
- 1QThread实现TCP通信的多线程实例_qt启动线程执行tcp接收数据
- 2in的绑定 mysql_WHERE IN子句与PDO的绑定参数?mysql
- 3RabbitMQ之Exchange、Queue参数详解_rabbitmq queue type
- 4IDEA如何运行SpringBoot+Vue前后端分离的项目(超详细截图)_怎么用idea运行前后端项目
- 5OpenCV编译CUDA模块face_landmark_model.dat下载失败的解决方法
- 6【QML初学者文档】一问读懂QML基础开发(内附大量简单源码)
- 7anaconda瘦身_anaconda 瘦身
- 8【JAVA】Web服务器—Tomcat_java web服务器
- 9【STA】常用约束指令学习记录
- 10[AIGC] Kafka 消费者的实现原理
XGBoost模型调参、训练、保存、评估和预测_xgboost训练
赞
踩
XGBoost在二分类问题中的使用
一.前期准备工作
1.1工具包和参数的简单说明
本文中脚本编写时使用的库版本如下,scikit-learn==0.24.1 、xgboost==1.6.1 、graphviz==0.20.1、pandas==1.2.4,如果使用中碰到问题,分别执行下方pip命令重新安装库即可
# 查看安装库版本 pip list 显示所有库及对应版本
pip list | find "scikit-learn"
# 卸载当前库,卸载非必须操作,不卸载可以直接覆盖
pip uninstall scikit-learn
# 使用清华园镜像安装对应版本库
pip install scikit-learn==0.24.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install xgboost==1.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install graphviz==0.20.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install pandas==1.2.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
xgboost的XGBClassifier方法是分类模型,具体模型参数见xgboost官网参数(default);
sklearn.model_selection的GridSearchCV是用来调参的方法;
sklearn.metrics的ccuracy_score, roc_auc_score, f1_score做分类问题的评分指标,其他指标见官网sklearn评估指标(Metrics);
""" xgboost模型调参、训练、保存、预测 官网信息辅助理解: xgboost官网参数(default) https://xgboost.readthedocs.io/en/latest/parameter.html#general-parameters sklearn评估指标(Metrics) https://scikit-learn.org/stable/modules/model_evaluation.html """ import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.metrics import accuracy_score, roc_auc_score, f1_score import xgboost as xgb from xgboost import XGBClassifier, plot_importance import warnings warnings.filterwarnings('ignore') plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.sans-serif'] = ['SimHei']

