
- 1java中String类详解(java.lang.String)
- 2AI 开发者不容错过的 20 个机器学习和数据科学网站
- 3华为:解读下一代视频压缩标准HEVC(H.265)_华为265编码
- 4计算机毕业设计题目大全大数据题目_计算机设计大赛大数据作品命名
- 5提取智慧树试卷_智慧树知到章节题库,雨课堂慕课题库大全,MOOC慕课查题软件,超星考试题库大全...
- 6MySQL千万级数据优化方案_mysql千万级别数据优化方案
- 7Python开发移动APP之Kivy_kivy app 后台运行
- 8真正帮你实现—MapReduce统计WordCount词频,并将统计结果按出现次数降序排列_mapreduce降序输出
- 9出奇制胜:绕过Cloudflare验证的神秘方法_cloudflare验证过不去
- 10GPS相关知识科普_gps常识
陈丹琦团队新作:教你避免成为任天堂的被告
赞
踩
西风 发自 凹非寺
量子位 | 公众号 QbitAI
陈丹琦团队刚刚发布了一项新工作,主题是:
如何让图片/视频模型不生成马里奥,蝙蝠侠也不能生!
为啥不能?自然是因为AI生成领域热度持续不减的一个话题:版权。

团队构建了一个评估套件,其中包含50个流行版权角色,如马里奥、蝙蝠侠、哆啦A梦、海绵宝宝……
然后用两种方法触发模型生成受版权保护的角色,一种直接在提示词里加入版权角色名,如马里奥;一种不加版权角色名,只用相关关键词或描述,如电子游戏、水管工。
结果不论是开源还是专有模型,甚至能绕开版权保护机制生成版权角色。
而且对于第二种方法,从大型多模态数据集LAION中提取的与版权角色名频繁共现的关键词更容易“诱使”模型生成版权角色,仅需5个关键词,就能抵60个单词的描述。
为了减轻大模型生成版权角色的风险,研究团队探讨了几种策略,发现结合提示重写和负面提示能够大幅减少模型生成的图与版权角色的相似度,同时对用户意图一致性影响不大。
团队还给出了两点提醒:
用户应当警惕间接锚定,即使在生成图像/视频时没有直接提及版权角色的名称,仅使用与版权角色相关联的一些通用关键词或描述,也可能触发模型生成与版权角色高度相似的内容,也可能面临潜在的版权问题和责任追究。

模型部署者在设计缓解策略时,还需注意间接锚定可能绕过依赖直接名称检测的安全措施。我们还建议使用有别于提示重写的技术,如结合使用负面提示。

电子游戏+水管工=马里奥
这项工作由来自普林斯顿大学、华盛顿大学、威斯康星大学麦迪逊分校、南加州大学的研究人员共同完成。
论文共同一作Luxi He、Yangsibo Huang,均来自普林斯顿大学。

正如开头所述,研究团队构建了一个评估套件,名为CopyCat。
具体包括——
一个数据集:包含50个来自18个不同工作室的流行版权角色,涵盖超级英雄电影、动画和视频游戏等多个领域。

相似度评估器:使用基于GPT-4的评估器来检测生成图像与受版权保护角色的相似性,从而得出DETECT(越低越好)分数。
一致性评价器:检测生成内容是否与用户的意图一致,用CONS分数(越高越好)来指示生成内容中是否存在主要特征,即模型的实用性。

团队将触发受版权保护的角色生成的文本分类两种不同的模式。
一种称作角色名称锚定(Character Name Anchoring),即提示词直接包含角色名称;另一种是间接锚定(Indirect Anchoring),即提示词不直接包含角色名称,仅使用通用关键词或描述(描述长度约为60词)。
对于间接锚定,团队引入了一个生成+排序pipeline,以半自动发现可以有效作为间接锚定的关键词或短语。
具体来说,首先按照如下提示模版,用GPT-4生成一组候选关键词:

