
热门标签
热门文章
- 1pandas数据预处理_合并_清洗_标准化数据_转换数据_15_pandas数据预处理_标准化数据_转换数据
- 2centos7 无法启动网络(service network restart)错误解决办法_service network restart报错
- 3anaconda瘦身_anaconda 瘦身
- 4Anaconda 管理Python环境(安装、激活、更新、删除)_conda管理python版本
- 5物联网实训室解决方案2024
- 6linux踩内存排查,linux下valgrind内存问题排查
- 7(zzulioj1006)给出三个整数,分别表示等差数列的第一项、最后一项和公差,求该数列的和。_给出三个整数,分别表示等差数列的第一项、最后一项和公差,求该数列的和。
- 8Linux的基本使用_opkk
- 9详解Kafka生产者和消费者的工作原理!保准看明白!_kafka生产消费原理
- 10spring boot3登录开发-3(账密登录逻辑实现)
当前位置: article > 正文
边缘智能相关论文(Edge Intelligence & Federated Learning)
作者:凡人多烦事01 | 2024-03-05 11:56:52
赞
踩
边缘智能相关论文
最近边缘计算方面出了很多新的研究成果,在AI背景下,边缘智能(Edge Intelligence)中新的研究相较于传统的深度学习研究方向,关注不仅仅是模型的准确率,更多的在于实际部署中的可用性,例如响应度、效率、能耗、资源占用等方面。
除此之外,联邦学习是边缘智能的一个很重要的方面,以及相关的安全性方面的研究。选取了近几年顶会和引用量较高的几篇论文分享↓↓↓↓
Fast Inference
