
- 1Spring源码分析-BeanDefinition_spring源码系列之beandefinition
- 2Mac 解决配置 zsh 后,nvm不见的问题
- 3苹果微信分身双开怎么弄?2024最新苹果微信分身下载教程!
- 4AI代码生成助手Cursor、TabNine 、Cosy使用体验_cursor是基于chargbt的吗
- 5四、Hybrid_astar.py文件中Hybrid A * 算法程序的详细介绍
- 6微信小程序电子签名及图片生成_电子签名小程序
- 7腾讯云认证FAQ | 热门考试方向、考试报名流程、模拟试题等_腾讯云运维工程师认证
- 8Sublime text3 Version 3.22下载安装及注册_sublime 322 注册
- 9详解Python对Excel处理_python能处理xls文件吗
- 10《Flink原理、实战与性能优化》(Flink知识梳理一)
C-Pack: Packaged Resources To Advance General Chinese Embedding_c-mteb
赞
踩
简介
论文提出了一个C-pack资源集合,其中包括三个主要的部分:
- C-MTEB一个中文综合基准集合,包括6个任务和35个数据集合。
- C-MTP一个中文embedding数据集合,包括unlabeled和labeled两种数据。
- C-TEM一个embedding模型家族,包括多种尺寸的模型。
- 提出了一套预训练的Recipe方法,通过一次预训练+两次fine-tune取得了良好的模型训练效果。
并且论文中提出的模型在C-MTEB数据集合上取得了优异的效果,有些任务取得了10%+的效果。
并且模型在英文的MTEB集合上也取得了SOTA的效果。
具体工作
之前的embedding预训练模型有以下的问题:
1.既没有准备好的训练资源。
2.也没有很好的benchmarks去验证模型的通用性。
为了解决传统做法的这些问题,论文做了以下的工作。
总体上C-Pack提供了中文embedding的首选解决方案。
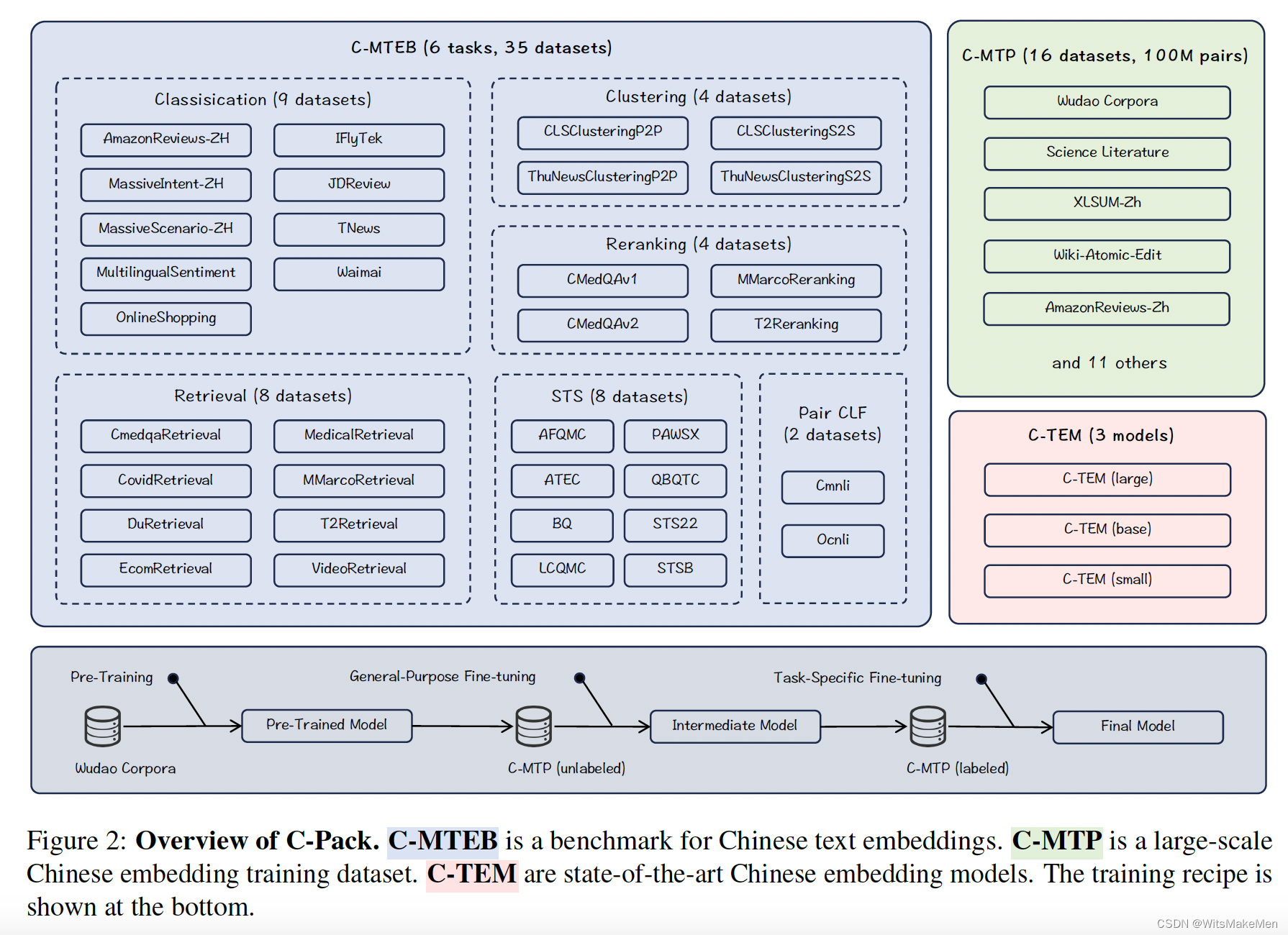
1.C-MTEB中文基准
