
- 1欢迎参加SPDK线上中文讨论会议
- 2阿里开源高性能搜索引擎 Havenask - Ha3
- 3Windows10多显卡修改默认高性能卡_windows server 更改默认显卡
- 4Python爬虫常用哪些库?_python爬虫库
- 5FPGA编程语言--VHDL OR Verilog?_fpga语言
- 6机器人仿真论文阅读1_机器人仿真设计论文
- 7yolov8 多卡训练报错subprocess.CalledProcessError: Command‘[‘/home/... returned non-zero exit status 1._yolov8多卡训练报错
- 8JAVA 中 Switch引用Enum问题
- 9Spark内核架构剖析_spark sql内核剖析 下载
- 10js中的map和set_js map赋值set
redis知识盘点【伍】_一致性哈希和cluster集群_redis cluster 一致性哈希
赞
踩
上篇文章:redis知识盘点【肆】_主从复制和sentinel哨兵
正如上文所讲,sentinel解决的是redis集群高可用问题,那么当我们系统缓存的数据量非常大,不再适合全量放在一个redis实例中的时候,redis 3.0版本推出的cluster功能就可以大展拳脚了。cluster虽然名字翻译过来是集群的意思,实际上它解决的是数据sharding问题,可以根据一定规则,将不同key的数据路由到不同的redis实例中保存。而在redis cluster功能开放之前,我们基本都是自己实现sharding功能的,这里就不得不提一致性哈希(Consistent Hashing)算法。
一致性哈希算法
首先说下什么是哈希算法。哈希算法就是将任意长度的二进制值映射为较短的固定长度的唯一的二进制值(即哈希值)。敲黑板,哈希算法的入参可以是任意长度,而出参是固定长度而且唯一。
而一致性哈希算法就是,先构造一个0到2^32的整数环(hash环,java中可用SortedMap实现),根据缓存服务器名称(也可以是ip:port)计算出hash值,根据其hash值将缓存服务器放置在hash环上。每次根据要缓存的key计算得到hash值,在hash环上顺时针查找距离最近的缓存服务器节点(SortedMap.tailMap(key)实现),进行set/set操作。原理如下图所示:
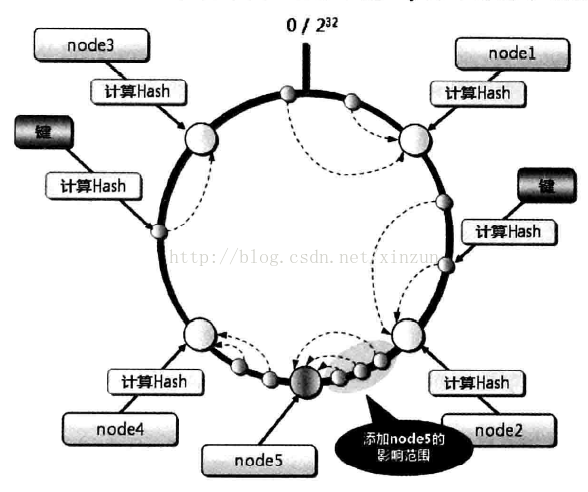
但是一致性哈希算法有如下问题:
1.加减缓存服务器节点会造成hash环部分数据无法命中;
2.少量缓存服务器节点时,数据分布不均匀,同时缓存服务器节点变化将影响大范围数据;
3.普通的一致性哈希分区需要增加一倍或减掉一半缓存服务器节点才能保持数据负载均衡;
当只有少量缓存服务器又想尽量保证负载均衡时,我们一般采用下面的办法:将一个缓存服务器节点虚拟成一组,比如某台缓存服务器为192.168.2.1:6379,我们就可以将其虚拟成一个虚拟节点数组,为192.168.2.1:6379-1,192.168.2.1:6379-2,192.168.2.1:6379-3……然后分别计算数组里的元素的hash值并映射到hash环上,每台缓存服务器都如此处理。当不同key的缓存路由到虚拟节点时,最终都是指向真实的缓存服务器节点。通过这样增加节点的方式,可以一定概率上使数据路由均衡。当然这也不是最好的解决方案,于是redis cluster横空出世了。
redis cluster集群
redis cluster使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含16384个哈希槽(slot), 每个 key 都属于这16384个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。槽(slot)是redis cluster中数据管理和迁移的基本单位,每个节点负责一定数量的槽。
cluster nodes配置很简单,首先将.conf配置文件中的cluster-enabled修改为yes,然后登陆某台redis服务器,执行cluster meet {ip} {port}去和集群中其他redis服务器握手,cluster nodes和cluster info命令可分别查询集群的节点和状态。
