
- 1python 文本分块_单独的文本块python
- 2MySql经典面试题(含表)_max(case c.c when '03' then b.score else null end)
- 3kafka 集成整合外部插件(springboot,flume,flink,spark)_springboot 整合spark、flink
- 4python3 read excel_关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
- 5Java 注释(Java Doc Comment)与注解(Annotation)_java注释和注解
- 6面试-JVM_jvm常量放在哪里
- 7服务器端身份证识别_两种基于服务器的身份证验证方式
- 8撰写论文时常用的研究方法有哪些?_文献研究法和案例分析法
- 9STM32学习笔记(江协科技)-----ADC模数转换
- 10【java】图书管理系统_java图书管理系统
详解贪心算法二
赞
踩
1:加油站
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
- 如果题目有解,该答案即为唯一答案。
- 输入数组均为非空数组,且长度相同。
- 输入数组中的元素均为非负数。
示例 1: 输入:
- gas = [1,2,3,4,5]
- cost = [3,4,5,1,2]
输出: 3 解释:
- 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
- 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
- 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
- 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
- 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
- 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
- 因此,3 可为起始索引。
示例 2: 输入:
-
gas = [2,3,4]
-
cost = [3,4,3]
-
输出: -1
-
解释: 你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油。开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油。开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油。你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。因此,无论怎样,你都不可能绕环路行驶一周。
#思路
首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,因为这个区间选择任何一个位置作为起点,到i这里都会断油,那么起始位置从i+1算起,再从0计算curSum。
如图:

那么为什么一旦[0,i] 区间和为负数,起始位置就可以是i+1呢,i+1后面就不会出现更大的负数?
如果出现更大的负数,就是更新i,那么起始位置又变成新的i+1了。
那有没有可能 [0,i] 区间 选某一个作为起点,累加到 i这里 curSum是不会小于零呢? 如图:
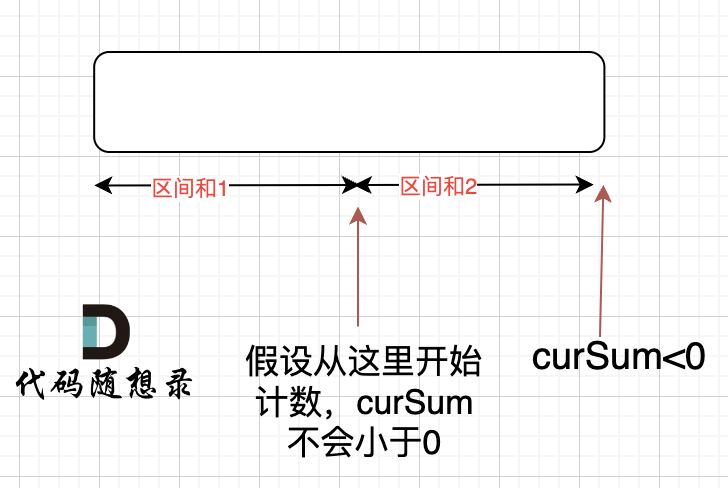
如果 curSum<0 说明 区间和1 + 区间和2 < 0, 那么 假设从上图中的位置开始计数curSum不会小于0的话,就是 区间和2>0。
区间和1 + 区间和2 < 0 同时 区间和2>0,只能说明区间和1 < 0, 那么就会从假设的箭头初就开始从新选择其实位置了。
那么局部最优:当前累加rest[i]的和curSum一旦小于0,起始位置至少要是i+1,因为从i之前开始一定不行。全局最优:找到可以跑一圈的起始位置。
局部最优可以推出全局最优,找不出反例,试试贪心!
