
- 1VScode+Zotero+Latex文献引用联动
- 2算法:什么是红黑树
- 3【密码学】三、分组密码概述_密码算法里的圈函数是什么
- 4MySQL - 自动更新时间_modified_time
- 5鸿蒙 harmonyOS 使用Text文字超长时使用省略号结尾_truncation mode
- 6理解目标检测算法之R-FCN_r-fcn全称
- 7外贸常用的出口认证 | 全球外贸数据服务平台 | 箱讯科技
- 8(亲测有效)win11系统无需命令开启wsa并完美运行APP
- 9HarmonyOS/OpenHarmony-ArkTS基于API9元服务开发快速入门_harmony api9
- 10Nginx+Tomcat的Web服务器安装与配置_linux nginx和tomcat配置比赛
北京大学发布,将试错引入大模型代理学习!
赞
踩
引言:探索语言智能的新边界
在人工智能的发展历程中,语言智能始终是一个核心的研究领域。随着大语言模型(LLM)的兴起,我们对语言智能的理解和应用已经迈入了一个新的阶段。这些模型不仅能够理解和生成自然语言,还能够在多种环境中控制代理(agent)进行交互和决策。然而,尽管LLM在理解语言和规划方面展现出了巨大的潜力,它们在从经验中学习并改进行动策略方面仍存在限制。
传统的强化学习方法通过试错学习来训练代理策略,但这种方法往往忽略了代理在特定环境中的先验知识。而LLM正是在这方面表现出了优势。然而,直接对大规模的LLM进行策略模型微调在实践中是不切实际的,因此研究者们开始探索如何将历史交互融入提示中,以利用过去的经验来规划未来的行动。这些方法虽然有其局限性,但也提供了新的思路。
本文提出了一种新的学习范式,即通过学习扩展和精细化行动空间,使任务与代理的规划能力更加紧密对齐。研究者通过适应LLM的规划来解决固定行动空间带来的限制,例如常识知识引导的规划与行动之间的不匹配,以及由于未满足的先决条件或无效策略导致的行动错误。研究者们的方法不仅缓解了语言代理性能的瓶颈,还允许跨不同任务转移经验。
为了更具体地说明该方法,研究者们将介绍LearnAct框架,它旨在动态生成新的行动类型作为API,并通过反馈循环不断精炼行动。实验结果表明,LearnAct通过迭代精炼,不仅创造了复杂且用户友好的行动类型,而且相较于以往的方法,实现了更有效和高效的学习。
论文标题: Empowering Large Language Model Agents through Action Learning
论文链接:https://arxiv.org/pdf/2402.15809.pdf
LearnAct框架介绍:动态生成新的行动类型
1. LearnAct的核心理念与目标
LearnAct框架的核心理念是通过学习扩展和精炼行动空间,从而更紧密地与代理的规划能力相结合。与传统的语言模型代理不同,LearnAct不仅仅在预设的行动空间内操作,而是通过经验学习自然地扩展其行动类型。
这种方法解决了固定行动空间带来的限制,例如常识知识引导的规划与行动之间的不匹配,以及由于未满足的先决条件或无效策略导致的行动错误。
-
例如,在制作鸡尾酒的任务中,LearnAct允许LLM自然地指导代理按特定顺序收集所有组件并混合它们,而封闭的行动空间可能只涉及基本操作,如移动到不同地点和抓取瓶子,这大大增加了LLM代理的任务难度。
