
- 1斐讯T1刷机详细指南_斐讯t1刷机教程
- 2word2vec原理推导与代码分析_双重求和的偏导
- 3MongoDB与Java集成:熟悉Java驱动、ORM框架_java集成mongodb
- 4使用springboot简单整合springsecurity和mybatis-plus_springboot整合springsecurity mybatis
- 5昇思25天学习打卡营第11天|munger85
- 6全文检索的核心技术是将源文档中所有的基本元素的出现信息记录到索引库中_full-text search
- 7ICLR 2023 | 大模型上下文学习的无限扩展方法:kNN Prompting
- 8opencv 保存读取16位深度的图像_opencv保存16位图像
- 9限时免费开放AI绘画功能!快拉上小伙伴们来免费体验MJ绘画及更多AI功能!_聚力ai助手网站没有了
- 10二叉树的遍历——DFS深度优先搜索——先(根)序遍历、中序遍历、后序遍历_二叉树的先根遍历和中根遍历
论文阅读之LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS(2021)_9.1.1 lora 核心思想是什么?
赞
踩
论文地址
LORA: LOW-RANK ADAPTATION OF LARGE LAN-
GUAGE MODELS
主要内容
这篇文章的主要内容是介绍了一种名为LoRA(Low-Rank Adaptation)的技术,这是一种针对大型语言模型进行低秩适应的方法。LoRA的核心思想是在预训练模型的基础上,通过注入可训练的低秩分解矩阵到Transformer架构的每一层,而不是对所有模型参数进行微调(fine-tuning),从而大幅减少下游任务的可训练参数数量。这种方法在保持预训练权重不变的情况下,通过优化低秩矩阵来间接训练密集层的权重更新。
文章通过实验表明,LoRA在多个NLP任务上的表现与完全微调相当,甚至在某些情况下更优。LoRA的主要优势包括:
显著减少了可训练参数的数量,例如,与GPT-3 175B微调相比,LoRA可以将可训练参数减少10,000倍。
降低了GPU内存需求,提高了训练效率。
由于LoRA的简单线性设计,可以在部署时将训练矩阵与冻结权重合并,从而不会引入额外的推理延迟。