C++代码如下:
- class Solution {
- public:
- int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
- int curSum = 0;
- int totalSum = 0;
- int start = 0;
- for (int i = 0; i < gas.size(); i++) {
- curSum += gas[i] - cost[i];
- totalSum += gas[i] - cost[i];
- if (curSum < 0) { // 当前累加rest[i]和 curSum一旦小于0
- start = i + 1; // 起始位置更新为i+1
- curSum = 0; // curSum从0开始
- }
- }
- if (totalSum < 0) return -1; // 说明怎么走都不可能跑一圈了
- return start;
- }
- };

- 时间复杂度:O(n)
- 空间复杂度:O(1)
说这种解法为贪心算法,才是有理有据的,因为全局最优解是根据局部最优推导出来的。
2:分发糖果
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
- 每个孩子至少分配到 1 个糖果。
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
- 输入: [1,0,2]
- 输出: 5
- 解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
- 输入: [1,2,2]
- 输出: 4
- 解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
思路
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,如果两边一起考虑一定会顾此失彼。
先确定右边评分大于左边的情况(也就是从前向后遍历)
此时局部最优:只要右边评分比左边大,右边的孩子就多一个糖果,全局最优:相邻的孩子中,评分高的右孩子获得比左边孩子更多的糖果
局部最优可以推出全局最优。
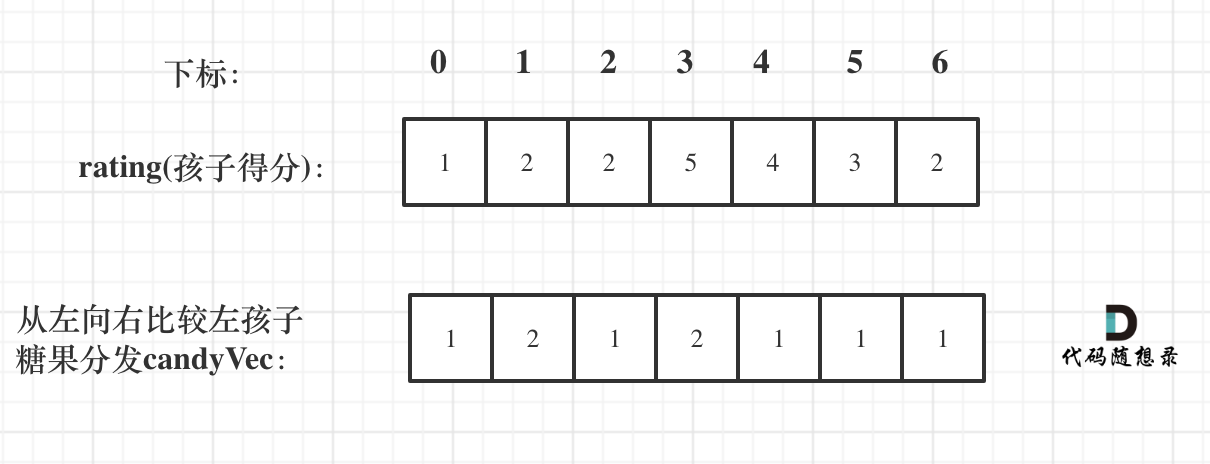
如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1
如图:
再确定左孩子大于右孩子的情况(从后向前遍历)
遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢?
因为 rating[5]与rating[4]的比较 要利用上 rating[5]与rating[6]的比较结果,所以 要从后向前遍历。
如果从前向后遍历,rating[5]与rating[4]的比较 就不能用上 rating[5]与rating[6]的比较结果了 。如图:

所以确定左孩子大于右孩子的情况一定要从后向前遍历!
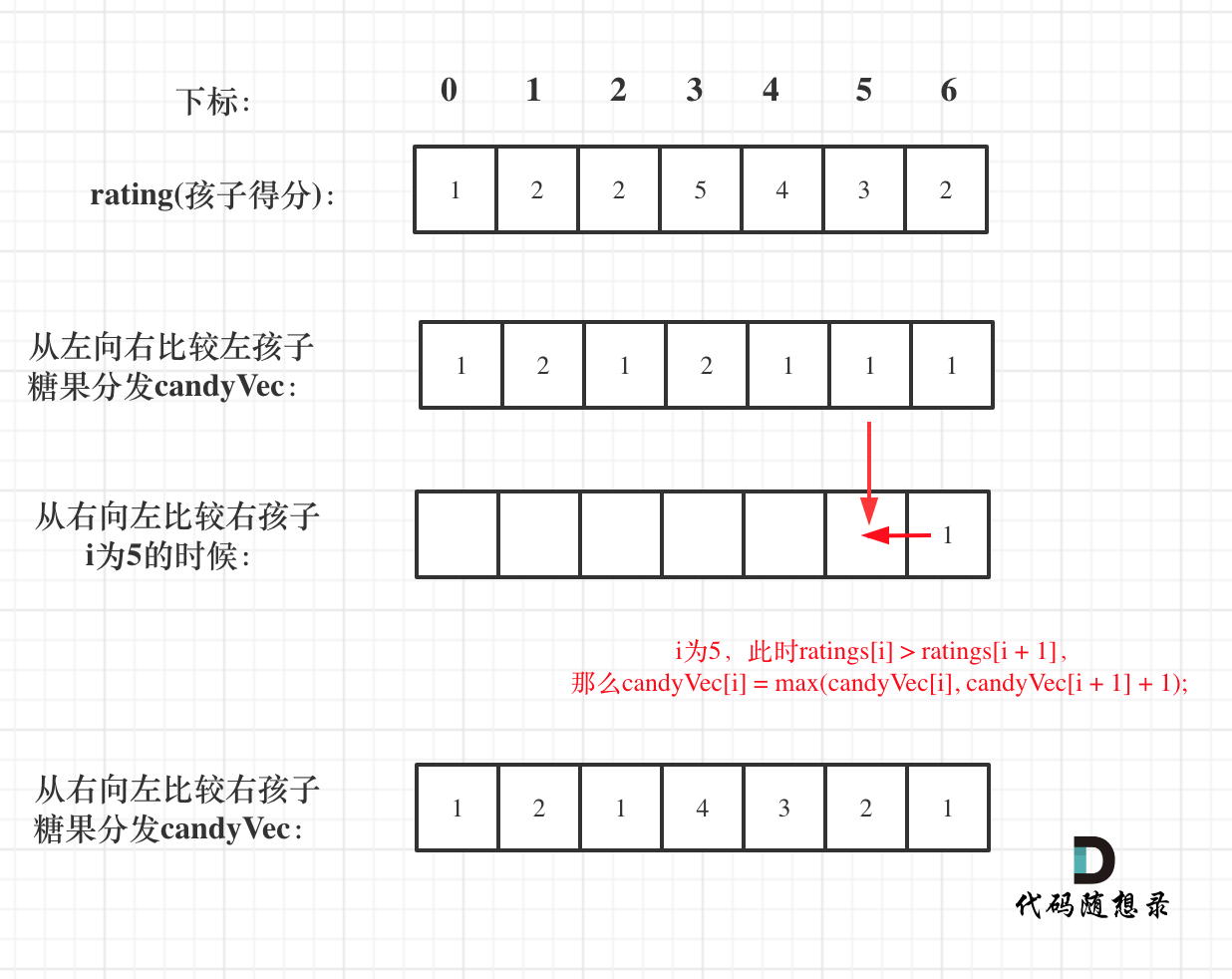
如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。
那么又要贪心了,局部最优:取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第i个小孩的糖果数量既大于左边的也大于右边的。全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
局部最优可以推出全局最优。
所以就取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多。
