
- 1【Quart 框架——来源于Flask的强大且灵活的异步Web框架】
- 2IDEA支付宝小程序开发流程——授权登录_支付宝小程序 minidev identitykeypath
- 3【计算机网络】域名劫持无处遁形:基于HTTPDNS打造可靠且安全的域名解析体系_域名解析接口
- 4什么是同步整流和异步整流_同步整流和异步整流的区别
- 525K Stars! Open WebUI + Ollama + Llama3搭建本地私人ChatGPT
- 6Postman 接口测试神器_在线postman
- 7RENISHAW雷尼绍双读数头系统应用分享
- 8亚马逊云科技 EC2服务搭配SD Webui开箱即用的AIGC文生图/图生图平台_aws sd-webui 配额
- 9elasticsearch配置文件详解_cluster.name
- 10MyBatis查询数据库之四(动态SQL -- if、trim、where、set、foreach 标签)_insert into和if标签
python抓取文献关键信息,python爬虫——使用selenium爬取知网文献相关信息
赞
踩
python爬虫——使用selenium爬取知网文献相关信息
写在前面:
本文章限于交流讨论,请不要使用文章的代码去攻击别人的服务器
如侵权联系作者删除
文中的错误已经修改过来了,谢谢各位爬友指出错误
在你复制本文章代码去运行的时候,请设置延迟,给自己留一条后路
转载请注明来源,谢谢
1. 先看爬取的效果
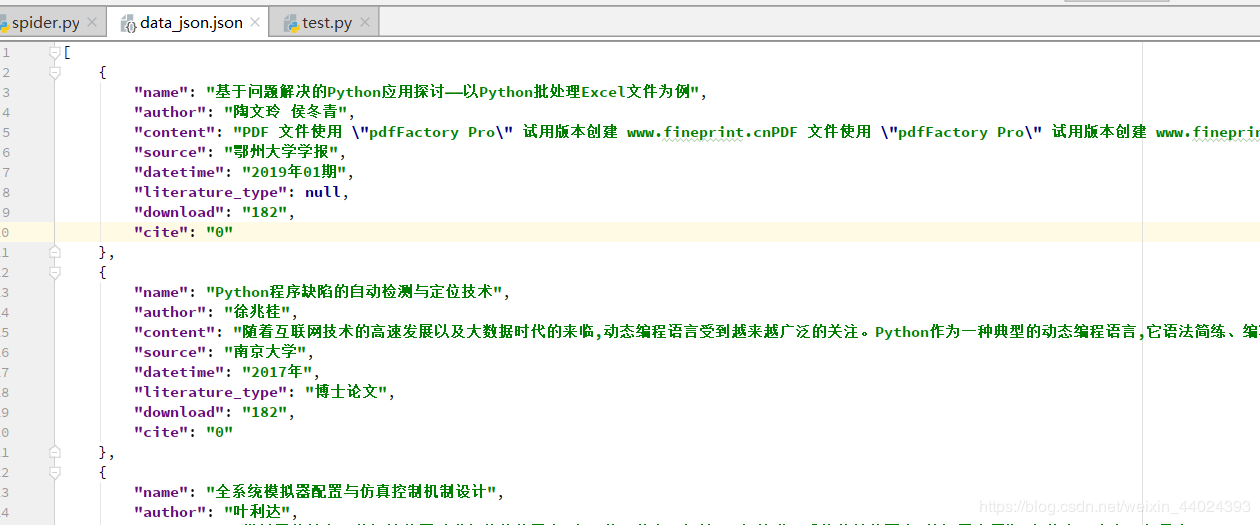
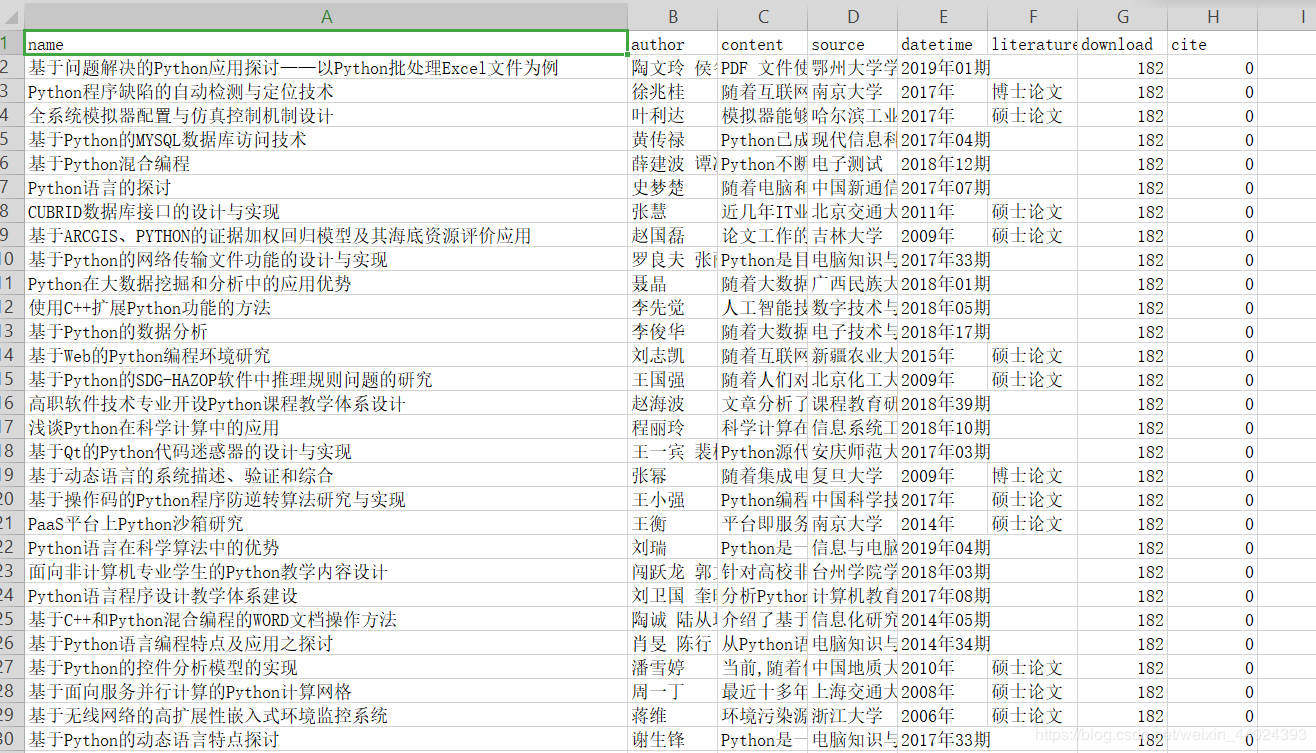
2.
知网的反爬虫手段很强,反正我爬取pc端的时候,用selenium爬取获取不到源代码,真是气人,后来换成手机端就可以获取了,爬取手机端的操作如下。
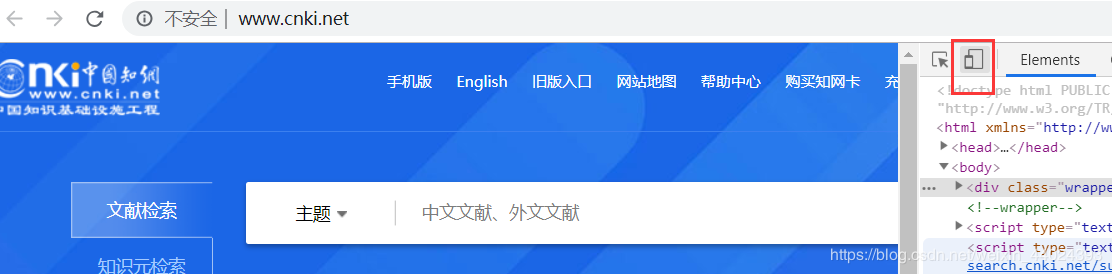
3. 首先进入知网后,选择开发工具,建议放在右边,之后再点击图中红框的东东,然后刷新一下网页就切换到手机端了
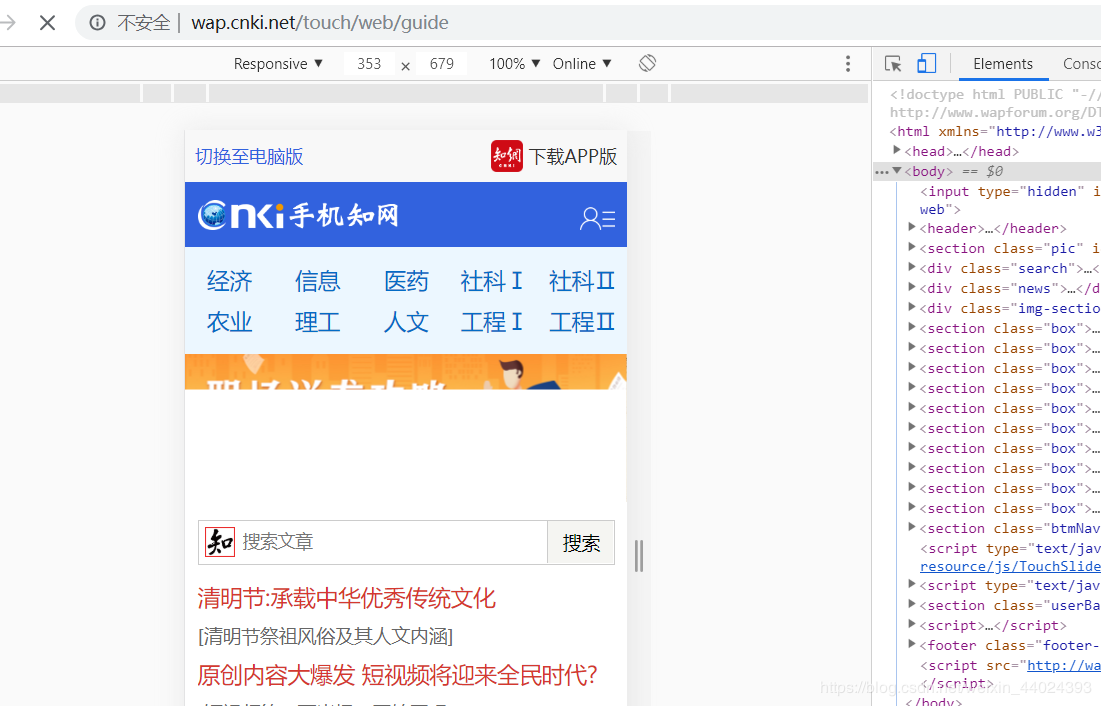