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
1.2划分训练集和验证集
百度网盘提取数据和完整脚本(提取码:54ul)无论训练集、验证集还是测试集,输入的数据都是数值型。XGBoost本身无法处理定性数据(分类数据和顺序数据),而是像随机森林一样,只接受定量数据。因此训练和测试数据必须通过各种编码方式:例如标记编码、均值编码或独热编码对数据进行处理。
# 数据集
dataset = pd.read_csv('Oil_well_parameters_train.csv', engine='python')
# 划分训练集和验证集
X_train, X_test, y_train, y_test = train_test_split(dataset.iloc[:, :-1], dataset.iloc[:, -1], test_size=0.2,
random_state=42)
- 1
- 2
- 3
- 4
- 5
二.模型调参
调参策略:逐个或逐类参数调整,避免所有参数一起调整导致模型复杂度过高。因此,调参过程分多步进行,每次调整相同类型的参数。
2.1调参示例
假设第一步n_estimators迭代次数已调参完毕,最佳参数为50,进行第二部调参演示,其余调参步骤按步进行,每次将确认好的最佳参数添加到fine_params字典中。
def xgboost_parameters():
"""模型调参过程"""
# 第二步:min_child_weight 以及 max_depth
# 参数的最佳取值:{'max_depth': 2, 'min_child_weight': 1}
# 最佳模型得分:0.9180952380952381,模型分数未提高
params = {'max_depth': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'min_child_weight': [1, 2, 3, 4, 5, 6]}
# 其他参数设置,每次调参将确定的参数加入,不写即默认参数
fine_params = {'n_estimators': 50}
return params, fine_params
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
模型调参过程会输出每个组合的平均得分值。根据GridSearchCV参数指定使用roc_auc为评分指标,进行cv=5 5折交叉验证,返回的平均得分即为5折交叉验证auc值的平均值。
def model_adjust_parameters(cv_params, other_params): """模型调参""" # 模型基本参数 model = XGBClassifier(**other_params) # sklearn提供的调参工具,训练集k折交叉验证 optimized_param = GridSearchCV(estimator=model, param_grid=cv_params, scoring='roc_auc', cv=5, verbose=1) # 模型训练 optimized_param.fit(X_train, y_train) # 对应参数的k折交叉验证平均得分 means = optimized_param.cv_results_['mean_test_score'] params = optimized_param.cv_results_['params'] for mean, param in zip(means, params): print("mean_score: %f, params: %r" % (mean, param)) # 最佳模型参数 print('参数的最佳取值:{0}'.format(optimized_param.best_params_)) # 最佳参数模型得分 print('最佳模型得分:{0}'.format(optimized_param.best_score_)) # 模型参数调整得分变化曲线绘制 