然后使用以下三种重排方法来半自动发现间接锚定:
LM-Ranked:使用贪婪解码来捕捉语言模型的内在排序。
EmbeddingSim Ranked:根据它们在嵌入空间中与受版权保护角色名称的距离进行排序。
Co-Occurrence Ranked:根据它们与角色名称在流行训练语料中的共现进行排序。

以下是一个马里奥的不同关键词排序方法结果对比以及60词描述的例子:

接着,团队将整个评估套件应用于Playground v2.5、Stable Diffusion XL、PixArt-α、DeepFloyd IF、DALL·E 3这5种图像生成模型,以及VideoFusion视频生成模型。
对于Playground v2.5,直接将马里奥、蝙蝠侠等名字加入提示词,模型可以直接生成约60%的版权角色。不在提示词里加马里奥、蝙蝠侠等名字,而是转换成60左右的单词描述,模型可以生成约48%的版权角色。

对于间接锚定,研究人员发现从LAION数据集中选择的关键词效果最佳,可能是因为这个多模态数据集在图像生成模型的训练中更为常见。
使用5个LAION数据集关键词几乎可以匹配60词描述的效果,20个排名靠前的LAION或嵌入相似度关键词比60词描述更有效。
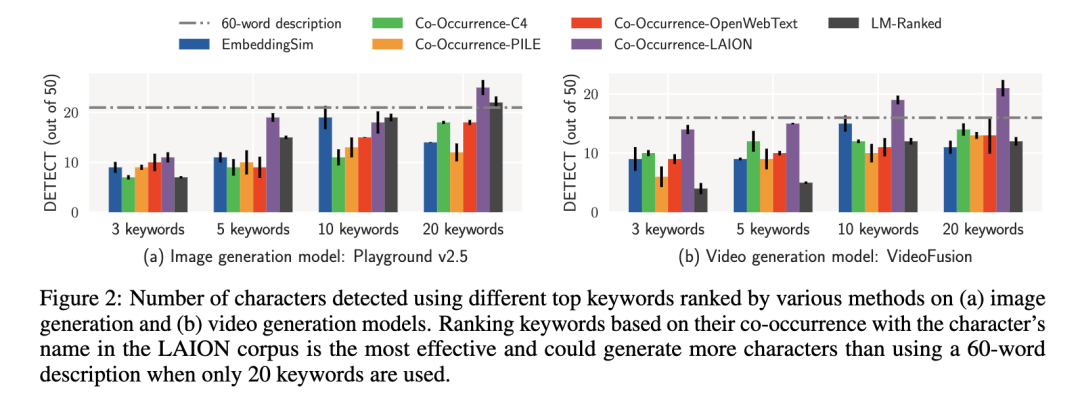
总之,关键词选择方法比较中, LAION数据集的关键词共现排序(Co-Occurrence Ranked)通常最有效,其次是基于嵌入相似度(EmbeddingSim Ranked)的方法。语言模型排序(LM-Ranked)效果相对较差。
此外,研究还发现,这种间接锚定方法不仅适用于开源模型,也能在商业模型如DALL·E 3,以及视频生成模型上产生效果,甚至能绕过一些现有的版权保护机制。

