
- 1论文阅读笔记《Squeeze-and-Excitation Networks》_独热激活
- 2基于微信小程序毕业设计选题200例【题目新颖】_什么小程序适合当毕设
- 3git stash 常用命令_git stash 备注
- 4公众号榜单 | 2020·5月公众号行业排行榜重磅发布_2020微信公众号影响力排行榜类别
- 5计算机专业选择银行必须知道的20个问题_面试问题对银行it有什么了解
- 6java RSA 加密 解密
- 7oracle自定义字符串分割函数
- 8LLMs之GPT-4 Turbo:11月6日OpenAI重磅更新—在DevDay上宣布的新模型和开发者产品(全新的GPT-4 Turbo、128K上下文窗口、视觉功能)_gpt-4 turbo llm
- 9学生成绩管理系统设计报告python,学生成绩管理系统(Python学习)
- 10【正点原子STM32连载】 第九章 STM32启动过程分析 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1_正点原子stm32h7驱动
LLM 大模型为什么会有上下文 tokens 的限制?
赞
踩
▼最近直播超级多,预约保你有收获
今晚直播:《构建企业专用大模型实战》
—1—
大模型为什么会有 tokens 限制?
人是以字数来计算文本长度,大语言模型 (LLM)是以 token 数来计算长度的。LLM 使用 token 把一个句子分解成若干部分。
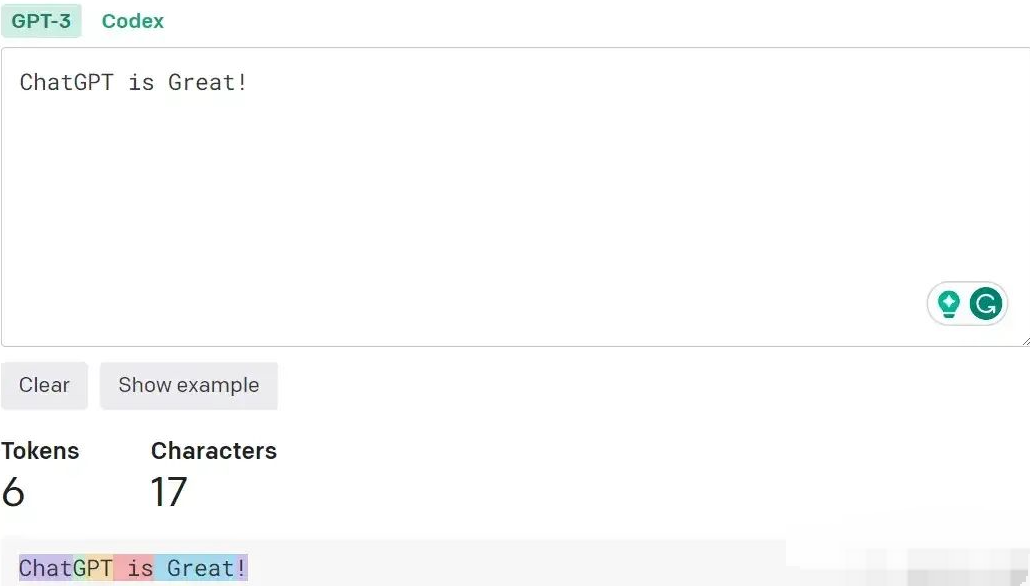
token 可以是一个单词、一个单词中的一个部分、甚至是一个字符,具体取决于它使用的标记化方法 (tokenization method)。比如:句子 "ChatGPT is great !" 可能会被分割成 ["Chat", "G", "PT", " is", " great", "!"] 这 6 个 tokens。