parameters_score = pd.DataFrame(params, means) parameters_score['means_score'] = parameters_score.index parameters_score = parameters_score.reset_index(drop=True) parameters_score.to_excel('parameters_score.xlsx', index=False) # 画图 plt.figure(figsize=(15, 12)) plt.subplot(2, 1, 1) plt.plot(parameters_score.iloc[:, :-1], 'o-') plt.legend(parameters_score.columns.to_list()[:-1], loc='upper left') plt.title('Parameters_size', loc='left', fontsize='xx-large', fontweight='heavy') plt.subplot(2, 1, 2) plt.plot(parameters_score.iloc[:, -1], 'r+-') plt.legend(parameters_score.columns.to_list()[-1:], loc='upper left') plt.title('Score', loc='left', fontsize='xx-large', fontweight='heavy') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
调用自定义的调参函数进行调参,根据model_adjust_parameters设定会打印调参信息并画图辅助判断
if __name__ == '__main__':
"""
模型调参
调参策略:网格搜索、随机搜索、启发式搜索
补充:此处采用启发式搜索,逐个或逐类参数调整,避免所有参数一起调整导致模型训练复杂度过高
"""
# xgboost参数组合
adj_params, fixed_params = xgboost_parameters()
# 模型调参
model_adjust_parameters(adj_params, fixed_params)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
返回参数组合及对应的模型得分
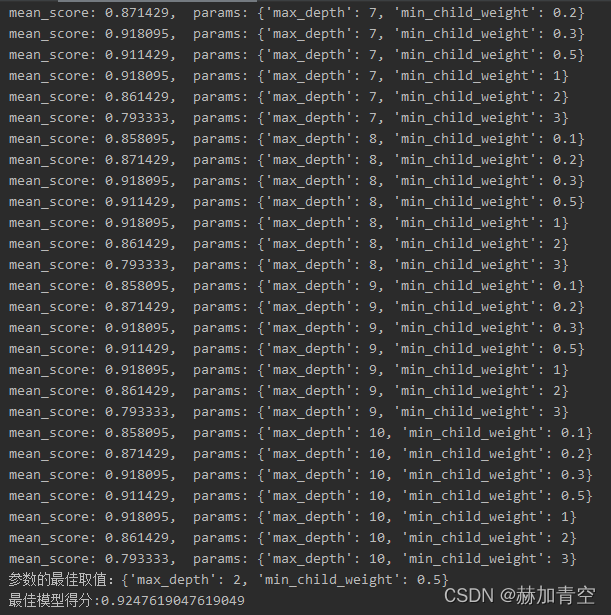
根据图可以清晰观察到随着min_child_weight的变大,得分值减小,所以可以重新设定参数取值,重新执行调参过程。
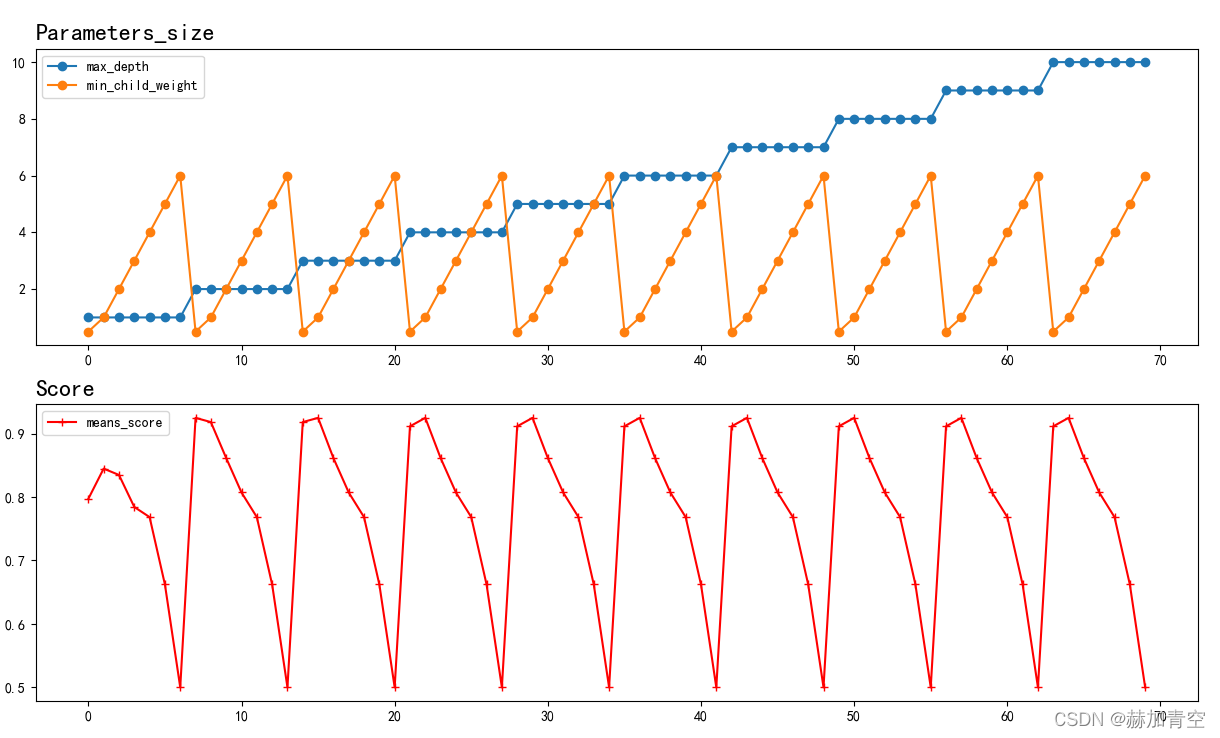
2.2详细的调参过程
每次记录最佳参数及其模型得分,便于对比提升度。具体参数需要根据实际项目手动调整,当最佳参数处于最大最小值时,需要扩大参数范围。
gamma[default=0, alias: min_split_loss]指定节点分裂所需的最小损失下降值,取值范围: [0,∞],值越大,算法越保守。
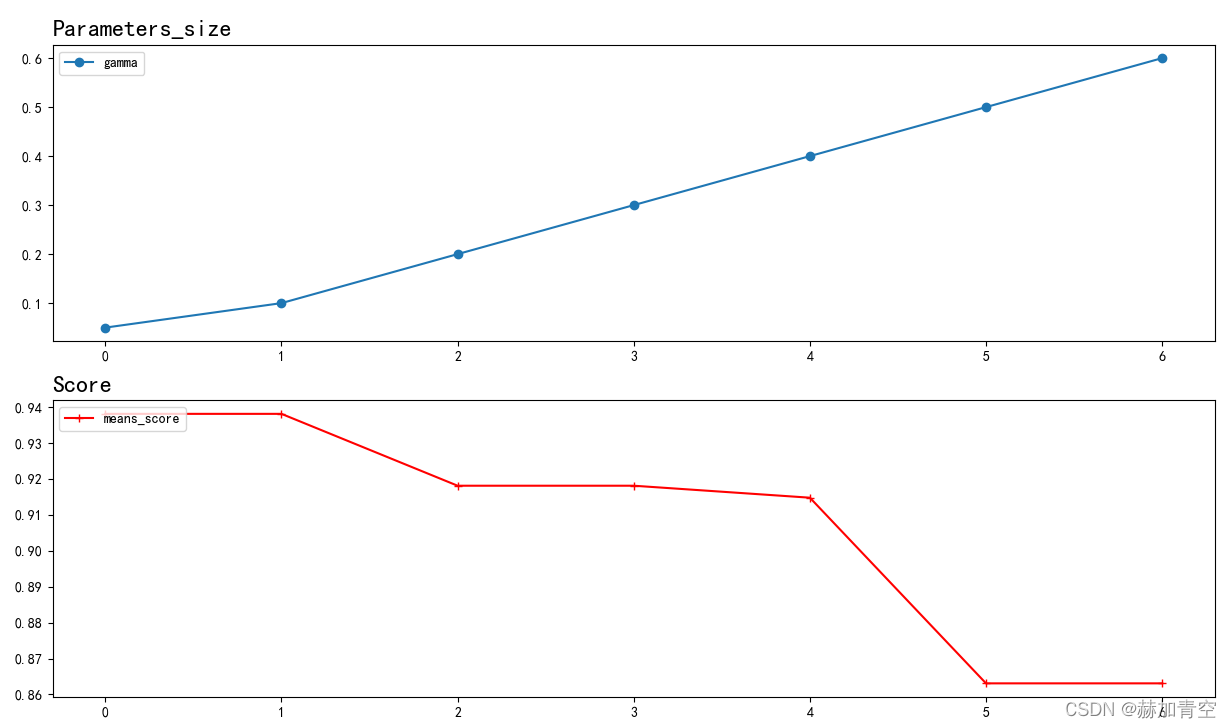
params = {'gamma': [0.1, 0.3, 0.4, 0.5, 0.6]}时最佳参数若为{'gamma': 0.1},则需要调整params = {'gamma': [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6]},由返回信息和图可观察到gamma=0.05和gamma=0.1模型得分一致,即可确定最佳参数gamma=0.1(也可更细划分),否则仍需调整参数继续训练。
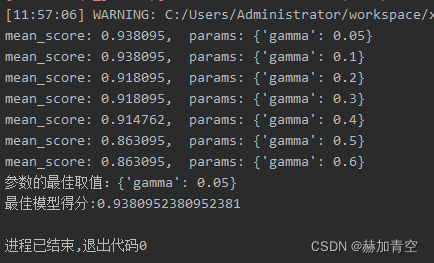
图像绘制结果,便于观察参数变化带来的模型效果走势
下方代码为参数迭代调整过程,每次将确认好的最佳参数添加到fine_params字典中,然后进行其余参数调参。