我们还可以为登陆的redis服务器设置一个从节点:cluster replicate {nodeid},其中nodeid为节点id,可通过cluster nodes命令查询。一个主节点可以社多多个从节点,当主节点挂掉时,redis cluster会选取一个从节点升级为主节点继续提供服务,只有当该节点的所有主从服务器全部挂掉,redis cluster才停止提供服务。
当我们配置好redis集群中的各个主从节点后没救可以进行槽(slot)的分配了,命令为cluster addslots {slot_index1} {slot_index 2} {slot_index 3} ...(此处槽id只支持一个一个指派,不过可以用linux循环命令运行)。注意,主要当16384个槽全部指派完毕后,redis cluster才会进入上线状态。
当进行redis集群扩容的时候,操作主要分三步,一是准备新节点;二是加入集群;三是进行槽和数据迁移。这里说说第三步的执行命令:
1.对目标节点发送
cluster setslot {slot_index} importing {source_node_id}
2.对源节点发送
cluster setslot {slot_index} migrating {target_node_id}
3.源节点循环执行
cluster getkeysinslot {slot_index} {count(key个数)}
4.源节点执行,把key通过流水线(pipeline)迁移到目标节点
migrate {target_ip} {target_port} "" 0 {timeout} keys {key1} {key2} {key3}
5.重复3、4步骤
6.向集群中所有主节点发送通知
cluster setslot {slot_index} node {target_nodeid}
【注】新版本提供了REDIS-MIGRATE-TOOL工具可以使用。
大概说一下redis cluster的内部实现,redis cluster中每个节点都维护了clusterNode和clusterState两种结构体(当然还有其他元素,这里只介绍这两个)。其中,每个节点不止维护了自身的clusterNode,还保存了集群中其他节点(无论主从)的clusterNode,会通过集群总的广播进行更新。clusterNode中有一个slots属性,是个二进制数组,长度为16384/8=2048,用每个二进制位上的0还是1来表示该节点是否负责slot[i],如下图所示:

而clusterState结构体中维护了一个*slot[16384]的指针数组,记录着集群中节点和槽的对应关系。每个槽对应的slot指针数据下标,直接指向对应节点的clusterNode结构体。这里将槽的指派信息又记录一遍的设计,是为了方便节点查询直接返回,而不是遍历一遍自己保存的集群总所有节点的clusterNode。
节点在接到命令请求时,会根据key所在的槽id去查clusterState.slot[槽id]是否指向自己的clusterNode,如果是则进行处理;如果不是则返回moved错误,moved错误携带正确的节点ip和端口号返回给客户端指引其转向执行,而且客户端以后的每一次关于该key都会去moved错误提供的节点去执行。
当节点的key正在迁移的时候,收到关于该key的请求,那么节点会返回ask错误,并但会正确的节点ip和端口号给客户端去执行。但是这个转向只对本次请求有效,后面关于该key的请求还是会发送到目前正在处理key迁移的节点,直到key迁移完毕并发送广播通知。
当然redis cluster也不是完美的,它有一些功能上的限制:
1.目前只支持同一个槽上的key的批量操作;
2.目前只支持同一个槽上的key事务;
3.只能使用数据库0(每个redis实例有16个数据库,可通过select {index}命令来切换);
4.不能将一个大的key(如hash、list)映射到不同的节点上;
5.目前集群主从复制只支持一层,不支持嵌套树状架构;
到这里感觉redis比较核心的东西都写完了,下一篇写点什么我再想想。

