
- 1MySQL详解 --- 表的基本操作_mysql怎么表示前一个表
- 2MySQL索引详解_mysql数据库索引
- 3RabbitMq延迟交换机延迟消息插件_invalid argument, 'x-delayed-type' must be an exis
- 4Python知识点14---被规定的资源_在python类的内部,使用def关键字可以定义属于类的方法,这种方法需要使用{ }
- 5大数据系列教程002-初识hadoop_现要求统计2017年全国使用qq聊天最多的10个人? 如何使用hadoop技术进行统计?请结
- 6文字识别tesseract--ORC(py版)_python 文字识别
- 7C++发起https请求_c++网络请求
- 8Oracle checkpoint详解_oracle 发生checkpoint
- 9黑马Redis视频教程实战篇(三)_黑马redis加锁
- 10定时任务特辑 | Quartz、xxl-job、elastic-job、Cron四个定时任务框架对比,和Spring Boot集成实战_elastic-job xxl-jon
BEV-IO:Instance Occupancy引领新纪元,解放BEV下的3D检测!
赞
踩
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到Wrysunny来分享BEV感知的最新进展BEV-IO,Wrysunny也是我们的签约作者,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【BEV感知】技术交流群
自动驾驶之心原创 · 作者 | Wrysunny
编辑 | 自动驾驶之心
BEV-IO:Instance Occupancy引领新纪元,解放BEV下的3D检测

标题:BEV-IO: Enhancing Bird’s-Eye-View 3D Detection with Instance Occupancy
Paper: https://arxiv.org/pdf/2305.16829.pdf
导读
本文提出了一种名为BEV-IO的新的3D检测方法,旨在增强鸟瞰视角(BEV)表示,并提供更全面的3D场景结构信息。传统的BEV表示方法将2D图像特征映射到视锥体空间上,是基于显式预测的深度分布。但是,深度分布只能表征可见物体表面的3D几何信息,无法捕捉它们的内部空间和整体几何结构,导致生成的3D表示稀疏且不令人满意。