LoRA与许多现有方法正交,可以与它们结合使用,例如前缀微调(prefix-tuning)。
此外,文章还提供了对LoRA的实证研究,探讨了在语言模型适应中秩不足性的作用,并解释了LoRA的有效性。作者还发布了一个包,方便将LoRA与PyTorch模型集成,并提供了RoBERTa、DeBERTa和GPT-2的实现和模型检查点。
主要贡献
文章的主要贡献可以总结为以下几点:
1.LoRA方法的提出:文章提出了一种新的低秩适应(Low-Rank Adaptation, LoRA)方法,用于在不重新训练所有参数的情况下,对大型预训练语言模型进行有效适应。这种方法通过在Transformer架构的每一层注入可训练的低秩矩阵来实现,从而大幅减少了下游任务的可训练参数数量。
2.显著降低参数数量和内存需求:LoRA能够将可训练参数的数量减少10,000倍,同时将GPU内存需求降低3倍,这使得在资源受限的环境中部署和使用大型模型变得更加可行。
3.保持或提升模型性能:尽管LoRA减少了可训练参数的数量,但它在多个NLP任务上的性能与完全微调相当或更好,这表明LoRA是一种高效的模型适应方法。
4.无额外推理延迟:LoRA的设计允许在部署时将训练矩阵与冻结权重合并,这意味着在推理时不会引入额外的计算延迟,这与完全微调的模型相比是一个显著优势。
5.与现有技术的兼容性:LoRA可以与许多现有的模型适应技术结合使用,如前缀微调(prefix-tuning),这增加了LoRA的灵活性和实用性。
6.实证研究:文章提供了对LoRA方法的实证研究,探讨了在语言模型适应中秩不足性的作用,并解释了LoRA的有效性。
7.资源和工具的发布:作者发布了一个包,方便将LoRA与PyTorch模型集成,并提供了RoBERTa、DeBERTa和GPT-2的实现和模型检查点,这为研究社区提供了宝贵的资源。
总的来说,文章的主要贡献在于提出了一种新的、高效的大型语言模型适应方法,这种方法在减少资源消耗的同时,保持了模型的性能,并且易于与现有技术结合使用。
模型图
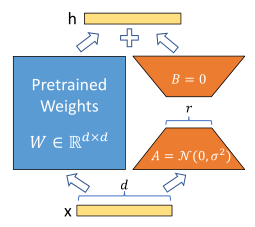
言简意赅
左边预训练模型权重不动
只训练右边的A和B
技术细节
假设预训练模型要进行常规全参数微调