- BranchyNet: Fast inference via early exiting from deep neural networks, ICPR, 2016,提出了一种在模型推断时,估计准确率,达到准确率阈值后,就近选择快速跳出模型获得结果的方法。

- Neurosurgeon: Collaborative Intelligence Between the Cloud and Mobile Edge, ASPLOS, 2017, 在BranchyNet的基础上,结合边缘计算,采用云边端协同推断的方法,将神经网络在推断部署时分散到云边端中,达到模型推断的能耗和延迟要求。
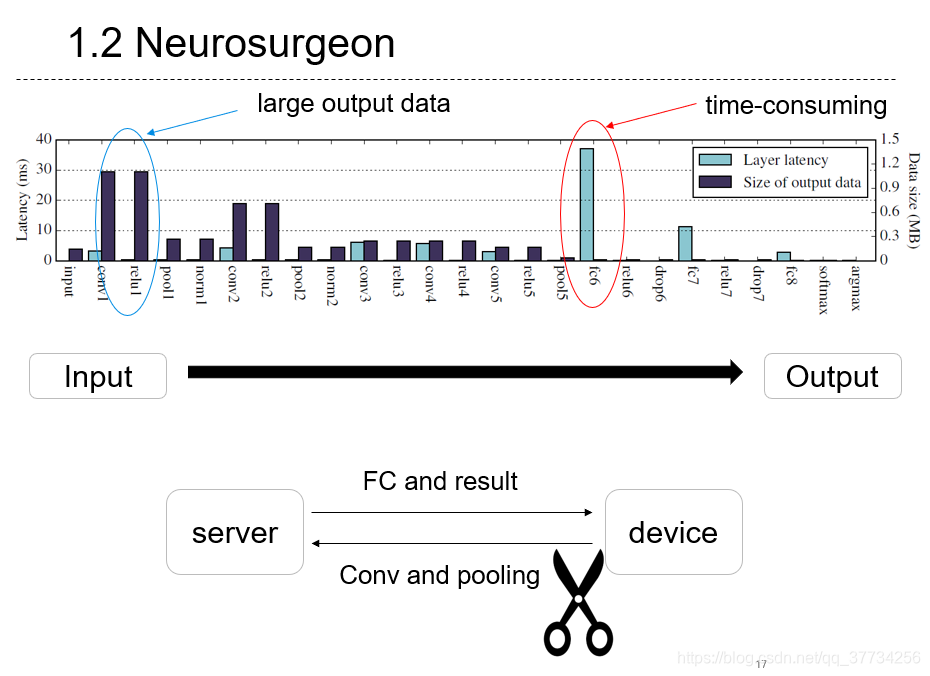
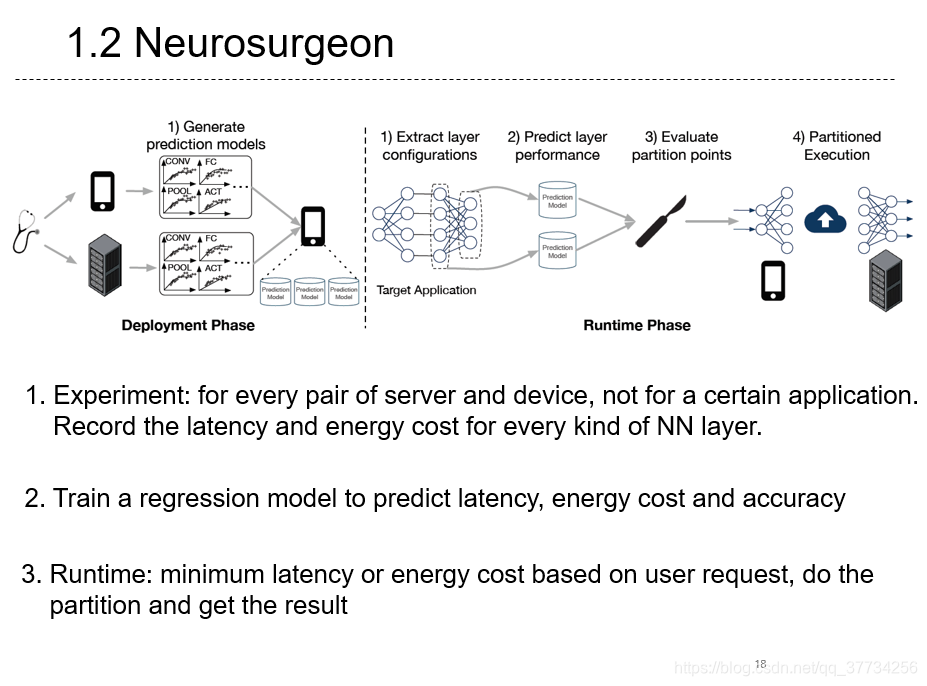

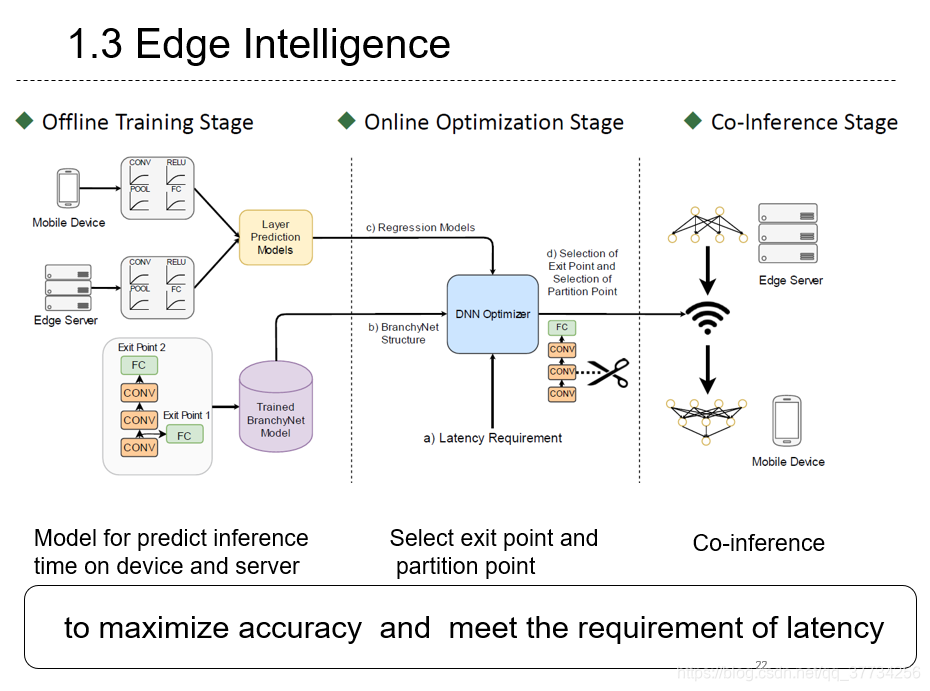
- Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy, SIGCOMM, 2018, 在前两篇BranchyNet和Neurosurgeon的基础上,参考前一篇论文,使用线性回归模型,来实现自动化的神经网络拆分和自动化的BranchyNet,在满足时延要求的同时达到最大化精度。

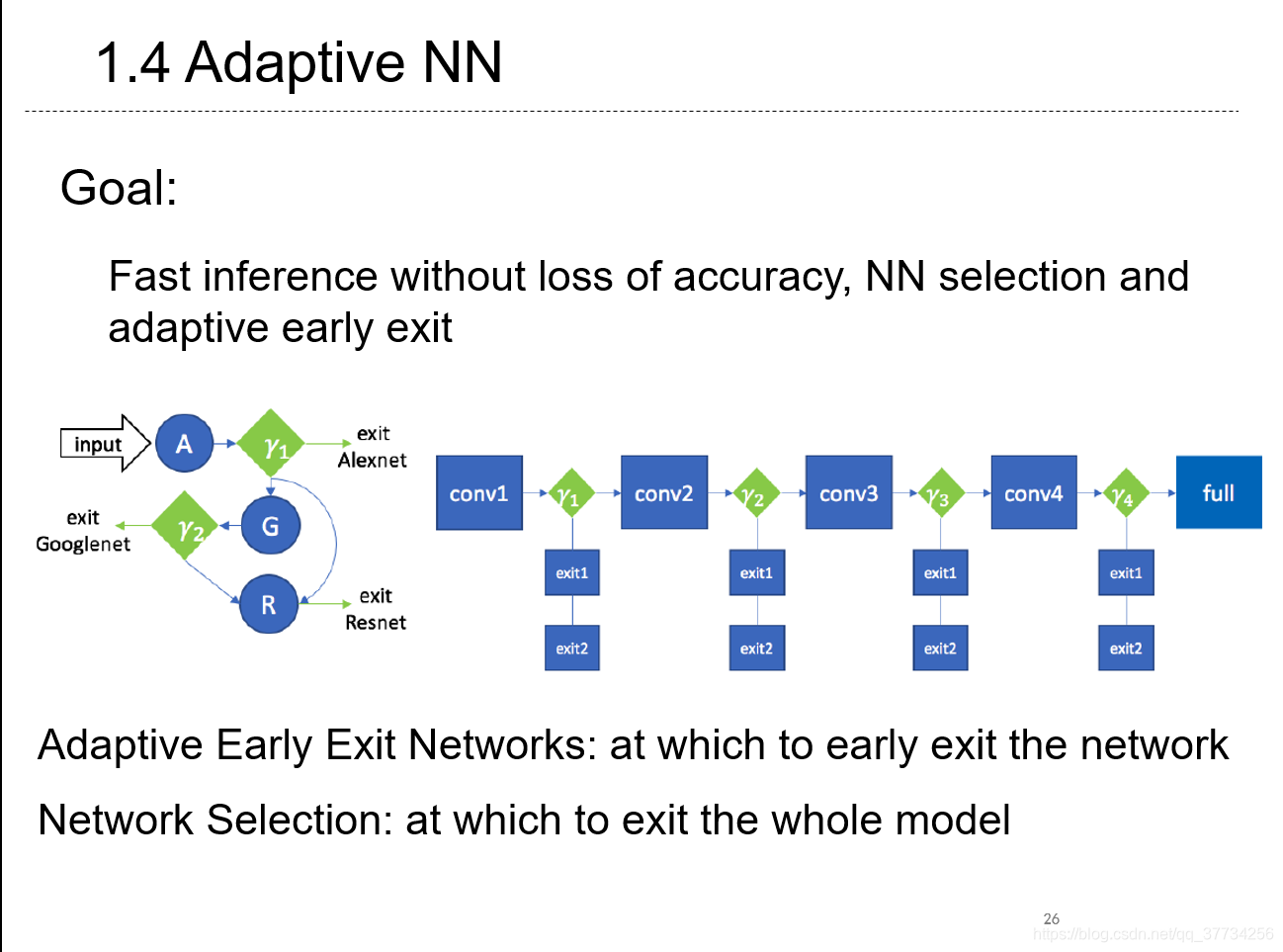
- Adaptive Neural Networks for Efficient Inference, ICML, 2017, 在BranchyNet的基础上,BranchyNet是在一个网络模型例如AlexNet中,提前退出,不执行后面几层。而该文章中,是按自动机的方式连接几个神经网络模型,如果提前退出就不执行后面更复杂的神经网络。例如在图像分类中,用类似自动机的方法,入口进入AlexNet,结合BranchyNet,如果精度达到就退出,否则进入后面的GoogleNet和ResNet部分继续执行。
