
- 1数据结构 二叉树遍历专题_先序中可以用bitnode *p作为遍历指针吗
- 2pycharm导出依赖包_pycharm 创建的 django 项目。通过 npm install 安装完依赖包后 pycharm 卡死。...
- 3python的列表list排序方法——sort、reverse用法及实例
- 4如何使用git上传文件到gitee以及大项目文件(超过100MB的文件如传送)remote: error: File: f422c55c723a183a1944cbec840c0171042(超详细)_gitee超过100m
- 5【Spark】sparkSQL中cache的若干问题_sparksql 强制cache
- 6huggingface 中模型下载及部署演示_hugging face模型的下载以及使用
- 7pycharm联合Anaconda_pycharm和anaconda的联合使用
- 8计算机怎么盲打键盘,如何练习盲打 键盘盲打指法练习技巧-电脑教程
- 9CannotAcquireLockException处理
- 10路漫漫其修远兮
【Kafka】Kafka提高生产者吞吐量、数据可靠性-06
赞
踩
【Kafka】Kafka提高生产者吞吐量-06
1. 提高生产者吞吐量

import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CustomProducerParameters { public static void main(String[] args) throws InterruptedException { // 1. 创建 kafka 生产者的配置对象 Properties properties = new Properties(); // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // batch.size:批次大小,默认 16K properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // linger.ms:等待时间,默认 0 properties.put(ProducerConfig.LINGER_MS_CONFIG, 1); // RecordAccumulator:缓冲区大小,默认 32M:buffer.memory properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // compression.type:压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); // 3. 创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); // 4. 调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i)); } // 5. 关闭资源 kafkaProducer.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
