- 1Android精美登录界面设计
- 2使用 Calendar 计算时间_calendar 时间计算
- 3redis在linux的安装及redis常用指令的使用_linux 通过命令增加redis内存
- 4rabbitMQ知识概括_rabbitmq 端口
- 5模仿dcloudio/uni-preset-vue 自定义基于uni-app的小程序框架
- 6python断言assert实例求素数_Python单元测试框架之pytest -- 断言
- 7数字图像处理、计算机图形学相关的名词解释和解答题(二)
- 8使用vscode进行rebase拉取_vscode rebase
- 9翻译:Face-Sensitive Image-to-Emotional-Text Cross-modal Translation for Multimodal Aspect-based Sentim
- 10为什么java会发生溢出,java – 为什么这个乘法整数溢出导致零?
【NLP】GPT GPT-2 GPT-3语言模型_gpt3 是decoder
赞
踩
一、GPT简介
我们说BERT是Transformer的encoder,那么GPT就是Transformer的decoder。GPT全称为Generative Pre-Training。
参数量对比:ELMO-94M、BERT-340M、GPT-2-1542M(大规模)、GPT-3-175B(超大规模)
二、GPT基本原理
GPT的原理并不复杂,首我们知道它是基于Transformer的decoder结构。
首先,通过自注意力机制,去计算词嵌入之间的attention,然后做weighted-sum,再经过全连接层等,最终得到输出结果。注意:因为这里是Transformer的decoder,所以是masked-attention,每个输入只能看得到前面的词。

后面同理,以此类推:
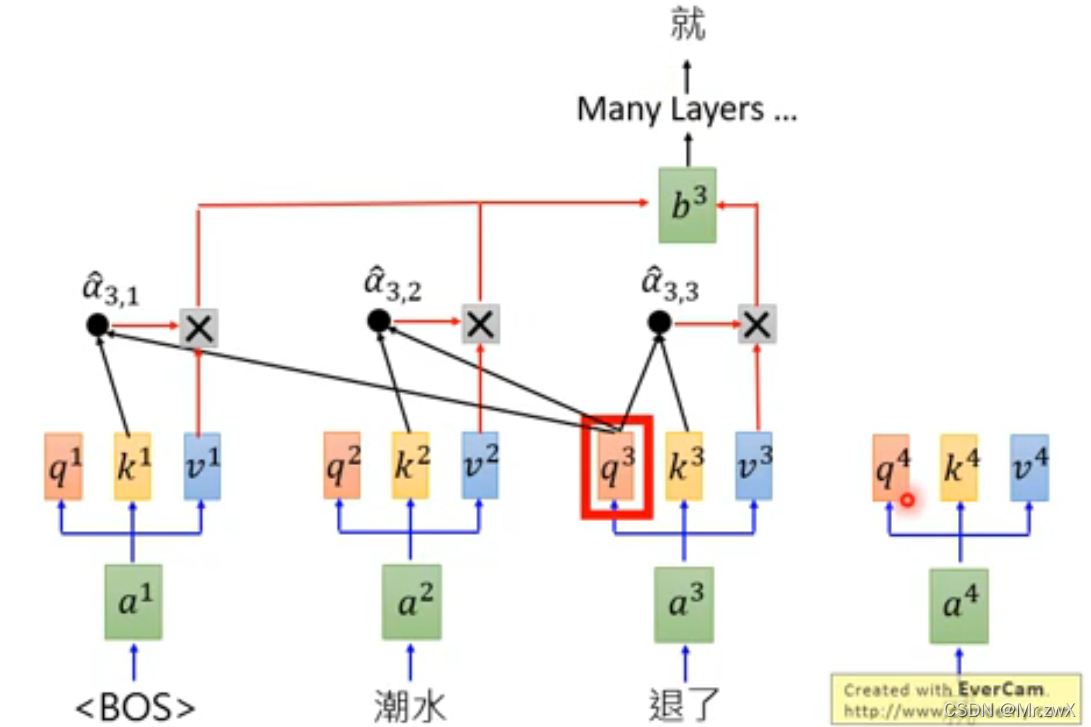
三、GPT
Improving Language Understanding by Generative Pre-Training
1 训练目标
无监督预训练
给前面一段话,预测之后的词,采用最大似然的方式作为目标:
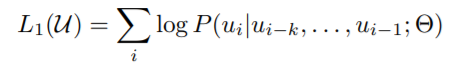
BERT没有用这种标准的语言模型目标,而是采用的完形填空作为目标,所以说GPT的训练目标更困难。
有监督微调
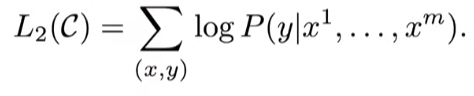
最终目标
结合上面两种目标进行训练能得到更好的效果:
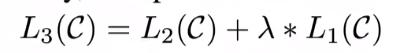
2 微调的不同任务
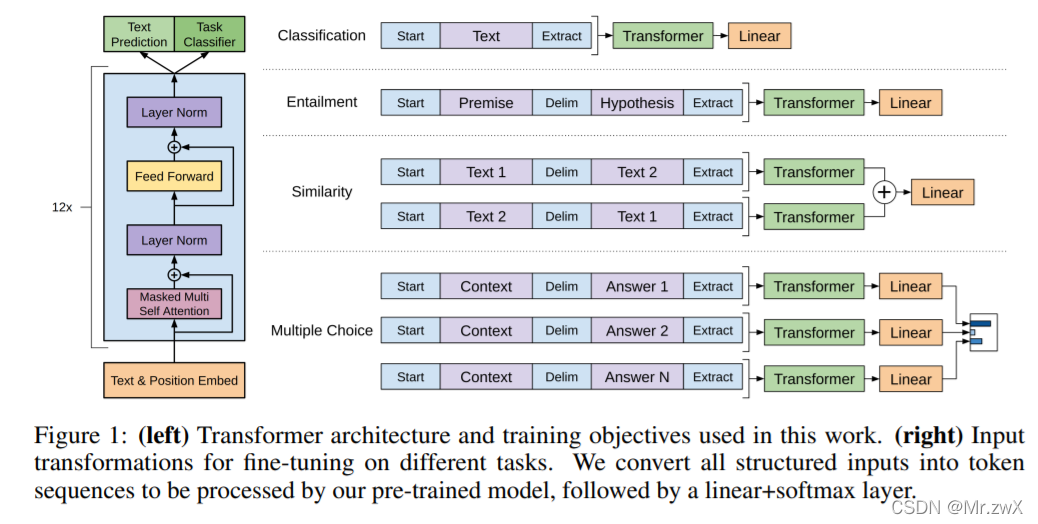
- Classification:对序列进行分类,属于多分类问题
- Entailment:蕴含,给出前提和假设,判断是否成立/无关,属于三分类问题
- Similarity:判断两段文字是否相似,需要将两段进行交换区再进行判断(对称性),属于二分类问题
- Multiple Choice:多选问题,对每个问题都输出一个值,得到多选题的答案
四、GPT-2
Language Models are Unsupervised Multitask Learners
用了新的数据集进行训练:百万级别的文本。同时模型规模也变大很多,参数量变为15亿(BERT_LARGE参数量3.4亿)。规模变大这么多的情况下,作者发现和BERT相比优势不大,所以选择了另一个观点作为切入点——Zero-shot(简单来说就是,训练好一个模型,在任何一个场景都能直接使用,泛化性很好)。
李沐老师在这里说了一点对科研的想法:如果GPT-2仅仅是在GPT的基础上变大,效果更好,那就是做一个工程的感觉,这篇文章会不太有意思。但是如果说换一个角度思考,去做一个更困难的问题,虽然效果有上有下,但这样新意度一下子就上来了!做科研不要一条路走到黑,要灵活思考,从新角度看问题。
作者设计了如下四种规模的模型:

GPT-2的架构非常非常大,参数量也非常多。非常神奇的事情发生了,GPT-2在完全没有训练数据的情况下,做到reading comprehension、summarization、translation这些任务!BERT是需要数据训练才能做到。

五、GPT-3
训练了一个175亿参数的GPT-3模型,做下游任务的时候,GPT-3不做梯度更新和微调。GPT-3的架构和GPT-2相同,其改进是将Sparse Transformer中的东西应用了过来。
下面这幅图解释了如何将GPT-3理解为meta learning,模型学习了很多不同的任务,可以类比成元学习的过程,因此具有更好的泛化性。
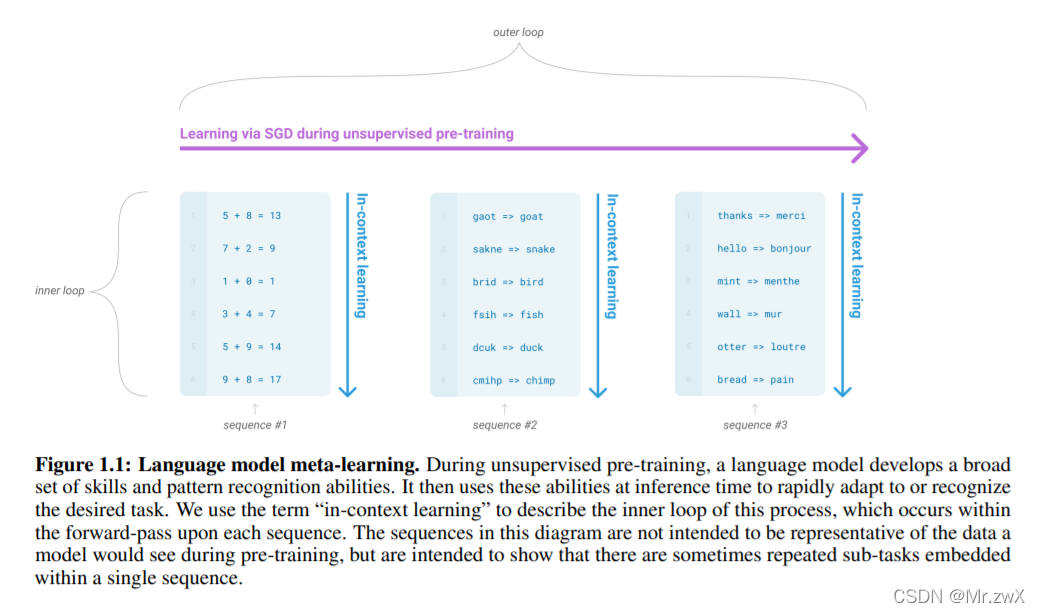
在评估GPT-3的时候,采用了三种方式:
-
few-shot learning