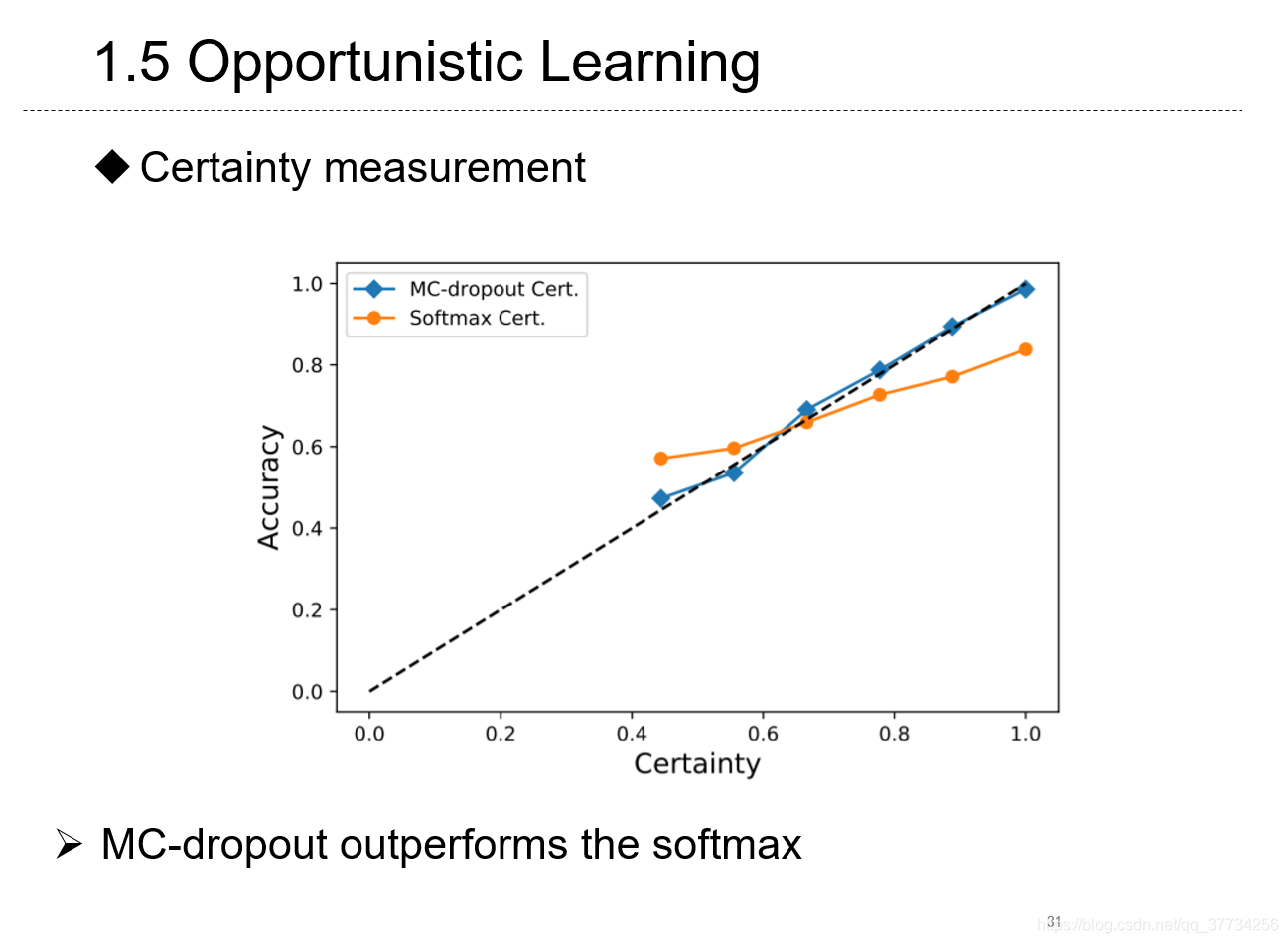
- Opportunistic Learning: Budgeted Cost-Sensitive Learning from Data Streams, ICLR, 2019, 文章中提出某些机器学习场景和边缘智能场景,例如对视频流处理,特征获取是需要付出代价的,使用强化学习的价值函数来获取特征。文中还特别地指出BranchyNet中那样利用熵估计精度不准确,提出了蒙特卡洛估计精度方法。

Model Compression
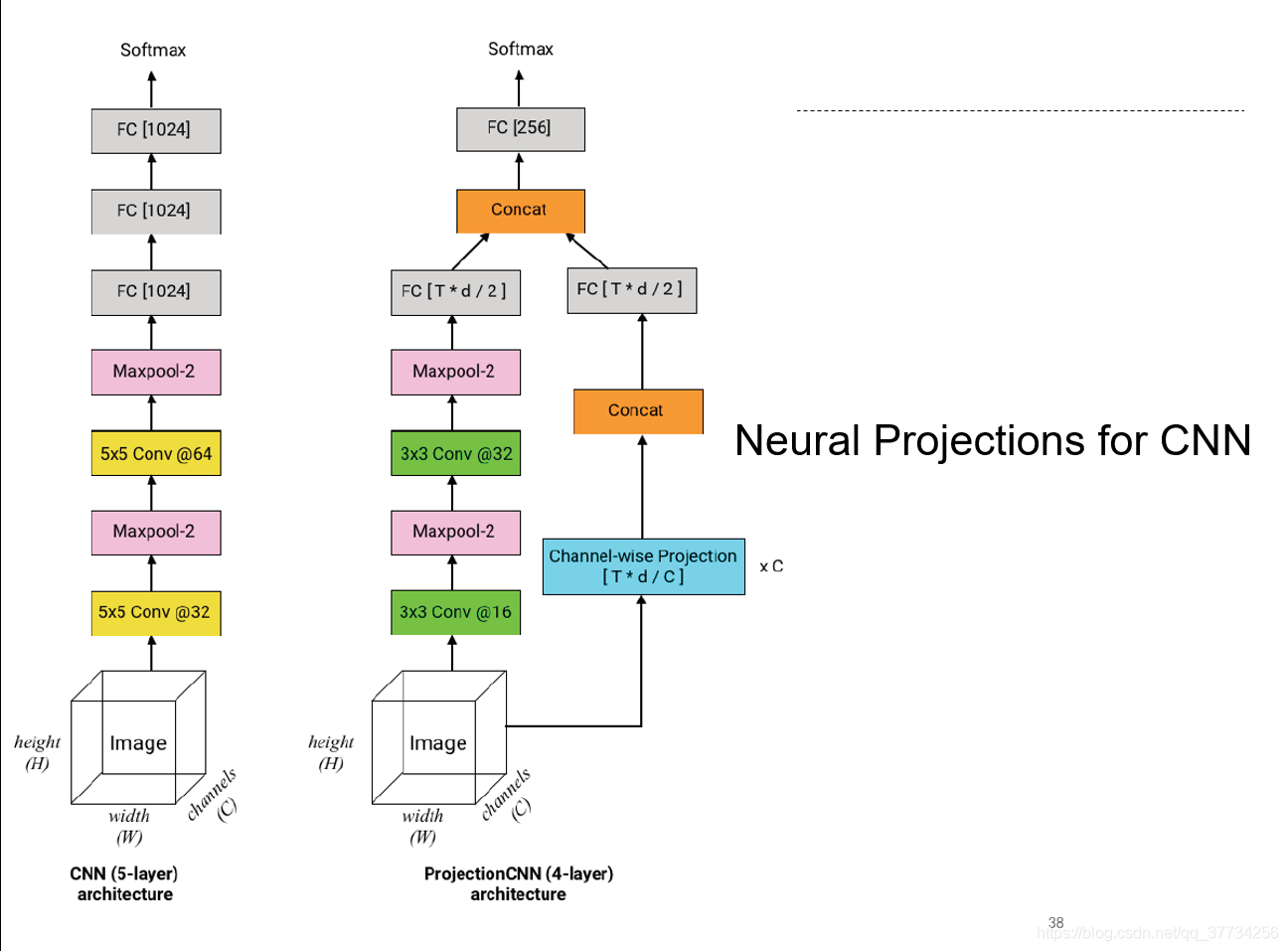
Efficient On-Device Models using Neural Projections
, ICML, 2019, 提出了一种类似GAN和知识蒸馏的神经网络投影的方法来压缩模型结构,获得更小的模型,该方法还为CNN、RNN做了定制。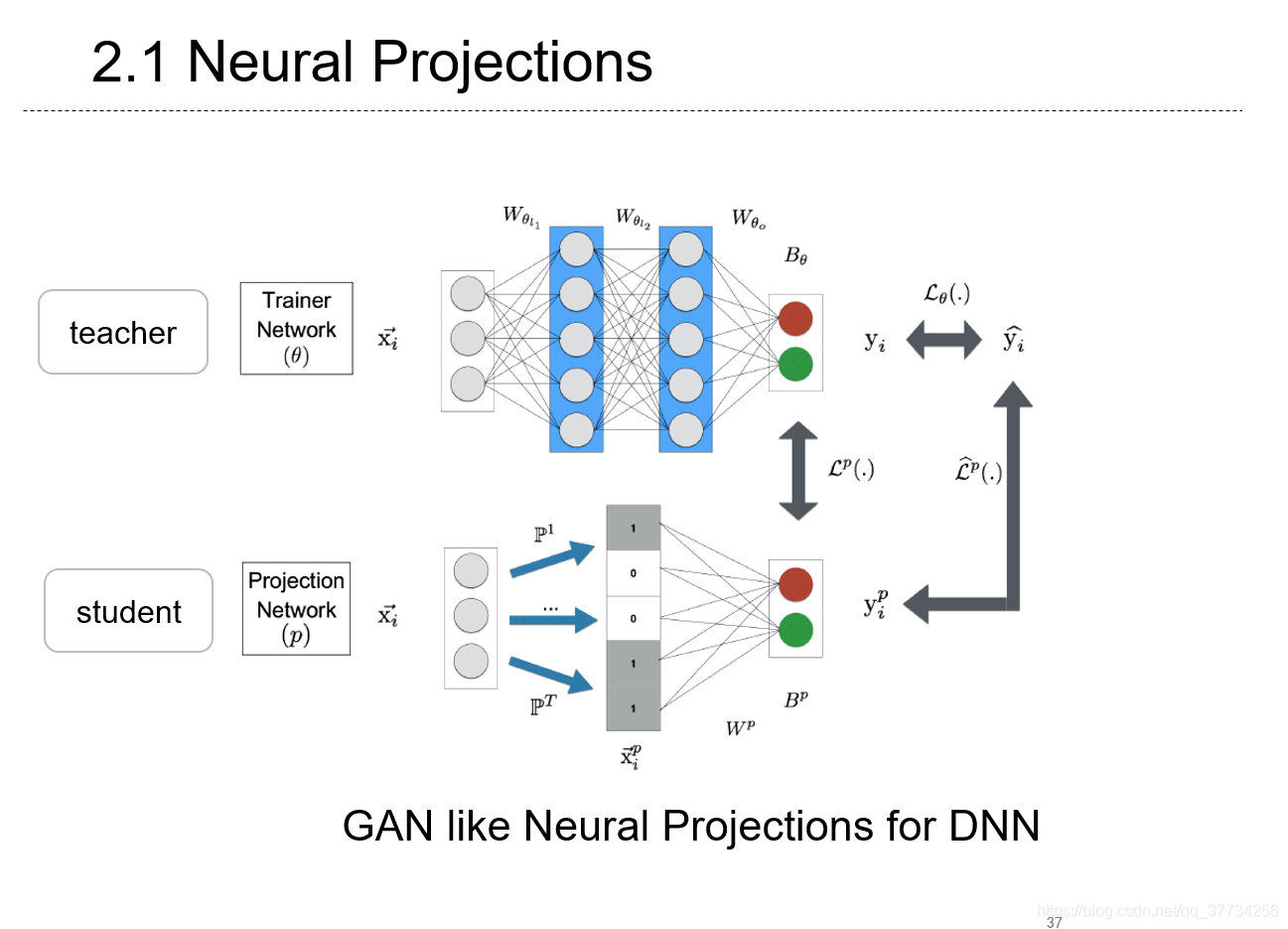
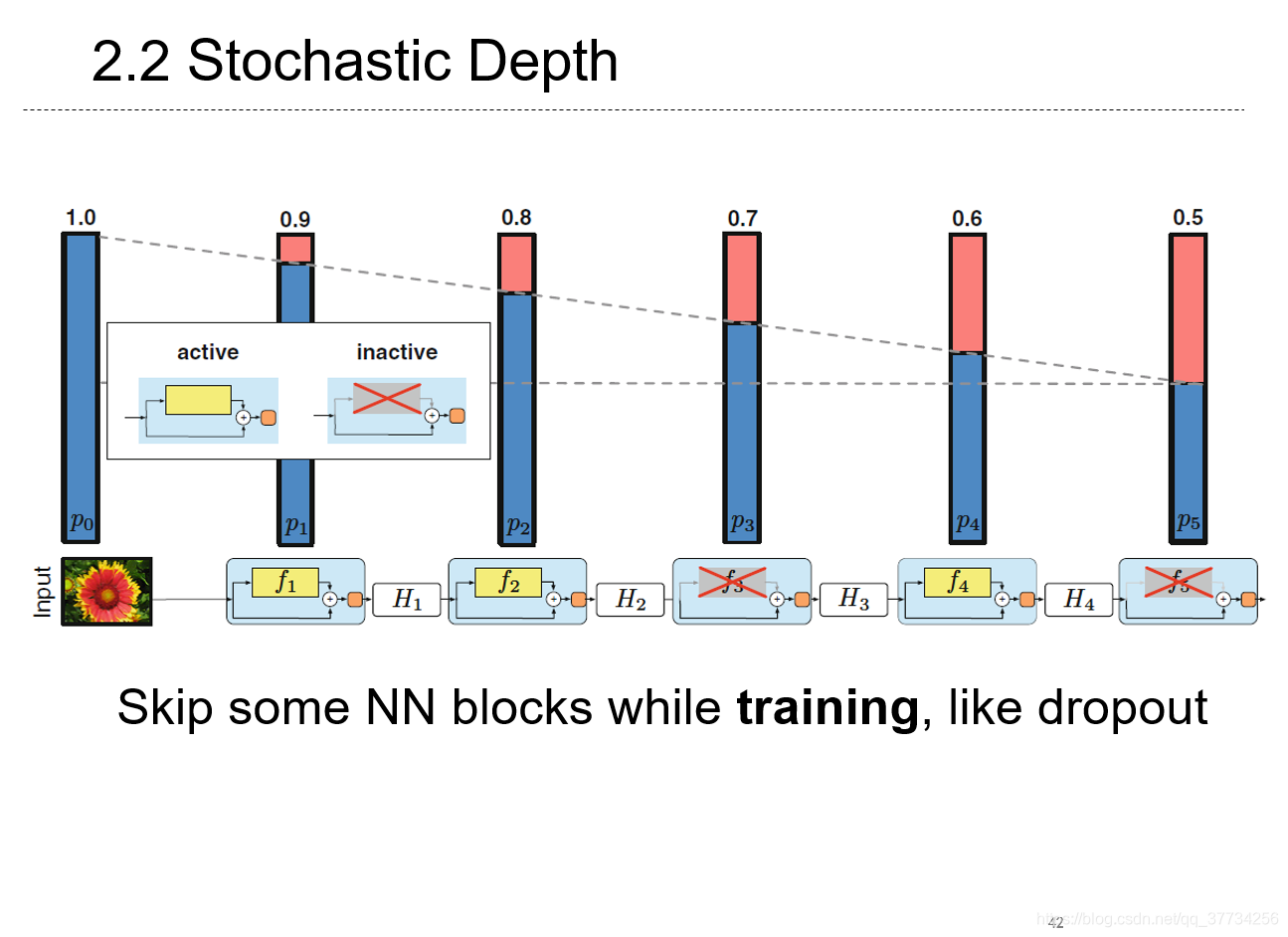
- Deep Networks with Stochastic Depth, ECCV, 2016, 放在模型压缩里面,是因为别的都是加快模型推断,这一篇加快了训练过程,在训练时使用skip的方法,把神经网络看成一个个块,像dropout一样,对于一个块,可以选择跳过也可以选择经过,可以加速训练过程;在推断时,使用完整的网络。
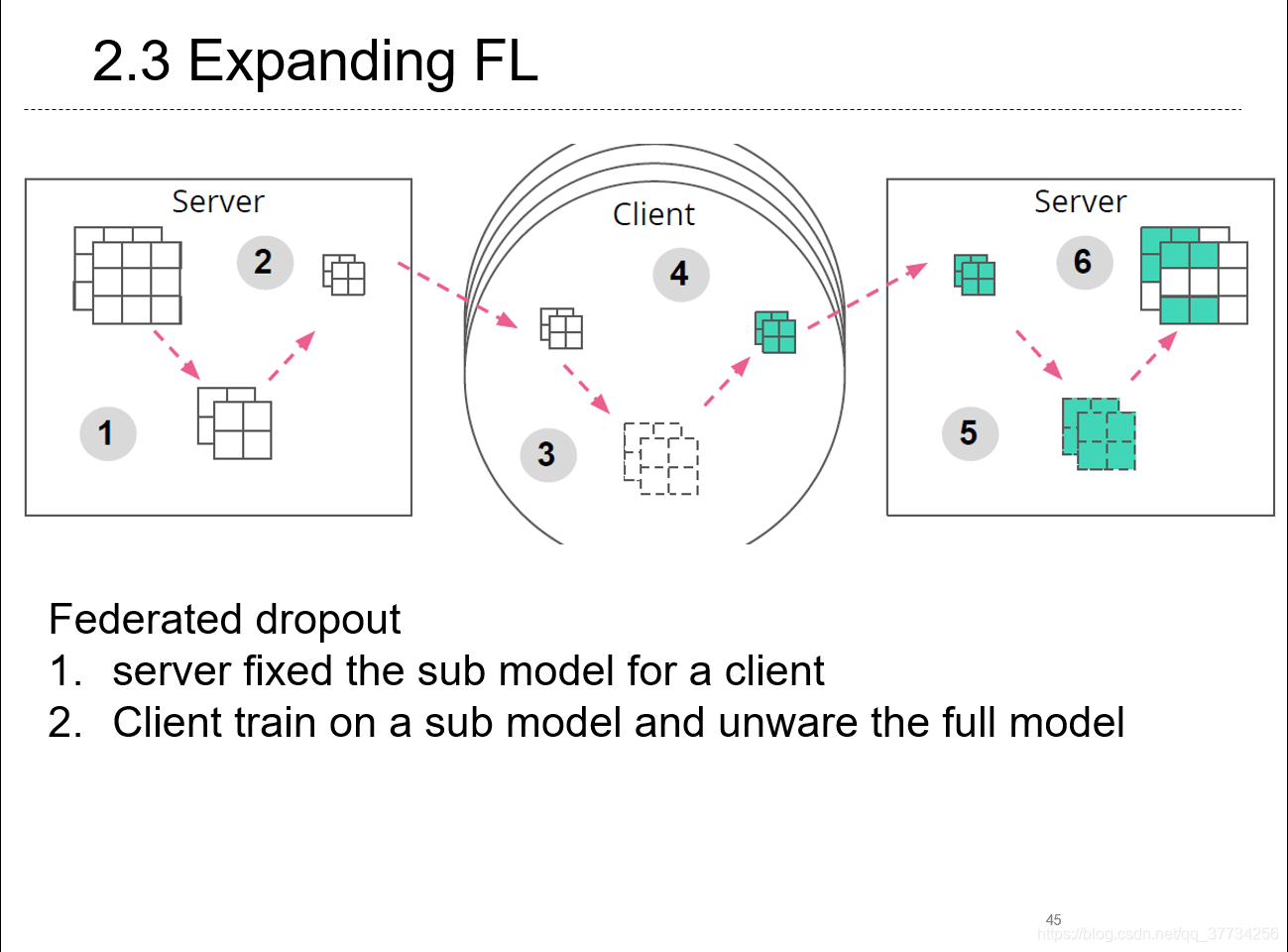