def xgboost_parameters(): """模型调参过程""" # 第一步:确定迭代次数 n_estimators # 参数的最佳取值:{'n_estimators': 50} # 最佳模型得分:0.9180952380952381 # params = {'n_estimators': [5, 10, 50, 75, 100, 200]} # 第二步:min_child_weight[default=1],range: [0,∞] 和 max_depth[default=6],range: [0,∞] # min_child_weight:如果树分区步骤导致叶节点的实例权重之和小于min_child_weight,那么构建过程将放弃进一步的分区,最小子权重越大,算法就越保守 # max_depth:树的最大深度,增加该值将使模型更复杂,更可能过度拟合,0表示深度没有限制 # 参数的最佳取值:{'max_depth': 2, 'min_child_weight': 1} # 最佳模型得分:0.9180952380952381,模型分数未提高 # params = {'max_depth': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'min_child_weight': [1, 2, 3, 4, 5, 6]} # 第三步:gamma[default=0, alias: min_split_loss],range: [0,∞] # gamma:在树的叶子节点上进行进一步分区所需的最小损失下降,gamma越大,算法就越保守 # 参数的最佳取值:{'gamma': 0.1} # 最佳模型得分:0.9247619047619049 # params = {'gamma': [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6]} # 第四步:subsample[default=1],range: (0,1] 和 colsample_bytree[default=1],range: (0,1] # subsample:训练实例的子样本比率。将其设置为0.5意味着XGBoost将在种植树木之前随机抽样一半的训练数据。这将防止过度安装。每一次提升迭代中都会进行一次子采样。 # colsample_bytree:用于列的子采样的参数,用来控制每颗树随机采样的列数的占比。有利于满足多样性要求,避免过拟合 # 参数的最佳取值:{'colsample_bytree': 1, 'subsample': 1} # 最佳模型得分:0.9247619047619049, 无提高即默认值 # params = {'subsample': [0.6, 0.7, 0.8, 0.9, 1], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9, 1]} # 第五步:alpha[default=0, alias: reg_alpha], 和 lambda[default=1, alias: reg_lambda] # alpha:L1关于权重的正则化项。增加该值将使模型更加保守 # lambda:关于权重的L2正则化项。增加该值将使模型更加保守 # 参数的最佳取值:{'reg_alpha': 0.01, 'reg_lambda': 3} # 最佳模型得分:0.9380952380952381 # params = {'alpha': [0.01, 0.02, 0.03, 0.04, 0.05, 0.1, 1, 2, 3], 'lambda': [0.05, 0.1, 1, 2, 3, 4]} # 第六步:learning_rate[default=0.3, alias: eta],range: [0,1] # learning_rate:一般这时候要调小学习率来测试,学习率越小训练速度越慢,模型可靠性越高,但并非越小越好 # 参数的最佳取值:{'learning_rate': 