这个基准是在MTEB基础上进行的扩展,收集了6种任务的35个public数据集。由于集合的规模和多样性,主要的中文embedding能力可以被很好的评估,可以很好的评估embedding模型的通用性。
评估的主要任务有:
1.Retrieval召回
2.Re-ranking重排
3.STS语音文本相似度
4.Classification分类
5.Pair-classification文本对相关度分类
6.Clustering聚类
embedding模型的通用能力用6种任务的平均得分进行评估
2.C-MTP中文文本预料
建立了100M的中文文本预料,包括大量的unlabeled数据和少量高质量的labeled数据。
1.C-MTP (unlabeled)寻找大量的语料,蕴含大量的语义信息。主要数据来源于开源网络语料库。最主要的来源是wudao语料库,对于其中的每一篇文章,我们解析了title和passage正文作为文本对,用同样的方法也整理了很多其他的开源语料。因为开源的语料对不能保证完全的相关性,因此进行了第三方模型判断,过滤掉得分较低的语料对。为语料库带来了非常好的效果提升。
2.C-MTP (labeled)同时收集了84w高质量的预料对,大多数的labeled的语料对,都是通过人工标注的方式进行的。人工标注的语料对同样包含了文本embedding的多种能力,包括召回、排序等。
3.C-TEM中文文本embedding模型
利用上面的语料训练了一些列模型(包括24M,102M,326M三种模型),模型在中文基准上取得了非常好的效果。并且C-TEM可以继续被fine-tune应用到不同的业务场景中。
模型整体是Bert-like的模型结构,最后一层的隐藏状态CLS被训练作为embedding信息。最大的一个模型达到了最高的embedding通用能力。
C-TEM模型可以作为一个embedding基座,进行fine-tune预训练后应用到不同的业务中。
4.Training Recipe训练方法
提出来三步训练方法,
4.1 用plain text进行预训练

4.2 C-MTP (unlabeled)的数据进行对比学习

4.3 C-MTP (labeled)进行多任务学习