上下文 token 长度为什么会有限制?有以下3方面的相互制约:文本长短、注意力、算力,这3方面不可能同时满足,也就是存在“不可能三角”,如下图所示:
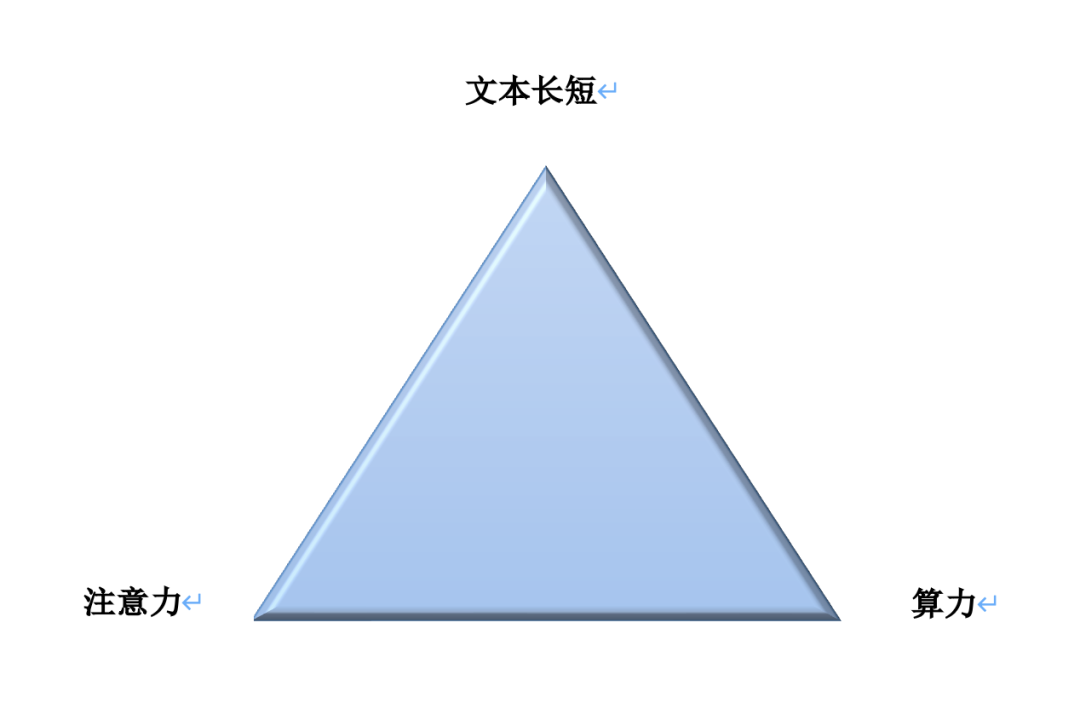
也就是说:上下文文本越长,越难聚焦充分注意力(Transformer 网络的注意力机制),难以完整理解;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,从而提高了成本。
根本原因还是大模型的 Transformer 网络结构的自注意力机制,自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如:上下文增加32倍时,计算量实际会增长1000倍。这就构成了“不可能三角”中的第一组矛盾:上下文文本长短与注意力。
另外在大模型实际部署时,企业端根本无法提供很大的算力支持,这也就倒逼厂商无论是扩大模型参数还是文本长度,都要紧守算力一关。但现阶段要想突破更长的文本技术,就不得不消耗更多的算力,于是就形成了文本长短与算力之间的第二组矛盾。
—2—
大模型如何突破 tokens 限制?
突破大模型的 tokens 限制主要采用以下 3种方法。
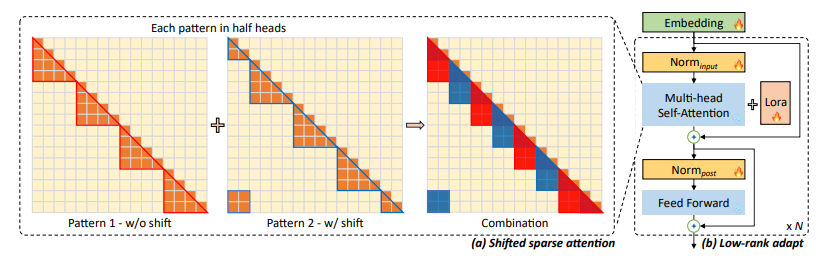
方法一:采用 LongLoRA 微调技术重建自注意力计算方式。
通过 LongLoRA 微调技术将长文本划分为不同的组,在每个组里进行计算,而不用计算每个词之间的关系,从而降低计算量,提供生成速度。
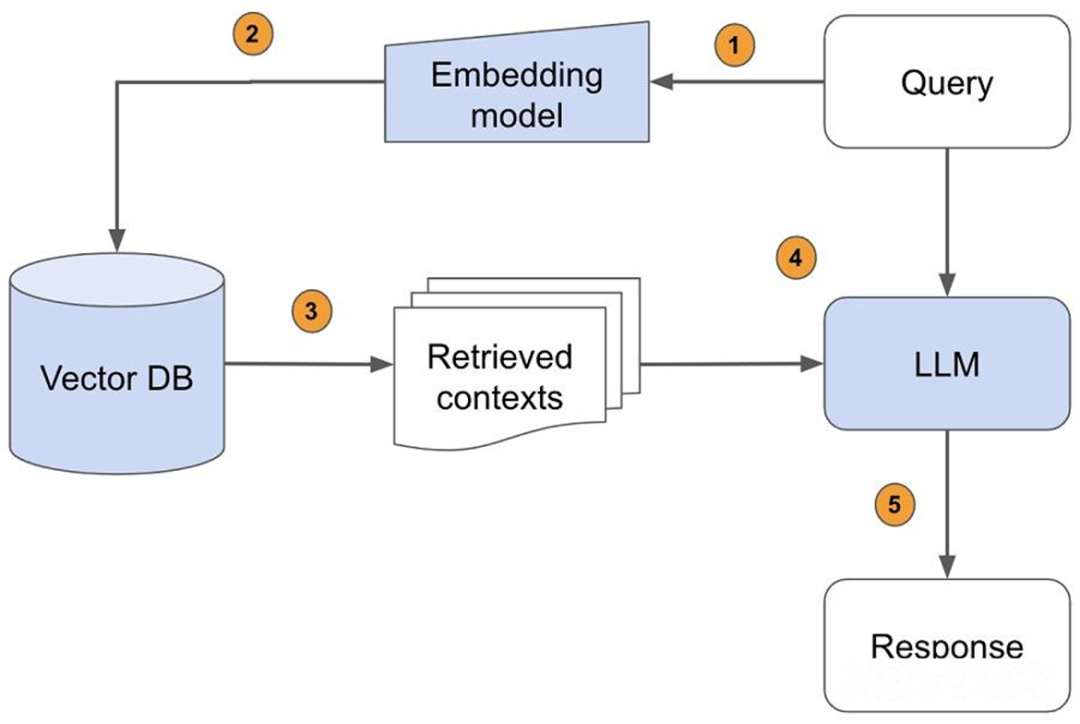
方法二:采用 RAG 技术给大模型开“外挂”。