测试:
①在 hadoop102 上开启 Kafka 消费者
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
- 1
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
- 1
- 2
- 3
- 4
- 5
- 6
2.数据可靠性
2.1 回顾数据的发送流程
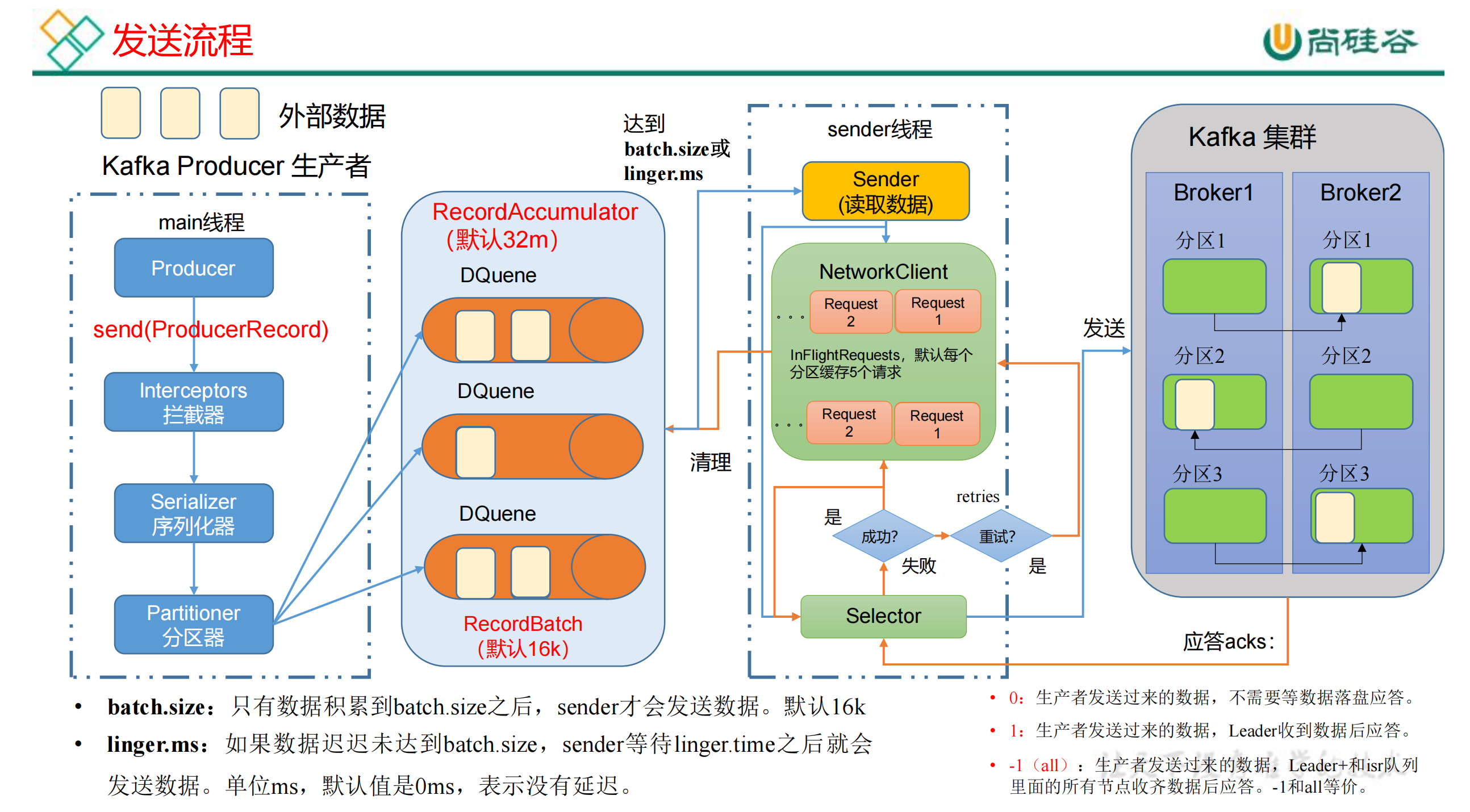
2.2 ack应答级别
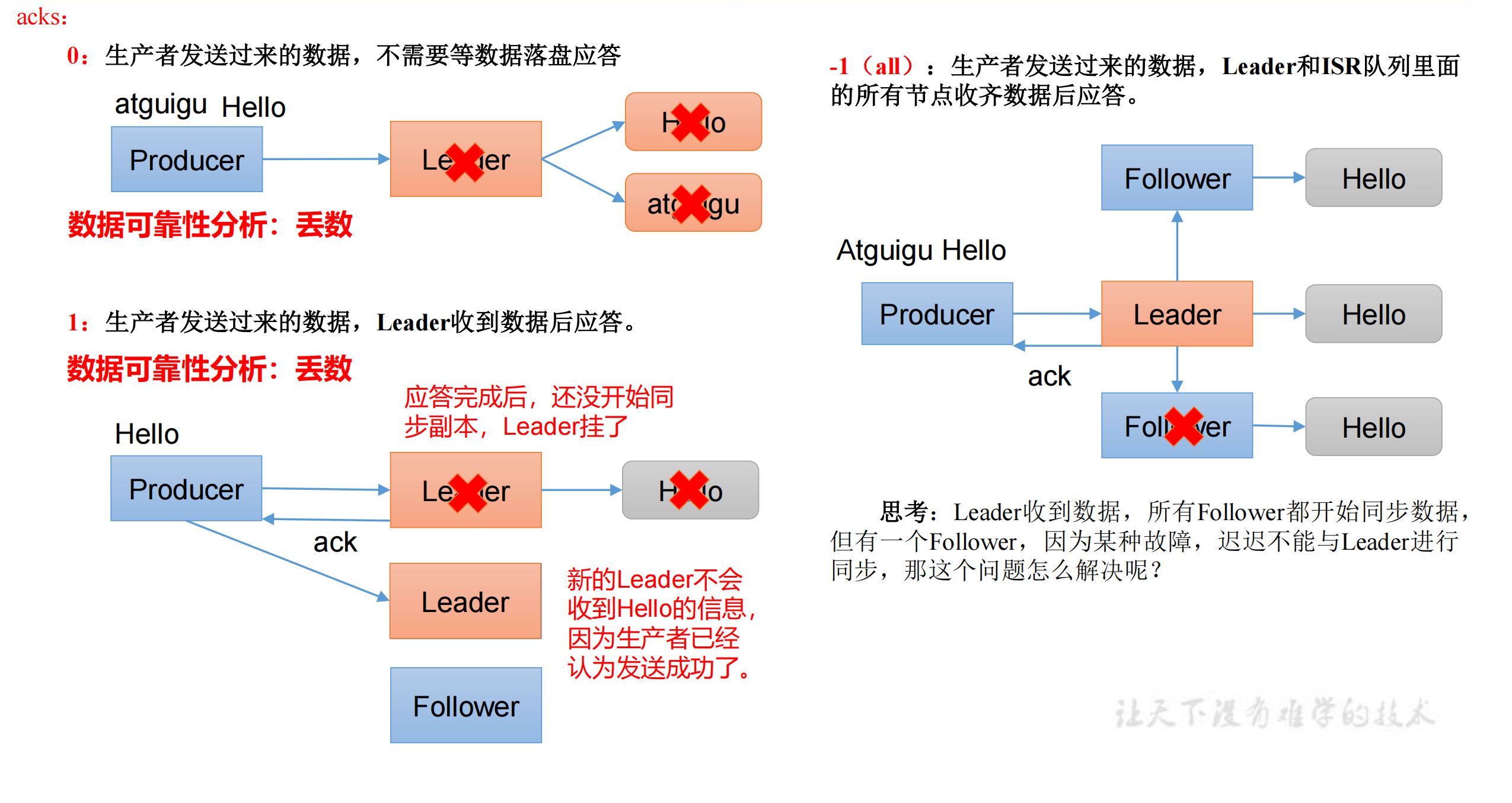
2.2.1 acks:0
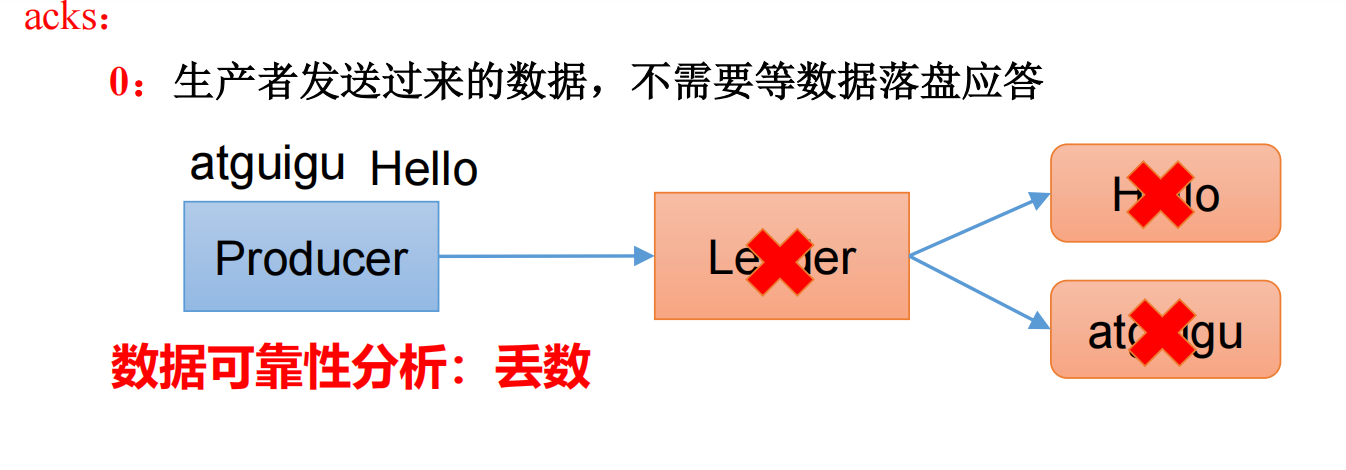
当应答级别为0时,生产者发送过来的数据,不需要等数据落盘应答。
工作:生产者将数据发送到leader中,如果leader突然挂掉了,leader还没有与follower同步,那么整个数据就全部都丢了。
2.2.2 acks:1
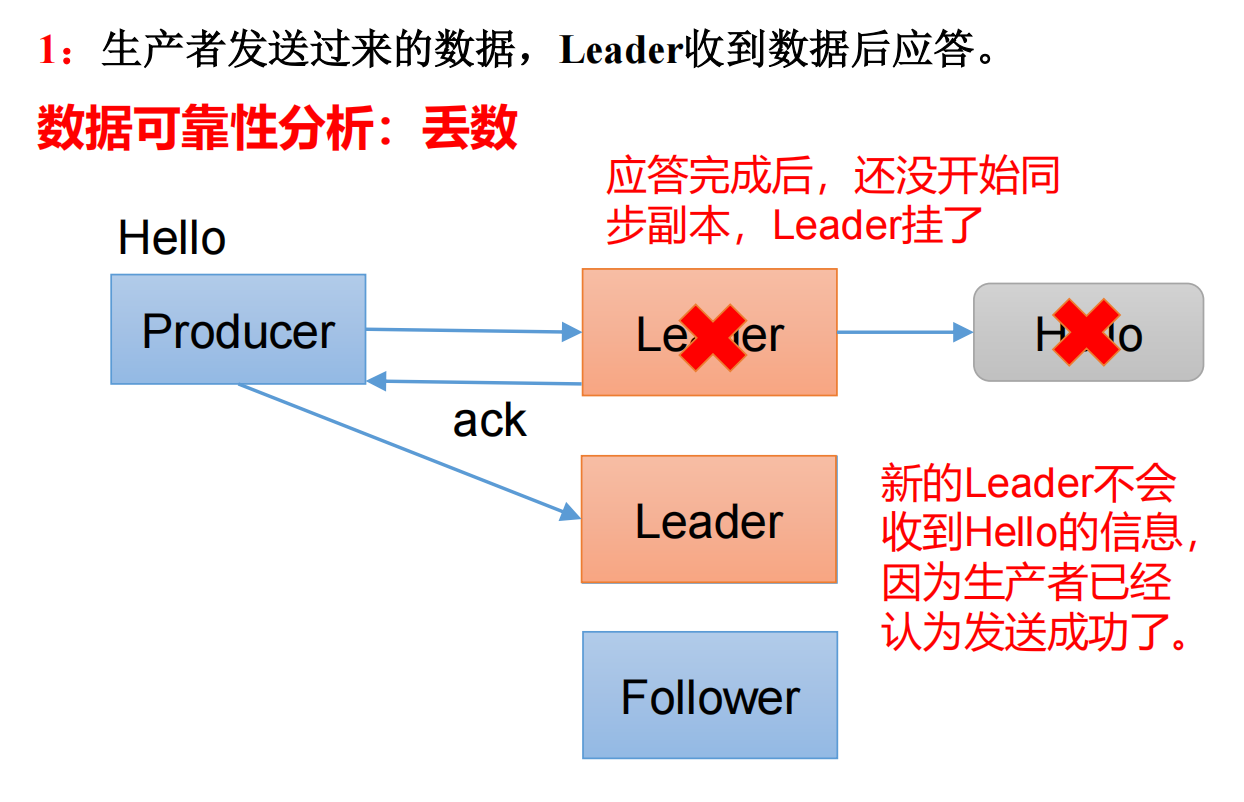
当应答级别为1时,生产者发送过来的数据,Leader收到数据后应答。
工作:如果应答完毕之后,leader还未与follower同步,leader挂了,新的leader会产生,原来的一条数据不会再次发送,造成了数据的丢失。
2.2.2 acks:-1(all)
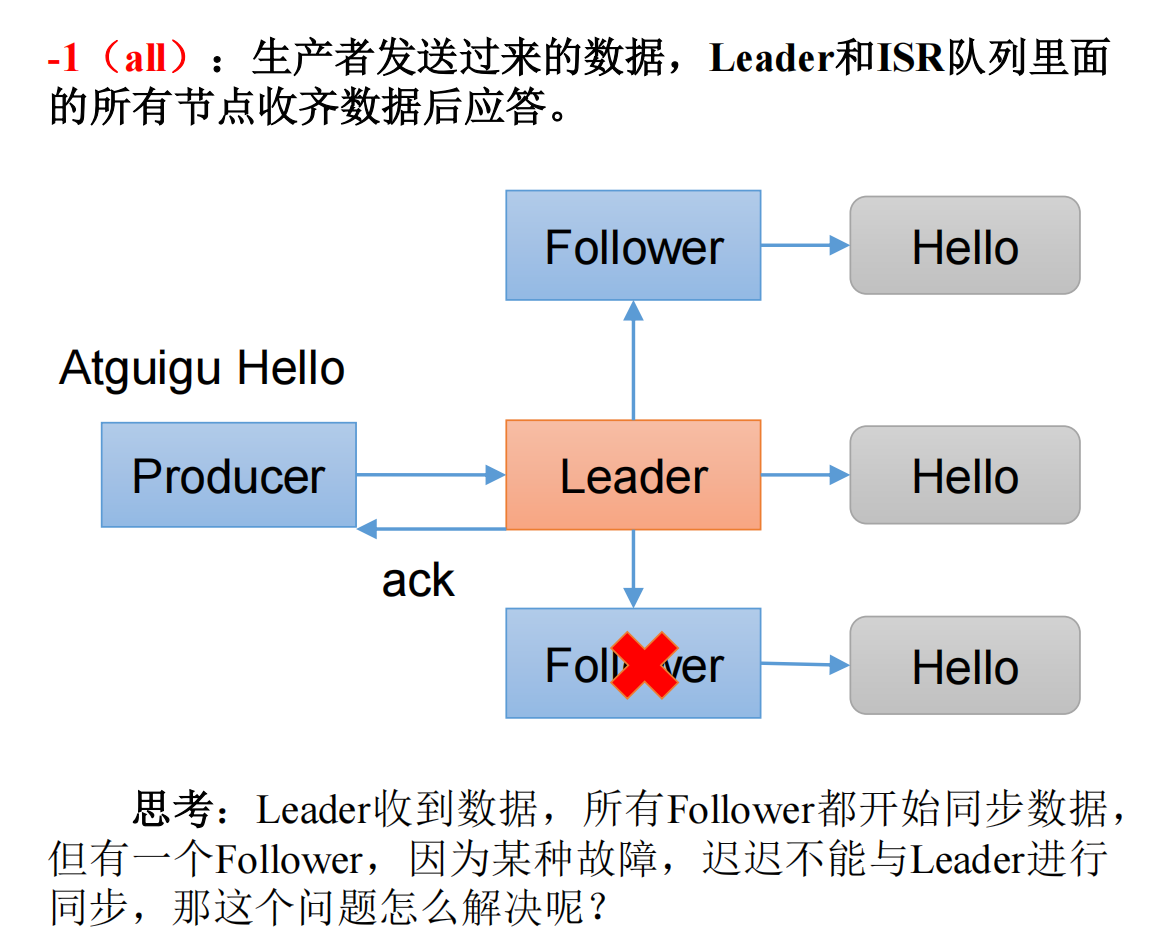
当应答级别为-1时,生产者发送过来的数据,Leader+和isr队列
里面的所有节点收齐数据后应答。-1和all等价。
工作:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader同步,那这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和Leader保持问步的Folower + Leader集合(leader:0, isr:0,1,2)。
如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,(leader:0, isr:0,1)。
这样就不用等长期联系不上或者己经故障的节点。
2.2.2.1 数据可靠性分析
如果分区副本设置为1个,或者ISR里应答的最小副本数量(min.insync.replicas 默认为1)设置为1,和ack=1的效果是一样的,仍然有丢数的风险(leader:0,isr:0)
2.2.2.2 数据完全可靠
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
2.3 可靠性总结
可靠性总结:
-
acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
-
acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
-
acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
-
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
2.4 可靠性代码配置
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CustomProducerAck { public static void main(String[] args) throws InterruptedException { // 1. 创建 kafka 生产者的配置对象 Properties properties = new Properties(); // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 设置 acks properties.put(ProducerConfig.ACKS_CONFIG, "all"); // 重试次数 retries,默认是 int 最大值,2147483647 properties.put(ProducerConfig.RETRIES_CONFIG, 3); // 3. 创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); // 4. 调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i)); } // 5. 关闭资源 kafkaProducer.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

