实例的整体输出,可自然地完成目标的追踪,无需任何后处理。该方法在四个 RVOS 数据集上(Ref-Youtube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences)均取得了当前最优的性能。
arXiv: https://arxiv.org/abs/2201.00487
code: https://github.com/wjn922/ReferFormer

GCFSR: 不借助人脸先验,一种生成细节可控的人脸超分方法
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
这篇工作由字节跳动智能创作团队和中国科学院先进技术研究院共同完成。
人脸超分辨通常依靠面部先验来恢复真实细节并保留身份信息。在 GAN piror 的帮助下,最近的进展要么设计复杂的模块来修改固定的 GAN prior,要么采用复杂的训练策略来对生成器进行微调。
论文作者提出了生成细节可控的人脸超分框架 GCFSR,能在无需任何额外的先验的情况下,重建具有真实身份信息的图像。
该框架是一个编码器-生成器架构。为了完成多个放大倍率的人脸超分,我们设计了两个模块:旨在生成逼真的面部细节的样式调制模块,以及根据条件放大倍率对多尺度编码特征和生成特征进行动态融合的特征调制模块,以实现用端到端的方式从头开始训练。
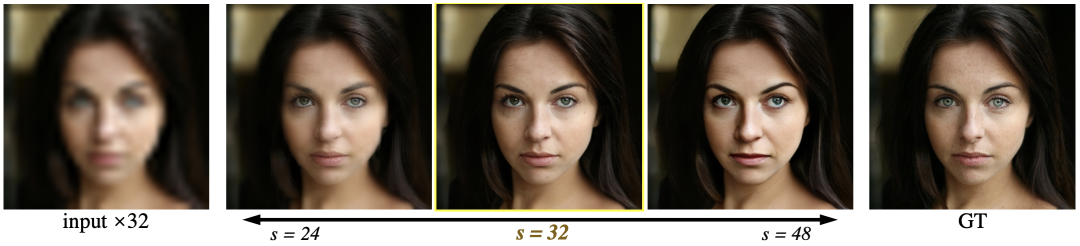
对于较小倍率超分(<=8),该框架可以在仅有的 GAN loss 的约束下产生令人惊讶的好结果。在添加 L1 loss 和 perceptual loss 后,GCFSR 可以在大倍率超分任务上(16, 32, 64)达到 SOTA 的结果。
网站: https://github.com/hejingwenhejingwen/GCFSR
arXiv: https://arxiv.org/abs/2203.07319

局部解耦的图像生成
SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
这篇论文来自字节跳动智能创作团队。
由于 StyleGAN 的 latent space 是基于图像尺度来分解的,这使得 StyleGAN 擅长处理全局风格,却不利于局部编辑。这篇论文提出一种新的 GAN 网络,使得 latent space 在不同的语义局部上解耦。
为了实现这一目标,本文从 inductive bias 和监督信息两个方面入手。在第一方面,本文将 StyleGAN 生成器的底层生成模块分解为不同的局部生成器,每个生成器生成对应某个区域的局部特征图(feature map)和伪深度图(pseudo-depth map),这些伪深度图随后以类似 z-buffering 的方式组合全局的 semantic mask 和 feature map 来渲染图像。在监督信息方面,本文提出了一种 dual-branch discriminator,同时对图像及其语义标签同时建模,保证每一个局部生成器能对应有意义的局部。

最终得到的模型能够对每个语义局部构建独立的 latent space,实现局部的风格变换。同时可以在保证局部可控的前提下配合 latent space 的编辑方法进行图像编辑。
网站: https://semanticstylegan.github.io
arXiv: https://arxiv.org/abs/2112.02236

