
- 1计算机图形学入门02:线性代数基础
- 2posgresql远程连接及用户授权_psql 远程连接
- 3Unity UGUI 效果 之 多页翻页,多页任意翻页的简单效果实现(示例演示为动态加载多图片实现翻页预览效果)_unity 图片多次翻书展开动画
- 4朱啸虎:AI应用明年肯定大爆发;第3款爆火AI游戏出现了;AI应用定价策略「不能说的秘密」;人类数据不够用了怎么办 | ShowMeAI日报
- 5php问答系统模板,tipask问答系统模板资料对照
- 6Python函数式编程进阶:用函数实现设计模式
- 7Lombok工具 : 常用注解介绍 (全)_lombok注解
- 8Java的线程安全
- 9自己买的U盘,Mac不识别,如何解决?_windows u盘格式化后mac识别不了
- 10多模态大模型入门指南_多模大模型
自然语言处理学习笔记2:分词工具及分词原理
赞
踩
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
作用:
中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。
中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法。
影响:
中文分词对于搜索引擎来说,最重要的并不是找到所有结果,因为在上百亿的网页中找到所有结果没有太多的意义,没有人能看得完,最重要的是把最相关的结果排在最前面,这也称为相关度排序。中文分词的准确与否,常常直接影响到对搜索结果的相关度排序。从定性分析来说,搜索引擎的分词算法不同,词库的不同都会影响页面的返回结果
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;常用的几种机械分词方法如下:
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小);
4)双向最大匹配法(进行由左到右、由右到左两次扫描)
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。
一种方法是改进扫描方式,称为特征扫描或标志切分,优先在待分析字符串中识别和切分出一些带有明显特征的词,以这些词作为断点,可将原字符串分为较小的串再来进机械分词,从而减少匹配的错误率。
另一种方法是将分词和词类标注结合起来,利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
对于机械分词方法,可以建立一个一般的模型,在这方面有专业的学术论文,这里不做详细论述。
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
它通常包括三个部分:分词子系统、句法语义子系统、总控部分。
在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。
因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。
但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用字组,例如“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
另外一类是 基于统计机器学习的方法。首先给出大量已经分词的文本,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。我们知道,汉语中各个字单独作词语的能力是不同的,此外有的字常常作为前缀出现,有的字却常常作为后缀(“者”“性”),结合两个字相临时是否成词的信息,这样就得到了许多与分词有关的知识。这种方法就是充分利用汉语组词的规律来分词代码的输出结果为:
- 中国人民银行:中国 人民 银行
- 中华人民共和国今天成立了:中华人民共和国 今天 成立 了
- 努力提高居民收入:努力 提高 居民 收入
到底哪种分词算法的准确度更高,目前并无定论。对于任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需要综合不同的算法。例如,海量科技的分词算法就采用“复方分词法”,所谓复方,就是像中西医结合般综合运用机械方法和知识方法。对于成熟的中文分词系统,需要多种算法综合处理问题。
2.中文分词工具介绍
2.1 jieba
jieba分词是国内使用人数最多的中文分词工具(github链接:https://github.com/fxsjy/jieba)。jieba分词支持三种模式:
(1)精确模式:试图将句子最精确地切开,适合文本分析;
(2)全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba分词过程中主要涉及如下几种算法:
(1)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
(2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3)对于未登录词,采用了基于汉字成词能力的 HMM 模型,采用Viterbi 算法进行计算;
(4)基于Viterbi算法做词性标注;
(5)基于tf-idf和textrank模型抽取关键词;
测试代码如下所示:
- # -*- coding: utf-8 -*-
- """
- jieba分词测试
- """
-
- import jieba
-
-
- #全模式
- test1 = jieba.cut("杭州西湖风景很好,是旅游胜地!", cut_all=True)
- print("全模式: " + "| ".join(test1))
-
- #精确模式
- test2 = jieba.cut("杭州西湖风景很好,是旅游胜地!", cut_all=False)
- print("精确模式: " + "| ".join(test2))
-
- #搜索引擎模式
- test3= jieba.cut_for_search("杭州西湖风景很好,是旅游胜地,每年吸引大量前来游玩的游客!")