LearnAct通过动态生成新的行动类型作为API,利用LLM的广泛先验知识和代码生成能力来设计一个多样化和具有代表性的行动空间。此外,LearnAct的迭代学习策略通过反馈循环不断精炼行动,每个周期中,LLM使用训练示例评估当前行动的有效性,识别并纠正失败实例中的错误。
2. LearnAct的行动类型生成与迭代学习策略
LearnAct生成新的行动类型基于原子行动,以实现更具信息性和适用性的行动,类似于分层强化学习中的做法。不同于传统的分层强化学习,LearnAct不仅使用基于代码的行动空间,提供了更强的能力,还避免了严格的两级结构,而是使用灵活的混合级别行动。
LearnAct的行动类型生成涉及两个步骤:
-
首先,LLM被提示总结高级行动以完成任务,并以Python函数的形式为代理生成。这些函数可以调用多个基本或定义的行动来完成子任务。生成后,函数被解析并添加到行动空间中。
-
其次,生成新的行动函数后,研究者更新代理关于它们潜在应用的信息。基本指令包含行动描述和使用示例,更新后的策略指导包括每个函数的描述和使用示例。
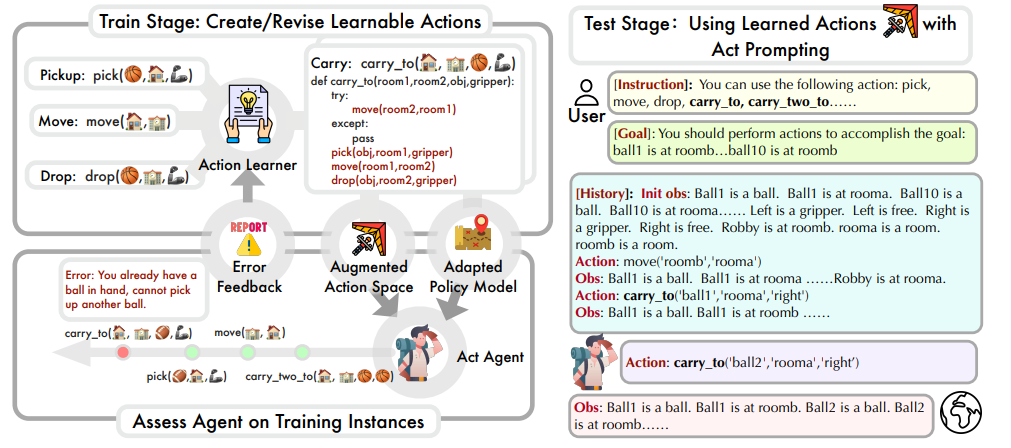
( 图为LearnAct的训练和测试阶段示意图)
在学习阶段,代理首先尝试用当前可用的行动空间和策略指令解决训练集中的问题,然后通过选择错误案例和行动学习操作来识别行动失败,并迭代更新行动集,直到成功解决所有实例中的行动错误或超过最大优化步骤。
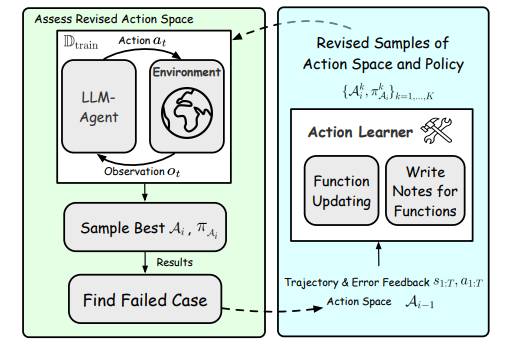
(在学习阶段,代理的动作使用和动作优化被重复执行)
行动学习通过实现函数更新或编写注释来解决错误,函数更新精炼Python函数以纠正对任务的误解和忽视,而编写注释则增强函数的描述,以指导代理更准确地使用行动。
LearnAct的实验设计:挑战与任务设置
1. 机器人规划任务
在机器人规划任务中,研究者在四个具有挑战性的任务上进行了实验,包括Gripper、Blockworld、Barman和Tyreworld。这些任务涉及长期机器人规划问题,例如根据客户订单使用可用成分和容器制作鸡尾酒,使用两个夹具在不同房间之间移动物体,或重新排列一堆积木以达到指定的目标配置。这些任务对代理的长期规划能力提出了重大要求。
2. 家庭环境任务
研究者还在AlfWorld任务上测试了代理,这些任务模拟了家庭环境中的六种目标。例如,代理需要在房子里找到一个苹果,加热它,然后将它放在目标区域。这些任务要求代理系统地探索房子,因为在代理观察到特定位置之前,环境的完整状态保持未知。此外,代理执行完成任务所需的基本步骤的能力至关重要。
LearnAct与现有方法的比较
1. 行动学习与语言智能的结合
LearnAct框架的提出,是为了解决现有大语言模型(LLM)控制的语言代理在学习经验方面的局限性。
-
传统的强化学习范式通过试错来学习代理策略,而LearnAct则通过生成新的动作类型作为API,利用LLM的广泛先验知识和代码生成能力,来构建一个多样化且具代表性的动作空间。
-
与此同时,LearnAct采用迭代学习策略,通过反馈循环不断完善动作。这种方法不仅创造了复杂且用户友好的动作类型,而且与先前的方法如Reflexion相比,实现了更有效和高效的学习。
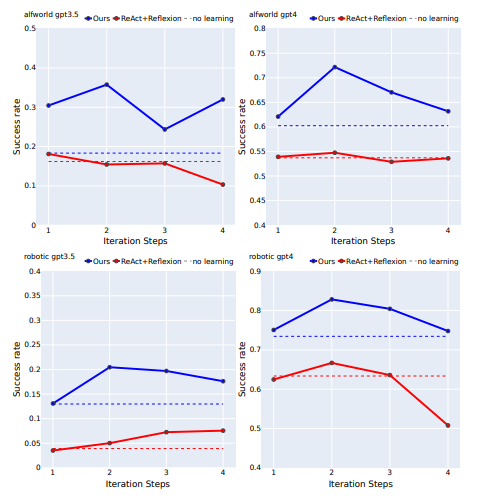
(图为不同最大学习迭代步数的性能)
2. LearnAct在不同任务中的表现
在实验中,LearnAct在机器人规划和AlfWorld任务中的表现明显优于其他基线模型。这表明,通过在动作空间内学习,LearnAct能够显著提高代理的性能。与直接在开环中生成代码的CodeAsPolicy方法和缺乏迭代动作学习的Voyager方法相比,LearnAct的动作学习对于提高动作质量至关重要。