基于学习结构和纹理表征的三维感知图像生成
3D-aware Image Synthesis via Learning Structural and Textural Representations
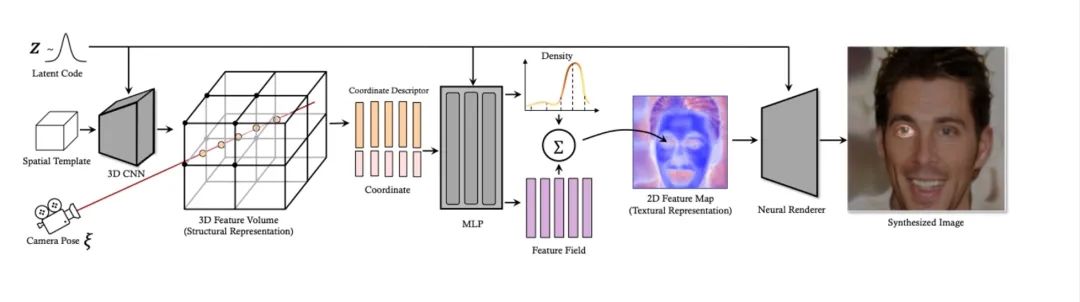
这篇工作由字节跳动智能创作团队和香港中文大学、浙江大学共同完成。
这篇论文主要研究如何让生成模型感知到三维信息。目前已有的研究主要将生成对抗网络中的生成器替换为神经辐射场(NeRF),NeRF 可以将三维空间坐标当作先验,逐像素地渲染出一张图片来。但 NeRF 中的隐式函数有一个非常局部的感受野,使得生成器很难意识到物体的全局结构,并且 NeRF 建立在体绘制(volume rendering)的基础上,增加了生成成本和优化难度。
为了解决这两个问题,论文作者提出了一个新的三维感知生成器来显示地学习物体的结构表征和纹理表征,名为 VolumeGAN。该生成器首先学习一个用来表示物体底层结构的特征体(feature volume),然后将这个特征体转换为特征场(feature field),再通过积分的形式将之转换为特征图(feature map),最终利用神经渲染器合成一张二维图像。
在众多数据集上进行的大量实验表明,与以前的方法相比,该方法取得了更好的生成图像质量以及更加准确的三维可控性。
arXiv: https://arxiv.org/abs/2112.10759
code: https://github.com/genforce/volumegan
demo: https://www.youtube.com/watch?v=p85TVGJBMFc

舞者追踪:统一外观和多样运动的多物体追踪
DanceTrack: Multi-Object Tracking in Uniform
这篇工作由字节跳动商业化技术团队与香港大学、卡耐基梅隆大学合作完成。
文章提出了一个新的多物体追踪数据集 DanceTrack,数据集的显著特点是:
(1)统一外观。舞者的着装高度相似,外观几乎无法区别。
(2)多样运动。舞者的运动模式复杂,来回穿梭。
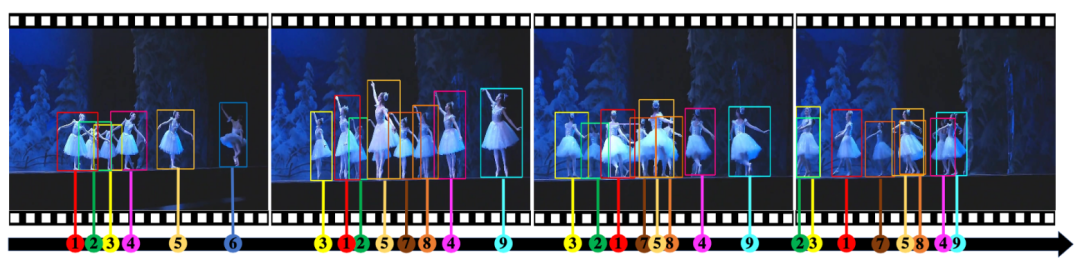
物体跟踪中可供利用的特征一般包括运动特征和外观特征。当前众多跟踪模型强依赖于外观模型提取物体特征,区分不同物体实例,在视频的不同帧间关联物体。然而外观特征并不总是有效的,如果追踪物体的外观基本一致时,现有模型的的表现如何?同时,当前主流多物体追踪数据集中物体的运动模式非常简单,近乎匀速直线运动,如果物体的运动模式非常复杂,多个物体互相来回穿梭,现有模型的的表现如何?实验结果显示现有模型在 DanceTrack 数据集上的性能远低于其他数据集,揭示了现有方法在统一外观和多样运动场景下的局限性。我们期待 DanceTrack 能够启发后续的多物体追踪方法。
arXiv: https://arxiv.org/abs/2111.14690
github: https://github.com/DanceTrack/DanceTrack