为了解决这个问题,BEV-IO引入了一种新的3D检测方法,通过实例占据信息增强BEV表示。该方法的核心是新设计的实例占据预测(IOP)模块,旨在推断每个实例在视锥体空间中的点级占据状态。为了保证训练效率并保持表达灵活性,该模块使用显式和隐式监督的组合进行训练。通过预测的占据信息,作者进一步设计了一种几何感知的特征传播机制(GFP),它根据视锥体中每条射线上的占据分布进行自注意力操作,以确保实例级特征的一致性。通过将IOP模块与GFP机制相结合,BEV-IO检测器能够生成具有更全面的BEV表示的高信息量的3D场景结构。实验结果表明,BEV-IO能够在性能上优于最先进的方法,同时只增加了可忽略的参数(0.2%)和计算开销(GFLOPs增加了0.24%)。
研究动机
BEV方法在3D检测中广泛应用,相比于基于激光雷达(LiDAR )的方法,基于摄像头的方法具有更高的成本效益,并在自动驾驶和机器人等实际应用中显示出强大的潜力。基于摄像头的方法主要分为两个流派,其区别在于它们是否显式估计场景的深度分布。
隐式方法通过使用BEV查询和注意机制,以隐式地从多视角图像中生成BEV特征,避免了估计深度分布。不过,缺乏深度信息使得隐式方法容易过拟合于边界情况。
显式方法通过首先根据估计的深度将2D图像特征映射到视锥体空间,然后将特征投射到BEV空间中,从而实现BEV表示。这种方法明确地利用深度信息生成BEV表示,能更可靠地进行3D检测。
总的来说,基于摄像头的方法在成本效益方面相对更具优势,在许多实际应用中显示出了潜在的优势。但是,隐式方法存在过拟合的风险,而显式方法能够更可靠地获得准确的BEV表示,我们需要在选择方法时进行不同优缺点的权衡,根据具体应用需求来决定使用哪种方法。
关于BEV特征构建的显式方法主要涉及两个关键方面:将2D特征映射到BEV空间的方式以及要映射哪些特征。前者关键在于3D几何感知。之前的LSS方法提出了2D-BEV映射过程,并通过BEV包围框的真实值隐式学习深度。LSS缺乏深度的真实值,主要关注目标区域的深度,在整个场景的深度性能较差。一些研究尝试利用稀疏的深度真实值来监督深度估计,这显著提高了深度估计的准确性。
然而,这些方法仍然面临两个主要问题。
首先,深度信息只能表征可见物体表面,无法捕捉到其内部空间或整体几何结构,导致BEV空间中的3D表示稀疏。
其次,很多实例相对较小且距离较远,真实值LiDAR点的密度非常低,从这些稀疏的监督中学习到的深度估计可能不够优化。
总结说来,显式方法在BEV特征构建中面临的问题,即深度估计的准确性和表示的稀疏性。
