
- 1成为比开发硬气的测试人,我都经历了什么?_大佬说开发和测试吵架
- 2kylin os auditd问题解决_audit-3.0-5.se.08.ky10
- 3HarmonyOS 应用开发之ExtensionAbility组件(2),阿里P7大牛亲自教你
- 4学业水平考试网登录_2019山东高中学业水平考试报名系统入口http://xysp.sdzk.cn
- 5路径规划:基于kinodynamic的路径搜索
- 6如何使用python来进行回归分析_python 回归分析
- 7云计算文献综述
- 8【EduCoder实训答案】二维数组_根据提示,在右侧编辑器 begin-end 区间补充代码,根据定义好的结构体类型,依次输出 6 个结
- 9Spring boot和Flink整合_springboot整合flink
- 10PHICOMM(斐讯)N1盒子 - Armbian5.77(Debian 9)配置自动连接WIFI无线网络_n1 armbian wifi
【分享笔记】符尧:预训练、指令微调、对齐、专业化——论大语言模型能力的来源
赞
踩
分享时间:2023.2
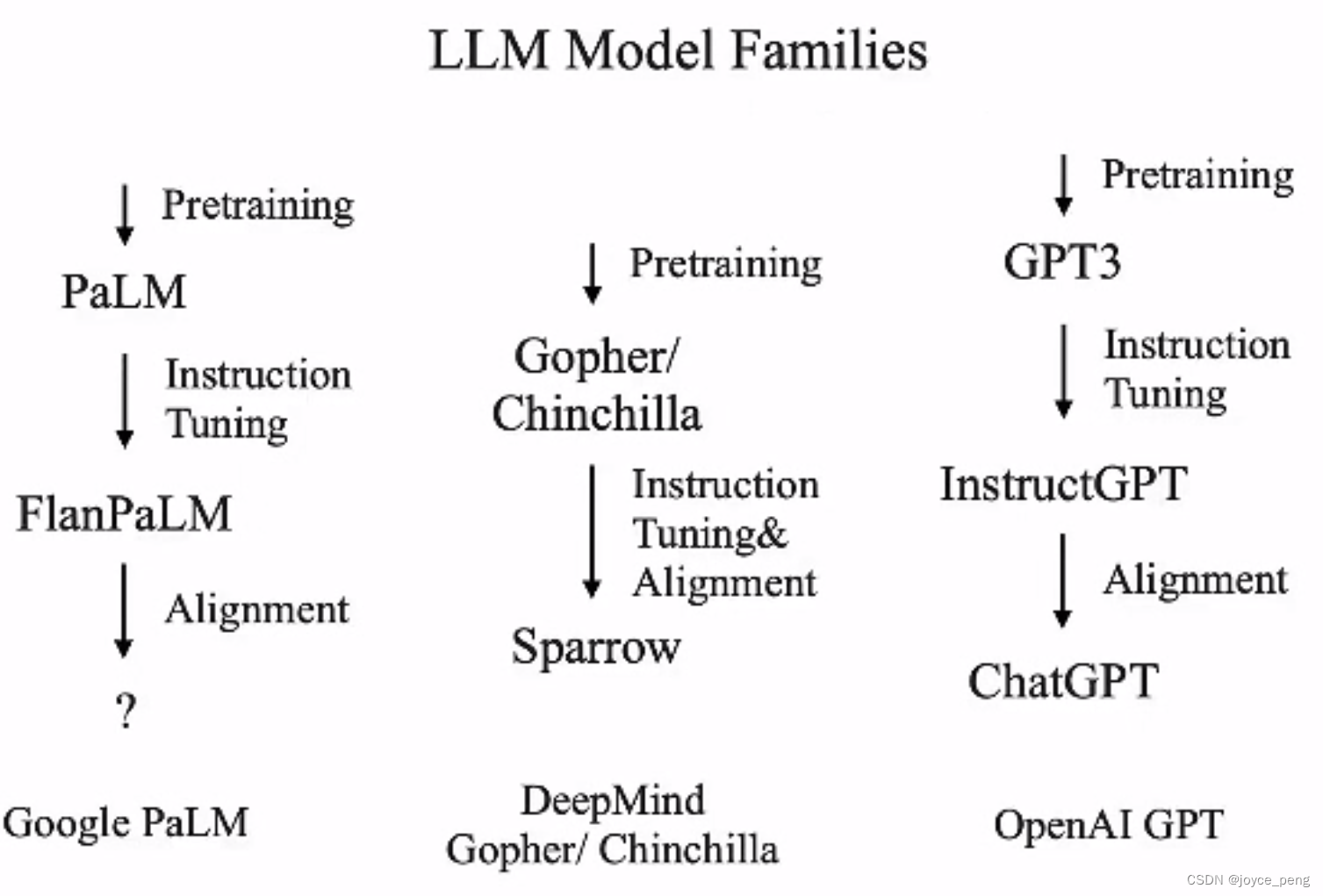