XMP-Font: 基于自监督跨模态预训练模型的少样本字体生成
XMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation
这篇论文来自字节跳动智能创作团队。
论文主要研究通过理解汉字书写基本笔画之间的复杂关系,来保证生成字体的质量。
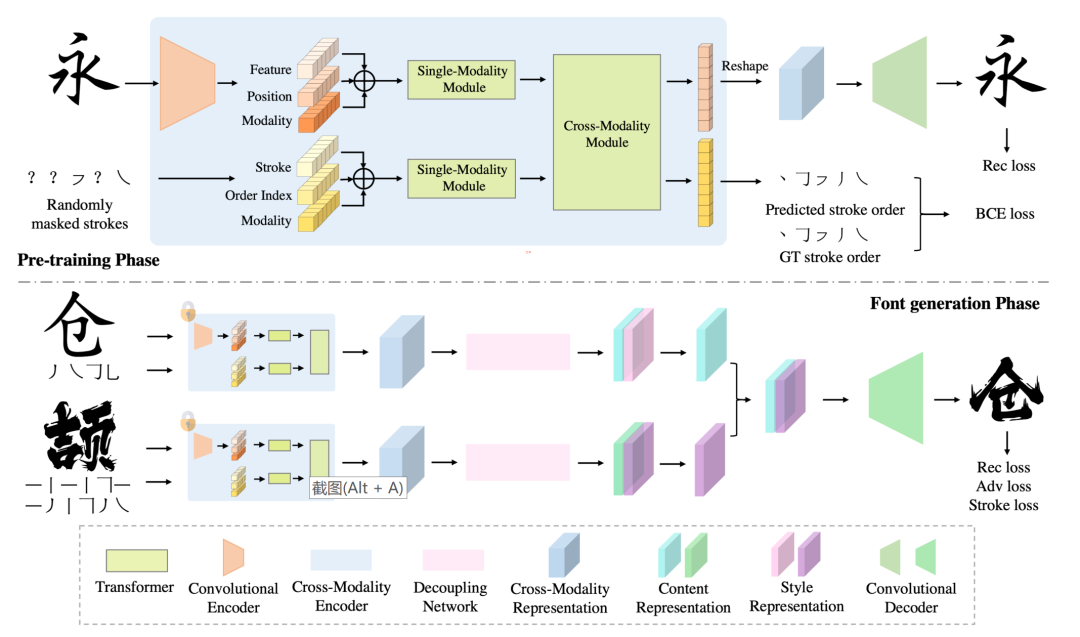
作者提出了一种基于自监督跨模态预训练模型的少样本字体生成算法。
首先在预训练阶段,预训练一个基于 BERT 的跨模态特征提取模型,通过重建损失和笔画预测损失,保证在不损失信息的情况下,让提取到的字体特征充分理解笔画之间的关系。之后,通过预训练好的特征提取器分别提取源域字和参考字的特征,并进行解耦重组,最终生成和参考字形相同字体的源域字。
此外,作者在字体生成阶段提出针对汉字的 stroke loss,进一步提高了生成质量。
通过实验的量化指标和问卷调研的结果表明,这篇论文提出的 XMP-Font 优于其他 SOTA 方法。
arXiv: https://arxiv.org/abs/2204.05084

多尺度特征融合Transformer
Shunted Self-Attention via Multi-Scale Token Aggregation
这是一篇 CVPR Oral Presentation 论文,由字节跳动智能创作团队与新加坡国立大学、华南理工大学合作完成。
文章提出了一种新的多尺度自注意力机制:在每一层进行 correlation 学习的时候, 赋予不同 token 不同的感受野,进而学习到不同尺度 semantics 之间的相关性。