- Expanding the Reach of Federated Learning by Reducing Client Resource Requirements, TODO, 2018, 提出了Federated Dropout的方法来训练,每个参与者拥有的不是传统联邦学习框架下完整的model,而是dropout的一部分submodel。
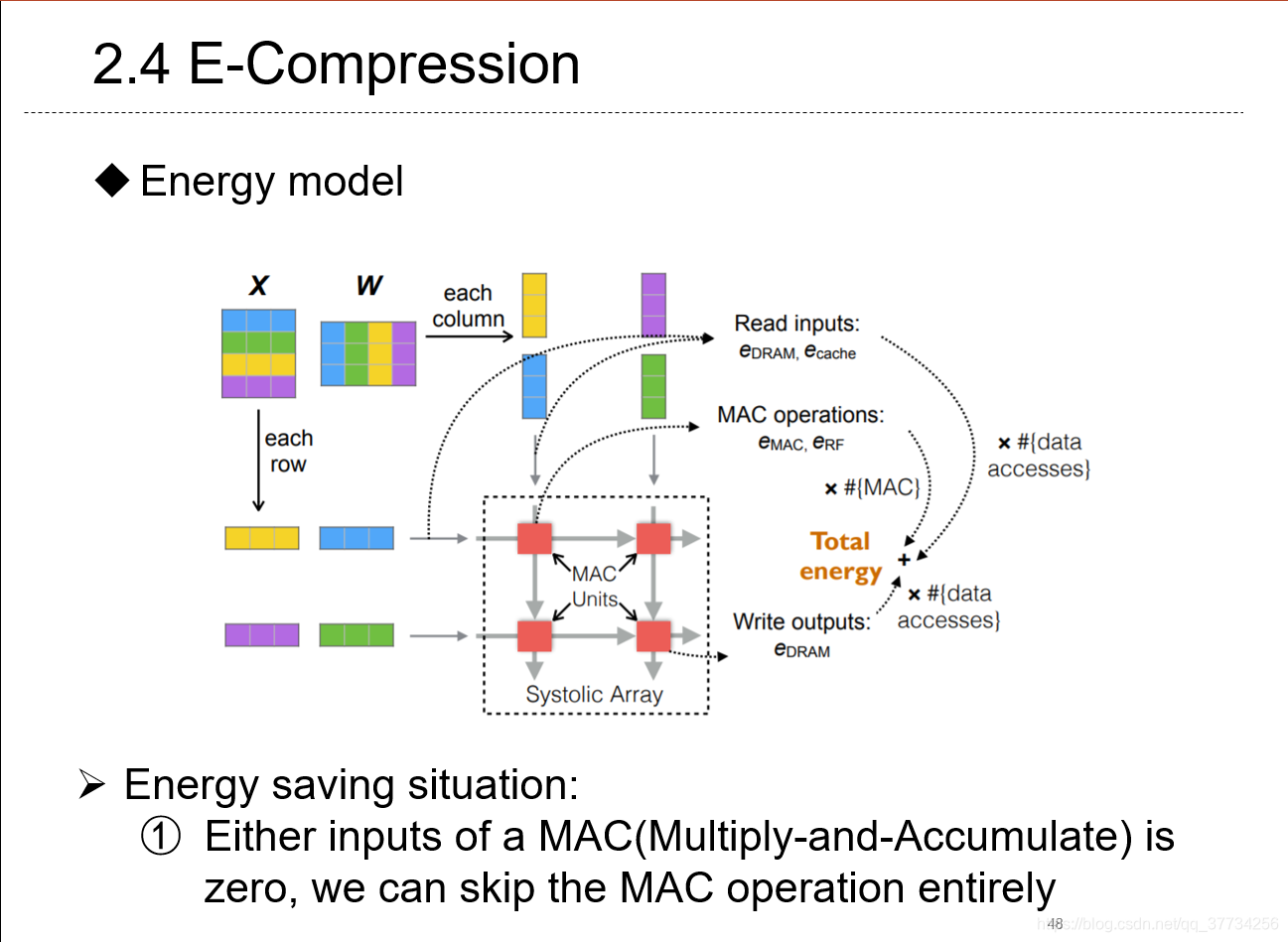
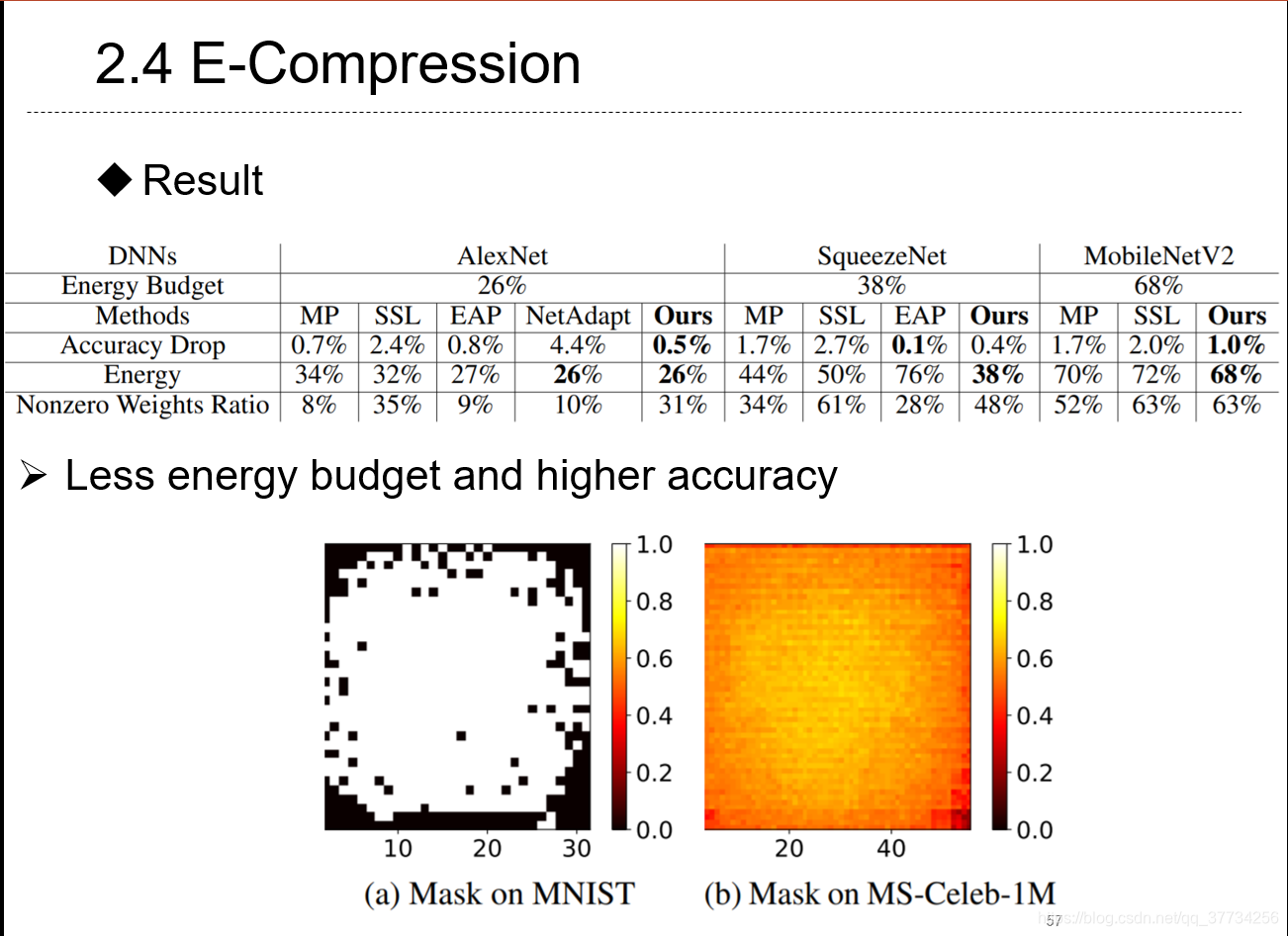
- Energy-Constrained Compression for Deep Neural Networks via Weighted Sparse Projection and Layer Inp, ICLR, 2019, 第一个提出用量化的角度来看待神经网络推断时的能耗的,分析了加速矩阵乘加运算应该要尽可能多的零参与运算,通过神经网络权重的稀疏投影,以及首次提出的input mask方法可以对输入本身进行“训练”,达到能耗最低。
Reduction in Communication
- Federated Learning: Strategies for Improving Communication Efficiency, NIPS, 2016, 首次提出用structured update和skewed update来进行联邦学习的参数更新,减少通信量。


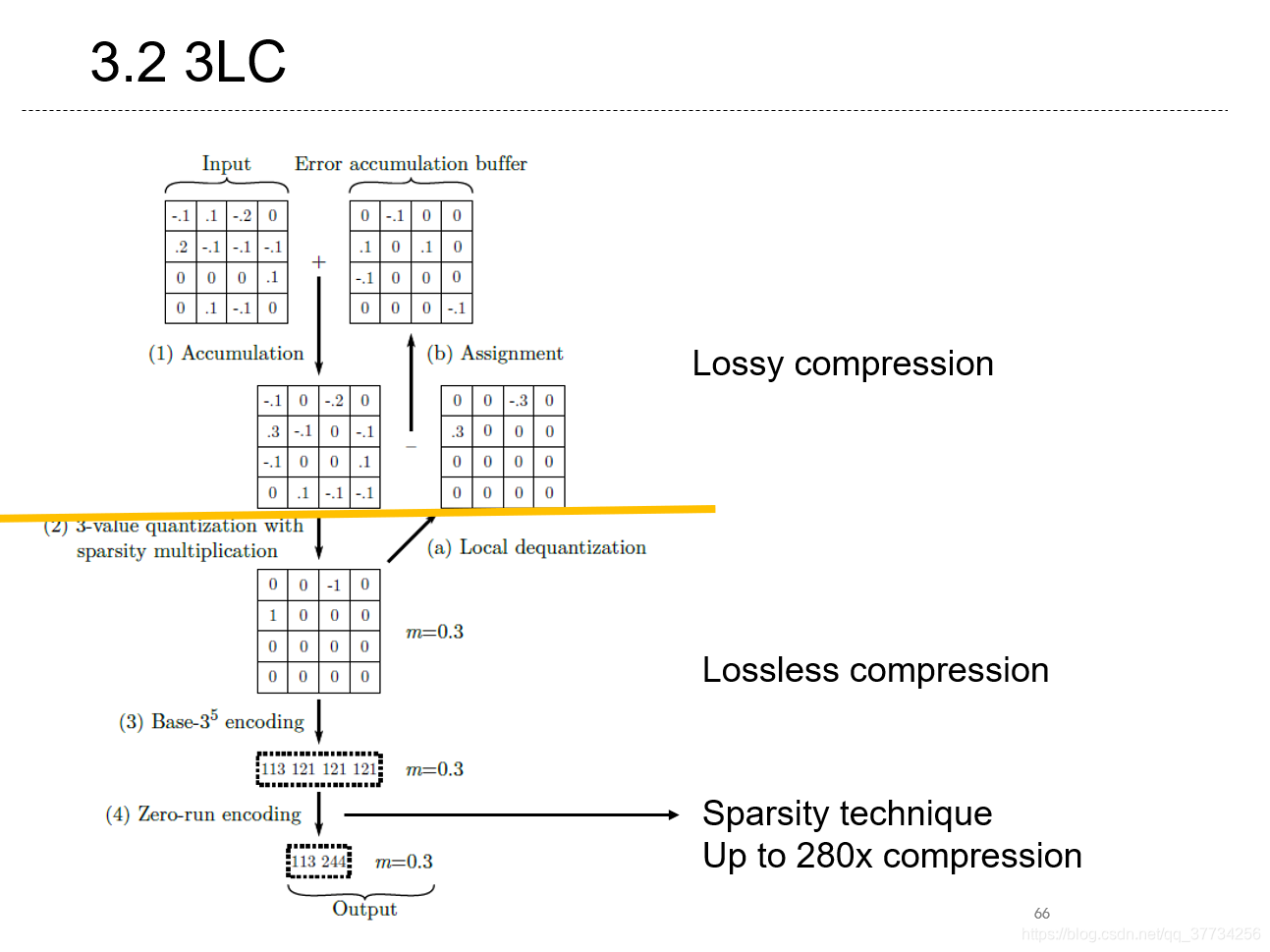
- 3LC: Lightweight and Effective Traffic Compression for Distributed Machine Learning, SysML, 2019, 提出了有损的梯度压缩编码方案,首次使用错误累计矩阵,最佳时可压缩280x。