模型家族
看模型要从演化家族来看,而不能单独看,很多人认为一些能力并不是RLHF激发出来的,而是本来的基础模型就有的。
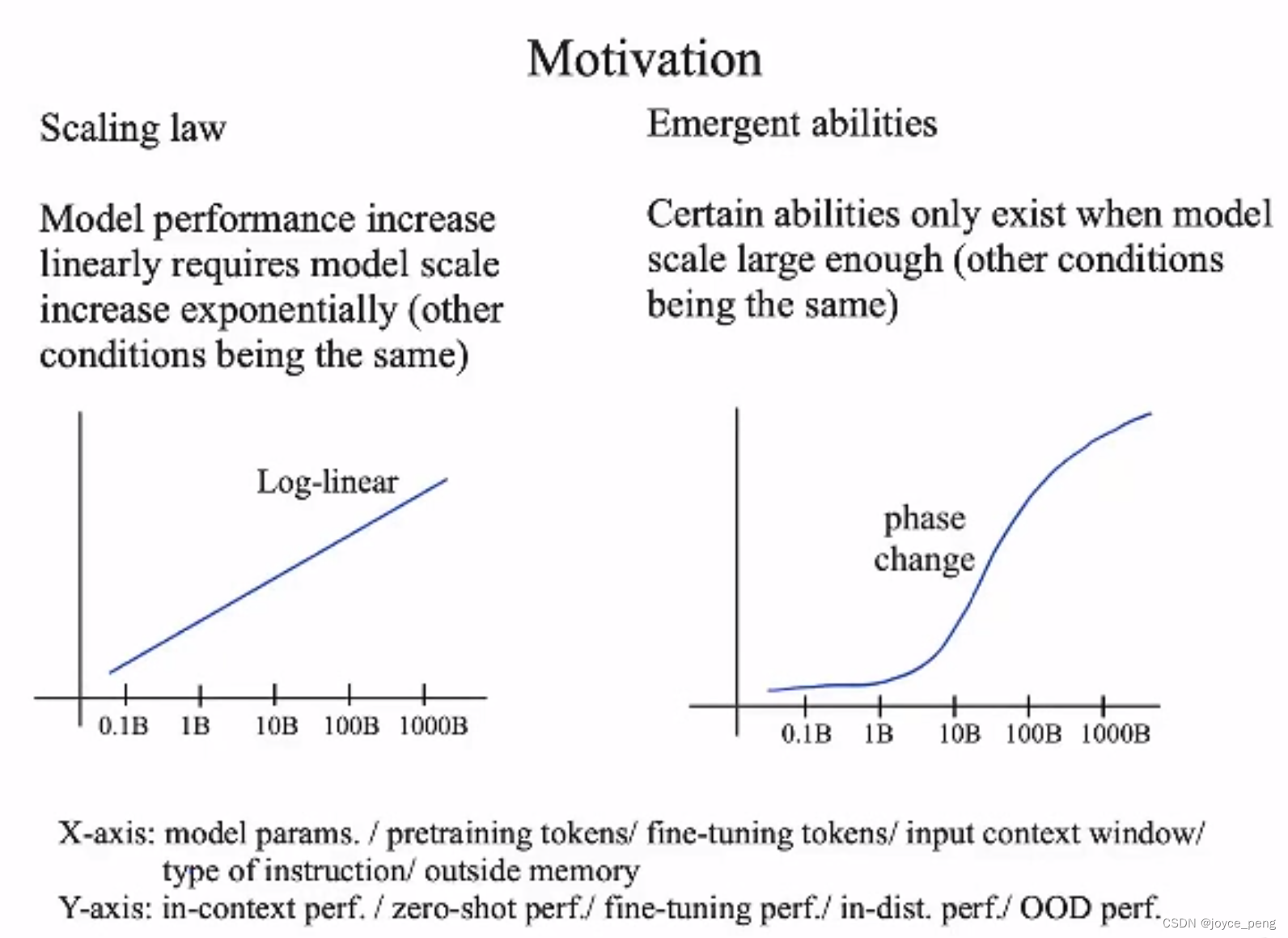
scaling law和涌现能力
scaling law适用于很多方面(这里指语言的scaling law,不确定cv的),比如模型参数、指令类型数、指令下数据量等。如果横坐标是数据量级的话,干净的数据可以增加曲线斜率,但是依然符合scaling law。
涌现能力:当模型大小<10B时,很多能力没有涌现
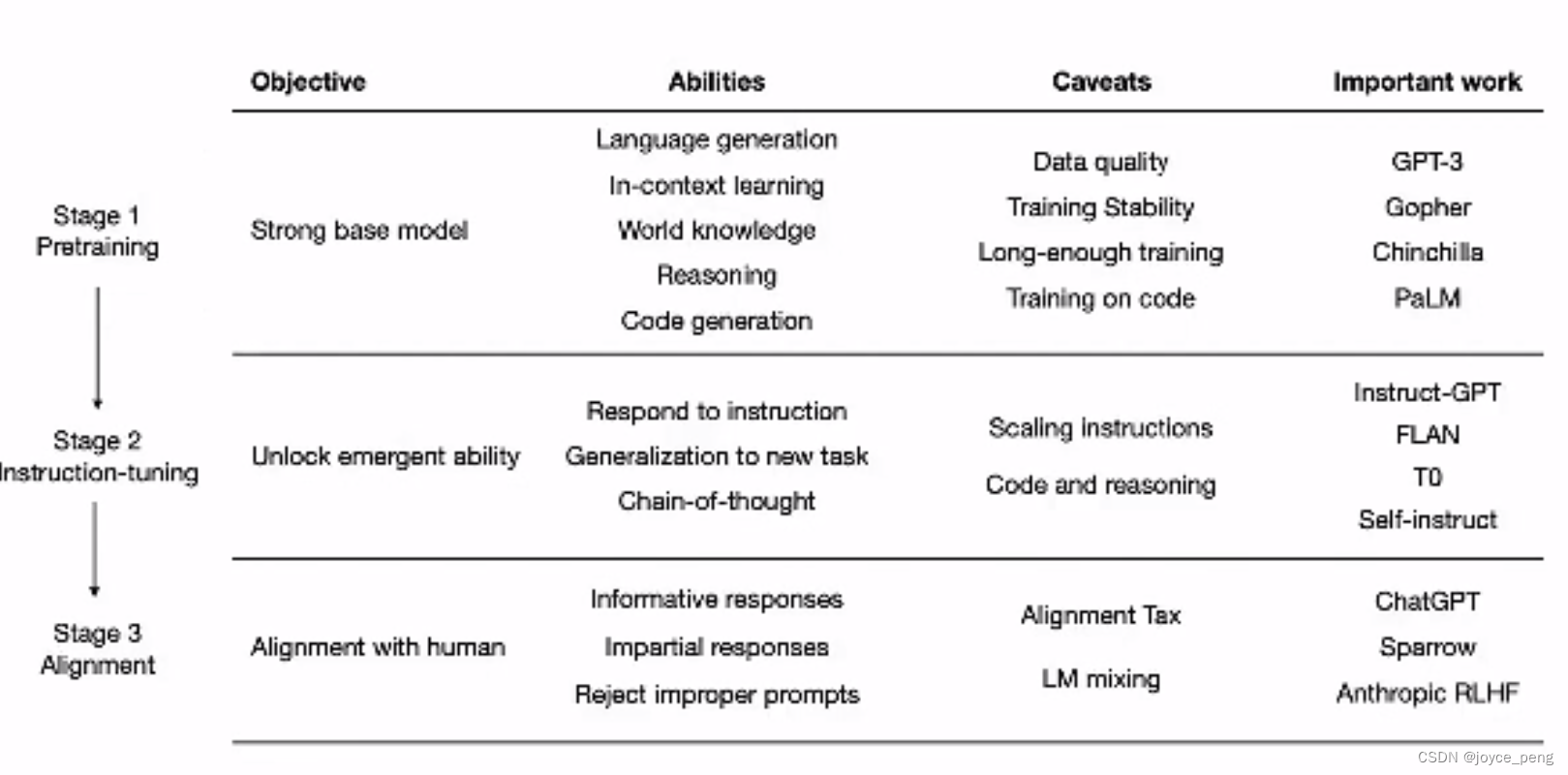
模型不同阶段
分三个阶段,有的能力在预训练之后不能被直接观察到,sft时可以被观察到,如果这个能力在预训练可以直接观察到,sft可以变强。大模型:什么都能做什么都做不好,经过sft的小模型,模型六边形效果更好。sft是激发而不是赋予。
pretraining
衡量大模型效果的各个方面。
wordl knowledge: HELM中提过,知识密集型任务和模型大小息息相关。
in-context learning:当模型大的时候,in-context learning会好很多。
code:训练数据中有这个,就有这个能力。
复杂推理:(仅仅是假设而不是结论)在code上训练可能会提高复杂推理能力

intruction tuning
指令微调:提高指令种类数量,可以提高泛化能力,因为不同的指令其实就是不同的任务,任务更多,泛化能力更强。至于多少指令数量,可以参考scaling law,指令越多,泛化能力越强。
sft效果和基础模型显著相关。
LM-instruct模拟了gpt指令微调前后,核心内容是指令种类要多,而不是单个指令下数据更多,后者也符合scaling law,对于那一项能力会更好,但可能会牺牲其他能力,就涉及到不同能力之间的平衡问题。
compositional generalization:组合泛化能力。代码指令+摘要指令,可以混成一块为对代码做摘要。

alignment
希望模型符合人类期望,模型可能会掉点。比如安全能力。
Anthropic是一个很安全的模型,supervised有两种,可以让人标注,或者模型生成多种不同的答案,人选择最好的。RLHF是代替后者的人类。要先supervised再RLHF。

upper bound和lower bound



