
- 1Redis缓存详解(黑马-未完结)_redis缓存介绍
- 2人脸识别示例解析(三)——微笑识别解析_面部识别 如何微笑
- 3渗透测试快速稳定远控软件,高级渗透测试第八季-demo即是远控
- 4基于java相亲交友系统的设计与实现论文_基于java的社交网站设计与实现
- 5文献学习-20-基于学习的视觉应变融合,用于手眼连续体机器人姿态估计与控制
- 6代码随想录-二分查找题目分析
- 7基于React Hooks的简单全局状态共享实现方案
- 8把数据从mysql导入到hdfs中_mysql to hdfs full
- 9淘宝人生2的AIGC技术应用——虚拟人写真算法技术方案
- 10MKS SERVO28C 闭环步进电机 使用说明_闭环步进电机怎么使用
改进yolov5实现目标检测与语意分割项目_yolov5语义分割
赞
踩
简介
- 基于ultralytics/yolov5多任务模型。
- 同时实现yolo目标检测与语意分割
- 以增加少量计算和显存为代价,同时完成目标检测和语义分割(1024×512输入约增加350MB,同尺寸增加一个bisenet需要约1.3GB,两个单任务模型独立输入还有额外的延时)。
- 模型在Cityscapes语义分割数据集和由Cityscapes实例分割标签转换来的目标检测数据集上同时训练,检测结果略好于原版单任务的YOLOV5(仅限于此实验数据集),分割指标s模型验证集mIoU
0.73,测试集0.715;m模型验证集mIoU 0.75测试集0.735。由于将继续考研,tag 2.0发布后仓库近期不会再频繁更新,issue大概率不会回复(问题请参考以下Doc,震荡爆炸请尝试砍学习率。 - List item
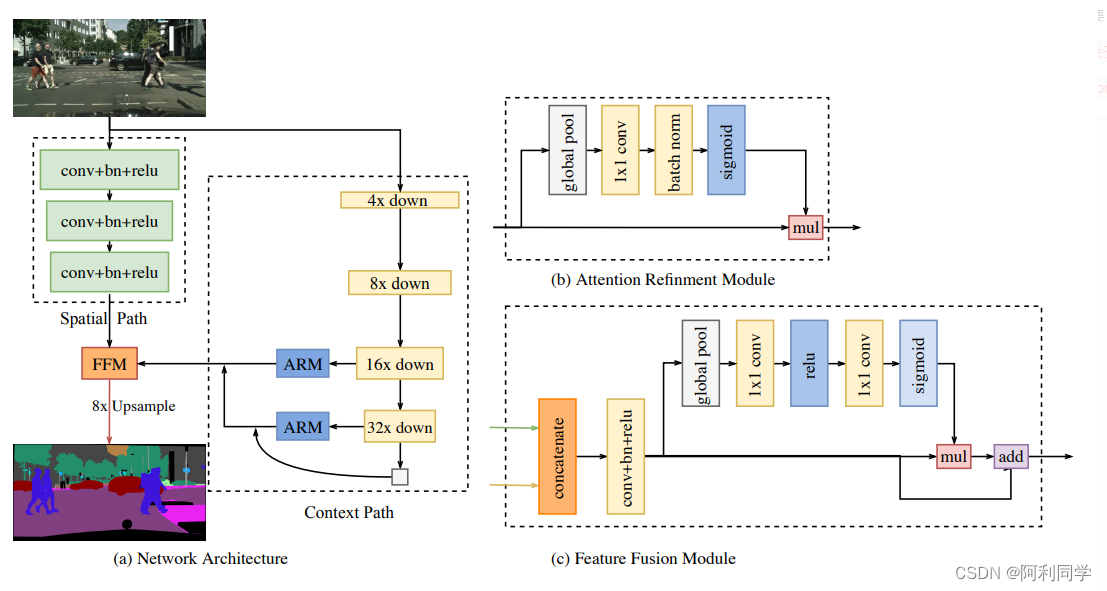
- 用了yolo官方的COCO检测预训练模型,训练中使用了检测数据,但推理时会比以上模型多跑一个检测头),可视化如下图:

多模型集成
一种常见的方法是使用YOLOv5进行目标检测,然后使用专门的语义分割模型(如DeepLab、UNet等)来实现语义分割任务。最后,将两个任务的结果进行集成。这种方法的优势在于可以根据每个任务的特点选择最适合的模型结构和损失函数,从而达到更好的性能。

自定义模型
另一种可能的方法是探索自定义深度学习模型,将目标检测和语义分割结合到一个统一的模型中。这可能需要深入了解神经网络架构设计、损失函数的定义以及训练技巧等方面的知识。通过精心设计模型结构和损失函数,可以实现同时进行目标检测和语义分割的功能。
多任务学习
另一个研究方向是利用多任务学习的方法,通过共享网络的特征提取部分,同时训练目标检测和语义分割两个任务。通过这种方式,可以使模型学习到更加丰富和通用的特征表示,从而提高模型的泛化能力和效果。
结合传统方法
除了深度学习模型,还可以考虑结合传统的计算机视觉方法,如基于边缘检测和区域生长的图像分割算法,来实现语义分割任务。将传统方法与深度学习模型相结合,可能会为同时进行目标检测和语义分割任务带来新的思路和方法。
应用场景
通过同时进行目标检测和语义分割,可以为许多实际应用场景带来更多可能性。例如,在自动驾驶领域,可以通过同时检测交通标识和实现道路的语义分割来实现更加智能的驾驶辅助系统。在医学影像分析领域,可以通过同时识别病灶并进行器官的精确分割来帮助医生进行诊断和治疗。
挑战与前景
核心代码
原作者目标检测使用的Coco数据集,语义分割使用的是Cityscapes数据集。
模型主要是在YOLOv5-5.0版本上进行修改的,基准模型采用的是YOLOv5m,语义分割的实现主要是在模型输出的Head部分添加了一个头:
yolov5m_city_seg.yaml
# parameters
nc: 10 # number of classes
n_segcls: 19 # 分割类别数
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4 # PANet是add, yolov5是concat
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
#[类别/输出通道, C3的n, C3的c2, C3的shortcut(以base为例,其他头含义可能不同)] yolo.py解析代码, []内第一项必须是输出通道数
#[[4, 19], 1, SegMaskLab, [n_segcls, 3, 256, False]], # 语义分割头通道配置256,[]内n为3
[[16, 19, 22], 1, SegMaskPSP, [n_segcls, 3, 256, False]], # 语义分割头通道配置256
#[[16, 19, 22], 1, SegMaskBiSe, [n_segcls, 3, 256, False]], # 语义分割头通道配置无效
#[[16], 1, SegMaskBase, [n_segcls, 3, 512, False]], # 语义分割头通道配置512
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) 必须在最后一层, 原代码很多默认了Detect是最后, 并没有全改
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
总结
总的来说,尽管目前YOLOv5并不直接支持同时进行目标检测和语义分割,但通过多模型集成、自定义模型、多任务学习和结合传统方法等途径,可以探索出一些可能的方向。同时,通过同时进行目标检测和语义分割,可以为计算机视觉领域带来更多的可能性和应用场景,为实际问题提供更加全面和深入的解决方案。