0.3} # 最佳模型得分:0.9380952380952381, 无提高即默认值 params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2, 0.25, 0.3, 0.4]} # 其他参数设置,每次调参将确定的参数加入 fine_params = {'n_estimators': 50, 'max_depth': 2, 'min_child_weight': 1, 'gamma': 0.1, 'colsample_bytree': 1, 'subsample': 1, 'reg_alpha': 0.01, 'reg_lambda': 3, 'learning_rate': 0.3} return params, fine_params
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
三.模型训练与保存
3.1模型训练、验证、评估及特征重要性提取
根据调参确定好的参数训练模型,对验证集数据进行预测,预测结果与验证集标签进行对比给出准确率accuracy、F1值f1_score、auc曲线下面积roc_auc_score,判断模型效果。值得注意的是,模型调参是在训练数据集上进行,并不能保证一定会在测试集得到更好的体现,即在预测时的泛化误差并不一定会有减小。
其中metrics_sklearn() 和feature_importance_selected()两个模块的内容在下方单独写出,便于测试集对模型评估的使用
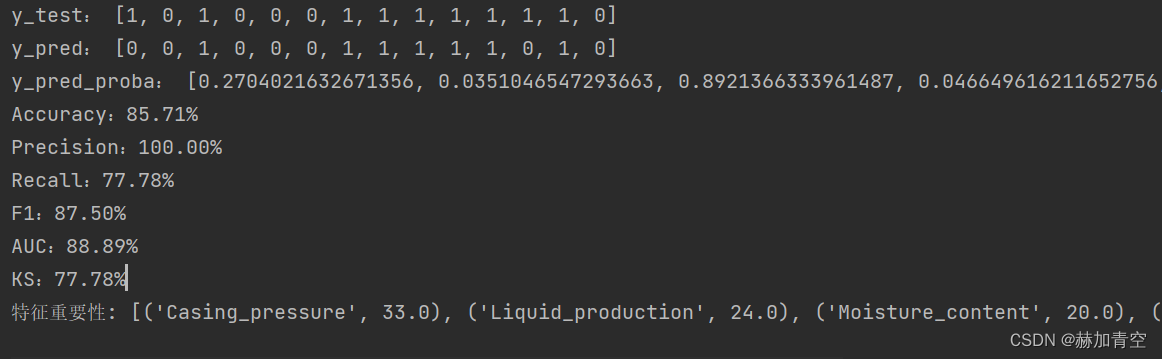
def model_fit(): """模型训练""" # XGBoost训练过程,下面的参数是调试出来的最佳参数组合 model = XGBClassifier(learning_rate=0.3, n_estimators=50, max_depth=2, min_child_weight=1, subsample=1, colsample_bytree=1, gamma=0.1, reg_alpha=0.01, reg_lambda=3) model.fit(X_train, y_train) # 对验证集进行预测——类别 y_pred = model.predict(X_test) y_test_ = y_test.values print('y_test:', y_test_) print('y_pred:', y_pred) # 对验证集进行预测——概率 y_pred_proba = model.predict_proba(X_test) # 结果类别是1的概率 y_pred_proba_ = [] for i in y_pred_proba.tolist(): y_pred_proba_.append(i[1]) print('y_pred_proba:', y_pred_proba_) # 模型对验证集预测结果评分 metrics_sklearn(y_test_, y_pred) # 模型特征重要性提取、展示和保存 feature_importance_selected(model) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
模型评估:准确率、精准率、召回率、F1值、AUC值的标准调用。
def metrics_sklearn(y_valid, y_pred_): """模型对验证集和测试集结果的评分""" # 准确率 accuracy = accuracy_score(y_valid, y_pred_) print('Accuracy:%.2f%%' % (accuracy * 100)) # 精准率 precision = precision_score(y_valid, y_pred_) print('Precision:%.2f%%' % (precision * 100)) # 召回率 recall = recall_score(y_valid, y_pred_) print('Recall:%.2f%%' % (recall * 100)) # F1值 f1 = f1_score(y_valid, y_pred_) print('F1:%.2f%%' % (f1 * 100)) # auc曲线下面积 auc = roc_auc_score(y_valid, y_pred_) print('AUC:%.2f%%' % (auc * 100)) # ks值 fpr, tpr, thresholds = roc_curve(y_valid, y_pred_) ks = max(abs(fpr - tpr)) print('KS:%.2f%%' % (ks * 100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
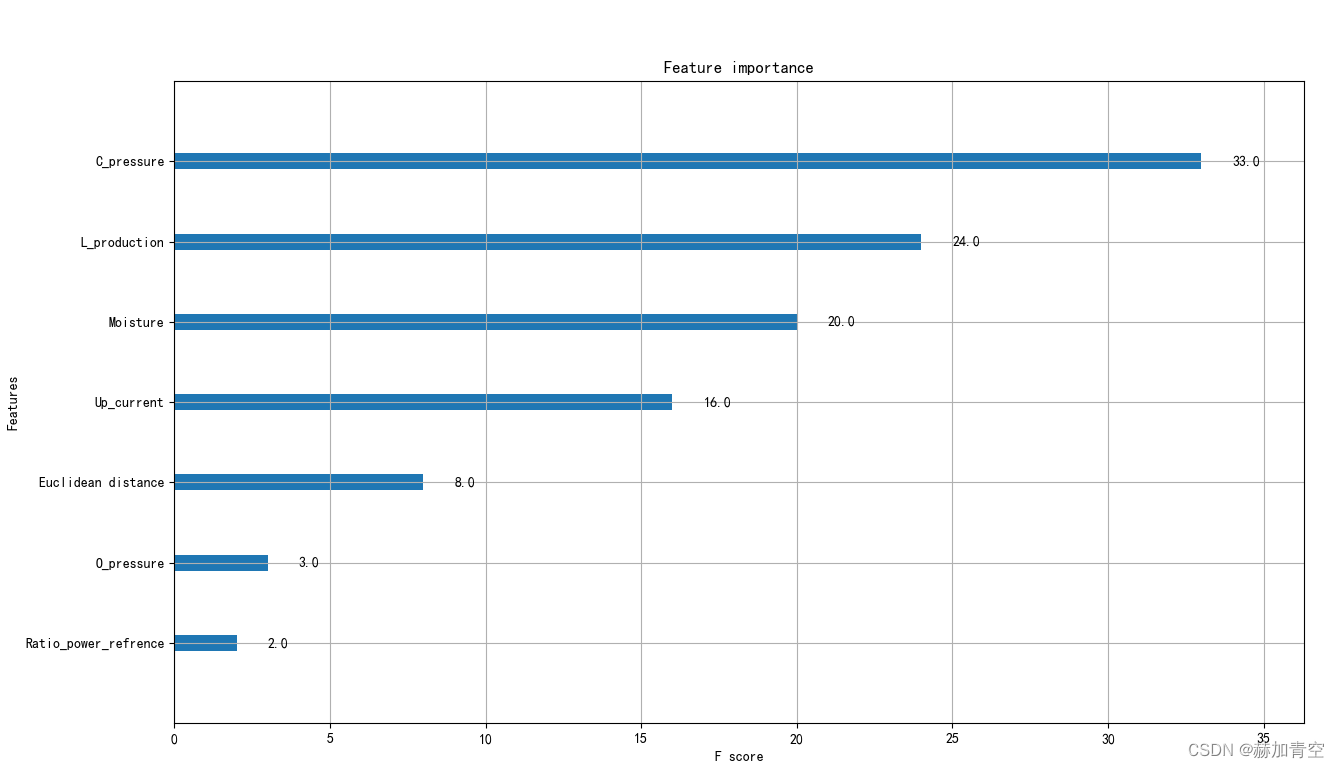
这里利用model.get_booster().get_fscore() 提取特征重要性为字典格式,plot_importance绘制图形。特殊强调:特征重要性保存到本地的作用是特征的筛选,当数据特征很多时,实际参与分类的特征可能很少。例如:原数据有1000个特征,只有90个有重要性,且重要性大于5的只有30个,其他910个特征并未参与模型的建立和预测。此时可以只取部分有特征重要性的特征(90)或重要性大于某一阈值的特征(30个)入模参与预测。
def feature_importance_selected(clf_model):
"""模型特征重要性提取与保存"""
# 模型特征重要性打印和保存
feature_importance = clf_model.get_booster().get_fscore()
feature_importance = sorted(feature_importance.items(), key=lambda x: x[1], reverse=True)
feature_ipt = pd.DataFrame(feature_importance, columns=['特征名称', '重要性'])
feature_ipt.to_csv('feature_importance.csv', index=False)
print('特征重要性:', feature_importance)
# 模型特征重要性绘图
plot_importance(clf_model)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.2模型训练与保存
模型保存通过save_model实现,保存为.model文件,模型的保存是对训练好的模型结果的持久化。另外,这里也实现了dump_model方法保存模型为.txt格式,便于模型分析、优化和提供可解释性(可解释性详见《Graphviz绘制模型树》,本文不再赘述)。
def model_save_type(clf_model):
# 模型训练完成后做持久化,模型保存为model模式,便于调用预测
clf_model.save_model('xgboost_classifier_model.model')
# 模型保存为文本格式,便于分析、优化和提供可解释性
clf = clf_model.get_booster()
clf.dump_model('dump.txt')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
实际作业中并不会每次都去训练模型然后应用,加载已保存的模型是常规操作
if __name__ == '__main__':
"""
模型训练、评分与保存
结论:训练集k折交叉验证带来的模型评分提升,未必会在测试集上得到提升
"""
# 模型训练
model_xgbclf = model_fit()
# 模型保存:model和txt两种格式
model_save_type(model_xgbclf)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