如图:
整体代码如下:
- class Solution {
- public:
- int candy(vector<int>& ratings) {
- vector<int> candyVec(ratings.size(), 1);
- // 从前向后
- for (int i = 1; i < ratings.size(); i++) {
- if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1;
- }
- // 从后向前
- for (int i = ratings.size() - 2; i >= 0; i--) {
- if (ratings[i] > ratings[i + 1] ) {
- candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1);
- }
- }
- // 统计结果
- int result = 0;
- for (int i = 0; i < candyVec.size(); i++) result += candyVec[i];
- return result;
- }
- };
- 时间复杂度: O(n)
- 空间复杂度: O(n)
3:柠檬水找零
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
- 输入:[5,5,5,10,20]
- 输出:true
- 解释:
- 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
- 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
- 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
- 由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
- 输入:[5,5,10]
- 输出:true
示例 3:
- 输入:[10,10]
- 输出:false
示例 4:
- 输入:[5,5,10,10,20]
- 输出:false
- 解释:
- 前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
- 对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
- 对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
- 由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
- 0 <= bills.length <= 10000
- bills[i] 不是 5 就是 10 或是 20
思路
这是前几天的leetcode每日一题,感觉不错,给大家讲一下。
这道题目刚一看,可能会有点懵,这要怎么找零才能保证完成全部账单的找零呢?
但仔细一琢磨就会发现,可供我们做判断的空间非常少!
只需要维护三种金额的数量,5,10和20。
有如下三种情况:
- 情况一:账单是5,直接收下。
- 情况二:账单是10,消耗一个5,增加一个10
- 情况三:账单是20,优先消耗一个10和一个5,如果不够,再消耗三个5
此时大家就发现 情况一,情况二,都是固定策略,都不用我们来做分析了,而唯一不确定的其实在情况三。
而情况三逻辑也不复杂甚至感觉纯模拟就可以了,其实情况三这里是有贪心的。
账单是20的情况,为什么要优先消耗一个10和一个5呢?