这篇论文的多尺度信息是并行存在于同一个 block 的 input token 上的, 而不是通过传递不同 block 之间的 token 进行融合。因此方法在 COCO 等包含不同大小物体的数据集上性能优势尤为明显,对比 SWIN transformer,在模型内存和计算量类似的情况下,可达到 3-4% mAP 的性能提升。
arXiv: https://arxiv.org/abs/2111.15193
GitHub: https://github.com/oliverrensu/shunted-transformer

TransMix: 几行代码帮助Vision Transformer无痛涨点
TransMix: Attend to Mix for Vision Transformers
这篇工作由字节跳动商业化技术团队与约翰霍普金斯大学、牛津大学合作完成。
基于 Mixup 的数据增强已经被证明在训练过程中对模型进行泛化是有效的,特别是对于 Vision transformer(ViT),因为它们很容易过拟合。
然而,以往基于 Mixup 的方法有一个潜在的先验知识,即目标的线性插值比率应该与输入插值中提出的比率保持一致。这可能会导致一种奇怪的现象,有时由于增广的随机过程,Mixup 图像中没有有效的对象,但标签空间中仍然有响应。
为了弥补输入空间和标签空间之间的差距,本文提出了 TransMix,它基于 Vision transformer 的Attention Map mix labels。Attention Map 对相应输入图像的加权越高,标签的置信度越大。
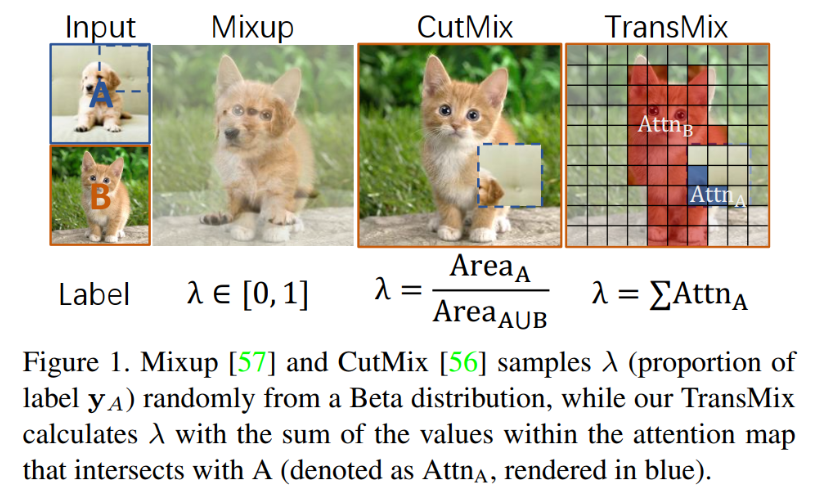
TransMix 非常简单,只需几行代码就可以实现,且无需向基于 ViT 的模型引入任何额外的参数和计算量,可以完全无痛地帮助各种基于ViT 的模型性能在多个不同任务(分类,检测,分割及鲁棒性)和数据集上大幅提升。
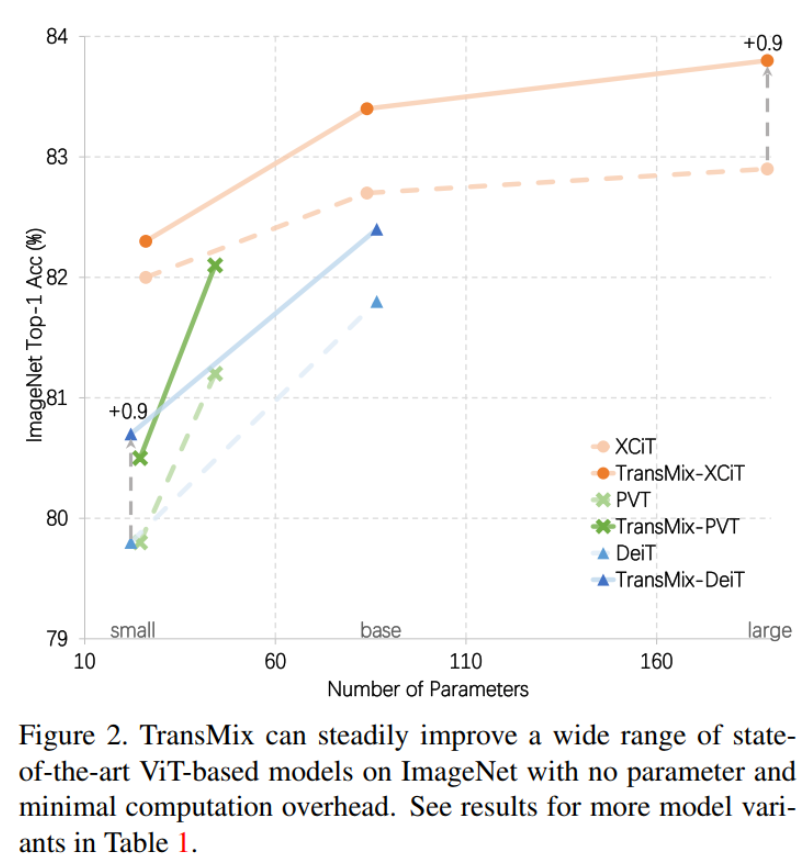
arXiv: https://arxiv.org/abs/2111.09833
Github: https://github.com/Beckschen/TransMix