- print("搜索引擎模式:" + "| ".join(test3))

- 测试结果如下图所示:

2.2 SnowNLP
SnowNLP是一个python写的类库(https://github.com/isnowfy/snownlp),可以方便的处理中文文本内容,是受到了TextBlob的启发而写的。SnowNLP主要包括如下几个功能:
(1)中文分词(Character-Based Generative Model);
(2)词性标注(3-gram HMM);
(3)情感分析(简单分析,如评价信息);
(4)文本分类(Naive Bayes)
(5)转换成拼音(Trie树实现的最大匹配)
(6)繁简转换(Trie树实现的最大匹配)
(7)文本关键词和文本摘要提取(TextRank算法)
(8)计算文档词频(TF,Term Frequency)和逆向文档频率(IDF,Inverse Document Frequency)
(9)Tokenization(分割成句子)
(10)文本相似度计算(BM25)
SnowNLP的最大特点是特别容易上手,用其处理中文文本时能够得到不少有意思的结果,但不少功能比较简单,还有待进一步完善。
测试代码如下所示:
- # -*- coding: utf-8 -*-
- """
- SnowNLP测试
- """
-
- from snownlp import SnowNLP
-
- s = SnowNLP(u'杭州西湖风景很好,是旅游胜地,每年吸引大量前来游玩的游客!')
-
- #分词
- print(s.words)
-
-
- #情感词性计算
- print("该文本的情感词性为正的概率:" + str(s.sentiments))
-
- text = u'''
- 西湖,位于浙江省杭州市西面,是中国大陆首批国家重点风景名胜区和中国十大风景名胜之一。
- 它是中国大陆主要的观赏性淡水湖泊之一,也是现今《世界遗产名录》中少数几个和中国唯一一个湖泊类文化遗产。
- 西湖三面环山,面积约6.39平方千米,东西宽约2.8千米,南北长约3.2千米,绕湖一周近15千米。
- 湖中被孤山、白堤、苏堤、杨公堤分隔,按面积大小分别为外西湖、西里湖、北里湖、小南湖及岳湖等五片水面,
- 苏堤、白堤越过湖面,小瀛洲、湖心亭、阮公墩三个小岛鼎立于外西湖湖心,夕照山的雷峰塔与宝石山的保俶塔隔湖相映,
- 由此形成了“一山、二塔、三岛、三堤、五湖”的基本格局。
- '''
-
- s2 = SnowNLP(text)
-
- #文本关键词提取
- print(s2.keywords(10))
测试结果如下图所示:

2.3 THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包(github链接:https://github.com/thunlp/THULAC-Python),具有中文分词和词性标注功能。THULAC具有如下几个特点:
(1)能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
(2)准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
(3)速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
THU词性标记集(通用版)如下所示:
- n/名词 np/人名 ns/地名 ni/机构名 nz/其它专名
- m/数词 q/量词 mq/数量词 t/时间词 f/方位词 s/处所词
- v/动词 a/形容词 d/副词 h/前接成分 k/后接成分 i/习语
- j/简称 r/代词 c/连词 p/介词 u/助词 y/语气助词
- e/叹词 o/拟声词 g/语素 w/标点 x/其它
测试代码(python版)如下所示:
- # -*- coding: utf-8 -*-
- """
- THULAC 分词测试
- """
-
- import thulac
-
- #默认模式,分词的同时进行词性标注
- test1 = thulac.thulac()
- text1 = test1.cut("杭州西湖风景很好,是旅游胜地!")
- print(text1)
-
-
- #只进行分词
- test2 = thulac.thulac(seg_only=True)
- text2 = test2.cut("杭州西湖风景很好,是旅游胜地!")
- print(text2)
测试结果如下图所示:

2.4 NLPIR
NLPIR分词系统(前身为2000年发布的ICTCLAS词法分析系统,gtihub链接:https://github.com/NLPIR-team/NLPIR),是由北京理工大学张华平博士研发的中文分词系统,经过十余年的不断完善,拥有丰富的功能和强大的性能。NLPIR是一整套对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。主要功能包括:中文分词,词性标注,命名实体识别,用户词典、新词发现与关键词提取等功能。本文测试所采用的是PyNLPIR(NLPIR的Python版本,github链接:https://github.com/tsroten/pynlpir)
测试代码如下所示:
- # -*- coding: utf-8 -*-
- """
- PYNLPIR 分词测试
- """
-
- import pynlpir
-
-
- #打开分词器
- pynlpir.open()
-
- text1 = "杭州西湖风景很好,是旅游胜地,每年吸引大量前来游玩的游客!"