因为美元10只能给账单20找零,而美元5可以给账单10和账单20找零,美元5更万能!
所以局部最优:遇到账单20,优先消耗美元10,完成本次找零。全局最优:完成全部账单的找零。
局部最优可以推出全局最优,并找不出反例,那么就试试贪心算法!
C++代码如下:
- class Solution {
- public:
- bool lemonadeChange(vector<int>& bills) {
- int five = 0, ten = 0, twenty = 0;
- for (int bill : bills) {
- // 情况一
- if (bill == 5) five++;
- // 情况二
- if (bill == 10) {
- if (five <= 0) return false;
- ten++;
- five--;
- }
- // 情况三
- if (bill == 20) {
- // 优先消耗10美元,因为5美元的找零用处更大,能多留着就多留着
- if (five > 0 && ten > 0) {
- five--;
- ten--;
- twenty++; // 其实这行代码可以删了,因为记录20已经没有意义了,不会用20来找零
- } else if (five >= 3) {
- five -= 3;
- twenty++; // 同理,这行代码也可以删了
- } else return false;
- }
- }
- return true;
- }
- };
- 时间复杂度: O(n)
- 空间复杂度: O(1)
4:根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
- 输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
- 输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
- 解释:
- 编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
- 编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
- 编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
- 编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
- 编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
- 编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
- 因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
示例 2:
- 输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
- 输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
提示:
- 1 <= people.length <= 2000
- 0 <= hi <= 10^6
- 0 <= ki < people.length
题目数据确保队列可以被重建
思路
本题有两个维度,h和k,看到这种题目一定要想如何确定一个维度,然后再按照另一个维度重新排列。
其实如果大家认真做了135. 分发糖果
(opens new window),就会发现和此题有点点的像。
(opens new window)我就强调过一次,遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
如果两个维度一起考虑一定会顾此失彼。
对于本题相信大家困惑的点是先确定k还是先确定h呢,也就是究竟先按h排序呢,还是先按照k排序呢?
如果按照k来从小到大排序,排完之后,会发现k的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
那么按照身高h来排序呢,身高一定是从大到小排(身高相同的话则k小的站前面),让高个子在前面。
此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!
那么只需要按照k为下标重新插入队列就可以了,为什么呢?
以图中{5,2} 为例:

按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
所以在按照身高从大到小排序后:
局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性
全局最优:最后都做完插入操作,整个队列满足题目队列属性
局部最优可推出全局最优,找不出反例,那就试试贪心。
一些同学可能也会疑惑,你怎么知道局部最优就可以推出全局最优呢? 有数学证明么?
在贪心系列开篇词关于贪心算法,你该了解这些!
(opens new window)中,我已经讲过了这个问题了。
刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心,至于严格的数学证明,就不在讨论范围内了。
如果没有读过关于贪心算法,你该了解这些!
(opens new window)的同学建议读一下,相信对贪心就有初步的了解了。
回归本题,整个插入过程如下:
排序完的people: [[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
- 插入[7,0]:[[7,0]]
- 插入[7,1]:[[7,0],[7,1]]
- 插入[6,1]:[[7,0],[6,1],[7,1]]
- 插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
- 插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
- 插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
此时就按照题目的要求完成了重新排列。
C++代码如下:
- // 版本一
- class Solution {
- public:
- static bool cmp(const vector<int>& a, const vector<int>& b) {
- if (a[0] == b[0]) return a[1] < b[1];
- return a[0] > b[0];
- }
- vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
- sort (people.begin(), people.end(), cmp);
- vector<vector<int>> que;
- for (int i = 0; i < people.size(); i++) {
- int position = people[i][1];
- que.insert(que.begin() + position, people[i]);
- }
- return que;
- }
- };
- 时间复杂度:O(nlog n + n^2)
- 空间复杂度:O(n)
但使用vector是非常费时的,C++中vector(可以理解是一个动态数组,底层是普通数组实现的)如果插入元素大于预先普通数组大小,vector底部会有一个扩容的操作,即申请两倍于原先普通数组的大小,然后把数据拷贝到另一个更大的数组上。
所以使用vector(动态数组)来insert,是费时的,插入再拷贝的话,单纯一个插入的操作就是O(n^2)了,甚至可能拷贝好几次,就不止O(n^2)了。
改成链表之后,C++代码如下:
- // 版本二
- class Solution {
- public:
- // 身高从大到小排(身高相同k小的站前面)
- static bool cmp(const vector<int>& a, const vector<int>& b) {
- if (a[0] == b[0]) return a[1] < b[1];
- return a[0] > b[0];
- }
- vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
- sort (people.begin(), people.end(), cmp);
- list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
- for (int i = 0; i < people.size(); i++) {
- int position = people[i][1]; // 插入到下标为position的位置
- std::list<vector<int>>::iterator it = que.begin();
- while (position--) { // 寻找在插入位置
- it++;
- }
- que.insert(it, people[i]);
- }
- return vector<vector<int>>(que.begin(), que.end());
- }
- };
- 时间复杂度:O(nlog n + n^2)
- 空间复杂度:O(n)
大家可以把两个版本的代码提交一下试试,就可以发现其差别了!
