
热门标签
热门文章
- 1IO_总结
- 2mysql开启ssl_mysql ssl
- 3Elasticsearch7.6.x学习笔记(超详细)_es 7.6源码解析
- 4YOLOv7 | 注意力机制 | 添加ECA注意力机制_eca模块
- 5Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明_深度学习算法
- 6Flutter-Android签名打包,给小伙伴分享APP吧_flutter android签名打包
- 7C语言实现运动会分数统计_运动会分数统计系统c语言
- 8copy 修改时间_SCI论文审稿时间需要多久?
- 9n皇后问题(DFS)_比赛 题库 提交记录 hack! 博客 帮助 好评差评[-5] #58. n皇后问题百度翻译实时翻
- 10云原生存储:使用MinIO与Spring整合
当前位置: article > 正文
hadoop3 集群搭建_hadoop3 集群部署
作者:你好赵伟 | 2024-07-20 06:58:09
赞
踩
hadoop3 集群部署
1 环境准备
hadoop1 192.168.38.150 jdk1.8
hadoop2 192.168.38.151 jdk1.8
hadoop3 192.168.38.152 jdk1.8
- 1
- 2
- 3
2 环境准备
#3台
yum install ssh pdsh
#修改host
vim /etc/hosts
192.168.38.150 hadoop1
192.168.38.151 hadoop2
192.168.38.152 hadoop3
#修改主机名
hostnamectl set-hostname hadoop1
hostnamectl set-hostname hadoop2
hostnamectl set-hostname hadoop3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3 集群规划