本文贡献
本文所提的BEV-IO方法旨在利用实例占用信息,来解决上述两个问题。实例占用表示了3D点被物体占用的概率,与深度不同,它能够捕捉场景的全面3D空间几何信息。
它引入实例占用预测(IOP)模块,IOP通过显式和隐式的训练方式进行训练。显式训练方式利用3D包围框的注释作为强有力的监督信号,而隐式训练策略则通过端到端的优化来提高占用预测的性能,从而实现更灵活的训练。通过将显式和隐式的训练策略相结合,IOP模块能够填充物体的内部结构,并且不受稀疏深度真值的影响,生成更加针对实例的、全面的BEV表示。
对于第二个问题(要映射哪些特征):设计了一种几何感知特征传播(GFP)机制作为替代方案,利用几何线索传播图像上下文特征,沿着每条输入射线进行占用分布自注意力来图像特征传递,并融入占用的几何结构信息,以更好地捕捉物体的内部空间结构。
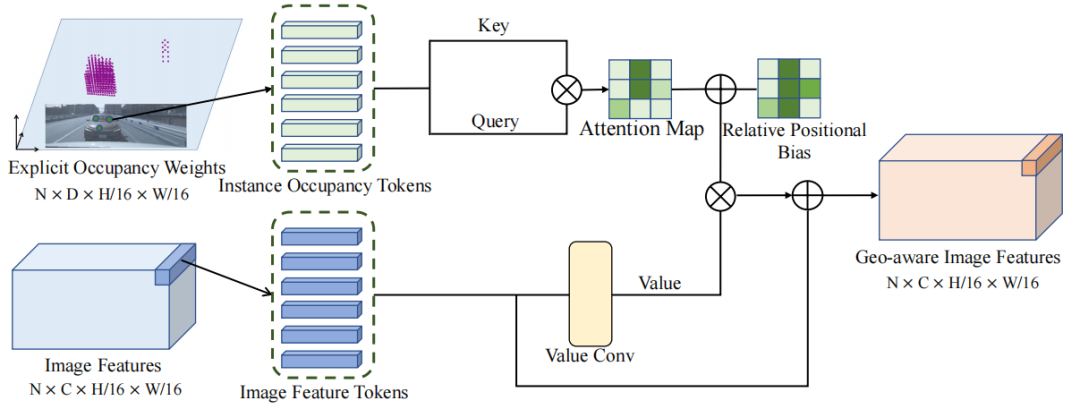
看下图中,(a)使用估计的深度权重将图像特征映射到BEV空间,深度权重仅包含可见表面的信息,无法提供完整的几何结构信息;(b)在深度权重之上引入了占用权重,此外还通过了占用线索传递具有几何感知能力的图像特征。
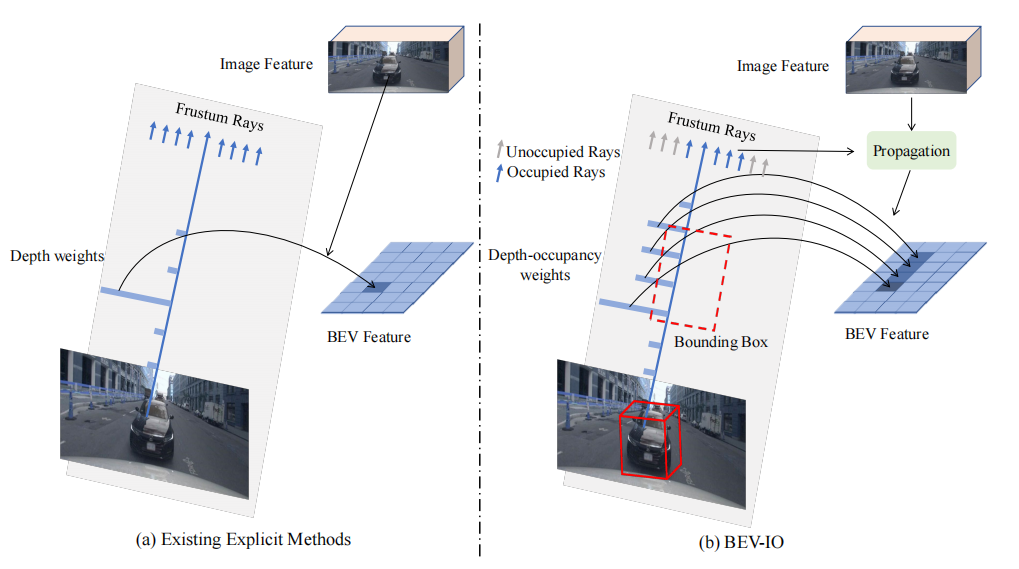
现有方法介绍
1. 多视图 3D 目标检测
现有的方法都遵循一个统一的范式:将图像特征投影到BEV空间进行检测。这些方法可以根据它们不同的投影方法分为显式方法和隐式方法。显式方法通过特征映射将图像特征投影到BEV空间,而隐式方法则通过特征查询的方式进行投影。二者介绍分别如下:
(1)隐式的BEV-based检测方法
隐式方法不依赖于显式的几何信息,而是使用注意机制获取BEV特征。现有的隐式方法包括BEVFormer、BEVFormerv2、PETR、DA-BEV、OA-BEV和FrustumFormer等。它们通过不同的方式来处理BEV特征。例如,BEVFormer使用柱状结构进行可变形的跨注意力机制,BEVFormerv2引入透视检测器,PETR通过位置编码增强BEV特征的几何感知能力,DA-BEV进一步增强了BEV空间信息和预测深度之间的关系,OA-BEV利用实例点云特征提高检测性能,而FrustumFormer则利用实例掩码和BEV占用掩码增强了实例之间的特征交互。与FrustumFormer中的BEV占用掩码不同,BEV-IO直接预测了3D空间中点级别的占用情况,以更好地辅助显式方法中的特征提取过程。
(2)显式的BEV-based检测方法