5:用最少数量的剑引爆气球
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
- 输入:points = [[10,16],[2,8],[1,6],[7,12]]
- 输出:2
- 解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
示例 2:
- 输入:points = [[1,2],[3,4],[5,6],[7,8]]
- 输出:4
示例 3:
- 输入:points = [[1,2],[2,3],[3,4],[4,5]]
- 输出:2
示例 4:
- 输入:points = [[1,2]]
- 输出:1
示例 5:
- 输入:points = [[2,3],[2,3]]
- 输出:1
提示:
- 0 <= points.length <= 10^4
- points[i].length == 2
- -2^31 <= xstart < xend <= 2^31 - 1
思路
如何使用最少的弓箭呢?
直觉上来看,貌似只射重叠最多的气球,用的弓箭一定最少,那么有没有当前重叠了三个气球,我射两个,留下一个和后面的一起射这样弓箭用的更少的情况呢?
尝试一下举反例,发现没有这种情况。
那么就试一试贪心吧!局部最优:当气球出现重叠,一起射,所用弓箭最少。全局最优:把所有气球射爆所用弓箭最少。
算法确定下来了,那么如何模拟气球射爆的过程呢?是在数组中移除元素还是做标记呢?
如果真实的模拟射气球的过程,应该射一个,气球数组就remove一个元素,这样最直观,毕竟气球被射了。
但仔细思考一下就发现:如果把气球排序之后,从前到后遍历气球,被射过的气球仅仅跳过就行了,没有必要让气球数组remove气球,只要记录一下箭的数量就可以了。
以上为思考过程,已经确定下来使用贪心了,那么开始解题。
为了让气球尽可能的重叠,需要对数组进行排序。
那么按照气球起始位置排序,还是按照气球终止位置排序呢?
其实都可以!只不过对应的遍历顺序不同,我就按照气球的起始位置排序了。
既然按照起始位置排序,那么就从前向后遍历气球数组,靠左尽可能让气球重复。
从前向后遍历遇到重叠的气球了怎么办?
如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭。
以题目示例: [[10,16],[2,8],[1,6],[7,12]]为例,如图:(方便起见,已经排序)
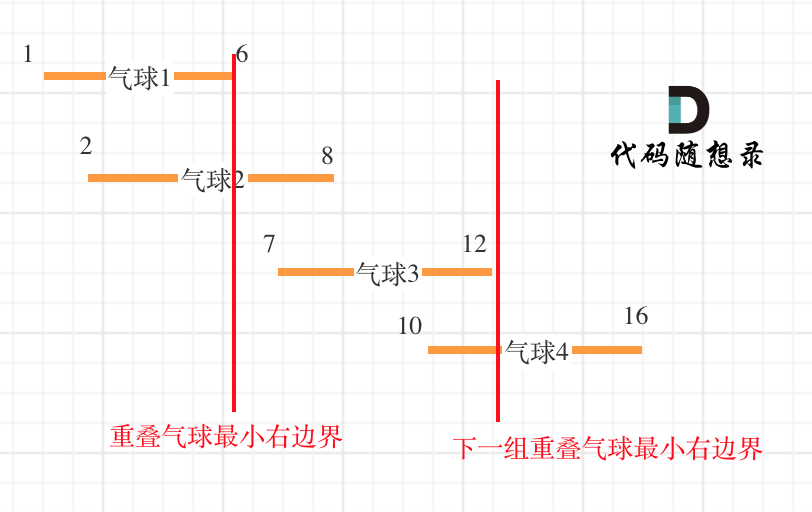
可以看出首先第一组重叠气球,一定是需要一个箭,气球3,的左边界大于了 第一组重叠气球的最小右边界,所以再需要一支箭来射气球3了。
C++代码如下:
- class Solution {
- private:
- static bool cmp(const vector<int>& a, const vector<int>& b) {
- return a[0] < b[0];
- }