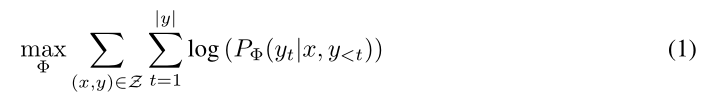
其中Φ表示模型的参数,x表示输入,y表示输出
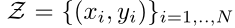
表示进行微调任务的数据集
此时我们需要调整的参数就是全参数:
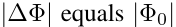
如果是175B的模型,微调一个下游任务的模型,每次都要调整这么多参数,工作量巨大。
但是使用LoRA技术的话
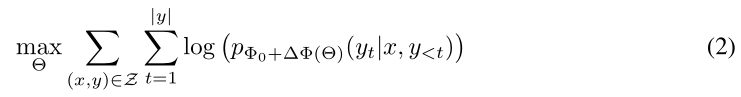
预训练模型的参数都冻结,不调整
只是额外加一组小小的参数
也能做到和下游任务适配
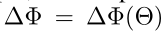
而此时需要调整的参数远远小于预训练模型的参数

也就是说此时需要调整的参数很小。
文章主要聚焦于将LoRA在transformer注意力机制上进行使用,因为这也是transformer的精髓
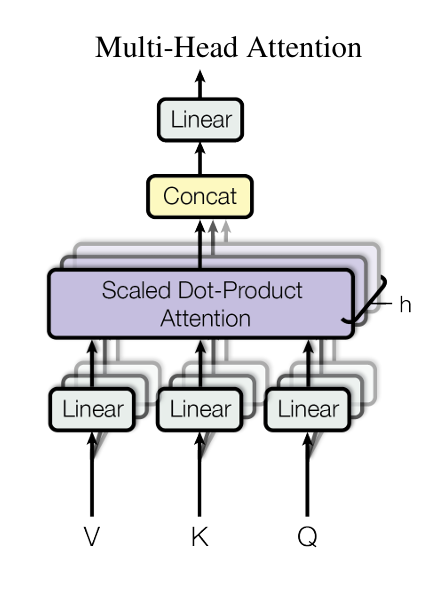
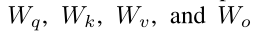
分别用于表示四个线性层的参数。
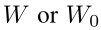
用于表示预训练模型的参数
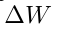
是自适应过程中的累积梯度更新
r就是低秩矩阵的秩
例如我们在
W上加个LoRA
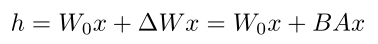
假设W0为512*512
就单单只看这部分的话
全参数微调需要调整512*512 = 262144个参数
使用LoRA后,这262144个参数就冻结了
此时增加两个低秩矩阵 例如512*2和2*512
那么此时需要调整的参数大小就为512*2+2*512 = 2048个参数
2048 / 262144 = 0.0078125
此时要训练的参数就减少了许多
而且,当我们面对不同的下游任务时,因为原本的预训练模型是冻结的,所以预训练模型用一个就行,只需要保存的参数就是加入的低秩矩阵,这样的话,也能节省大量的存储空间。