显式的BEV-based检测方法的核心思想是使用几何信息将2D图像特征映射到BEV空间中。一些方法(LSS)使用深度权重将特征映射到视锥体空间,然后投影到BEV空间;而另一些方法(BEVDepth)利用GT深度监督来提高深度估计的准确性;此外,还有一些方法通过引入时间信息(BEVDet4D)或多视角机制(BEVStereo、STS)进一步改进性能。这些方法都存在一定的局限性:无法全面准确地表示BEV空间中的几何结构。
2. 占用预测
占用预测是预测给定空间中3D点或体素的占用状态。在基于BEV的3D物体检测中,占用预测的目标是估计3D点或体素被物体占用的概率或可能性。它提供了关于哪些空间部分很可能包含物体,哪些部分可能为空或是背景的信息。
一些研究提出了不同的方法来预测空间元素的占用状态:
MonoScene 提出了一种通过估计深度视锥体来预测占用状态的方法;
OccDepth 使用立体视觉先验来估计度量深度,从而提高占用状态的预测准确性;
Voxformer是一个两阶段的方法,将占用状态的预测与物体类别的预测分开处理;
TPVFormer 则提出了利用三视图特征来估计占用状态的方法;
OpenOccupancy 在nuscenes数据集上进行了占用状态的密集注释。
本文方法
显式的BEV-based
首先,来自六个视角的图像 被输入到预训练的图像编码器中,以获取图像特征 ,这里 、和分别表示特征图的高度、宽度和维度。与隐式方法不同,显式方法估计每个视角的深度视锥体 ,其中深度视锥体 表示在视锥体中沿每条射线的不同手工设定的深度区间的概率, 表示深度区间的数量。通过使用深度视锥体 对图像特征 进行加权,可以得到图像特征视锥体 :
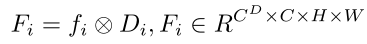
多个视角的图像特征视锥体被映射间,得到对应的三维空间表示,并通过体素池化(将多个三维空间中的体素值合并为一个单独的值)操作将它们投影到BEV空间中,数学描述如下:
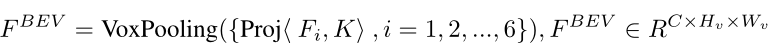
在基于摄像头的方法中,相机内参矩阵K用于将图像上的像素坐标转换为三维空间中的射线方向。相机内参包括焦距、主点坐标和相机畸变参数等信息,这些信息描述了相机的内部几何特征。
投影操作(Proj)利用相机内参矩阵K和深度信息,将图像特征从二维图像空间映射到三维空间。具体而言,对于图像上的每个像素点(x, y),投影操作可以计算出相应的射线方向,即将二维坐标映射到三维空间中的一个射线。这个射线的方向可以由相机内参和深度信息确定,从而将图像特征映射到对应的三维空间位置。