- public:
- int findMinArrowShots(vector<vector<int>>& points) {
- if (points.size() == 0) return 0;
- sort(points.begin(), points.end(), cmp);
-
- int result = 1; // points 不为空至少需要一支箭
- for (int i = 1; i < points.size(); i++) {
- if (points[i][0] > points[i - 1][1]) { // 气球i和气球i-1不挨着,注意这里不是>=
- result++; // 需要一支箭
- }
- else { // 气球i和气球i-1挨着
- points[i][1] = min(points[i - 1][1], points[i][1]); // 更新重叠气球最小右边界
- }
- }
- return result;
- }
- };
- 时间复杂度:O(nlog n),因为有一个快排
- 空间复杂度:O(1),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
可以看出代码并不复杂。
# 注意事项
注意题目中说的是:满足 xstart ≤ x ≤ xend,则该气球会被引爆。那么说明两个气球挨在一起不重叠也可以一起射爆,
所以代码中 if (points[i][0] > points[i - 1][1]) 不能是>=
6:无重叠区间
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
- 输入: [ [1,2], [2,3], [3,4], [1,3] ]
- 输出: 1
- 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
- 输入: [ [1,2], [1,2], [1,2] ]
- 输出: 2
- 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
- 输入: [ [1,2], [2,3] ]
- 输出: 0
- 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
思路
相信很多同学看到这道题目都冥冥之中感觉要排序,但是究竟是按照右边界排序,还是按照左边界排序呢?
其实都可以。主要就是为了让区间尽可能的重叠。
我来按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了。
此时问题就是要求非交叉区间的最大个数。
这里记录非交叉区间的个数还是有技巧的,如图:
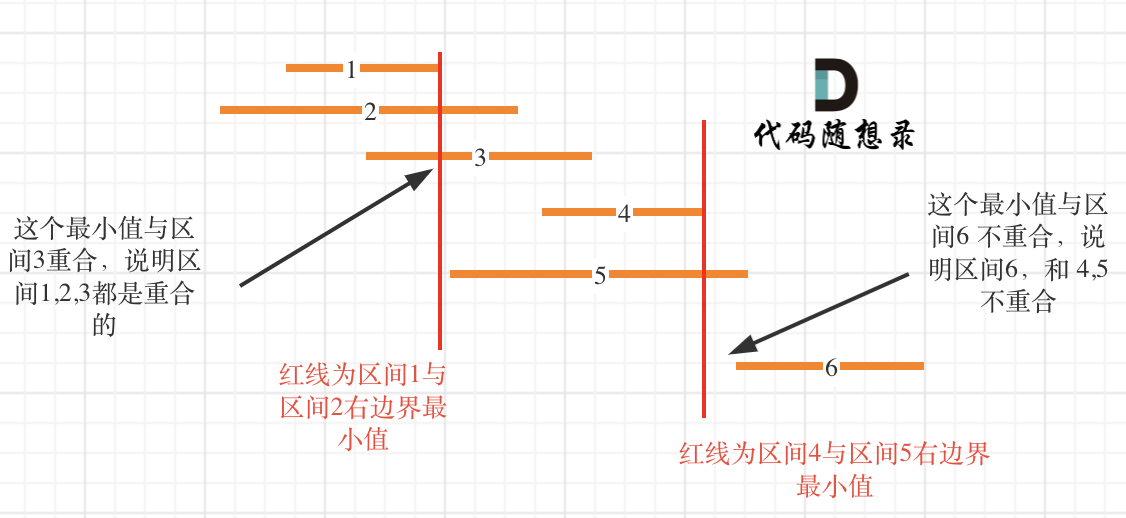
区间,1,2,3,4,5,6都按照右边界排好序。
当确定区间 1 和 区间2 重叠后,如何确定是否与 区间3 也重贴呢?
