
- 1用php和mysql写动态网页_php+apache+mysql终于实现了第一个动态网页,写一下感受
- 2elasticsearch的底层模块深入解析
- 3python字典_字典元素的读取可以使用字典的健作为下标来访问字典元素的值,若指定的键不存
- 4一条命令安装docker
- 5一文分清Cortex-M系列处理器指令集_arm cortex m0移位指令
- 6VS Code上,QT基于cmake,qmake的构建方法(非常详细)_vscode qt cmake
- 7UE5WebUI启用后无法透过WebUI来触发场景中鼠标左右键的平移旋转视角功能的解决方法_ue5 在鼠标旋转视角的时候不会穿到地形里面
- 8Kafka 之消费者 Consumer 配置_kafka消费者配置类
- 9redis中的zset_redis zset
- 10笔试算法复盘_华为0508笔试 时间轴上有n种周期出现的资源,每种资源有周期和偏移
Hashset和hashmap的区别_hashset和hashmap区别
赞
踩
如果时间紧可以如下理解:
1、HashSet底层是采用HashMap实现的。HashSet 的实现比较简单,HashSet 的绝大部分方法都是通过调用 HashMap 的方法来实现的,因此 HashSet 和 HashMap 两个集合在实现本质上是相同的。
2、HashMap的key就是放进HashSet中对象,value是Object类型的。
3、当调用HashSet的add方法时,实际上是向HashMap中增加了一行(key-value对),该行的key就是向HashSet增加的那个对象,该行的value就是一个Object类型的常量
如果还有时间,详解如下
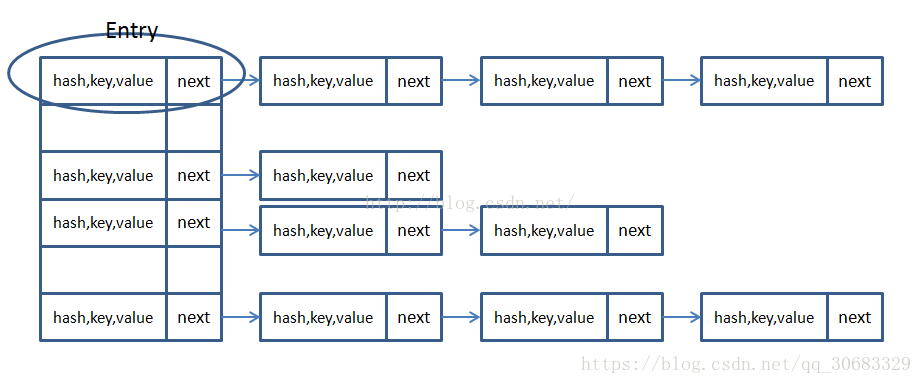
(1)HashSet是set的一个实现类,hashMap是Map的一个实现类,同时hashMap是hashTable的替代品(为什么后面会讲到).
(2)HashSet以对象作为元素,而HashMap以(key-value)的一组对象作为元素,且HashSet拒绝接受重复的对象.HashMap可以看作三个视图:key的Set,value的Collection,Entry的Set。 这里HashSet就是其实就是HashMap的一个视图。
HashSet内部就是使用Hashmap实现的,和Hashmap不同的是它不需要Key和Value两个值。
往hashset中插入对象其实只不过是内部做了
public boolean add(Object o) {
return map.put(o, PRESENT)==null;
}
现在来看hastTable和hashMap的区别:
1. HashMap
1) hashmap的数据结构
Hashmap是一个数组和链表的结合体(在数据结构称“链表散列“),如下图示:

当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
2)使用

- Map map = new HashMap();
- map.put("Rajib Sarma","100");
- map.put("Rajib Sarma","200");//The value "100" is replaced by "200".
- map.put("Sazid Ahmed","200");
-
- Iterator iter = map.entrySet().iterator();
- while (iter.hasNext()) {
- Map.Entry entry = (Map.Entry) iter.next();
- Object key = entry.getKey();
- Object val = entry.getValue();
- }
2. HashTable和HashMap区别
第一,继承不同。
- public class Hashtable extends Dictionary<> implements Map<>
- public class HashMap extends AbstractMap<> implements Map<>
具体可见Java API.
第二
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五
哈希值的使用不同,HashTable直接使用对象的hashCode,如下:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
而HashMap重新计算hash值。
而HashMap重新计算hash值,而且用与代替求模:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
第六
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
其它的一些资料:
1.HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。
2.HashTable使用Enumeration,HashMap使用Iterator。
以上只是一些比较突出的区别,当然他们的实现上还是有很多不同的,比如
下面都代表了Java中的集合,这里主要从其元素是否有序,是否可重复来进行区别记忆,以便恰当地使用,当然还存在同步方面的差异,见上一篇相关文章。
|
| 有序否 | 允许元素重复否 | |
| Collection | 否 | 是 | |
| List | 是 | 是 | |
| Set | AbstractSet | 否 | 否 |
| HashSet | |||
| TreeSet | 是(用二叉树排序) | ||
| Map | AbstractMap | 否 | 使用key-value来映射和存储数据,Key必须惟一,value可以重复 |
| HashMap | |||
| TreeMap | 是(用二叉树排序) | ||
List 接口对Collection进行了简单的扩充,它的具体实现类常用的有ArrayList和LinkedList。你可以将任何东西放到一个List容器中,并在需要时从中取出。ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快,而LinkedList的内部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而 ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
Set接口也是 Collection的一种扩展,而与List不同的时,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和 Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一个数组进行类似的操作。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现: HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub (Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。