4.进入手机端的界面如下图所示(注:记得刷新网页):
5. 这是网址
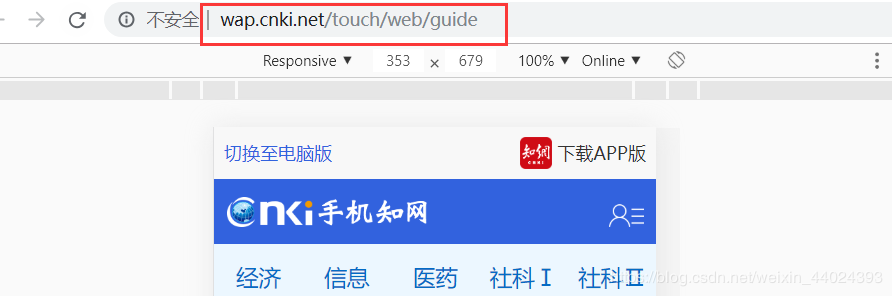
6. 首先在调用selenium之前设置一些参数
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import json
import csv
# 设置谷歌驱动器的环境
options = webdriver.ChromeOptions()
# 设置chrome不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(options=options)
url = 'http://wap.cnki.net/touch/web/guide'
7. 既然使用selenium,那么我们需要获取输入框的id来自动输入关键字,输入关键字之后再获取搜索的按钮,然后点击

8.代码如下(输入的关键字是python):
# 请求url
browser.get(url)