就是取 区间1 和 区间2 右边界的最小值,因为这个最小值之前的部分一定是 区间1 和区间2 的重合部分,如果这个最小值也触达到区间3,那么说明 区间 1,2,3都是重合的。
接下来就是找大于区间1结束位置的区间,是从区间4开始。那有同学问了为什么不从区间5开始?别忘了已经是按照右边界排序的了。
区间4结束之后,再找到区间6,所以一共记录非交叉区间的个数是三个。
总共区间个数为6,减去非交叉区间的个数3。移除区间的最小数量就是3。
C++代码如下:
- class Solution {
- public:
- // 按照区间右边界排序
- static bool cmp (const vector<int>& a, const vector<int>& b) {
- return a[1] < b[1];
- }
- int eraseOverlapIntervals(vector<vector<int>>& intervals) {
- if (intervals.size() == 0) return 0;
- sort(intervals.begin(), intervals.end(), cmp);
- int count = 1; // 记录非交叉区间的个数
- int end = intervals[0][1]; // 记录区间分割点
- for (int i = 1; i < intervals.size(); i++) {
- if (end <= intervals[i][0]) {
- end = intervals[i][1];
- count++;
- }
- }
- return intervals.size() - count;
- }
- };
- 时间复杂度:O(nlog n) ,有一个快排
- 空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
大家此时会发现如此复杂的一个问题,代码实现却这么简单!
# 补充(1)
左边界排序可不可以呢?
也是可以的,只不过 左边界排序我们就是直接求 重叠的区间,count为记录重叠区间数。
- class Solution {
- public:
- static bool cmp (const vector<int>& a, const vector<int>& b) {
- return a[0] < b[0]; // 改为左边界排序
- }
- int eraseOverlapIntervals(vector<vector<int>>& intervals) {
- if (intervals.size() == 0) return 0;
- sort(intervals.begin(), intervals.end(), cmp);
- int count = 0; // 注意这里从0开始,因为是记录重叠区间
- int end = intervals[0][1]; // 记录区间分割点
- for (int i = 1; i < intervals.size(); i++) {
- if (intervals[i][0] >= end) end = intervals[i][1]; // 无重叠的情况
- else { // 重叠情况
- end = min(end, intervals[i][1]);
- count++;
- }
- }
- return count;
- }
- };
其实代码还可以精简一下, 用 intervals[i][1] 替代 end变量,只判断 重叠情况就好
- class Solution {
- public:
- static bool cmp (const vector<int>& a, const vector<int>& b) {
- return a[0] < b[0]; // 改为左边界排序
- }
- int eraseOverlapIntervals(vector<vector<int>>& intervals) {
- if (intervals.size() == 0) return 0;
- sort(intervals.begin(), intervals.end(), cmp);
- int count = 0; // 注意这里从0开始,因为是记录重叠区间
- for (int i = 1; i < intervals.size(); i++) {
- if (intervals[i][0] < intervals[i - 1][1]) { //重叠情况
- intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]);
- count++;
- }
- }
- return count;
- }
- };
-
# 补充(2)
本题其实和上一题非常像,弓箭的数量就相当于是非交叉区间的数量,只要把弓箭那道题目代码里射爆气球的判断条件加个等号(认为[0,1][1,2]不是相邻区间),然后用总区间数减去弓箭数量 就是要移除的区间数量了。
把代码稍做修改,就可以AC本题。
- class Solution {
- public:
- // 按照区间右边界排序
- static bool cmp (const vector<int>& a, const vector<int>& b) {
- return a[1] < b[1]; // 右边界排序
- }
- int eraseOverlapIntervals(vector<vector<int>>& intervals) {
- if (intervals.size() == 0) return 0;
- sort(intervals.begin(), intervals.end(), cmp);
-
- int result = 1; // points 不为空至少需要一支箭
- for (int i = 1; i < intervals.size(); i++) {
- if (intervals[i][0] >= intervals[i - 1][1]) {
- result++; // 需要一支箭
- }
- else { // 气球i和气球i-1挨着
- intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]); // 更新重叠气球最小右边界
- }
- }
- return intervals.size() - result;
- }
- };
这里按照 左边界排序,或者按照右边界排序,都可以AC,原理是一样的。
- class Solution {
- public:
- // 按照区间左边界排序
- static bool cmp (const vector<int>& a, const vector<int>& b) {
- return a[0] < b[0]; // 左边界排序
- }
- int eraseOverlapIntervals(vector<vector<int>>& intervals) {
- if (intervals.size() == 0) return 0;
- sort(intervals.begin(), intervals.end(), cmp);
-
- int result = 1; // points 不为空至少需要一支箭
- for (int i = 1; i < intervals.size(); i++) {
- if (intervals[i][0] >= intervals[i - 1][1]) {
- result++; // 需要一支箭
- }
- else { // 气球i和气球i-1挨着
- intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]); // 更新重叠气球最小右边界
- }
- }
- return intervals.size() - result;
- }
- };
-
7:划分字母区间
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
- 输入:S = "ababcbacadefegdehijhklij"
- 输出:[9,7,8] 解释: 划分结果为 "ababcbaca", "defegde", "hijhklij"。 每个字母最多出现在一个片段中。 像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
提示:
- S的长度在[1, 500]之间。
- S只包含小写字母 'a' 到 'z' 。
思路
一想到分割字符串就想到了回溯,但本题其实不用回溯去暴力搜索。
题目要求同一字母最多出现在一个片段中,那么如何把同一个字母的都圈在同一个区间里呢?