Federated Learning and Optimization
- Privacy-Preserving Deep Learning,CCS, 2015
文中提出了Distributed Selective SGD,许多联邦学习文章都会引用该论文。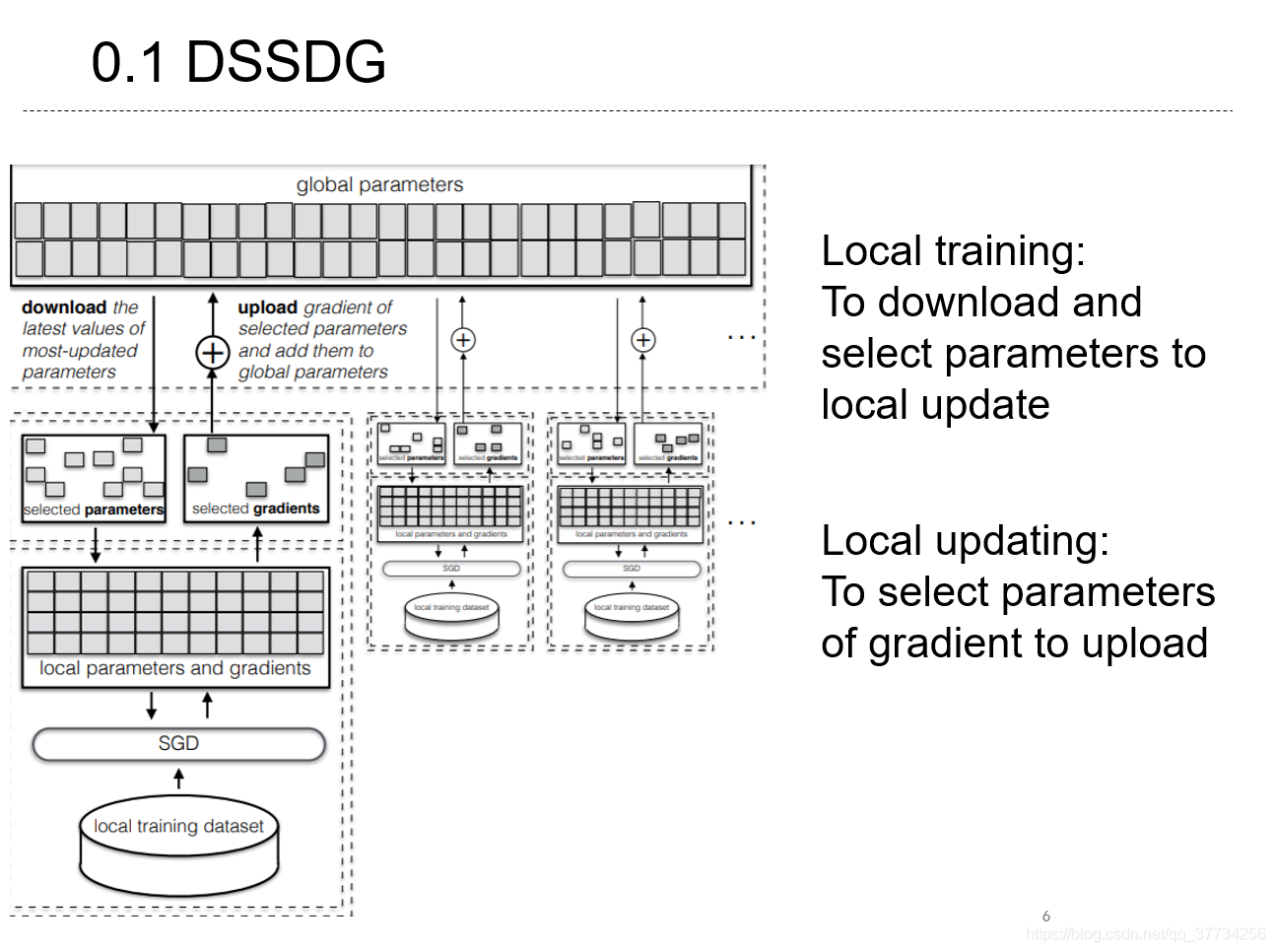
- Communication-Efficient Learning of Deep Network from Decentralized Data,AISTATS, 2017,联邦学习开山之作之一,提出了FedAVG的参数聚合方法。

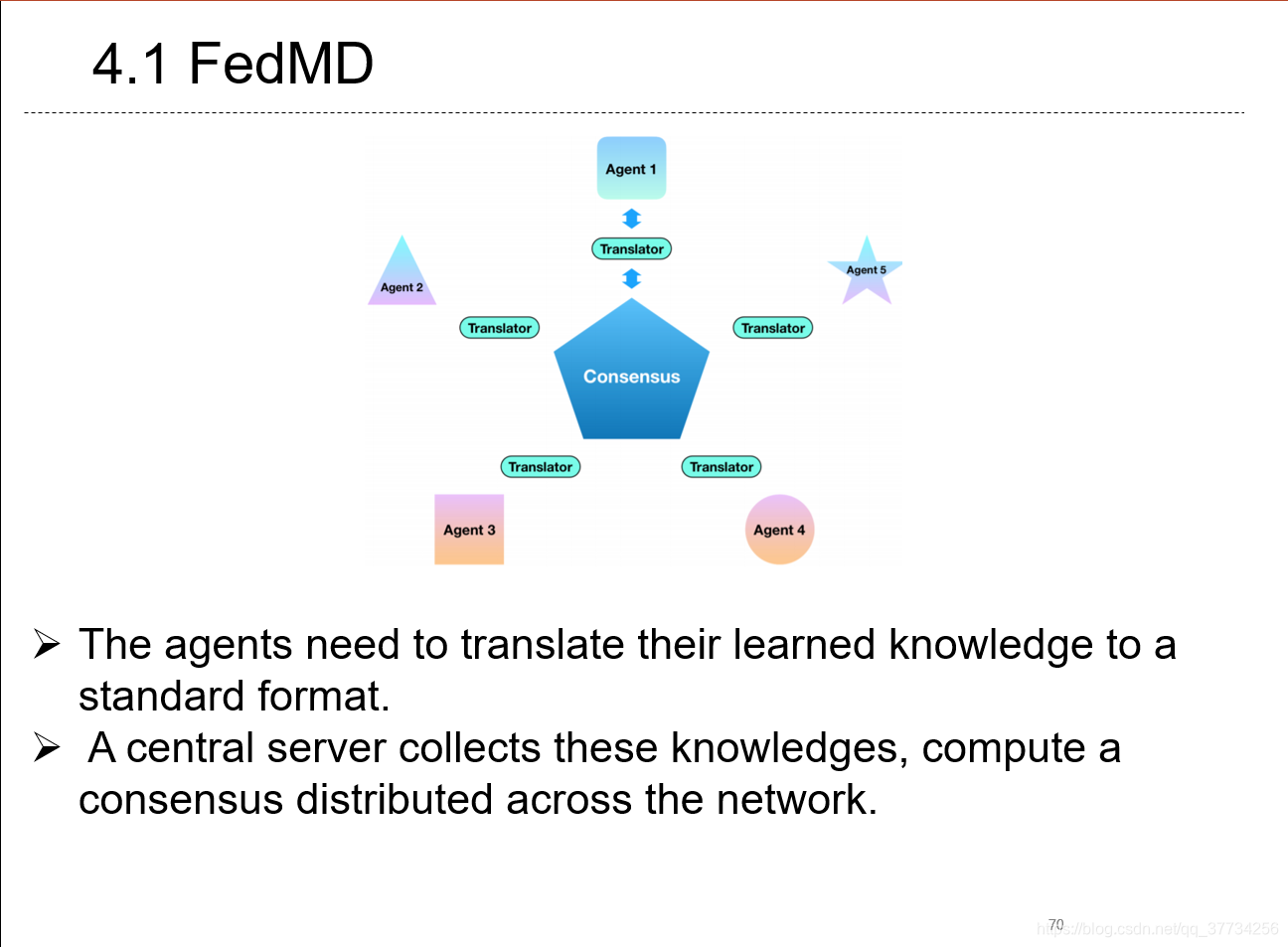
- FedMD: Heterogeneous Federated Learning via Model Distillation, NeuIPS WorkShop, 2019, 将知识蒸馏用于联邦学习场景,传递的不是梯度,而是soft score。
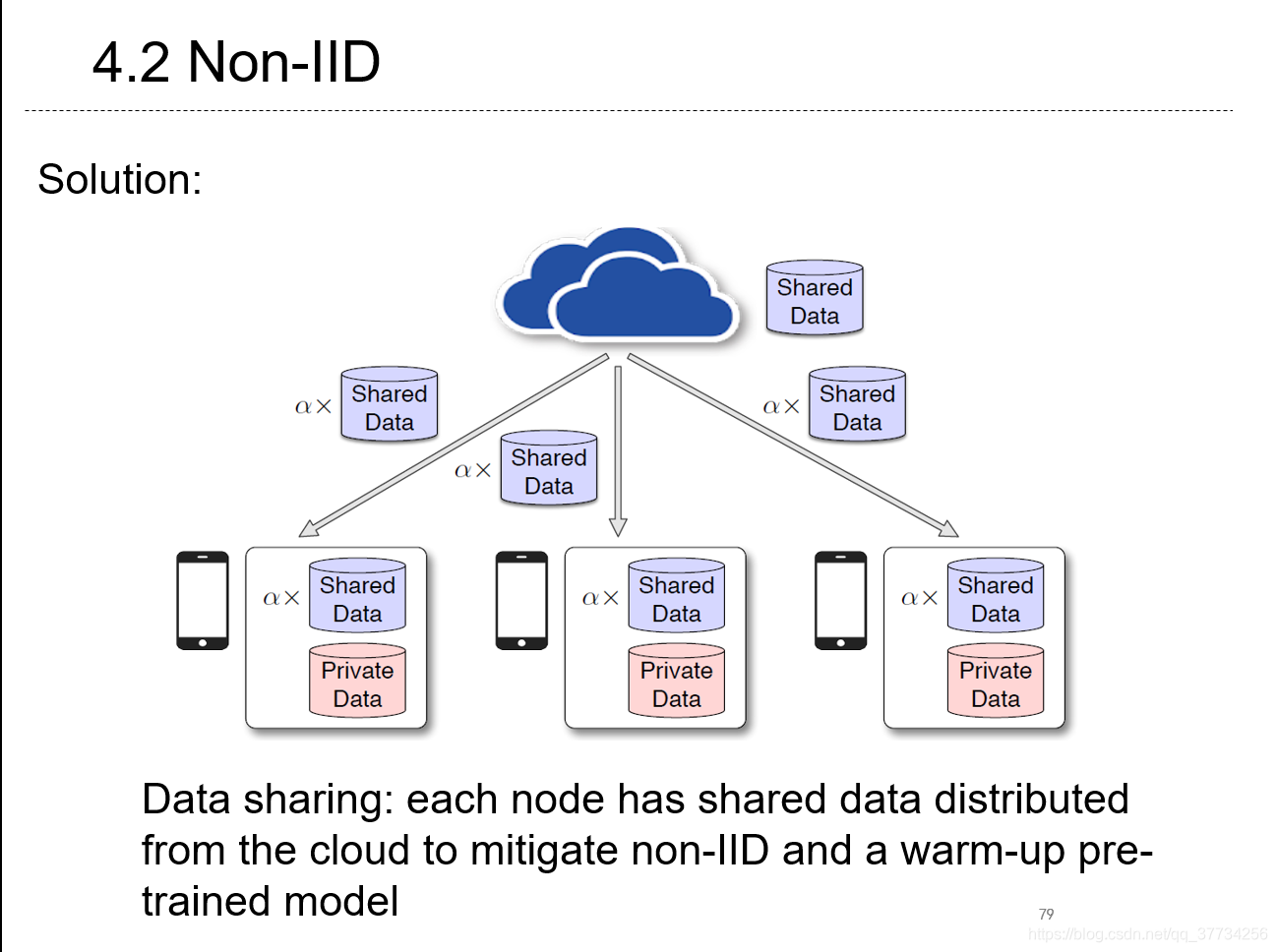
- Federated Learning with Non-IID Data, CoRR, 2018, 通过实验和推导,指出联邦学习的每个参与者数据的Earth mover’s distance与non-iid以及性能下降之间有关联,并提出通过分享数据降低non-iid程度。
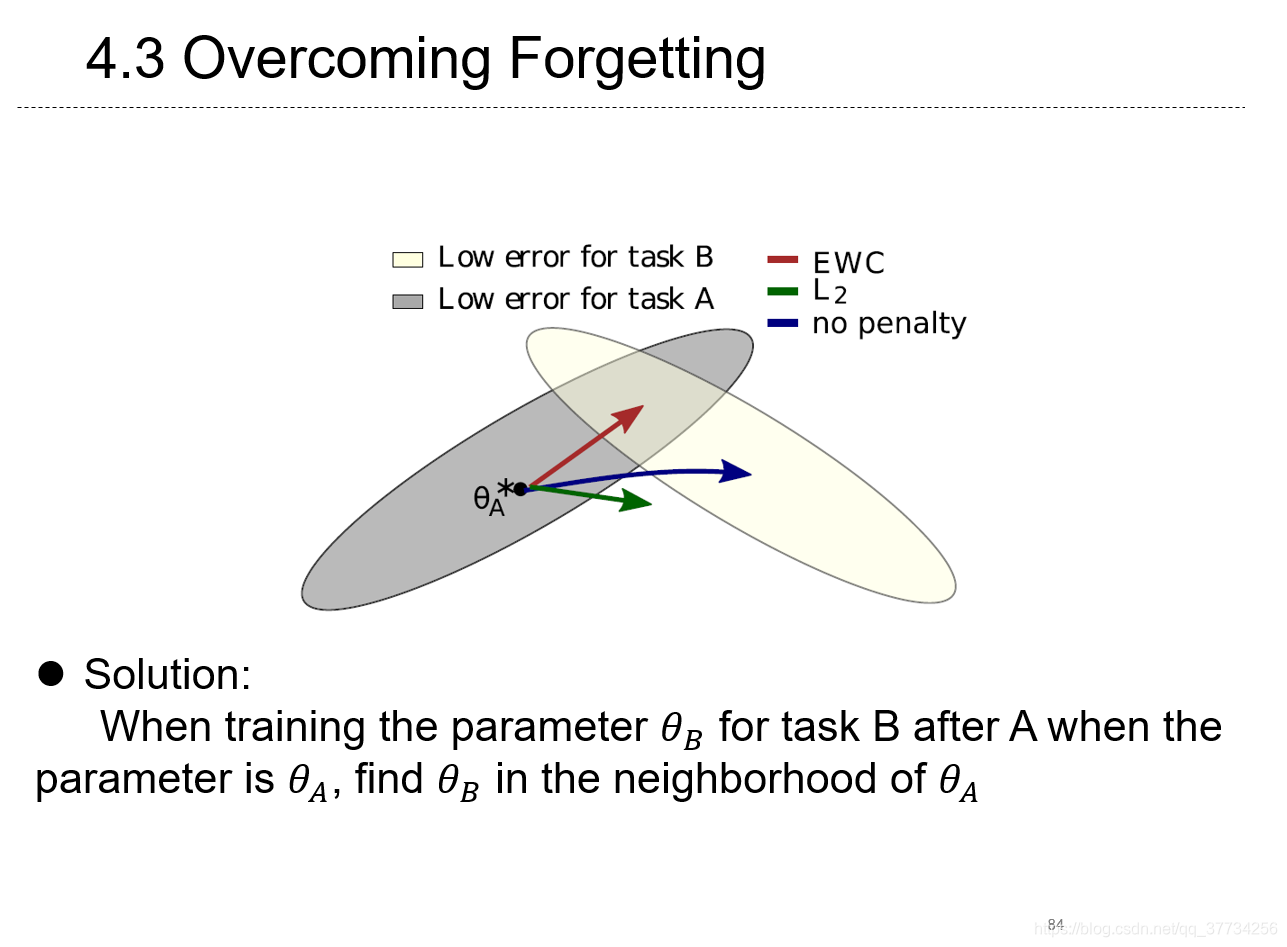
- Overcoming Forgetting in Federaerd Learning on Non-IID Data, NeuIPS WorkShop, 2019, 提出使用持续学习中防止遗忘的EWC损失,缓解联邦学习中non-iid问题。