基于压缩域的端到端通用事件表示学习
End-to-End Compressed Video Representation Learning for Generic Event Boundary Detection
这篇工作由字节跳动智能创作团队和中国科学院大学、中国科学院软件研究所共同完成。
传统的视频处理算法需要对视频进行解码,在解码后的 RGB 帧上进行训练和推理。然而视频解码本身需要占用比较可观的计算资源,并且视频相邻帧之间包含了大量的冗余信息。
另外在视频编码格式中的运动向量(Motion Vector)和残差(Residual)包含了视频的运动信息,这些信息能够为更好地理解视频提供更多帮助。
基于上述两点考虑,文章提出了一种在视频压缩域(Compressed Domain)上进行端到端通用事件检测(GEBD)的解决方案,希望能够使用视频压缩域上的解码中间信息来对非关键帧进行快速高质量的特征提取。
为此,论文提出了 SCCP(Spatial Channel Compressed Encoder)模块。对于关键帧,在完全解码后使用常规骨干网络提取特征;对于非关键帧,通过使用运动向量和残差以及对应的关键帧特征在轻量级的网络上提取非关键帧的高质量特征;同时利用 Temporal Contrasitive 模块实现端到端的训练和推理。
实验证明在保持和传统完全解码方法精度相同的前提下,我们的方法在模型上的提速 4.5 倍。