体素池化(VoxPooling)是将三维空间中的特征值汇聚到BEV空间中的过程。在这个过程中,相邻的体素(三维空间中的体积像素)的特征值被合并以生成BEV特征。体素池化可以通过不同的方式进行,例如平均池化或最大池化,用于将体素特征进行降维和聚合,以生成BEV表示。
BEV-IO架构
它包括三个主要部分:图像编码器、视图转换器和检测头。这里,图像编码器和检测头与BEVDepth相同,就不过多介绍,主要来说视图转换器。视图转换器采用双分支:3D几何分支和特征传播分支。
(1)3D几何分支由深度解码器和两个实例占据预测解码器组成。深度解码器用于预测深度权重,而实例占据预测解码器用于预测截锥体空间内的实例占据权重。这些解码器是有监督的,会与GT进行对比。深度权重和实例占据权重被合并成深度-占据权重,将图像特征投影到截锥体空间。
(2)特征传播分支的核心是几何感知特征传播模块(GFP)。该模块利用显式的实例占据权重和图像特征作为输入,生成几何感知特征。这些特征将被投影到截锥体空间,形成BEV特征。
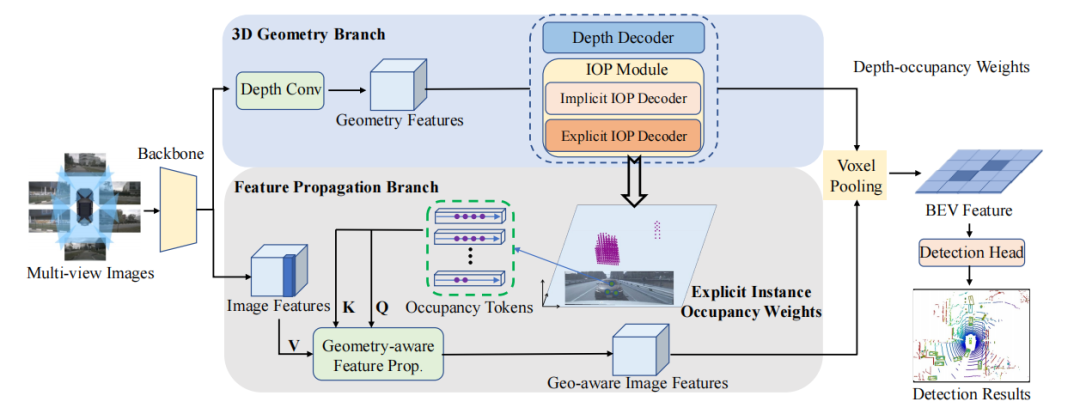
来看整个流程,3D几何分支接收backbone提取到的图像特征作为输入,用于估计深度和显式/隐式实例占据权重。这些权重被融合起来生成深度-占据权重。下面的特征传播分支也接收图像特征和显式实例占据权重作为输入,然后通过一个几何感知的传播模块进一步增强图像特征,并融合几何信息。随后,使用深度-占据权重将获取到的几何感知特征投影到BEV空间中。最后将BEV 特征经过检测头得到最终结果。
3D几何分支
本文提出利用点级实例占据信息来辅助特征投影的方法,解决只使用深度信息将特征投影到BEV空间不完整的问题。
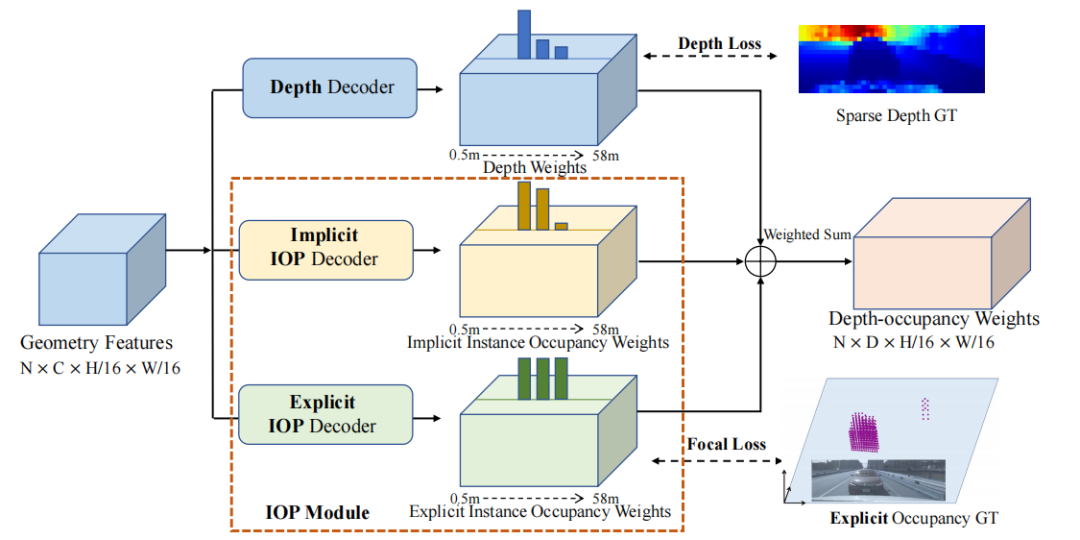
可以看到,3D几何分支以图像特征作为输入,预测深度、显式实例占用权重和隐式实例占用权重。深度和显式实例占用权重受到GT深度和生成的显式实例占用的监督。隐式实例占用权重学习一种隐式占用表示,深度-占用权重是这三种权重的加权和。
深度解码器:在BEVdepth 的基础上,深度解码器用于预测一组深度权重,这些权重对应于一组手动设计的深度区间。并通过二元交叉熵损失进行监督学习:
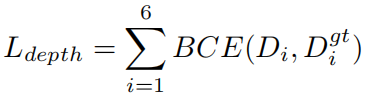