- Variational Federated Multi-Task Learning, CoRR, 2019, 探索联邦学习的框架下的多任务学习,使用了贝叶斯网络的方法,很贝叶斯。


- Knowledge Extraction with No Observable Data, NeurIPS, 2019, 提出不需要观测数据,也能从一个神经网络模型中获取到信息,进行知识蒸馏,利用了类似GAN的方法,生成的数据表示很像联邦学习中隐私泄露得到的数据均值。
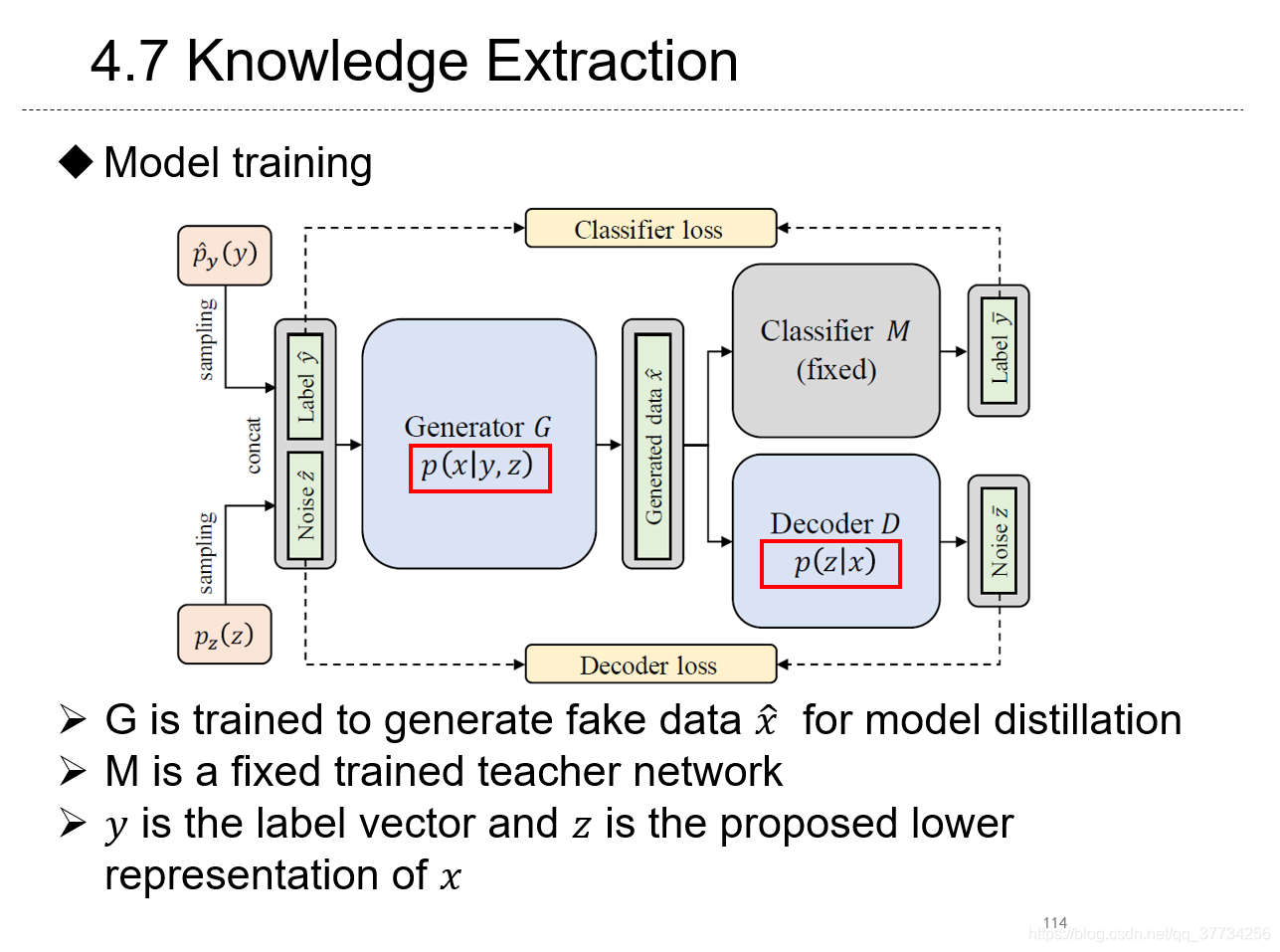

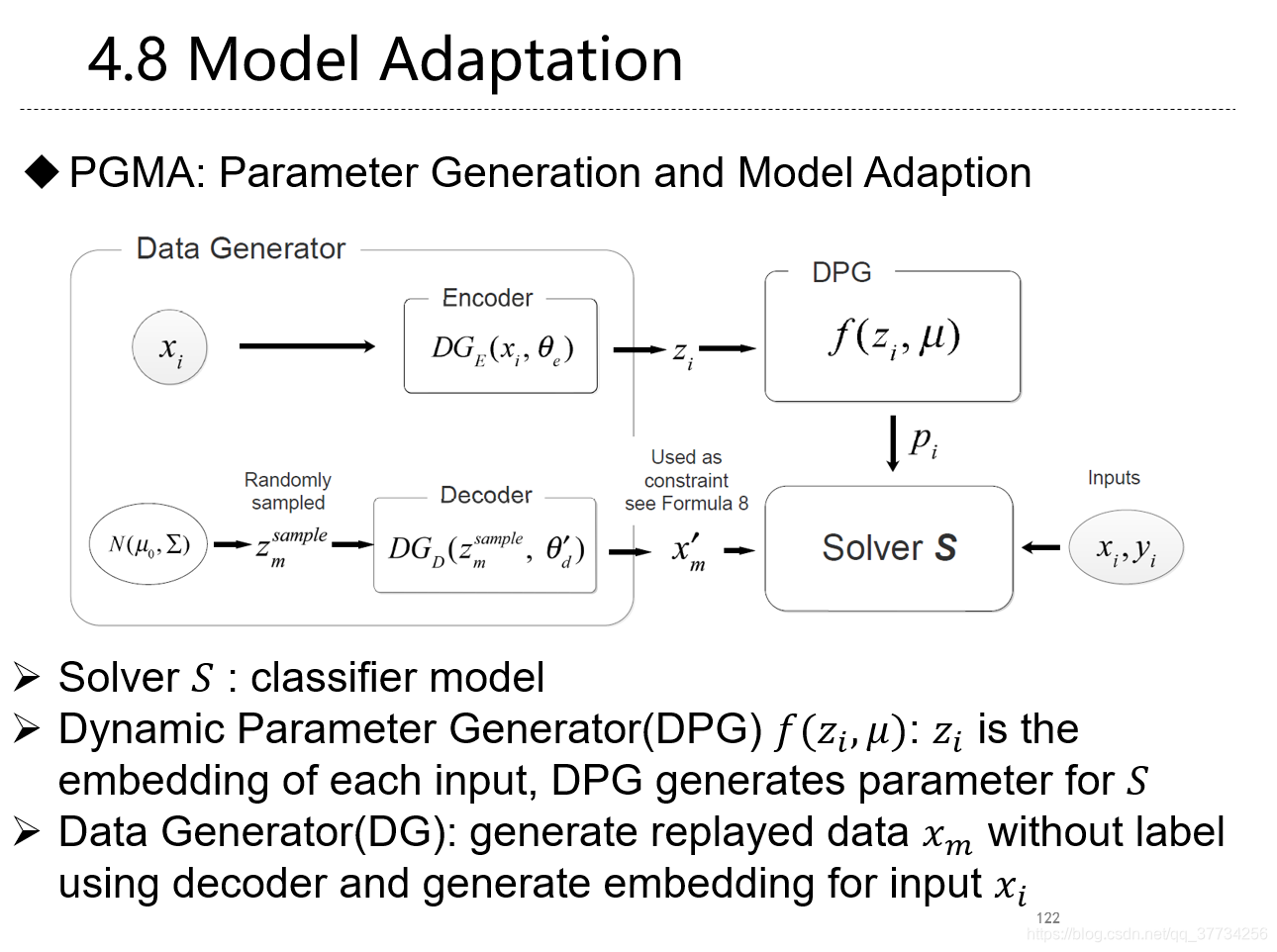
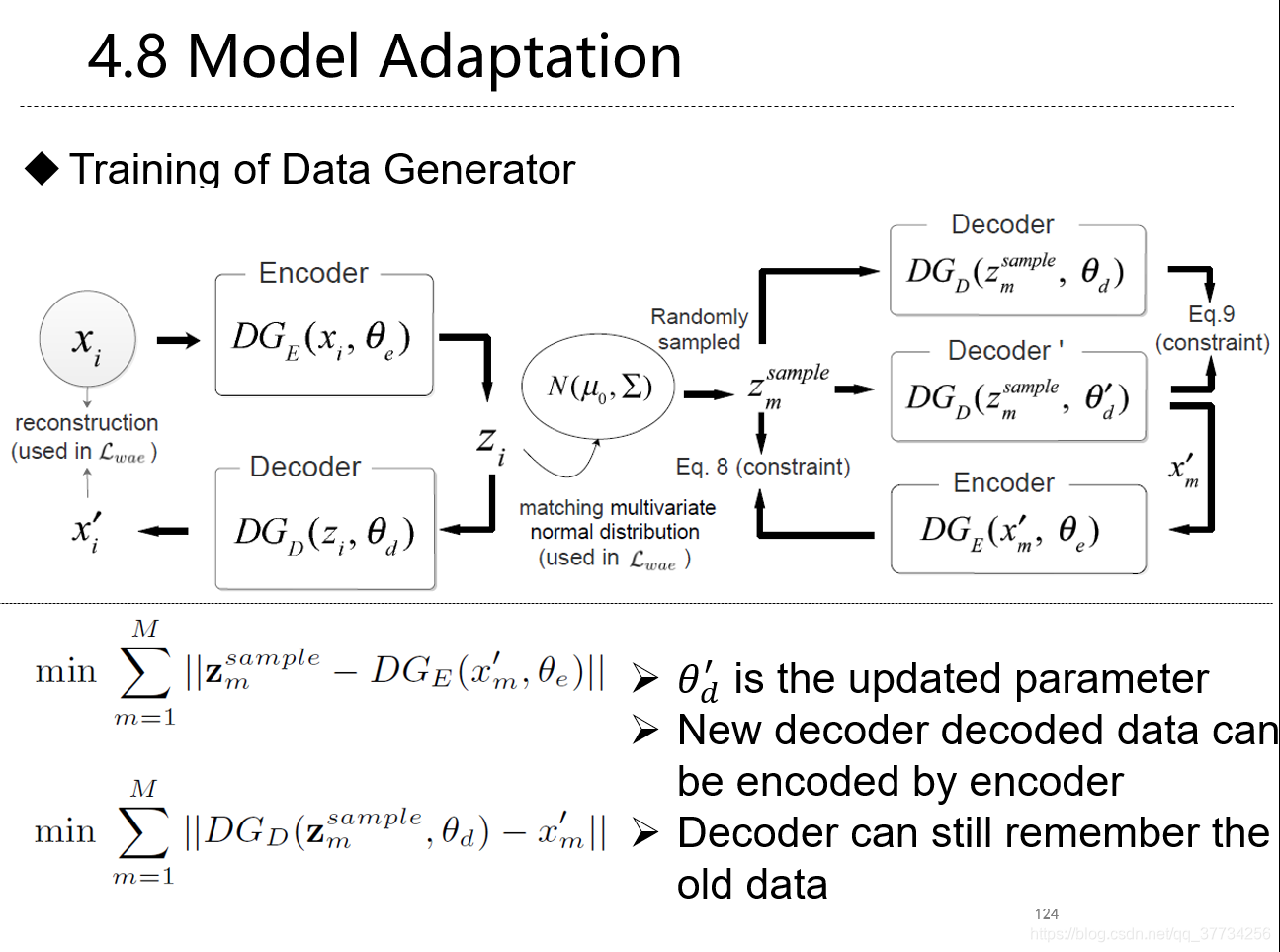
- Overcoming Catastrophic Forgetting for Continual Learning via Model Adaptation, ICLR, 2019, 提出使用模型适配来提升对每个样本的准确度,使用生成数据来进行回放,防止遗忘。
Federated Learning and security
- Abnormal client Behavior Detection in Federated Learning, NeuIPS WorkShop, 2019, 第一篇提出来基于侦测的方法来侦测联邦学习中异常梯度,使用自动编码器,而不是基于防御的方法。

- SignSGD with Majority Vote is Communication Efficient and Fault Tolerant, ICLR, 2019, 提出了使用多数投票的方式来进行梯度更新,梯度位只有1位,降低了通信量,提升了鲁棒性。同时文中还对Adam的收敛性进行了说明。