arXiv: https://arxiv.org/abs/2203.15336

模仿oracle:通过初始阶段的表征去相关性来提升类增量学习
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
这篇工作由字节跳动智能创作团队与新加坡国立大学、中科院自动化所、牛津大学合作完成。
本文主要研究了 class incremental learning,即类增量学习。最终的学习目标是希望通过阶段式的学习(phase-by-phase learning)能够得到一个与 joint training 性能匹配的模型。
一个分为多个阶段的类增量学习过程可以分成两个部分,即 initial phase(第一个学习阶段)与 later phase(除第一个学习阶段后面所有的学习阶段)。先前的工作不会对 initial phase 做特殊处理,而是在 later phase 对模型进行正则化来减轻遗忘。但是在这篇工作中,作者们发现 initial phase 在类增量学习的过程中同样关键。
作者们通过可视化发现,一个仅在 initial phase 训练得到的模型与 joint training 的 oracle model 输出的表征的最大区别是:initial-phase-model 的 representation 的分布只会集中在 representation space 的一个狭长的区域,而 oracle model 的 representation 将较为均匀的分布于各个方向。
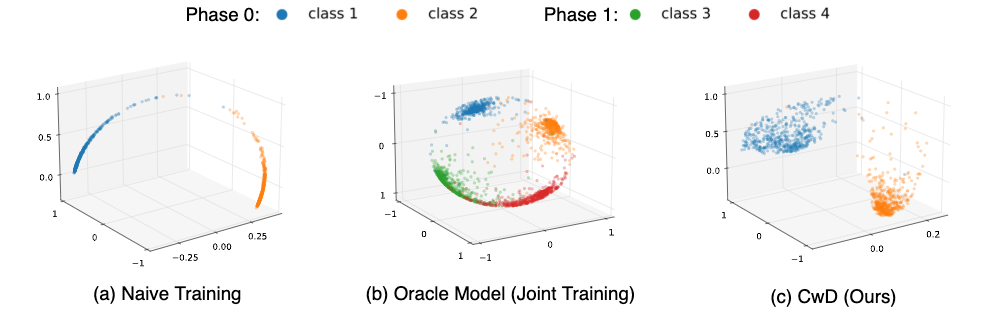
因此,作者们提出了一个新颖的正则项:Class-wise Decorrelation(CwD),只作用于 initial phase 的训练过程,使 initial phase 学习得到的模型的 representation 在空间中的分布能够在各个方向更加均匀,从而能够与 oracle model 更加相似。CwD 正则项能够对以往的 SOTA 类增量学习方法有约 1%~3% 的提升。
arXiv: https://arxiv.org/abs/2112.04731
code: https://github.com/Yujun-Shi/CwD

DINE: 基于单个或者多个黑盒源模型的域自适应
DINE: Domain Adaptation from Single and Multiple Black-box Predictors
这篇工作由字节跳动智能创作团队与中科院自动化所、新加坡国立大学合作完成。
论文作者提出了一种只需要预训练好的黑盒源域模型就可以有效进行无监督视觉域自适应的方法。不同于以往的基于源域数据或者白盒源域模型的域自适应,在黑盒域自适应问题中,只有源域模型的预测可见。
作者提出了先蒸馏再微调的方法(DINE) 来解决这一问题。在蒸馏阶段,作者利用自适应标签平滑的策略,只需要源模型的前 k 个预测值,即可得到有效的伪标签,用于单个样本的知识蒸馏。此外,作者利用样本混合策略来实现样本之间随机插值的一致正则化,以及利用互信息最大化实现对于全局样本的正则化。为了能学到更适合目标域数据的模型,作者在微调阶段只利用互信息最大化对蒸馏之后的模型进行微调。
DINE 可以利用单个或多个源模型,保护了源域的信息安全,且不要求跨域的网络结构一致,能针对目标域的计算资源情况实现简单而有效的自适应。在多个场景如单源、多源和部分集域自适应上的实验结果证实,与基于源域数据的域自适应方法相比,DINE 均获得了极具竞争力的性能。
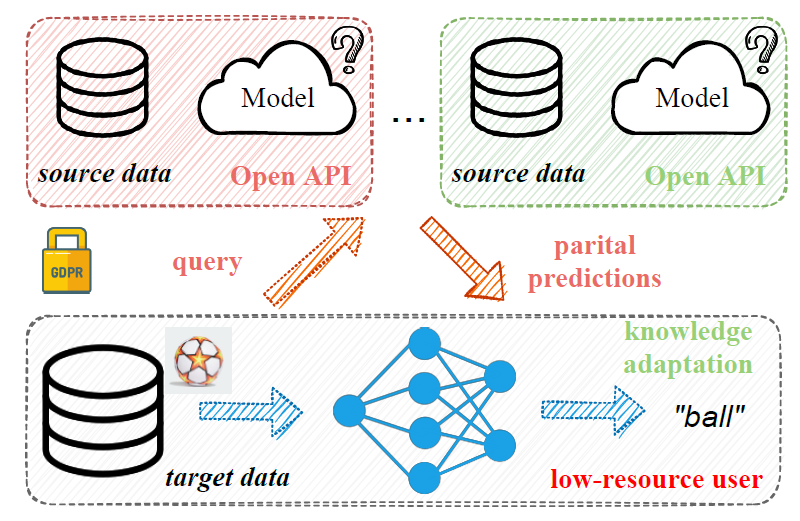
arXiv: https://arxiv.org/abs/2104.01539
github: https://github.com/tim-learn/DINE