4 解压配置环境变量
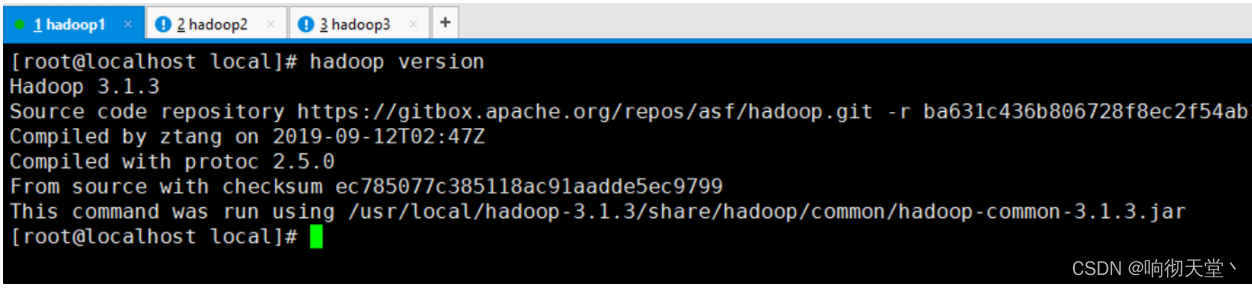
#3台解压 tar -zxvf hadoop-3.1.3.tar.gz #3台配置环境变量 vim /etc/profile export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_HOME=/usr/local/jdk1.8 export HADOOP_HOME=/usr/local/hadoop-3.1.3 export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile #查看是否配置成功 hadoop version

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5 免密登录
#hadoop 1 ssh-keygen -t rsa ssh-copy-id hadoop1 ssh-copy-id hadoop2 ssh-copy-id hadoop3 #hadoop 2 ssh-keygen -t rsa ssh-copy-id hadoop1 ssh-copy-id hadoop2 ssh-copy-id hadoop3 #hadoop 3 ssh-keygen -t rsa ssh-copy-id hadoop1 ssh-copy-id hadoop2 ssh-copy-id hadoop3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
6 配置core-site.xml