- Exploiting Unintended Feature Leakage in Collaborative Learning, S & P, 2019, 提出联合学习中,与主任务无关的属性会被泄露,例如年龄分类器会泄露性别,性别分类器会泄露人是不是戴眼镜。
- Property inference attacks on fully connected neural networks using permutation invariant representations, CCS, 2018, 以往属性推断攻击,很少针对神经网络,因为神经网络的可能性太大, 没办法穷举这么多,分别对这些模型*2,提供1个模型具有某属性(例如操作系统具有熔断漏洞),另1个不具有某属性(不具有该漏洞)的模型,2个模型分别训练得到梯度,梯度再分别作为label了的数据,送给属性推断攻击分类器进行训练。提出使用DeepSet的方法,将神经网络n!的可能性进行了大幅压缩。
- How To Backdoor Federated Learning, CoRR, 2018, 提出用模型毒化攻击联邦学习,比数据毒化更加有效,在文中,模型毒化没有很有效的防御方法,突破了现有的许多防御方法。
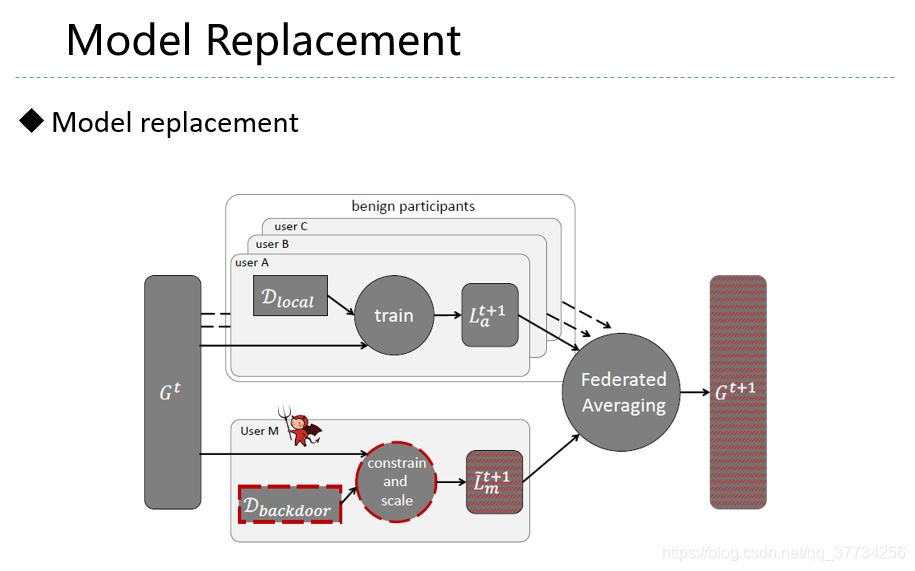
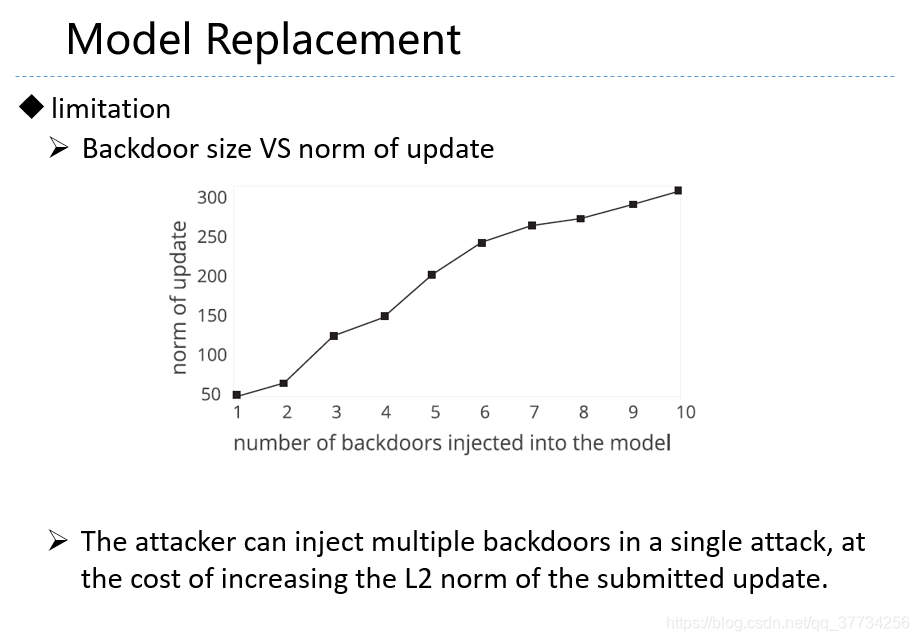
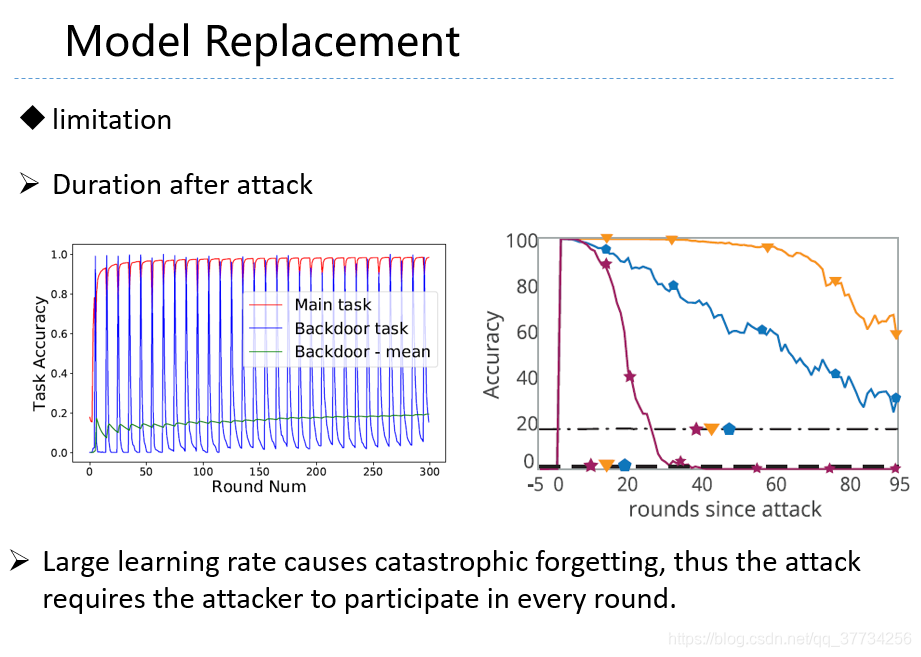