-
- #分词,默认打开分词和词性标注功能
- test1 = pynlpir.segment(text1)
- #print(test1)
- print('1.默认分词模式:\n' + str(test1))
-
- #将词性标注语言变更为汉语
- test2 = pynlpir.segment(text1,pos_english=False)
- print('2.汉语标注模式:\n' + str(test2))
-
-
- #关闭词性标注
- test3 = pynlpir.segment(text1,pos_tagging=False)
- print('3.无词性标注模式:\n' + str(test3))
测试结果如下图所示:

三大主流分词方法:基于词典的方法、基于规则的方法和基于统计的方法。
1、基于规则或词典的方法
定义:按照一定策略将待分析的汉字串与一个“大机器词典”中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
- 按照扫描方向的不同:正向匹配和逆向匹配
- 按照长度的不同:最大匹配和最小匹配
1.1正向最大匹配思想MM
- 从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。
- 查找大机器词典并进行匹配:
- 若匹配成功,则将这个匹配字段作为一个词切分出来。
- 若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
举个栗子:
现在,我们要对“南京市长江大桥”这个句子进行分词,根据正向最大匹配的原则:
- 先从句子中拿出前5个字符“南京市长江”,把这5个字符到词典中匹配,发现没有这个词,那就缩短取字个数,取前四个“南京市长”,发现词库有这个词,就把该词切下来;
- 对剩余三个字“江大桥”再次进行正向最大匹配,会切成“江”、“大桥”;
- 整个句子切分完成为:南京市长、江、大桥;
1.2逆向最大匹配算法RMM
该算法是正向最大匹配的逆向思维,匹配不成功,将匹配字段的最前一个字去掉,实验表明,逆向最大匹配算法要优于正向最大匹配算法。
还是那个栗子:
- 取出“南京市长江大桥”的后四个字“长江大桥”,发现词典中有匹配,切割下来;
- 对剩余的“南京市”进行分词,整体结果为:南京市、长江大桥
1.3 双向最大匹配法(Bi-directction Matching method,BM)
双向最大匹配法是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。
据SunM.S. 和 Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,或者正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因所在。
还是那个栗子:
双向的最大匹配,即把所有可能的最大词都分出来,上面的句子可以分为:南京市、南京市长、长江大桥、江、大桥
1.4设立切分标志法
收集切分标志,在自动分词前处理切分标志,再用MM、RMM进行细加工。
1.5最佳匹配(OM,分正向和逆向)
对分词词典按词频大小顺序排列,并注明长度,降低时间复杂度。
优点:易于实现
缺点:匹配速度慢。对于未登录词的补充较难实现。缺乏自学习。
1.6逐词遍历法
这种方法是将词库中的词由长到短递减的顺序,逐个在待处理的材料中搜索,直到切分出所有的词为止。
处理以上基本的机械分词方法外,还有双向扫描法、二次扫描法、基于词频统计的分词方法、联想—回溯法等。
2、基于统计的分词
随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法。
主要思想:把每个词看做是由词的最小单位各个字总成的,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。因此我们就可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
主要统计模型:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
优势:在实际的应用中经常是将分词词典串匹配分词和统计分词能较好地识别新词两者结合起来使用,这样既体现了匹配分词切分不仅速度快,而且效率高的特点;同时又能充分地利用统计分词在结合上下文识别生词、自动消除歧义方面的优点。
2.1 N-gram模型思想
模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
我们给定一个词,然后猜测下一个词是什么。当我说“艳照门”这个词时,你想到下一个词是什么呢?我想大家很有可能会想到“陈冠希”,基本上不会有人会想到“陈志杰”吧,N-gram模型的主要思想就是这样的。
对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么
P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
但是这种方法存在两个致命的缺陷:一个缺陷是参数空间过大,不可能实用化;另外一个缺陷是数据稀疏严重。为了解决这个问题,我们引入了马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即P(T) =P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。一般的小公司,用到二元的模型就够了,像Google这种巨头,也只是用到了大约四元的程度,它对计算能力和空间的需求都太大了。
以此类推,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。
2.2 HMM、CRF 模型思想
