
热门标签
热门文章
- 1CSS 颜色代码_css浅蓝色
- 2shardingsphere 集成springboot【水平分表】
- 3Android WebView调用系统相册和相机,注入以及与H5的交互_webview 增加打开相机相册交互
- 4有关windows10修改C盘用户中文名文件夹相关问题的具体解决方案_win10修改c盘下用户的文件夹名会出问题吗
- 5关于UE4打包问题_编译模式_实例1_ue4打包后效果不一样
- 6uniapp+vue微信小程序的 健身房预约系统_uniapp 热量数据
- 7OpenSSL/GMSSL EVP接口说明——3.5 加密解密_evp_pkey_ctx_set_ec_sign_type( pkctx, nid_sm_schem
- 82023最新玩客云刷机armbian,部署docker并配置各种常用容器镜像_玩客云 armbian
- 9Unity接入Steam平台详细流程一_steammanager获取名字
- 10十五、进程&线程&协程_pool.map 怎么等待主线程执行完
当前位置: article > 正文
使用yolov8进行文本行检测
作者:凡人多烦事01 | 2024-02-21 09:24:35
赞
踩
使用yolov8进行文本行检测
最近使用yolov8进行字符检测任务,因为场景数据是摆正后的证件数据,所以没有使用DB进行模型训练,直接选用了yolov8n进行文本检测,但是长条字符区域检测效果一直不太好,检出不全,通过检测和分割等算法的调试,发现算法本身不太适合作文本检测,然后调试的时候去掉了DFL loss,整个检出效果就可以使用了,目前还没有对DFL loss进行算法分析。修改不使用DFL loss 的代码在:ultralytics-main/ultralytics/nn/modules.py中line 396修改为1:

仅此记录一下。( torch.nn.Identity( ) 作用是输入是什么,输出就是什么)
DFL loss的全称Distribution Focal Loss;首次提出是:https://arxiv.org/pdf/2006.04388.pdf
将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布
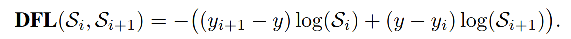
对yolov8 DFL loss的详细解说可参考:
补充细节说明:
运行代码在:train_detect.py
本人使用的是n结构,所以配置如下:
- from ultralytics import YOLO
-
- # Load a model
- model = YOLO('yolov8n-seg.yaml') # build a new model from YAML
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
-
- # Train the model
- # model.train(data='coco_38classes.yaml', epochs=100, imgsz=640, save=True)
- # model.train(data='coco_txtlinedetect.yaml', epochs=100, imgsz=640, save=True)
- model.train(data='coco_txtlinedetect_seg.yaml', epochs=300, imgsz=640, save=True)
数据配置文件在:/ultralytics/datasets/coco_txtlinedetect_seg.yaml 中;
参数详细配置:/ultralytics/yolo/cfg/default.yaml
其中有一个早停机制:patience: 300 (默认是50)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/122501
推荐阅读
相关标签

