
- 1月球绘画软件测试,宇宙飞船简笔画:第一个登上月球的宇航员
- 2东方终焉组引导页自适应html源码 视频背景炫酷_博客引导页源码 源码
- 3Vue3+AntdesignVue3/ElementPlus a-upload实现上传(上传前控制类型,数量,多文件限制大小自动拦截)、预览、单个下载、删除(删除前确认)、批量下载(压缩包)(终极版)_ant design vue3上传大文件
- 4.net百度编辑器的使用
- 5Mysql数据库的高级应用(存储过程,触发器、索引,视图,函数)_mysql数据库高级应用
- 6低代码开发大势所趋,这款无代码开发平台你值得拥有_ivx编辑器
- 7数字化运营在教育行业的技术架构实践总结
- 8Android : Broadcast_broadcast of intent
- 9吃饭睡觉打豆豆_用java编写小明吃饭睡觉打豆豆
- 10Linux中的vi/vim编译(一)_linux对vi程序编译
对利用Python爬取到的房价信息做数据可视化(附完整代码)_支持向量机房价预测
赞
踩
大家好,我是带我去滑雪,每天教你一个小技巧!
1、数据展示
本文利用Python爬取到的房价信息做数据可视化,爬取数据的文章见:
(利用Python爬取房价信息(附代码)_用python爬取房价数据_带我去滑雪的博客-CSDN博客)
所爬取的指标有小区名称、房屋位置、房屋户型、房屋面积、房屋朝向、房屋装修情况、有无电梯、楼层位置、附件有无地铁、关注度人数、看房次数、每平方米价格、房屋总价等指标,具体数据展示见表1,表2。
表1 python爬取数据展示(一)
| 编号 | 标题 | 小区名称 | 房屋位置 | 房屋户型 | 房屋面积(m2 ) | 房屋朝向 |
| 1 | 鸿城花园 精致两房 南向高楼层 | 鸿城花园 | 市桥 | 2室2厅 | 78.6 | 西南 |
| 2 | 岭南新世界 带空中花园实用 | 岭南新世界 | 白云大道北 | 4室2厅 | 98 | 西南 |
| 3 | 隆康花园 2室1厅 255万 | 隆康花园 | 白云大道南 | 2室1厅 | 58.1 | 西南 |
| 4 | 南北对流 楼层好 视野宽阔 采光充足 | 荷景花园一区 | 沙湾 | 4室2厅 | 118 | 东南
|
表2 python爬取数据展示(续一)
| 编号 | 房屋装修情况 | 有无电梯 | 楼层位置 | 附近有无地铁 | 关注度(人数) | 看房次数 | 每平方米价格(元) | 房屋总价(万元) |
| 1 | 其他 | 有电梯 | 高楼层 | 有地铁 | 58 | 14 | 26718 | 210 |
| 2 | 其他 | 有电梯 | 低楼层 | 有地铁 | 2337 | 18 | 44184 | 433 |
| 3 | 简装 | 有电梯 | 中楼层 | 有地铁 | 25 | 18 | 43890 | 255 |
| 4 | 精装 | 无电梯 | 中楼层 | 无地铁 | 2106 | 6 | 16526 | 195 |
| 5 | 简装 | 无电梯 | 高楼层 | 无地铁 | 1533 | 7 | 15354 | 150 |
| 6 | 简装 | 有电梯 | 中楼层 | 有地铁 | 47 | 5 | 49164 | 570 |
2、数据预处理
数据预处理是指在数据集中发现不准确、不完整或者不合理的数据,通过数据预处理,对这些数据进行一定的去重、修补、纠正或移除,将原始数据转化成分析算法适用的形式,以此提高数据质量。由于爬取的数据中包含类别型数据,为了方便后面数据分析,本文对分类型数据进行了分别赋值,处理后的变量表见表3,处理后的数据集部分见表4。
表3 变量表
| 属性 | 解释 | 类型 | 变量名 |
| WSSL | 房屋的卧室数量(个) | 连续值 | x1 |
| KTSL | 房屋的客厅数量(个) | 连续值 | x2 |
| MJ | 房屋面积(平方米) | 连续值 | x3 |
| FWZXQK | 房屋装修情况 | 离散值,0=其他;1=毛坯;2=简装;3=精装 | x4 |
| YWDT | 有无电梯 | 离散值,0=无电梯;1=有电梯 | x5 |
| LCWZ | 房屋所在楼层位置 | 离散值,0=低楼层;1=中楼层;2=高楼层 | x6 |
| FJYWDT | 房屋附近有无地铁 | 离散值,0=无地铁;1=有地铁 | x7 |
| GZD | 关注度(人次) | 连续值 | x8 |
| KFCS | 看房次数 | 连续值 | x9 |
| PRICE | 每平方米价格(元) | 连续值 | y |
| TOTAL PRICE | 房屋总价(万元) | 连续值 | y1 |
表4 经过数据预处理后的数据集
| 编号 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | y | y1 |
| 1 | 2 | 2 | 78.6 | 0 | 1 | 2 | 1 | 58 | 14 | 26718 | 210 |