#3台 cd /usr/local/hadoop-3.1.3/etc/hadoop vim core-site.xml <configuration> <!-- 指定 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:8020</value> </property> <!-- 指定 hadoop 数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-3.1.3/data</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
7 配置hdfs-site.xml
#3台 vim hdfs-site.xml <configuration> <!-- NameNode web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop1:9870</value> </property> <!-- SecondNameNode web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop3:9868</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
8 配置yarn-site.xml
#3台 vim yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
9 配置 mapred-site.xml
#3台 vim mapred-site.xml <configuration> <!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
10 配置workers
#3台
vim workers
hadoop1
hadoop2
hadoop3
- 1
- 2
- 3
- 4
- 5
- 6
11 配置JAVA_HOME HADOOP_CONF_DIR
#3台
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.3/etc/hadoop
- 1
- 2
- 3
- 4
- 5
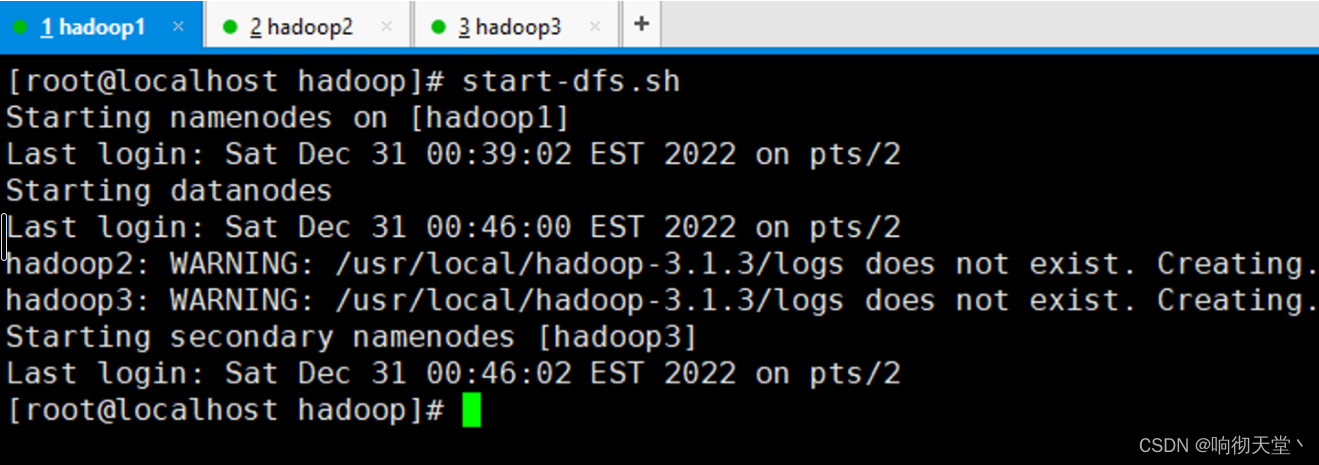
12 启动NameNode集群
#hadoop1 初始化(第一次需要初始化)
hdfs namenode -format
#hadoop01 启动集群
start-dfs.sh
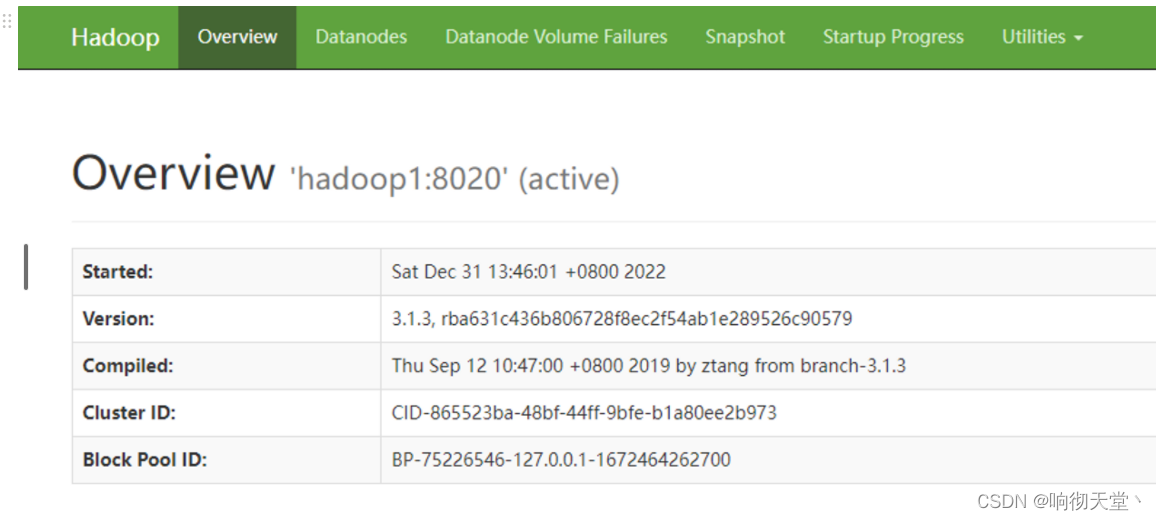
#访问页面
http://192.168.38.150:9870/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
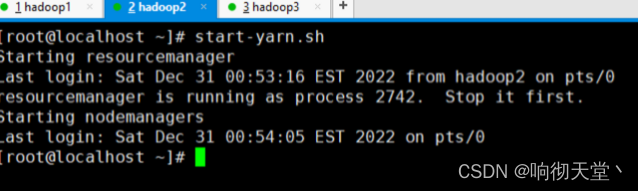
13 启动Yarn
## hadoop2上启动
start-yarn.sh
## 查看yarn
http://hadoop2:8088/
- 1
- 2
- 3
- 4
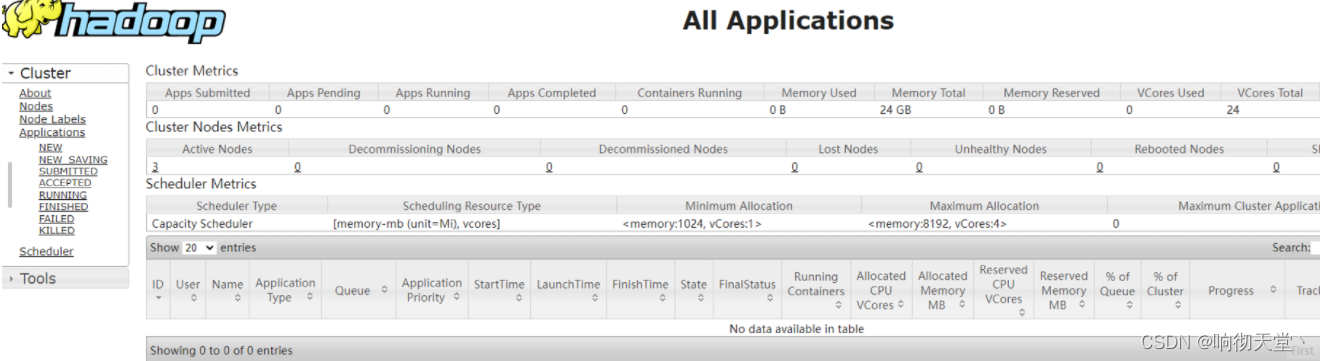
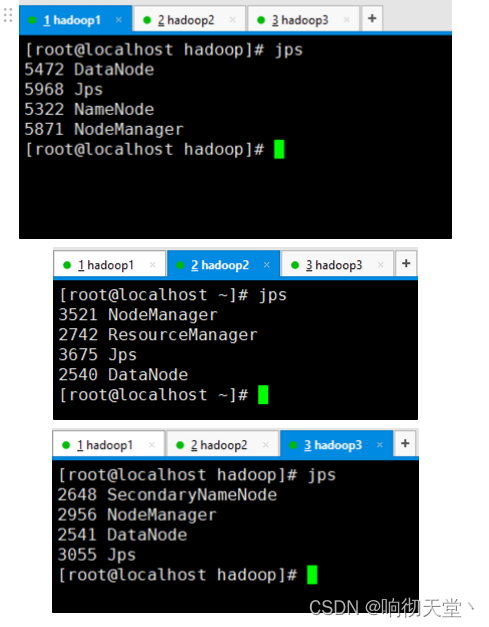
14 检查
jps
- 1
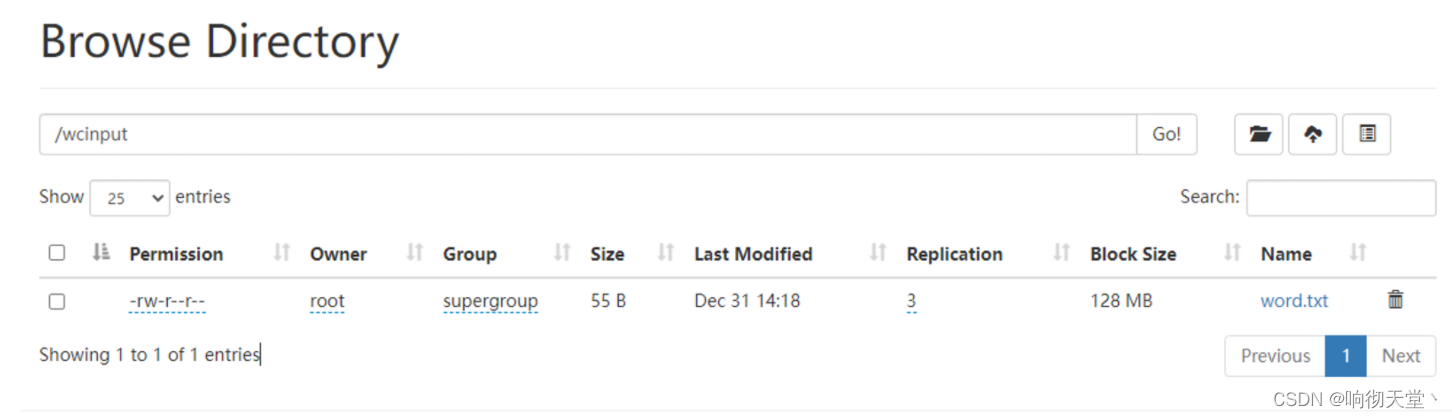
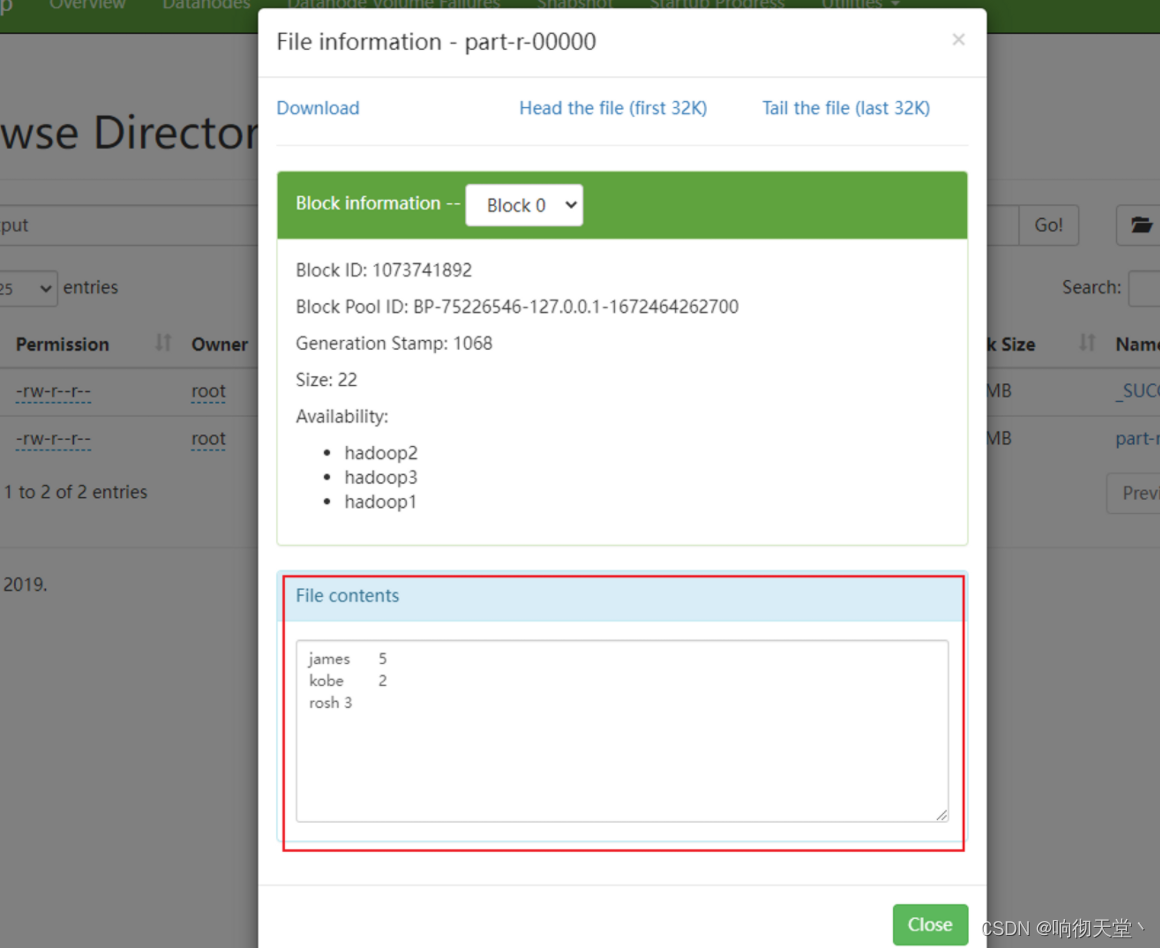
15 集群基本测试
#创建目录
hadoop fs -mkdir /wcinput
#上传小文件
hadoop fs -put ./word.txt /wcinput
#执行wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
- 1
- 2
- 3
- 4
- 5
- 6
- 7
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/855651
推荐阅读
相关标签