隐式 IOP 解码器:隐式实例占用预测解码器预测物体深度区间的占用概率,而深度权重只能捕捉到物体可见表面的信息,无法完整地表示物体内部空间。为了对缺失信息进行填补,隐式 IOP 解码器以端到端的方式,从输入的图像特征中预测每条射线上不同深度区间的占用概率,并且使用优化检测结果的整体目标代替GT的监督训练。
显式 IOP 解码器:手动注释点级占用信息费时费力,作者使用3D边界框的标签来构建占用标签,将占用标签建模为视锥体空间中的二元分类问题:将边界框内的3D点标记为1,否则标记为0。我们知道可以通过调节Focal loss中的α和γ参数,实现对样本权重的动态调节,使得模型聚焦于难分的样本,所以这里也是用 Focal loss 减轻类别不平衡的影响:
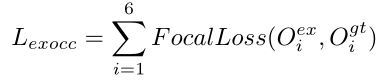
得到最终的深度占用权重如下:
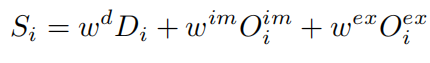
点级占用的GT生成:这是一种用于训练和评估模型的方法,通过将3D物体边界框划分为盒子的内部和外部来确定点的占用状态。下面是具体的步骤:
对于每个3D物体边界框,将其空间划分为盒子的内部和外部两个部分。这可以通过边界框的顶点坐标或边界框的最小和最大坐标确定。
对于要生成点级占用标签的每个点,计算它与边界框六个面的法向量的点积。这个点积可以用来确定点相对于边界框的位置。
如果一个点在边界框的所有六个面内部,即点与边界框的所有面的法向量点积都为正,那么该点被认为是被物体占用的点;相反,如果一个点在边界框的外部,即点与边界框的任何一个面的法向量点积为负,那么该点被认为是未被物体占用的点。
论文中的伪代码如下:

特征传播
对于每个特征点,将其显式占用权重用作自注意力机制的Key和Query。自注意力机制可以根据输入的Key、Query和Value来计算输出。在这种情况下,Key和Query是由占用权重生成的,而值是图像特征。通过计算自注意力机制,特征点的特征可以在同一实例中传播。这意味着具有相似占用权重的特征点将相互影响并传播彼此的特征,这种基于几何信息的特征传播确保了同一物体区域内特征的一致性。
Loss Function
总损失是检测损失、深度损失 和占用损失 的加权组合:
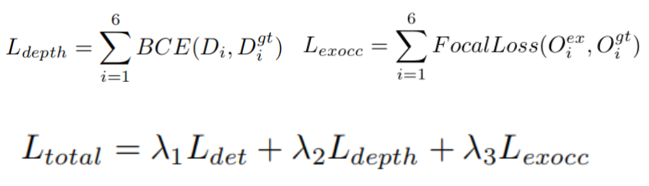
通过调整损失权重λ来决定每项损失的贡献程度,具体的权重通常是根据具体任务和数据集的特点进行调整的,在这篇文章中,λ是提前设置好的。
实验
一些介绍:
数据集:所使用的数据集是nuScenes数据集,这是一个大规模的自动驾驶数据集,包含超过1,000个场景的复杂城市驾驶场景,并标注了10个类别的1.4百万个3D边界框。这些场景涵盖了波士顿和新加坡的不同天气、光照条件和交通情景。
数据集划分:数据集的场景被官方划分为训练、验证和测试集,比例为700/150/150。
评估指标:在评估BEV-IO方法的性能时,使用了nuScenes数据集官方提供的一系列评估指标。这些指标包括nuScenes检测分数(NDS)和平均精度均值(mAP),用于衡量目标检测任务的准确性。此外,还使用了平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)和平均属性误差(mAAE),用于评估定位、尺度、方向、速度和属性等方面的误差。
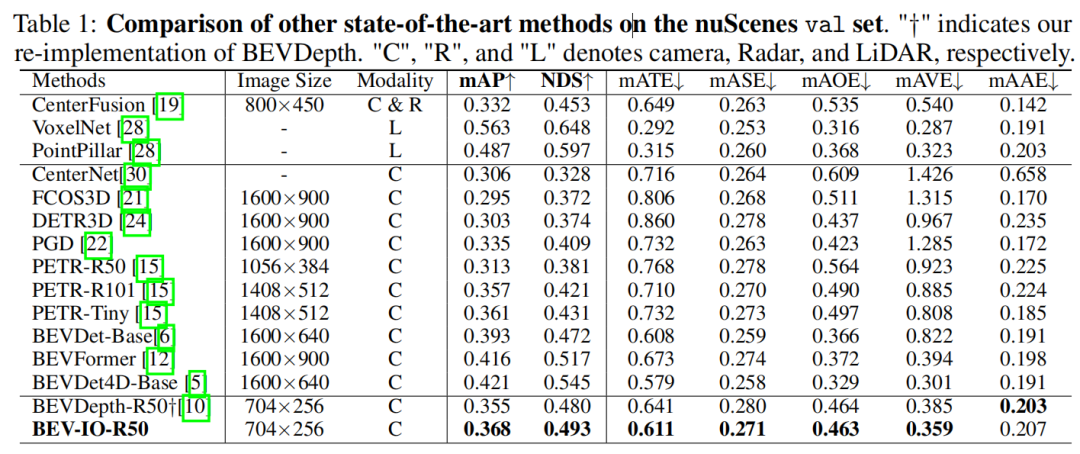
对比实验是与其他基于BEV的方法进行的,为了公平,所有方法都使用了CBGS策略进行训练。BEV-IO优于BEVDepth方法,而且仅增加了0.15M的参数和0.6 GFLOPS的计算量
接下来是消融实验,首先是BEV-IO所提的三个组件的情况:

为了验证一个问题:在估计的深度足够准确时,是否仍需要实例占据信息。所以,在BEV-IO中移除了深度解码器,并直接使用真实的深度当作独热编码的输入,另一种情况就是在此基础上去掉实例占据信息。说来,前者就是表示深度信息足够的情况,后者就是在深度信息足够时不使用实例占据信息,两者的对比情况如下,去掉Instance Occ各方面精度下降了:

接下来是对各方法参数、计算复杂度的比较,与baseline相比,BEV-IO仅增加0.2%的参数、0.24%的GFLOPs的情况下,其他指标得到了提升:

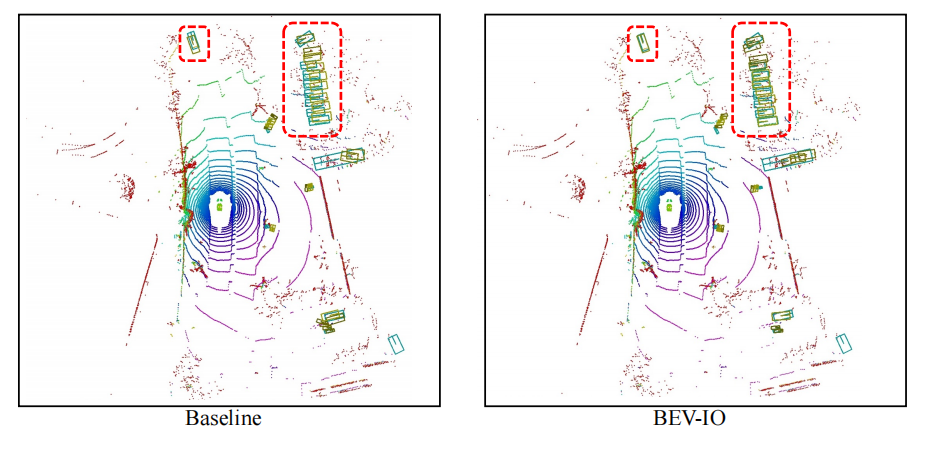
最后是检测结果的可视化,BEV-IO的预测结果和GT重合更接近(黄框:预测框;绿色:GT)
总结
作者在这项工作中提出了BEV-IO方法,用于解决深度在捕捉整个实例时的局限性。他们设计了一个实例占据预测模块,可以显式和隐式地估计实例点级占据信息,从而实现更全面的BEV特征表示。此外,还引入了一种几何感知特征传播机制,通过利用几何线索来有效地传播图像特征。实验结果表明,他们的方法在性能上超过了当前最先进的方法,而且仅在参数增加和计算开销方面增加了可忽略的量,在性能方面得到了更好的权衡。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