以往的分词方法,无论是基于规则的还是基于统计的,一般都依赖于一个事先编制的词表(词典),自动分词过程就是通过词表和相关信息来做出词语切分的决策。与此相反,
基于字标注(或者叫基于序列标注)的分词方法实际上是构词方法,即把分词过程视为字在字串中的标注问题。
由于每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),假如规定每个字最多只有四个构词位置:即B(词首),M (词中),E(词尾)和S(单独成词),那么下面句子(甲)的分词结果就可以直接表示成如(乙)所示的逐字标注形式:
- (甲)分词结果:/上海/计划/N/本/世纪/末/实现/人均/国内/生产/总值/五千美元/
- (乙)字标注形式:上/B海/E计/B划/E N/S 本/s世/B 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E生/B产/E总/B值/E 五/B千/M 美/M 元/E 。/S
首先需要说明,这里说到的“字”不只限于汉字。考虑到中文真实文本中不可避免地会包含一定数量的非汉字字符,本文所说的“字”,也包括外文字母、阿拉伯数字和标点符号等字符。所有这些字符都是构词的基本单元。当然,汉字依然是这个单元集合中数量最多的一类字符。
把分词过程视为字的标注问题的一个重要优势在于,它能够平衡地看待词表词和未登录词的识别问题。
在这种分词技术中,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习架构上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词(如人名、地名、机构名)识别模块。这使得分词系统的设计大大简化。在字标注过程中,所有的字根据预定义的特征进行词位特性的学习,获得一个概率模型。然后,在待分字串上,根据字与字之间的结合紧密程度,得到一个词位的标注结果。最后,根据词位定义直接获得最终的分词结果。总而言之,在这样一个分词过程中,分词成为字重组的简单过程。在学习构架上,由于可以不必特意强调词表词的信息,也不必专门设计针对未登录词的特定模块,这样使分词系统的设计变得尤为简单。
2001年Lafferty在最大熵模型(MEM)和隐马尔科夫模型(HMM)的基础上提出来了一种无向图模型–条件随机场(CRF)模型,它能在给定需要标记的观察序列的条件下,最大程度提高标记序列的联合概率。常用于切分和标注序列化数据的统计模型。CRF算法理论见我的其他博客,此处就不赘述了。
2.3 基于统计分词方法的实现
现在,我们已经从全概率公式引入了语言模型,那么真正用起来如何用呢?
我们有了统计语言模型,下一步要做的就是划分句子求出概率最高的分词,也就是对句子进行划分,最原始直接的方式,就是对句子的所有可能的分词方式进行遍历然后求出概率最高的分词组合。但是这种穷举法显而易见非常耗费性能,所以我们要想办法用别的方式达到目的。
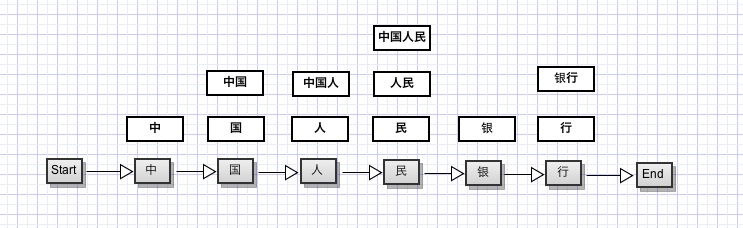
仔细思考一下,假如我们把每一个字当做一个节点,每两个字之间的连线看做边的话,对于句子“中国人民万岁”,我们可以构造一个如下的分词结构: 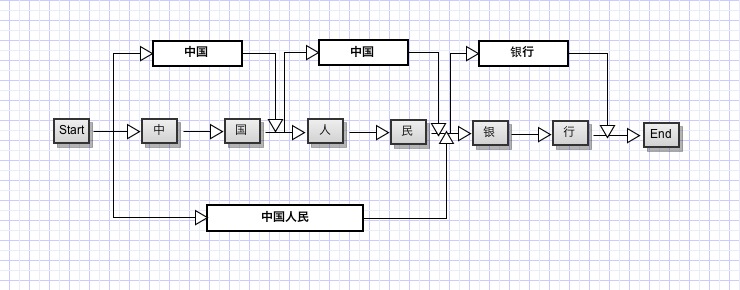
我们要找概率最大的分词结构的话,可以看做是一个动态规划问题, 也就是说,要找整个句子的最大概率结构,对于其子串也应该是最大概率的。
对于句子任意一个位置上的字,我们要从词典中找到其所有可能的词组形式,如上图中的第一个字,可能有:中、中国、中国人三种组合,第四个字可能只有民,经过整理,我们的分词结构可以转换成以下的有向图模型:
我们要做的就是找到一个概率最大的路径即可。我们假设表示第个字的位置可能的词是k,那么可以写出状态转移方程: 
其中k是当前位置的可能单词,l是上一个位置的可能单词,M是l可能的取值,有了状态转移返程,写出递归的动态规划代码就很容易了(这个方程其实就是著名的viterbi算法,通常在隐马尔科夫模型中应用较多)。
- #!/usr/bin/python
- # coding:utf-8
- """
- viterbi
- """
- from lm import LanguageModel
- class Node(object):
- """有向图中的节点"""
- def __init__(self,word):
- # 当前节点作为左右路径中的节点时的得分
- self.max_score = 0.0
- # 前一个最优节点
- self.prev_node = None
- # 当前节点所代表的词
- self.word = word
- class Graph(object):
- """有向图"""
- def __init__(self):
- # 有向图中的序列是一组hash集合
- self.sequence = []
- class DPSplit(object):
- """动态规划分词"""
- def __init__(self):
- self.lm = LanguageModel('RenMinData.txt')
- self.dict = {}
- self.words = []
- self.max_len_word = 0
- self.load_dict('dict.txt')
- self.graph = None
- self.viterbi_cache = {}
- def get_key(self, t, k):
- return '_'.join([str(t),str(k)])
- def load_dict(self,file):
- with open(file, 'r') as f:
- for line in f:
- word_list = [w.encode('utf-8') for w in list(line.strip().decode('utf-8'))]