可以看个伪代码:
class LowRankMatrix(nn.Module):
def __init__(self, weight_matrix, rank, alpha=1.0):
super(LowRankMatrix, self).__init__()
self.weight_matrix = weight_matrix
self.rank = rank
self.alpha = alpha / rank # 将缩放因子与秩相关联
# 初始化低秩矩阵A和B
self.A = nn.Parameter(torch.randn(weight_matrix.size(0), rank), requires_grad=True)
self.B = nn.Parameter(torch.randn(rank, weight_matrix.size(1)), requires_grad=True)
def forward(self, x):
# 计算低秩矩阵的乘积并添加到原始权重上
# 应用缩放因子
updated_weight = self.weight_matrix + self.alpha * torch.mm(self.B.t(), self.A)
return updated_weight
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
α和r用于缩放矩阵,帮助更好的训练
A矩阵使用随机高斯初始化
B矩阵初始化为0
实验结果
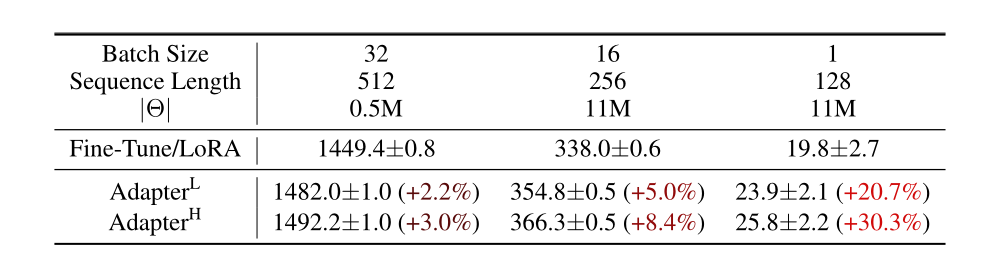
LoRA相较于Adapter不会显著增加推理的时间。
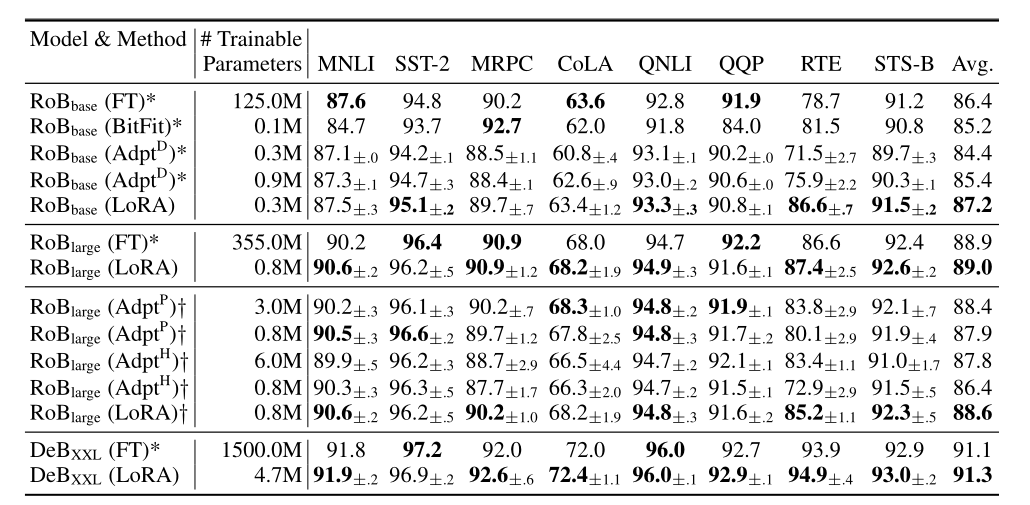
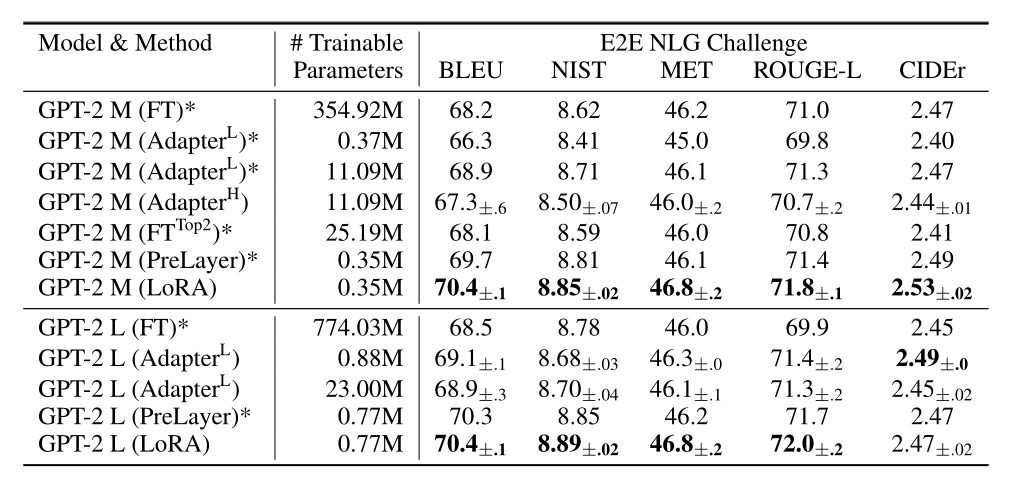
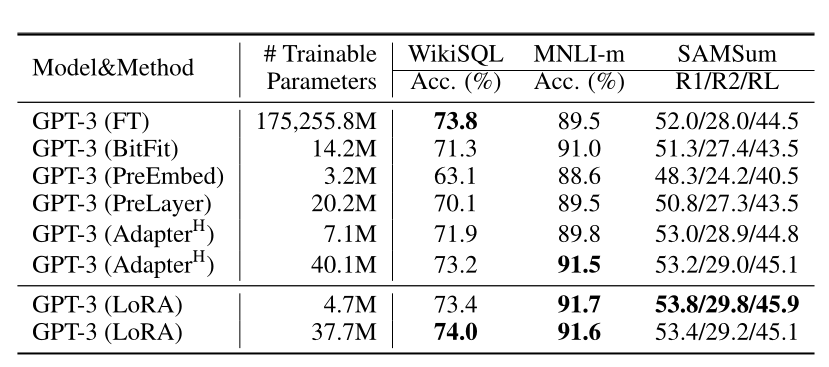
LoRA效果好
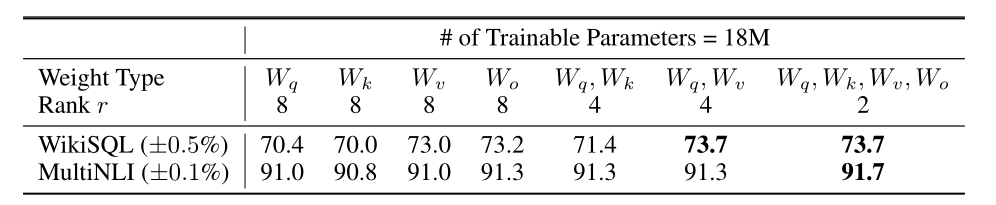
LoRA一起用到Wq和Wv效果比较好
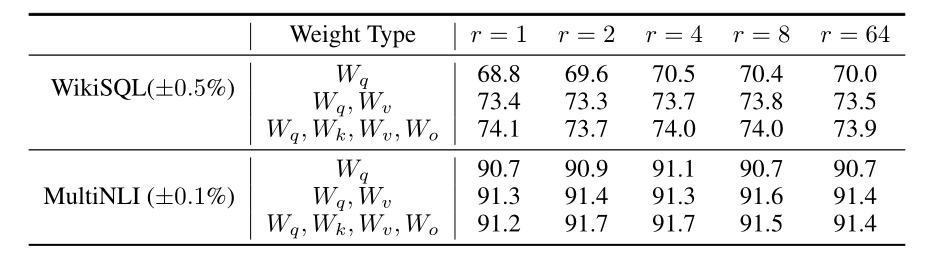
低秩已足够