| 2 | 4 | 2 | 98 | 0 | 1 | 0 | 1 | 2337 | 18 | 44184 | 433 |
| 3 | 2 | 1 | 58.1 | 2 | 1 | 1 | 1 | 25 | 18 | 43890 | 255 |
| 4 | 4 | 2 | 118 | 3 | 0 | 1 | 0 | 2106 | 6 | 16526 | 195 |
| 5 | 3 | 1 | 97.7 | 2 | 0 | 2 | 0 | 1533 | 7 | 15354 | 150 |
| 6 | 3 | 2 | 115.94 | 2 | 1 | 1 | 1 | 47 | 5 | 49164 | 570 |
| 7 | 3 | 2 | 102.72 | 2 | 1 | 0 | 1 | 80 | 19 | 61332 | 630 |
| 8 | 3 | 2 | 102.72 | 2 | 1 | 0 | 1 | 80 | 19 | 61332 | 630 |
| 9 | 2 | 2 | 73.3 | 2 | 1 | 0 | 1 | 873 | 21 | 42292 | 310 |
| 10 | 3 | 2 | 92 | 2 | 1 | 1 | 0 | 64 | 14 | 22066 | 203 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2981 | 2 | 1 | 80.3 | 2 | 1 | 1 | 1 | 8 | 0 | 46700 | 375 |
| 2982 | 2 | 2 | 64.81 | 2 | 1 | 1 | 1 | 2 | 0 | 41352 | 268 |
| 2983 | 2 | 1 | 57.26 | 0 | 0 | 0 | 1 | 0 | 0 | 41041 | 235 |
| 2984 | 2 | 1 | 75.38 | 2 | 1 | 2 | 0 | 0 | 0 | 39799 | 300 |
3、数据分析
3.1 词云分析
词云是文本大数据可视化的一种重要方式,该方法可以将文本信息中重复出现的词语进行高亮展示,使浏览文本信息的人们可以一眼看到关键信息。本文利用python对表1中的标题文本信息进行词云分析,输出结果见图1所示。

通过图1可以发现,在某网站上所挂楼房标题词中最多的是中间楼层、精装修、看房方便、采光好、近地铁、楼层好等字样,说明可能具有这些特点的房子更能吸引买家的注意,进而影响房屋的价格。
绘制词云图
import pandas as pd
file = open(r'\title.xlsx','rb')
data = pd.read_excel(file)
data.columns
title = data['标题']
import numpy as np
import os
lis = np.array(title)
lis = lis.tolist()
lis[:5]
str1 = "".join(lis)
item_main = str1.strip().replace('span','').replace('class','').replace('emoji','').replace(' ','')
def save_fig(fig_id, tight_layout=True):
path = os.path.join(r" E:\工作\硕士\学习\统计软件python\期末作业", fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)
import jieba
wordlist = jieba.cut(item_main,cut_all=True)
word_space_split =" ".join(wordlist)
type(word_space_split)
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
import PIL.Image as Image
coloring = np.array(Image.open(r'\Desktop\图片.jpg'))
my_wordcloud = WordCloud(background_color='white',max_words=200,mask=coloring,max_font_size=60,random_state=42,
scale=2,font_path=r'C:\Windows\Fonts\simkai.ttf').generate(item_main)
image_colors = ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis('off')
save_fig('my_wordcloud_fangjia')
plt.show()
3.2 描述性分析
利用python对搜集到的数据进行描述性分析,为了更加清晰的展示数据,分别绘制了饼图、条形图、嵌套环形图等图形,绘制图形的python代码见附件,其结果见图2、图3、图4、图5、图6所示。
