
- 1firewalld_firewallapi.dll
- 2【算法】辗转相除法求最大公约数
- 3初级数据结构(五)——树和二叉树的概念
- 4NLP传统基础(1)---BM25算法---计算文档和query相关性
- 5android自定义dialog对话框,android的自定义dialog对话框实现
- 6leetcode-二叉树_leetcode二叉树
- 7使用 JMX-Exporter 监控 Kafka 和 Zookeeper_jmx exporter 不需要jvm指标
- 8使用wireshark抓包分析ICMP拼通与不通,IP包分片与不分片,ARP中含对象mac地址与不含时的各层状态_wireshark中icmp怎么判断报文是否分段
- 9newifi安装php,新路由(newifi)登录地址安装设置步骤
- 10Direct3D 12——混合——混合_rendertargetwritemask
第一章:JAVA Spark的学习和开发【由浅入深,2024年最新含面试题+答案_java spark 教程
赞
踩
一、安装包和环境准备
spark安装包:spark-3.3.1-bin-hadoop3.tgz
hadoop安装包:hadoop-3.3.0.tar.gz
hadoop相关安装包:winutils-master.zip
jdk1.8安装包:jdk-8u401-windows-x64.exe
maven安装包:apache-maven-3.9.6-bin.zip
我的电脑用的是win11,最好是win10以上的环境去用,win7和win8没有测试过。
二、安装步骤
1.安装及环境变量配置
下载完成的spark、hadoop和winutils包解压缩,并统一放到磁盘的某个目录下
我的安装目录为:D:\bigdata
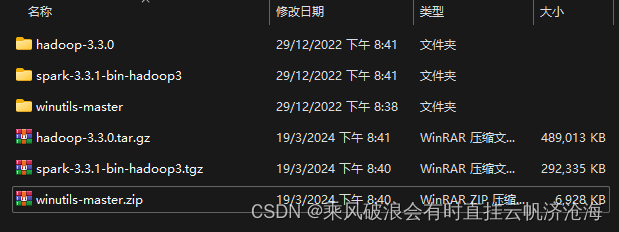
注意! winutils-master包解压完成后进入目录
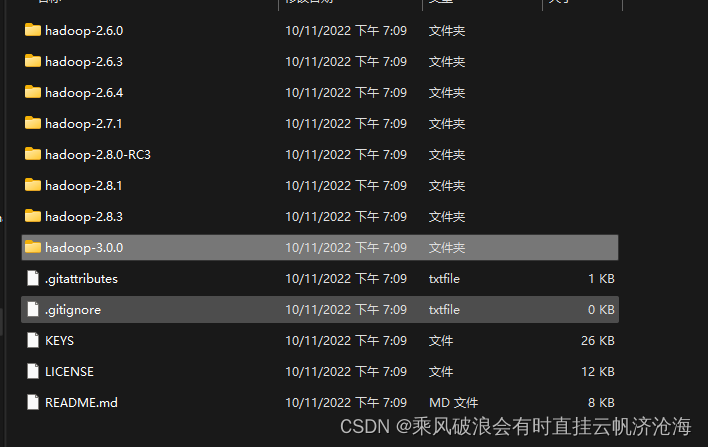
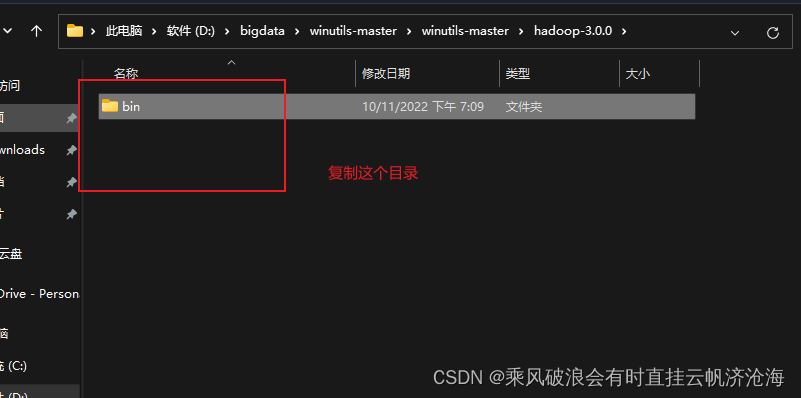
然后进入hadoop-3.0.0,把目录下的bin目录及文件复制替换到hadoop-3.3.0的bin目录中
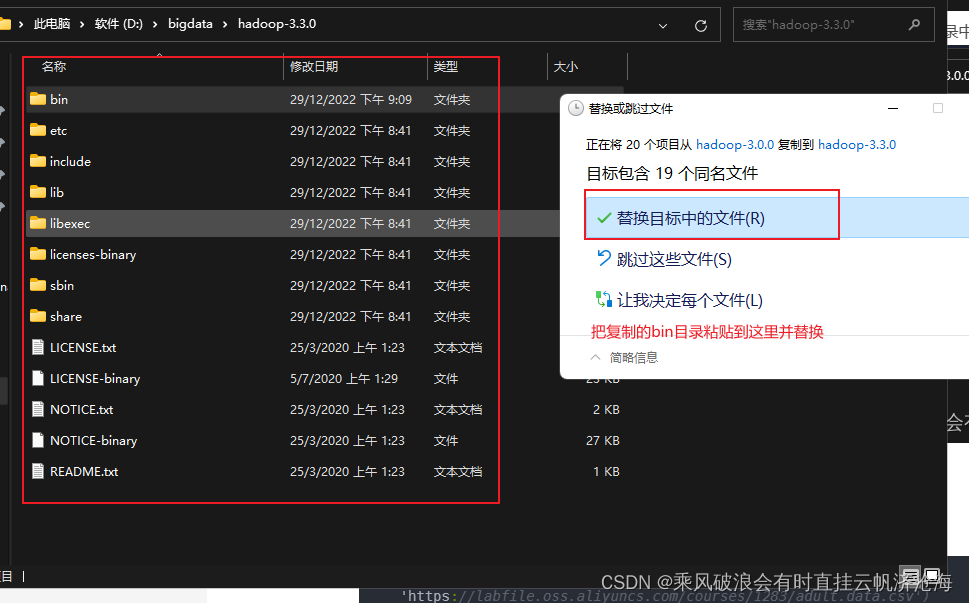
以上步骤操作完成后,开始设置系统环境变量。
新建:HADOOP_HOME D:\bigdata\hadoop-3.3.0(此路径为我的安装路径)
新建:SPARK_HOME D:\bigdata\spark-3.3.1-bin-hadoop3(此路径为我的安装路径)
PATH变量新增:
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
2.编写java spark代码
代码如下(示例):
public static void main(String[] args) {
getSparkCreate();
}
public static SparkSession getSparkCreate(){
SparkSession sparkSession = SparkSession.builder().appName(“sxw”)
.master(“local[*]”) //单机版用local参数*为使用可用线程执行
.getOrCreate();
List ls = new ArrayList<>();
user kk = new user();
kk.setName(“小明”);
kk.setAge(19);
ls.add(kk);
Dataset dataset = sparkSession.createDataFrame(ls,user.class);
dataset.show();
dataset.printSchema();
return sparkSession;
}
user实体类
@Data
public class user implements Serializable {
private String name;
private Integer age;
}
pom依赖
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-PHcD9Bbz-1712587702112)]