模型验证集预测结果及得分
特征重要性结果的绘图展示
特征重要性结果已保存到当前目录下的 feature_importance.csv 文件内,演示用例特征较少,实际项目中会碰到几百个特征,保存起来就很必要了。
四.模型加载与预测
模型加载过程,需要使用到Booster,不同于常规的load_model方式。模型预测打印预测结果y_pred及类别概率y_pred_proba
def model_load(model, x_transform):
# 模型加载
clf = xgb.XGBClassifier()
booster = xgb.Booster()
booster.load_model(model)
clf._Booster = booster
# 数据预测
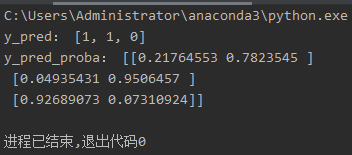
y_pred = [round(value) for value in clf.predict(x_transform)]
y_pred_proba = clf.predict_proba(x_transform)
print('y_pred:', y_pred)
print('y_pred_proba:', y_pred_proba)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
预测数据也要是数值格式,ndarray的格式可以直接用于预测,注意[[]],一定是两层,即使只有一组数据也要写成两层括号
if __name__ == '__main__':
"""
模型加载与数据预测
结论:持久化的模型用来预测数据结果,随着业务的变化模型也需要随之调整
补充:如果有测试集数据,与此预测相同,另外可通过 metrics_sklearn() 模块来进行预测结果评估,以此来判断模型可靠性
"""
x_pred = np.array([[0.63, 0.72, 7.6, 85.4, 40, 38, 0.598787852, 0.474784735],
[0.39, 0.42, 6.2, 95.4, 39, 38, 0.71287283, 0.5838785491],
[0.29, 0.32, 20.43, 92.7, 41, 39, 0.498825525, 0.476575973]])
model_save_load('xgboost_classifier_model.model', x_pred)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
预测结果如下
五.附加-模型的评估与理解
1.关于XGBoost的原理内容,
见《XGBoost算法原理及基础知识》 ,包括集成学习方法,XGBoost模型、目标函数、算法,公式推导等;
2.关于分类任务的评估指标值详解,
见《分类任务评估1——推导sklearn分类任务评估指标》,其中包含了详细的推理过程;
见《分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线》,其中包含ROC曲线、P-R曲线和K-S曲线的推导与绘制;
3.关于XGBoost模型中树的绘制和模型理解,
见《Graphviz绘制模型树1——软件配置与XGBoost树的绘制》,包含Graphviz软件的安装和配置,以及to_graphviz()和plot_trees()两个画图函数的部分使用细节;
见《Graphviz绘制模型树2——XGBoost模型的可解释性》,从模型中的树着手解释XGBoost模型,并用EXCEL构建出模型。
4.关于XGBoost实践,
见《机器学习实践(1.1)XGBoost分类任务》,包含二分类、多分类任务以及多分类的评估方法;
见《机器学习实践(1.2)XGBoost回归任务》,包含回归任务模型训练、评估(R2、MSE)。
❤️ 机器学习内容持续更新中… ❤️
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。