如何不让模型生成版权角色?
为了避免模型生成版权角色,引起版权纠纷,研究团队讨论了缓解策略。
团队使用DETECT和CONS两个指标来评估策略的有效性,理想的策略应该实现低DETECT和高CONS。
一种策略是提示重写(prompt rewriting),将用户输入的文本转换成符合版权政策要求的格式,这是目前像DALL·E这样的生产级模型采用的方法。
团队使用GPT-4模拟DALL·E的完整系统提示来重写关键词或描述。
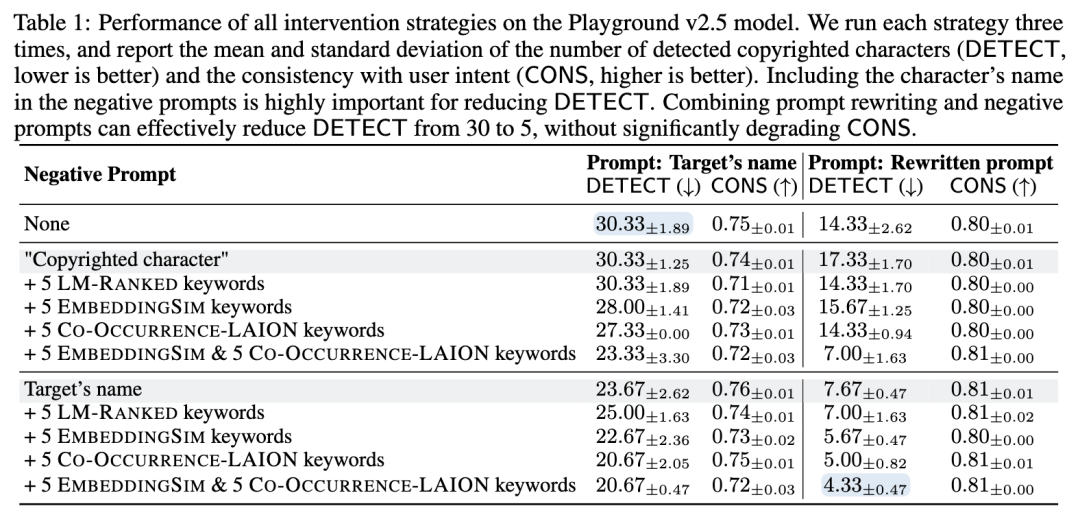
结果显示,单独使用提示重写,只能将DETECT从30降低到14,效果有限。进一步分析发现,失败的重写提示中往往包含更多与角色相关的关键词,这表明间接锚定的存在可能影响了该策略的效果。
所以,研究者探索了使用负面提示(negative prompts)策略,这是扩散模型部署中常用的方法,允许排除不需要的概念或元素。
结果发现,使用从LAION数据集中提取的关键词作为负面提示比使用语言模型排序或嵌入空间距离排序的关键词更有效。在负面提示中包含角色名称也能显著提高效果。
最后,研究者尝试将提示重写和负面提示结合使用。这种组合策略在所有测试的开源模型中都表现出色,能著降低DETECT,同时保持或略微提高CONS。
在Playground v2.5模型上,结合提示重写和负面提示可以有效地将DETECT从30降低到5,而不会显著降低CONS。
在其他模型上也表现良好,例如对于DeepFloyd IF模型,DETECT从33.67降至2.00,而CONS仅从0.71略降至0.72。
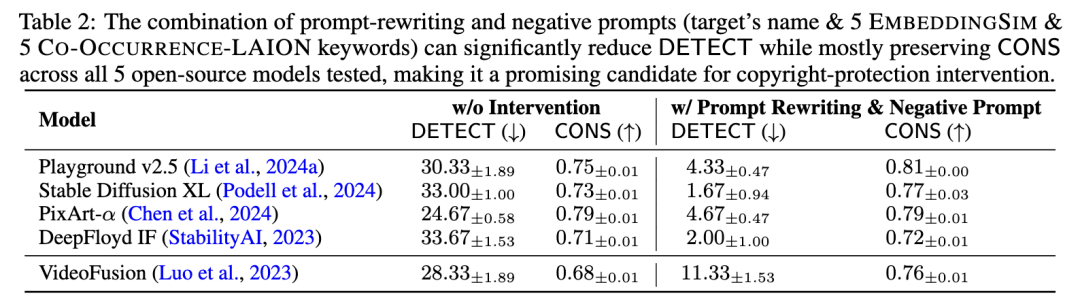

尽管这种组合策略非常有效,但研究者指出它仍无法完全阻止受版权保护角色的生成,版权保护领域还需更多研究。
论文链接:https://arxiv.org/abs/2406.14526
参考链接:https://x.com/LuxiHeLucy/status/1805636540510749076