NightLab: 基于检测的双层结构耦合的夜景分割方法
NightLab: A Dual-level Architecture with Hardness Detection for Segmentation at Night
这篇工作由字节跳动智能创作团队和加州大学美熹徳分校合作完成。
这篇论文主要研究夜景的语义分割问题,作者提出了一种集成多种深度学习模块的夜景分割方法 NightLab,它具有更好夜间感知和分析能力,主要包含两种颗粒度级别的模型,即全图和区域级别,每个级别的模型都是由光适应和分割模块构成的。给定夜间图像,全图级别的模型会提供一个初始分割结果,同时,NightLab 会用到检测的模型去提供一些图中比较难识别的区域。这些难识别的区域对应的图像,会被区域级别的模型进行进一步的分析。区域级模型会专注于这些难识别的区域去改善分割结果。NightLab 中的所有模型都是端到端训练的。
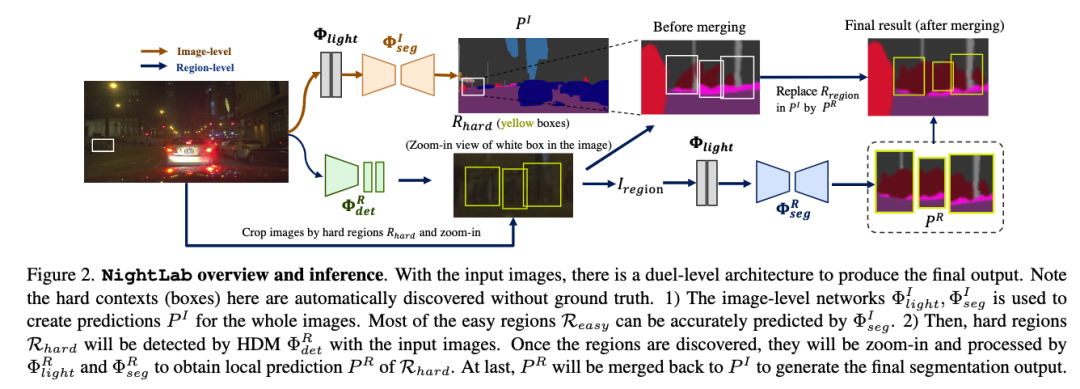
作者通过实验证明,NightLab 在 NightCity 和 BDD100K 公开数据集中达到了 SOTA。
arXiv: https://arxiv.org/abs/2204.05538