学习过程分析:行动的可靠性与实用性
1. 行动学习前后的变化
通过对比学习前后动作的使用频率和准确性,可以看出学习后的动作在可靠性和实用性上有了显著提升。这是因为LearnAct的学习方法专注于纠正使用过程中遇到的错误。此外,动作的使用率在学习后也有所提高,这可能是因为代理在认识到这些动作的有效性后更倾向于使用它们。
2. 行动学习对性能的影响
LearnAct的学习过程通过动作的可靠性和实用性提高了代理的性能。在学习迭代的过程中,代理首先尝试用当前可用的动作空间和策略指令解决训练集中的问题,然后通过选择错误案例和动作学习来修正错误,直到成功解决所有实例或达到最大优化步骤。学习算法的各个组成部分,包括更新函数和编写注释,以及学习过程中的采样,都对提高性能起到了关键作用。
LearnAct的学习算法:功能更新与注释编写
1. 学习算法的关键组成部分
LearnAct的学习算法是一种新颖的学习范式,旨在通过扩展和细化动作空间来提升LLM代理的性能。这种方法的核心在于动态生成新的动作类型,这些动作类型以Python函数的形式出现,利用LLM的广泛先验知识和代码生成能力来设计一个多样化且具有代表性的动作空间。
通过这种方式,LearnAct不仅能够解决固定动作空间带来的限制,比如常识知识引导的规划与动作之间的不匹配,还能够跨不同任务转移经验。

在LearnAct的学习算法中,关键的组成部分包括:
-
动作创建:通过生成新的动作函数,LearnAct能够让LLM与环境更加无缝地交互。这些动作函数能够调用多个基础或已定义的动作来完成子任务,从而实现更复杂的逻辑表达。
-
策略指令生成:生成新动作函数后,需要更新代理的策略指令,以包含每个函数的描述和使用示例,从而指导LLM在适当的场景中使用新动作。
-
基于错误反馈的动作学习:在创建初始动作集后,可能存在错误或对任务的误解。LearnAct通过试错的训练阶段,让语言模型通过反馈循环不断地完善动作,包括修正函数或编写注释。
2. 学习算法的实际应用与效果
LearnAct的学习算法在实际应用中展现了显著的效果。在一系列的实验中,LearnAct通过迭代细化的方法,不仅创建了复杂且用户友好的动作类型,而且与先前的最先进方法相比,实现了更有效和高效的学习。例如上文中所述的制作鸡尾酒的任务。
在机器人规划和AlfWorld任务中,LearnAct的表现显著优于其他基线模型,无论是使用GPT-3.5 Turbo还是GPT-4作为后端。这些结果证明了LearnAct在动作空间学习方面的重要性,以及其在开发更智能和能力更强的LLM代理方面的潜力。
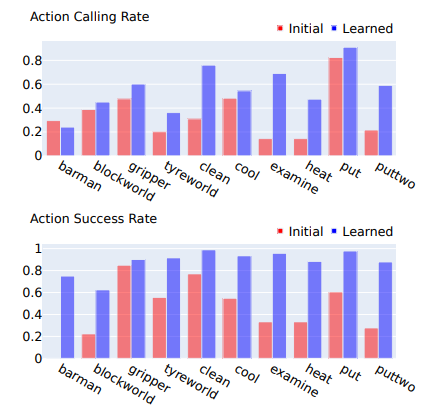
(图为学习前后所学动作的使用频率和准确性)
结论:LearnAct的贡献与未来展望
LearnAct通过其创新的学习算法,为大语言模型代理提供了一种新的能力:通过直接与环境互动来学习和完善动作。这种开放式的动作学习方法与人类获取和增强技能的方式密切相关。实验结果表明,LearnAct在机器人规划和AlfWorld环境中的成功应用,凸显了动作学习在发展更智能和能力更强的LLM代理方面的巨大潜力。
未来,我们期望LearnAct能够进一步提升其学习算法,以更好地适应各种复杂的任务和环境。随着LLM技术的不断进步,LearnAct有望在多个领域中发挥更大的作用,从而推动智能代理的发展和应用。




