
百川智能开源最新商用大模型!王小川:比LLaMA更香,下一枪打ChatGPT
赞
踩
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
我们现在可以获得比LLaMA更友好,且能力更强的开源模型。
这次在发布会现场表达出“遥遥领先”之意的,是百川智能CEO王小川。
保持一个月新发布一次大模型的频率,百川智能最新开源微调后的Baichuan2-7B,并且免费商用。
王小川表示,MMLU等英文评估基准的英文主流任务评分,70亿参数量的Baichuan2-7B在英文主流任务上与130亿参数的LLaMA2相当。
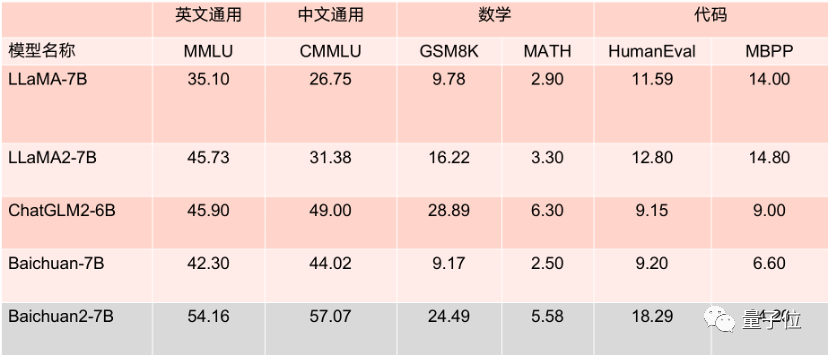
一并开源的还有Baichuan2-13B、Baichuan 2-13B-Chat与其4bit量化版本,以及模型训练从220B到2640B全过程的Check Poin。
同时公布了详细介绍训练细节的Baichuan2技术报告,旨在让外界了解其训练过程,“更好地推动大模型学术研究和社区的技术发展”。
Baichuan2系列大模型,开源的
Baichuan2系列的两款开源大模型,分别是70亿参数的Baichuan2-7B,以及130亿参数的Baichuan2-13B。
其数据取自万亿互联网数据和垂直行业,训练token规模在2.6TB。
据悉,Baichuan2系列大模型的数据处理借鉴了很多搜索时用到的经验。
一方面是在超大规模内容通过聚类系统,达到“小时级完成千亿数据清洗和去重工作”;另外,大部分数据清洗时进行了多粒度内容质量打分,支持细颗粒采样,从而提高模型质量(尤其是中文领域)。
系列里的两者均支持中、英、西、法等数十种语言,主要应用学术研究、互联网、金融等领域。
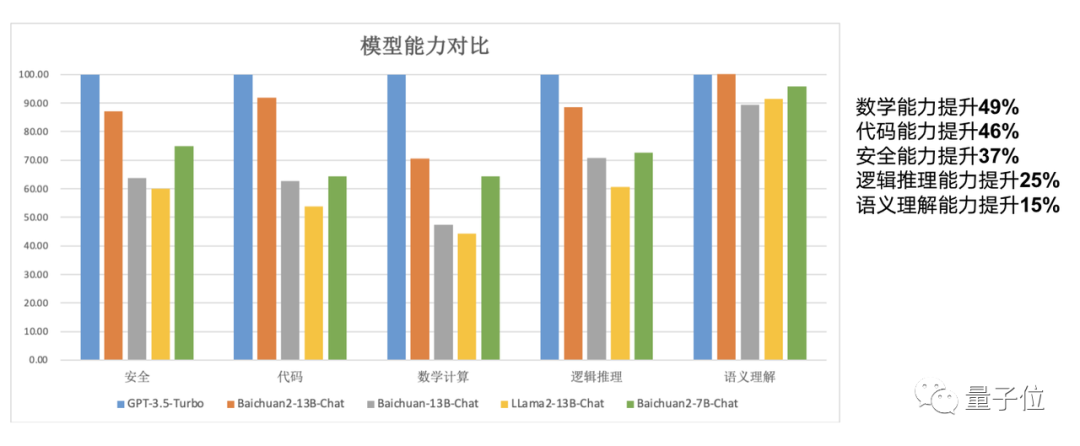
相比一代,Baichuan2数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑能力提升25%,语义理解能力提升15%,文理科能力方面均有提升。
百川在infra层也做了优化,使得现在在千卡A800集群里达到180TFLOPS的训练性能,使得机器利用率超过50%。
王小川在现场表示,在模型参数和结构设置上,Baichuan大模型尽可能靠近LLaMA系列。
这样做的最大的意义在于,让社区用户能够直接从LLaMA换成百川的模型。同时,我们尽可能兼容更多的社区生态。
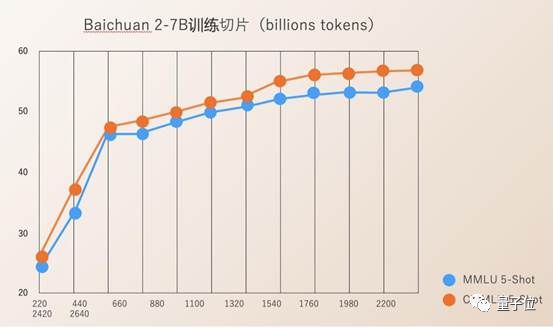
除了再更大模型,百川智能还公布了3000亿-2.6万亿tokens的模型训练中间过程。
也就是说,百川像切片一样把不同大小token的能力开发出来,“对大家理解预训练,或者在预训练上做微调强化更容易操作。”
这也是在国内首次有公司能开放这样的训练过程。
值得一提的是,百川系列大模型对学术界师生开通了绿色通道,申请时可以获得更多资料,以帮助学术。
预计明年1季度推出“超级应用”
自成立起,百川智能保持着月更大模型的速度,呈现出开闭源交替发布的情况。
此前Baichuan-7B、Baichuan-13B开源后,Hugging Face首周下载量破百万,总下载量为500万,是全球下载量最高的开源大模型,申请部署试用的企业数量超200家。
闭源模型方面,则有上个月发布的Baichuan-53B,对大模型和搜索进行了“很高程度”的融合。
为何“开源+闭源”并行?
“在二季度最后一个月,我们认为当时的需求,也是我们能贡献的地方,就是开源模型。”王小川现场解释称,“所以成立公司之后我们就发布开源模型,同时兼顾闭源大模型的训练。”

迄今为止,国内发布的大模型总数超百家。
不只是训模型,“落地”这一步也来到眼前:一周前,首批11家国产AI大模型也开始向公众开放。
但如中国科学院院士、清华大学人工智能研究院名誉院长张钹在发布会演讲时提到,市面上的大模型,“主要集中在垂直领域的应用上”,而不是“对大模型的学术研究本身”。
然而,这个工作既迫切,又重要。
到现在为止,全世界对大模型的理论工作原理、所产生的现象都是一头雾水,所有的结论都推导产生了“涌现现象”。
所谓涌现,就是解释不清楚的情况下给自己一个退路。我认为这个问题必须要把它搞清楚。
大模型赛道自身的繁荣,开源有益对创新和研发效率的助推,都有利于彻底了解GPT。

确定开闭源并行的公布模式,密集对外公布阶段性成果,目前App已实现对外开放,百川智能的下一步计划是什么?
今年四季度,预计发布千亿参数大模型。
明年一季度左右,预计推出“超级应用”。
这两个时间节点,也被诸多大模型厂商和创业公司此前立下flag。感觉到时候,作用用户一方,咱们又有更多期(hao)待(xi)了~
— 联系作者 —