如果没有接触过这种题目的话,还挺有难度的。
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
可以分为如下两步:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
如图:
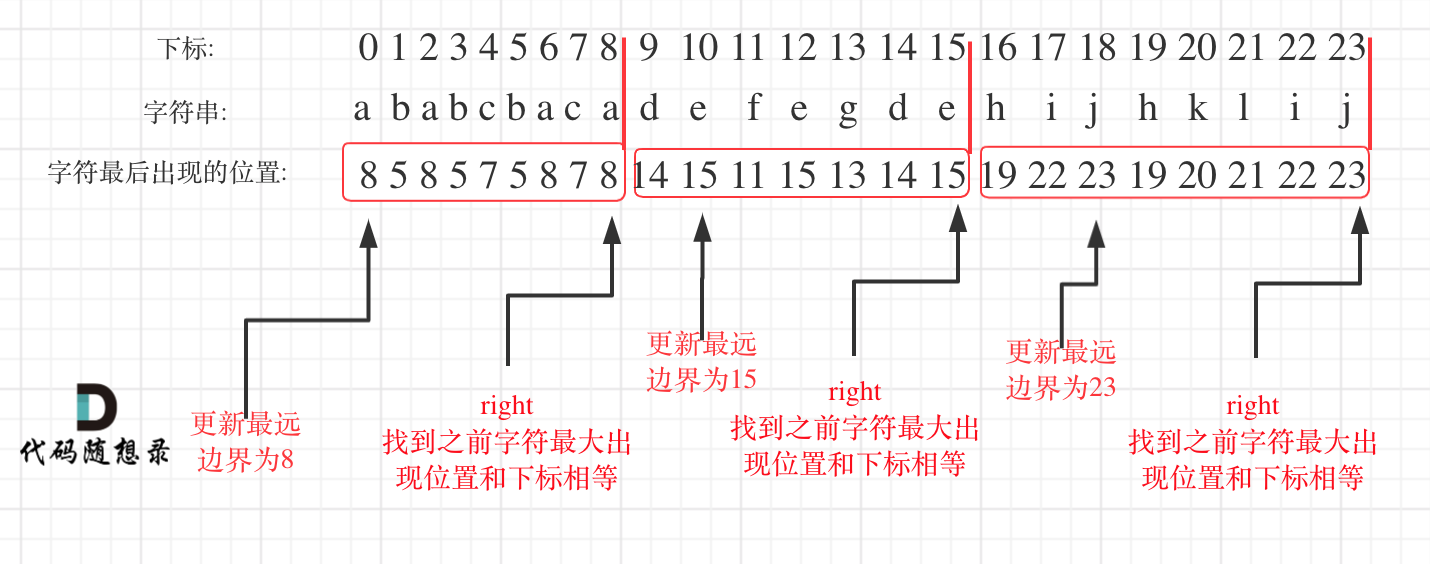
明白原理之后,代码并不复杂,
C++代码如下:
- class Solution {
- public:
- vector<int> partitionLabels(string S) {
- int hash[27] = {0}; // i为字符,hash[i]为字符出现的最后位置
- for (int i = 0; i < S.size(); i++) { // 统计每一个字符最后出现的位置
- hash[S[i] - 'a'] = i;
- }
- vector<int> result;
- int left = 0;
- int right = 0;
- for (int i = 0; i < S.size(); i++) {
- right = max(right, hash[S[i] - 'a']); // 找到字符出现的最远边界
- if (i == right) {
- result.push_back(right - left + 1);
- left = i + 1;
- }
- }
- return result;
- }
- };
- 时间复杂度:O(n)
- 空间复杂度:O(1),使用的hash数组是固定大小