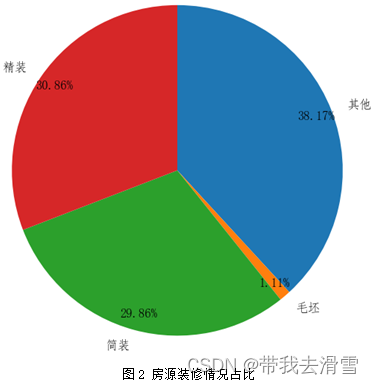
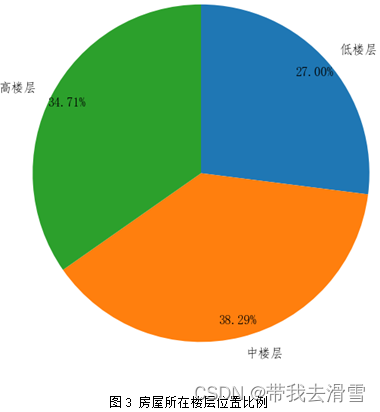
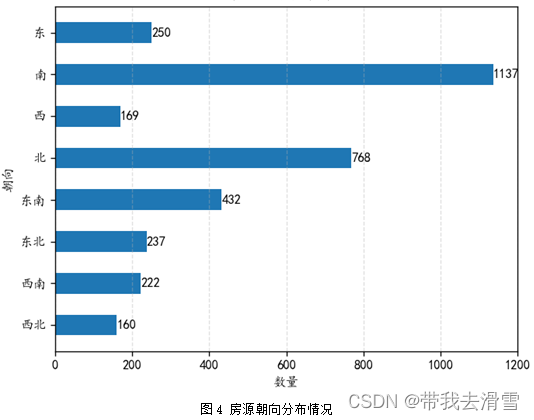
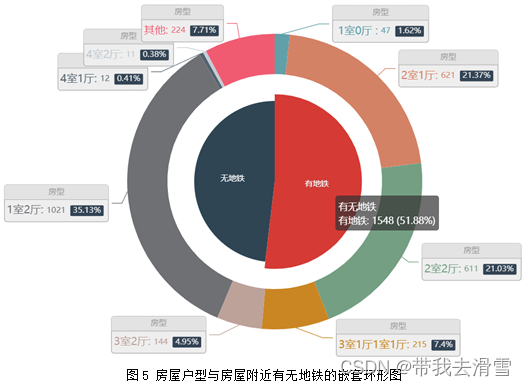
3.3 相关性分析
(1)房屋面积与房屋总价
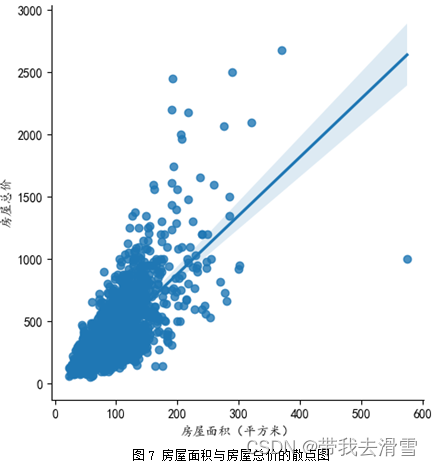
(2)房屋总价与关注度人数
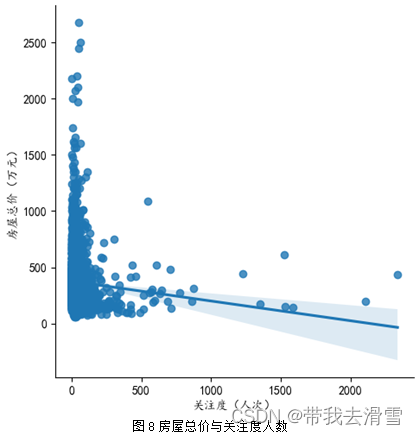
(3)房屋卧室个数与房屋总价
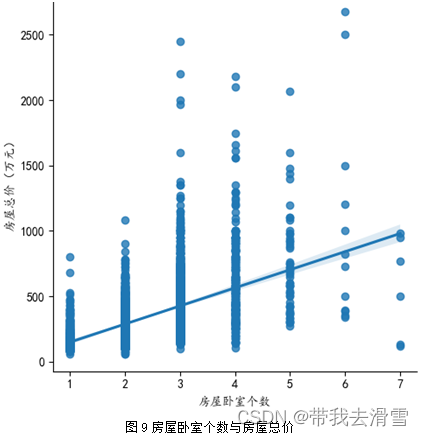
图2房屋装修情况占比饼状图
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r"E:\工作\硕士\学习\统计软件python\期末作业\qxhsj.csv")
plt.rcParams['font.sans-serif'] = ["Fangsong"]
plt.rcParams['axes.unicode_minus'] = False
# 设置画布大小
plt.figure(figsize=(12,6))
figure,axes = plt.subplots(1,1,figsize = (6,6),dpi = 120)
# 构造数据
y = [1139,33,891,921]
label=["其他", "毛坯", "简装", "精装"]
# 绘图
plt.pie(y,
labels=label, #
autopct='%.2f%%', # 让标签以百分比形式显示,且精确到两位小数
labeldistance = 1.1,
pctdistance = 0.9,
# shadow = True,
radius = 1,
startangle = 90,
counterclock = False
)
plt.title("房屋装修情况占比",fontsize = 12)
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib饼图.jpg", format="png")
# 可视化呈现
plt.show()
图3房屋所在楼层位置比例饼状图
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r"E:\工作\硕士\学习\统计软件python\期末作业\qxhsj.csv")
plt.rcParams['font.sans-serif'] = ["Fangsong"]
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12,6))
figure,axes = plt.subplots(1,1,figsize = (6,6),dpi = 120)
y = [806,1143,1036]
label=["低楼层", "中楼层", "高楼层"]
plt.pie(y,
labels=label,
autopct='%.2f%%',
labeldistance = 1.1,
pctdistance = 0.9,
# shadow = True,
radius = 1,
startangle = 90,
counterclock = False
)
plt.title("房屋所在楼层位置比例",fontsize = 12)
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib饼图.jpg", format="png")
plt.show()
图4房源朝向分布情况
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family']='KaiTi'
plt.figure(dpi=120)
provinces=['东', '南', '西', '北', '东南','东北', '西南', '西北']
gdp=[250, 1137,169, 768, 432,237,222,160]
plt.barh(provinces[::-1],gdp[::-1],height=0.5)
plt.title('房源朝向分布情况')
plt.grid(axis='x',ls='--',alpha=0.4)
plt.xlim(0,1200)
for i,j in enumerate(gdp[::-1]):
plt.text(j+0.05,i,j,va='center')
plt.xlabel('数量')
plt.ylabel('朝向')
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib条形图.jpg",format="png")