-
one-shot learning:在具体任务上,会给模型一个例子,但是并不训练!不更新梯度!只完成前向传播!期望通过注意力机制处理长句子,并从中抽取有用的信息。

-
zero-shot learning
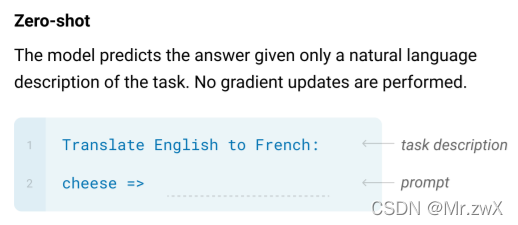
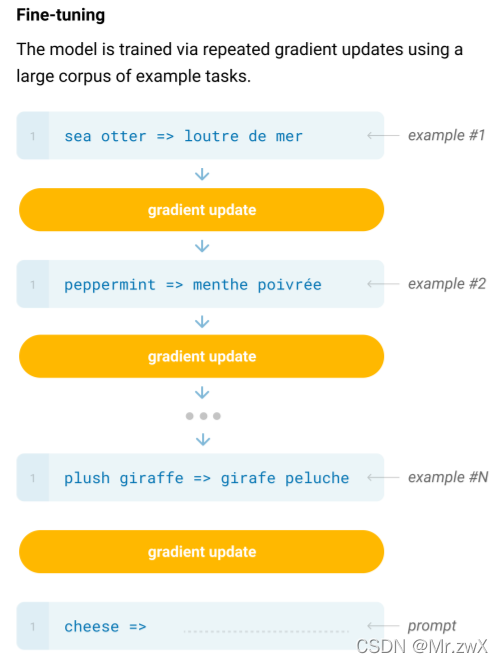
作者也介绍了fine-tuning的过程,但是GPT-3应用在具体任务上时并不使用fine-tuning和梯度更新。
作者设计了8种不同规模的模型:

模型的计算复杂度与层数(深度)成线性关系,与宽度成平方关系。
GPT-3有如下一些局限性:
- 很难生成非常长的文本
- 采用的decoder,所以只能向前面看
- 很均匀地区预测词,没有侧重点
- 没有见过视频、图像或者物理层面交互
- 样本有效性不够,用了太大规模的数据
- 到底是学到的知识,还是从之前的“记忆”里提取相关内容
- 计算量非常大
- 可解释性不强
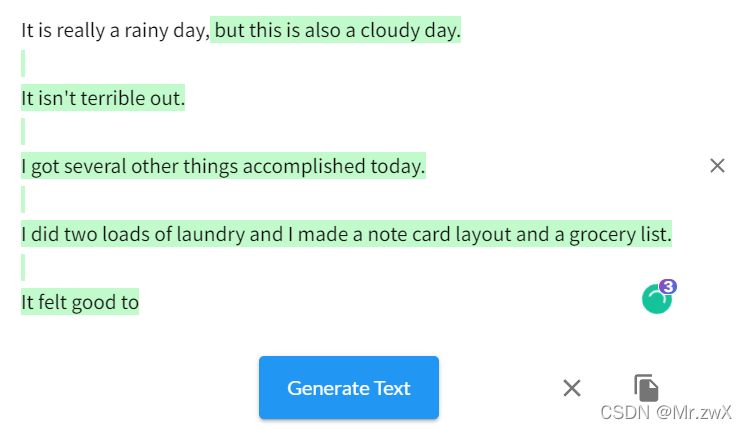
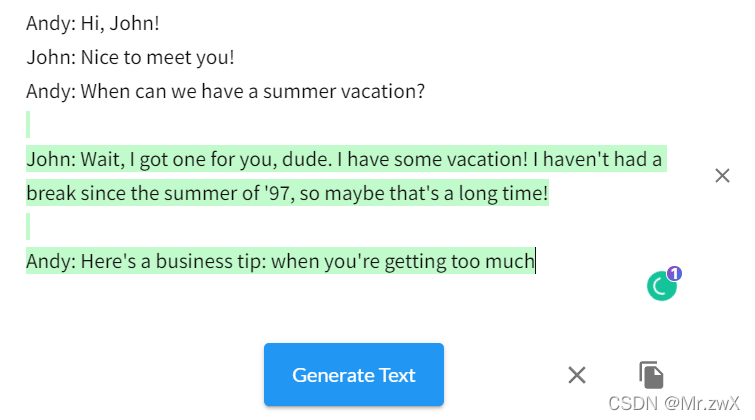
六、落地应用
现在有很多这样基于Transformer的网站,能做到续写故事、生成对话、生成代码等等神器的事情。在google中输入talktotransformer能搜到很多类似的网站,下面举一个例子。