- Analyzing Federated Learning through an Adversarial Lens, ICML, 2019, 在上文的第1版的基础上,对学习率进行了修正,提出应该用大的学习率,上文的第2版指出,本文用大的学习率的方法,会造成遗忘,使得需要多联邦学习模型一直进行攻击才能保持较高的后门任务准确率。
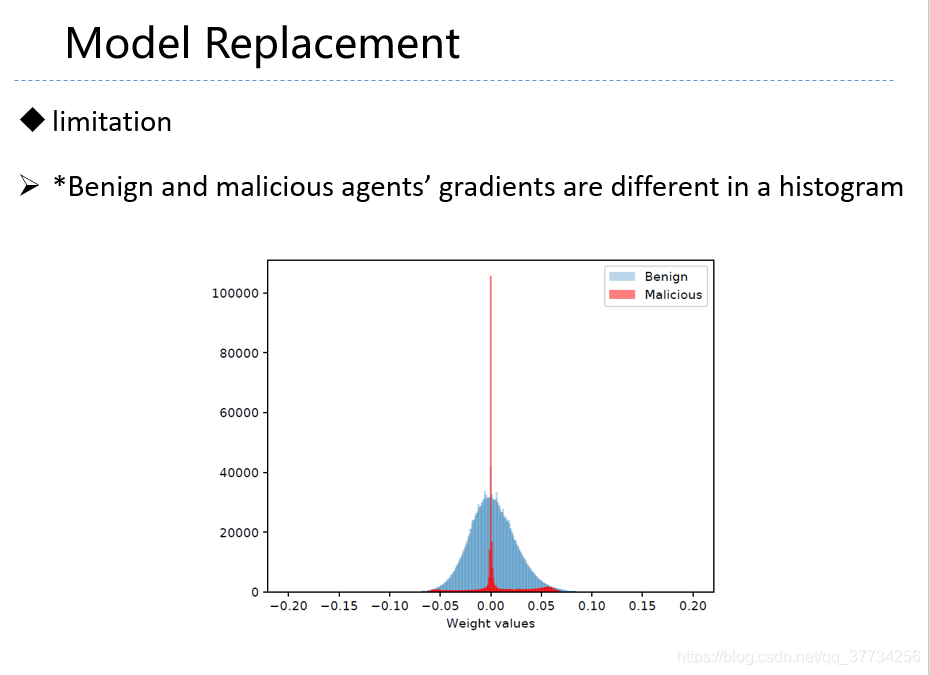
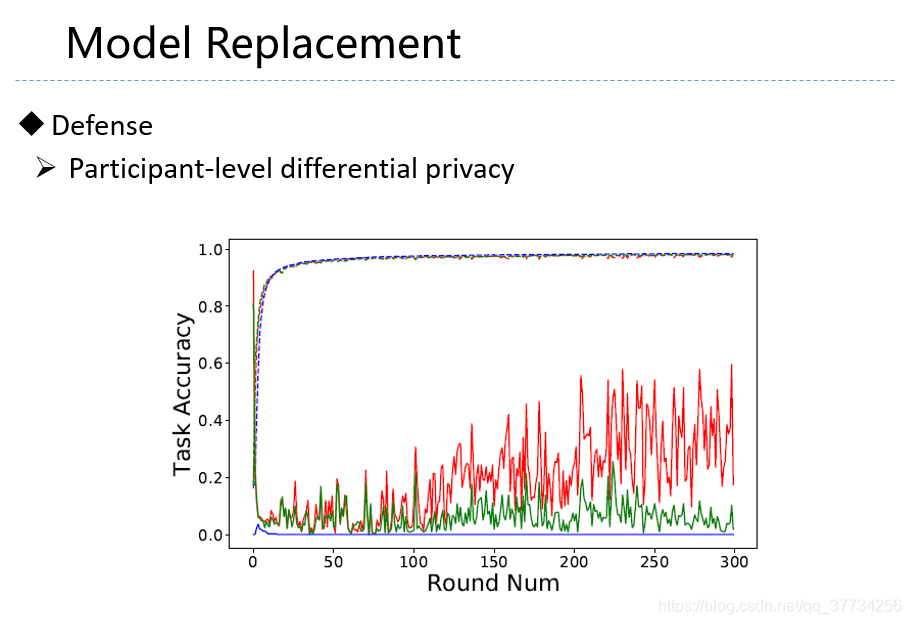
- Can You Really Backdoor Federated Learning, CoRR, 2019, 对联邦学习后门攻击进行了分析,有许多实验实例,文中,指出差分隐私和基于梯度范数值的防御,对后门攻击有一定效果。
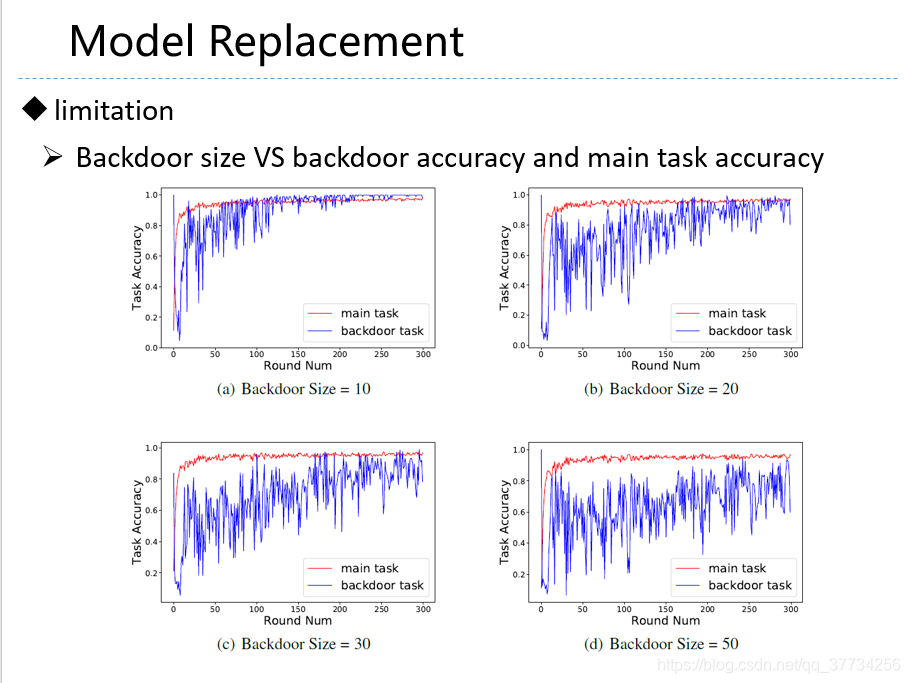
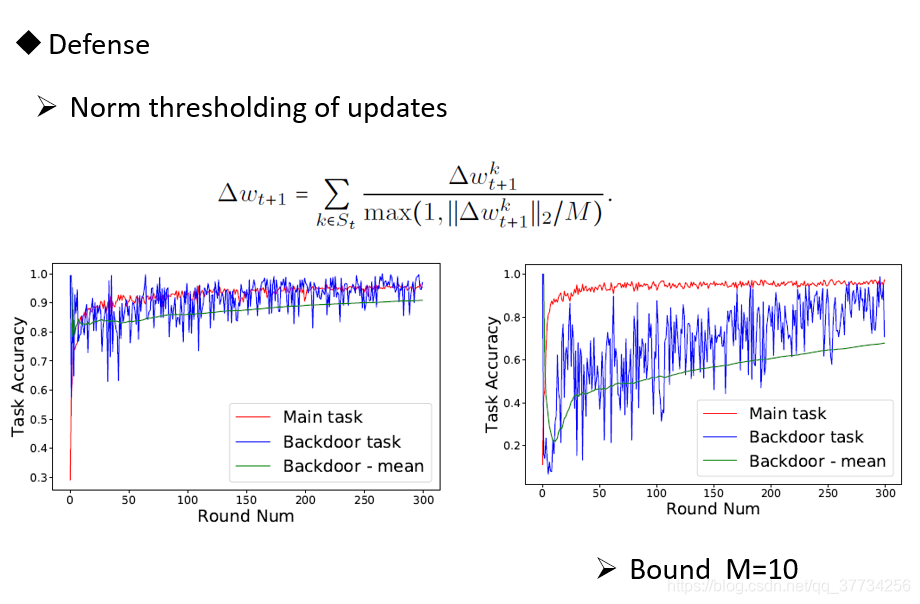
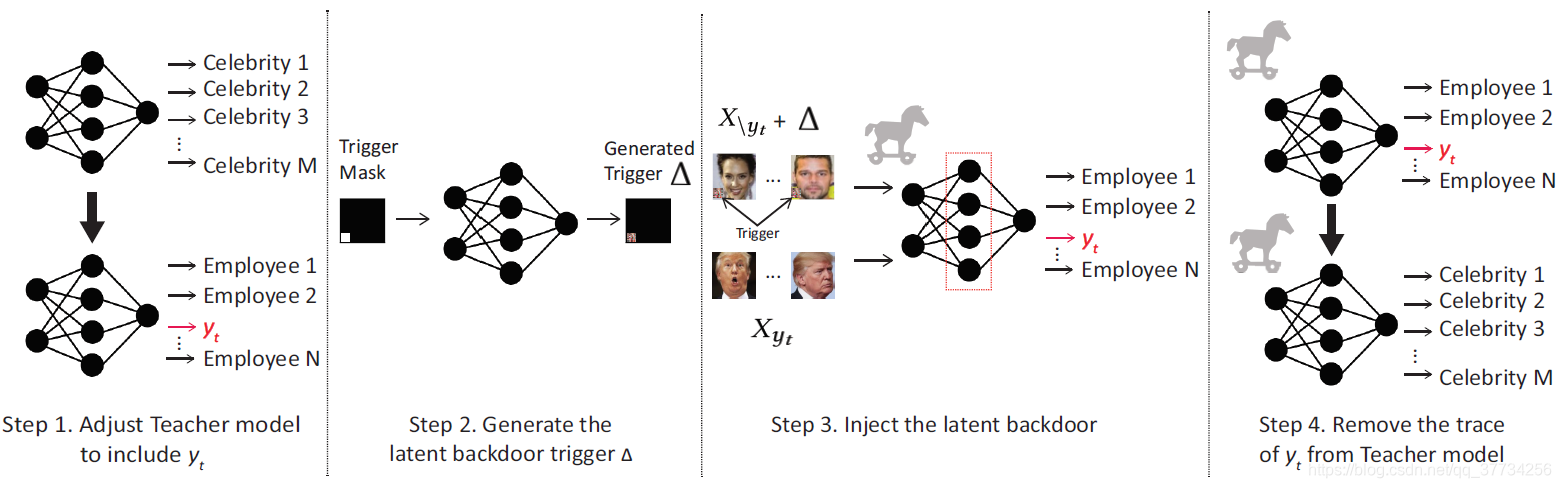
- Latent Backdoor Attacks on Deep Neural Networks, CCS, 2019, 提出了一种隐后门的攻击,攻击后的模型并没有后门任务的label,把后门藏在中间表示,隐藏性更好,现有方法无法防御。模型一旦被迁移学习,一旦迁移后的模型里面有后门任务的标签,后门任务就会被激活。

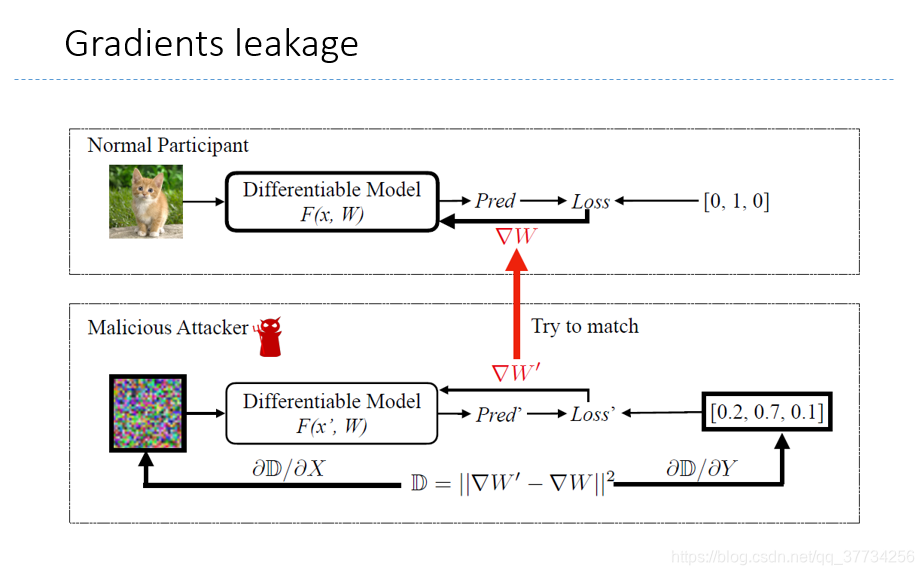
- Deep leakage from gradients, NeurIPS 2019, 从梯度泄露像素级别的图片,仅仅通过梯度,恢复原有图片,所以联邦学习中应该还是会进行安全聚合。


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/190875
推荐阅读
相关标签