基于知识蒸馏的高效预训练
Knowledge Distillation as Efficient Pre-training: Faster Convergence, Higher Data-efficiency, and Better Transferability
这篇工作由字节跳动商业化技术团队与香港大学、牛津大学合作完成。
大规模的预训练已被证明对广泛的计算机视觉任务都十分关键,能够带来显著的涨点;然而,随着预训练数据量的增大,私有数据的出现,模型结构的多样化,将所有的模型结构都在大规模预训练数据集上进行预训练,变得昂贵、低效、不实际。
研究者们思考:是否一个已经在大量数据上预训练好的模型已经提取了大量数据的知识,并且可以仅通过少部分预训练数据,将其高效快速的传递给一个新的模型?
进而,研究者们提出通过知识蒸馏来实现高效模型预训练。他们发现,传统的知识蒸馏由于在分类的 logits 上进行蒸馏,而这些分类的 logits 并不会被利用到下游迁移任务中,因此并不适合于预训练需要的特征学习。对此,研究者们提出一种基于无额外参数特征维度对齐的纯特征蒸馏方法。
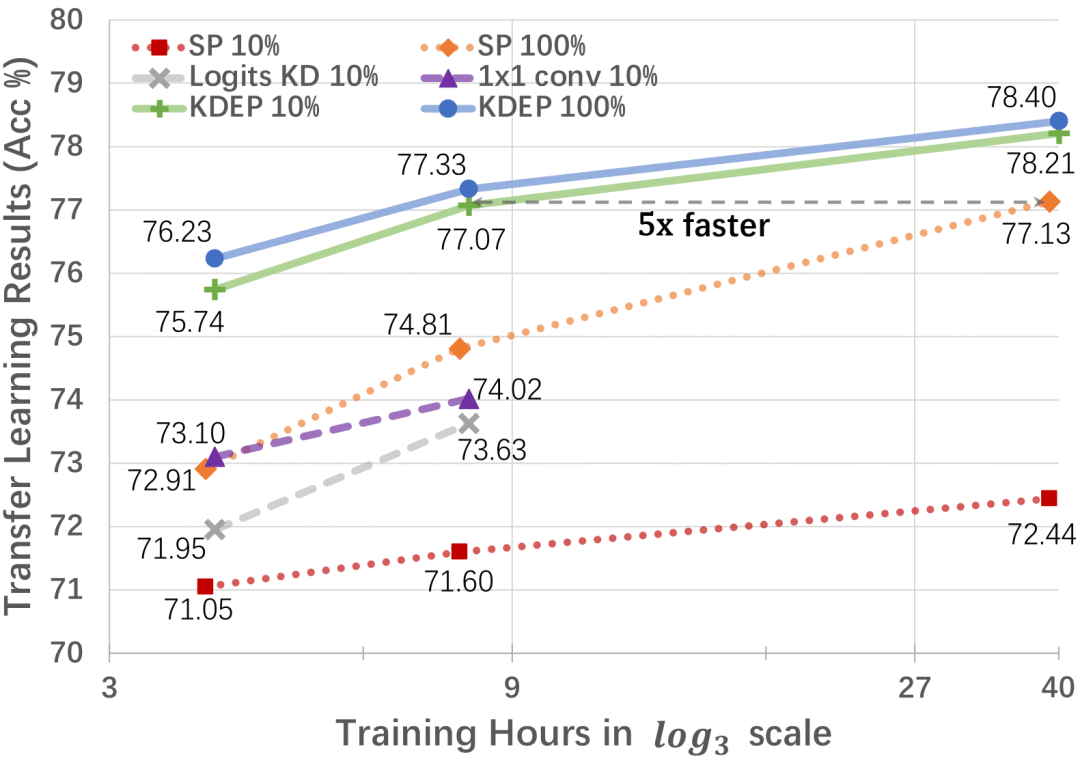
采用所提出的方法,仅使用 1/10 的预训练数据和 1/5 的预训练时间,就可以达到有监督预训练的迁移效果(在图像分类、语义分割、目标检测任务上评估迁移效果)。
arXiv: https://arxiv.org/abs/2203.05180
Github: https://github.com/CVMI-Lab/KDEP

傅里叶文档矫正
Fourier Document Restoration for Robust Document Dewarping and Recognition
这篇工作由字节跳动商业化技术团队与新加坡南洋理工大学合作完成。
现有的文档矫正方法大多利用图片生成技术来模拟形变文档,从而学习并预测文档的 3D 信息并进行矫正。由于合成图片与真实图片 domain gap 较大,这样训练出来的网络在真实图片上泛化能力较差。
我们提出一种可以直接在少量真实数据上进行训练的文档矫正方法 FDRNet。对于文档图片,文本内容通常由傅里叶空间中的高频信息组成,而文档背景则由低频信息组成。基于这一特性,FDRNet 在训练过程当中只关注于文档图片的高频信息并且忽略低频信息,从而利用文档的文本特征(而不是文档的 3D 信息)来矫正文档图片。这样使得 FDRNet 在训练过程当中不需要复杂的文档 3D ground-truth,而是可以直接利用现有的文档图片直接进行训练。FDRNet 用百分之一量级的真实图片训练即可达到 SOTA 效果,并且对于任意形变的文档矫正效果更佳。

arXiv: https://arxiv.org/abs/2203.09910
猜您喜欢:

附下载 |《TensorFlow 2.0 深度学习算法实战》