- if len(word_list) > 0:
- self.dict[''.join(word_list)] = 1
- if len(word_list) > self.max_len_word:
- self.max_len_word = len(word_list)
- def createGraph(self):
- """根据输入的句子创建有向图"""
- self.graph = Graph()
- for i in range(len(self.words)):
- self.graph.sequence.append({})
- word_length = len(self.words)
- # 为每一个字所在的位置创建一个可能词集合
- for i in range(word_length):
- for j in range(self.max_len_word):
- if i+j+1 > len(self.words):
- break
- word = ''.join(self.words[i:i+j+1])
- if word in self.dict:
- node = Node(word)
- # 按照该词的结尾字为其分配位置
- self.graph.sequence[i+j][word] = node
- # 增加一个结束空节点,方便计算
- end = Node('#')
- self.graph.sequence.append({'#':end})
- # for s in self.graph.sequence:
- # for i in s.values():
- # print i.word,
- # print ' - '
- # exit(-1)
- def split(self, sentence):
- self.words = [w.encode('utf-8') for w in list(sentence.decode('utf-8'))]
- self.createGraph()
- # 根据viterbi动态规划算法计算图中的所有节点最大分数
- self.viterbi(len(self.words), '#')
- # 输出分支最大的节点
- end = self.graph.sequence[-1]['#']
- node = end.prev_node
- result = []
- while node:
- result.insert(0,node.word)
- node = node.prev_node
- print ''.join(self.words)
- print ' '.join(result)
- def viterbi(self, t, k):
- """第t个位置,是单词k的最优路径概率"""
- if self.get_key(t,k) in self.viterbi_cache:
- return self.viterbi_cache[self.get_key(t,k)]
- node = self.graph.sequence[t][k]
- # t = 0 的情况,即句子第一个字
- if t == 0:
- node.max_score = self.lm.get_init_prop(k)
- self.viterbi_cache[self.get_key(t,k)] = node.max_score
- return node.max_score
- prev_t = t - len(k.decode('utf-8'))
- # 当前一个节点的位置已经超出句首,则无需再计算概率
- if prev_t == -1:
- return 1.0
- # 获得前一个状态所有可能的汉字
- pre_words = self.graph.sequence[prev_t].keys()
- for l in pre_words:
- # 从l到k的状态转移概率
- state_transfer = self.lm.get_trans_prop(k, l)
- # 当前状态的得分为上一个最优路径的概率乘以当前的状态转移概率
- score = self.viterbi(prev_t, l) * state_transfer
- prev_node = self.graph.sequence[prev_t][l]
- cur_score = score + prev_node.max_score
- if cur_score > node.max_score:
- node.max_score = cur_score
- # 把当前节点的上一最优节点保存起来,用来回溯输出
- node.prev_node = self.graph.sequence[prev_t][l]
- self.viterbi_cache[self.get_key(t,k)] = node.max_score
- return node.max_score
- def main():
- dp = DPSplit()
- dp.split('中国人民银行')
- dp.split('中华人民共和国今天成立了')
- dp.split('努力提高居民收入')
- if __name__ == '__main__':
- main()
需要特别注意的几点是:
1. 做递归计算式务必使用缓存,把子问题的解先暂存起来,参考动态规划入门实践。
2. 当前位置的前一位置应当使用当前位置单词的长度获得。
3. 以上代码只是作为实验用,原理没有问题,但性能较差,生产情况需要建立索引以提高性能。
4. 本分词代码忽略了英文单词、未登录词和标点符号,但改进并不复杂,读者可自行斟酌。
代码的输出结果为:
- 中国人民银行:中国 人民 银行
- 中华人民共和国今天成立了:中华人民共和国 今天 成立 了
- 努力提高居民收入:努力 提高 居民 收入