plt.show()
图5 房屋户型与房屋附近有无地铁的嵌套环形图
import pyecharts.options as opts
from pyecharts.charts import Pie
inner_x_data = ["有地铁", "无地铁"]
inner_y_data = [1548, 1436]
inner_data_pair = [list(z) for z in zip(inner_x_data, inner_y_data)]
outer_x_data = [' 1室0厅 ', '2室1厅', '2室2厅', '3室1厅' '1室1厅', '3室2厅','1室2厅', '4室1厅', '4室2厅','其他']
outer_y_data = [47,621,611,215,144,1021,12,11,224,81]
outer_data_pair = [list(z) for z in zip(outer_x_data, outer_y_data)]
(
Pie(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add(
series_name="有无地铁",
data_pair=inner_data_pair,
radius=[0, "30%"],
label_opts=opts.LabelOpts(position="inner"),
)
.add(
series_name="房型",
radius=["40%", "55%"],
data_pair=outer_data_pair,
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical"))
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
)
)
.render("nested_pies.html")
)
图6房屋总价分布图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family']='KaiTi'
plt.figure(dpi=120)
provinces=['57万-357万', '357万-657万', '657万-957万', '957万-1257万', '1257万-1557万']
gdp=[1829,869,206,52,12]
plt.barh(provinces[::-1],gdp[::-1],height=0.5)
plt.title('房价分布')
plt.grid(axis='x',ls='--',alpha=0.4)
plt.xlim(0,2000)
for i,j in enumerate(gdp[::-1]):
plt.text(j+0.05,i,j,va='center')
plt.xlabel('数量(套)')
plt.ylabel('总价')
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib条形图.jpg",format="png")
plt.show()
图7 房屋面积与房屋总价的散点图
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv(r"E:\工作\硕士\学习\统计软件python\期末作业\qxhsj.csv")
data.head()
sns.lmplot(x="x3", y="y1", data=data)
plt.xlabel('房屋面积(平方米)')
plt.ylabel('房屋总价')
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib.jpg", format="png")
图8 关注度人数与房屋总价的散点图
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv(r"E:\工作\硕士\学习\统计软件python\期末作业\qxhsj.csv")
data.head()
sns.lmplot(x="x8", y="y1", data=data)
plt.xlabel('关注度(人次)')
plt.ylabel('房屋总价(万元)')
plt.savefig(r"E:\工作\硕士\学习\统计软件python\matplotlib.jpg", format="png")
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/16GeXC9_f6KI4lS2wQ-Z1VQ?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
备注:明天更新两种预测房价的算法,分别是支持向量机和随机森林回归预测。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!