将长文本切分为多个短文本处理,大模型在处理长文本时,会在向量数据库中对短文本进行检索,以此来获得多个短文本回答构成的长文本。每次只加载所需要的短文本片段,从而避开了模型无法一次读入整个长文本的问题。
方法三:提升大模型支持的上下文长度。
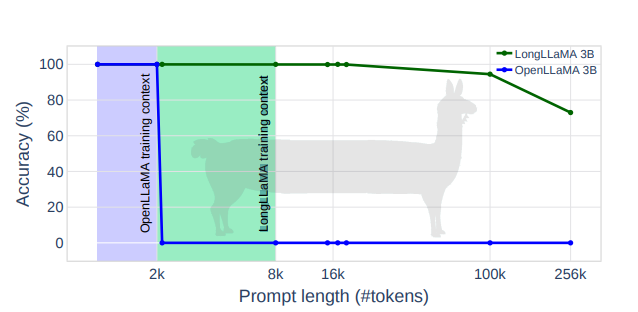
对大模型的上下文长度持续优化,比如:以 OpenLLaMA-3B 和 OpenLLaMA-7B 模型为起点,在其基础上进行微调,产生了LONGLLaMA 新模型。该模型很容易外推到更长的序列,在 8K tokens上训练的模型,很容易外推到 256K 窗口大小。
在技术侧这3种方法到底如何实现?今晚 20 点,我会开一场直播详细给大家剖析如何构建长下文的企业专用大模型。
直播精彩看点:
1、参数高效微调(PEFT) 之 LoRA 技术剖析
2、基于 LoRA 微调构建长上下文专用大模型过程详解
3、微调 Llama-2 模型根据自然语言生成 SQL 案例实践
请同学点击下方按钮预约直播,咱们今晚20点直播见!
—3—
关于《LLM 大模型技术知识图谱和学习路线》
最近很多同学在后台留言:“玄姐,大模型技术的知识图谱有没?”、“大模型技术有学习路线吗?”
我们倾心整理了大模型技术的知识图谱《最全大模型技术知识图谱》和学习路线《最佳大模型技术学习路线》快去领取吧!
LLM 大模型技术体系的确是相对比较复杂的,如何构建一条清晰的学习路径对每一个 IT 同学都是非常重要的,我们梳理了下 LLM 大模型的知识图谱,主要包括12项核心技能:大模型内核架构、大模型开发API、开发框架、向量数据库、AI 编程、AI Agent、缓存、算力、RAG、大模型微调、大模型预训练、LLMOps 等12项核心技能。

为了帮助每一个程序员掌握以上12项核心技能,我们准备了一系列免费直播干货,扫码一键免费全部预约领取!

END

