
- 1RabbitMQ安装教程(Mac)_mac m2 安装rabbitmq
- 2Hbase表两种数据备份方法-导入和导出示例_hbase表备份到本地
- 3Android Studio日志工具Log的使用--建议收藏备用!_android studio log
- 4关于android 4.4短信(sms)接收流程-状态机篇_sms activity
- 5关于机器学习的十个实例_某公司根据用户在试用期的的行为模式和所有用户过去的行为,识别出哪些用户会
- 6airtest使用总结_airtest logcat的用法
- 7Backtrace 分析_event:app_scout_warning thread:main backtrace:
- 8新版本根据微信小程序api获取手机号_business/getuserphonenumber
- 9android DrawerLayout实现仿QQ侧滑菜单_安卓仿qq侧滑
- 10Docker重命名镜像名称和TAG_镜像更换名字
看书标记【R语言数据分析项目精解:理论、方法、实战 2】_r语言数据分析练手项目
赞
踩
【R语言数据分析项目精解:理论、方法、实战】
chapter 2 R语言基础
R语言用高深的理论作为支撑、用简捷的语法作为工具、用清晰明了的结论作为结果。
2.1 安装R语言
http://www.r-project.org/>>“Download”>>“CRAN”>>“Download R for Windows”>>“base”
https://www.rstudio.com/>>“Download”
Tool>>Global Options>>packages>>CRAN mirror>>选择距离较近的镜像
Help>>R Help
2.2 R语言基本对象
2.2.2 向量
1.创建向量
同一个向量中的数据类型必须保持一致
#创建向量
c(1,2,3,4)
c("a","b","c","d")
c(T,T,F,F)
- 1
- 2
- 3
- 4
2.向量索引(下标索引)
下标索引、which函数、subset函数、match函数、%in%
#向量索引 ## 下标索引 a<-c(5,6,7,8) #创建向量 a a[1] #取向量第一个元素 a[-1] #取除了第一个元素外的所有元素 a[c(1:3)] #取下标为1到3的元素 a[c(1,3)] #取下表为1和3的元素 ## which函数(获得下标) which(a==6) #找出向量a中等于6的元素所在下标 which(a>6 & a<=8) #找出向量a中大于6并且小于等于8的元素所在下标 which.max(a) #找出向量中最大元素所在的下标 which.min(a) #找出向量中最小元素所在的下标 ## subset函数(获得元素) subset(a,a>6&a<=8) ## match函数 a<-c(11,11,12,12,13,13,14,14) #符合的按顺序标记,不匹配的NA match(a,c(11,13)) #符合的按顺序标记,不匹配的标记为0 match(a,c(11,13),nomatch=0) #符合的按顺序标记,忽略13 match(a,c(11,13),nomatch=0,incomparables=13) ## %in% #判断对象是否包含某项数据,存在返回T,否则返回F a<-c(11,11,12,12,13,13,14,14) #查看11和15是否在向量a中出现 c(11,15) %in% a

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
3.向量编辑
#1)向量扩展 a<-c(1,2) b<-c(3,4) ab<-c(a,b) ab ad<-c(a,c(7,8)) ad #2)向量元素修改 a<-c(1,2,3,4) a[2]<-5 a #3)向量元素删除 a<-c(1,2,3,4) a[-3] #4)去除向量内重复元素 a<-c(1,3,2,5,4,3,2,1,8,3,9,1) unique(a) #5)给向量元素命名 x <- c(2.1, 4.2, 3.3, 5.4) yy<-setNames(x,letters[1:4]) yy names(yy) yy["a"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.向量排序
rev():依据向量下标倒排序(按下标倒放)
sort():依据向量中实际数值的大小排序(升序)
a<-c(1,3,2,5,4,3,2,1,8,3,9,1)
rev(a)
sort(a)
sort(a,decreasing=TRUE) #降序
- 1
- 2
- 3
- 4
5.向量间的操作
#1)比较向量大小 aa<-c(1,2,3,4) bb<-c(2,1,2,5) cc<-pmin(aa,bb) ##把向量对应位置里最小的数据集合成一个新的向量 cc dd<-pmax(aa,bb) ##把向量对应位置里最大的数据集合成一个新的向量 dd #2)向量集合运算 a<-c(1,3,4,6,2) b<-c(7,8,3,2) intersect(a,b) ##求交集 union(a,b) ##求并集 setdiff(a,b) ##求差集 注意a、b的位置 #3)判断两个集合的包含关系 a<-c(1,2,3,4,5,7) c<-c(1,2,6) all(c%in%a)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6.创建等差序列和重复序列
#1)创建等差序列 seq(from第一项数值,to最后一项数值,by步长,length.out产生序列长度) #生成一个首项1,末项为-9,默认步长为-1的等差序列 seq(1,-9) #生成一个首项1,末项为-10,步长为-2的等差序列 seq(1,-10,by=-2) #生成一个首项1,步长为3,长度为5的等差序列 seq(1,by=3,length.out=5) #2)创建重复数据 rep(x重复的对象,times重复次数,length.out产生序列的长度,each每个元素的重复次数) #重复序列两次 rep(1:3,2) #每个元素重复3次 rep(1:3,each=3) #对应元素重复相应的次数 rep(1:3,c(1,2,1)) #每个元素重复2次,输出长度为4 rep(1:3,each=2,length.out=4) #每个元素重复3次,并且反复3次上述行为 rep(1:3,each=3,times=3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.3.3 矩阵和数组
# 1)创建矩阵matrix(data矩阵元素,nrow行数,ncol列数,byrow按行填充,dimnames以字符向量表示) data<-c(1:10) a<-matrix(data,ncol=2,nrow=5) a a<-matrix(data,ncol=2,nrow=5,byrow=T) a data<-c(1:10) a<-matrix(data) #设置行数为2,列数为5 dim(a)<-c(2,5) a data<-c(1:10) a<-matrix(data,ncol=2,nrow=5,dimnames= list(c("r1","r2","r3","r4","r5"),c("c1","c2"))) a #row函数和col函数 a row(a) col(a) # 2)矩阵索引 # a["r3","r2"]=a[3,2] # a[[8]]第八个元素 a<-matrix(c(1:10),ncol=2,nrow=5,dimnames=list(c("r1","r2","r3","r4","r5"),c("c1","c2"))) a[[8]] #4)使用单一维度选取 data<-c(1:10) a<-matrix(data,ncol=2,nrow=5,dimnames=list(c("r1","r2","r3","r4","r5"),c("c1","c2"))) a #选取3~5行的数据 a[c(3:5),] # 3)矩阵编辑 #1)矩阵合并 行数或者列数相同 a<-matrix(1:10,nrow=5) a b<-matrix(1:15,nrow=5) b #矩阵横向合并 cbind(a,b) #2)删除矩阵 a[-1,] #删除第一行数据 a[,-1] #删除第一列数据 #3)反转矩阵的行或列 a[rev(1:nrow(a)),] #反转矩阵a的行 a[,rev(1:ncol(a))] #反转矩阵a的列 #4)选取矩阵子集 a<-matrix(1:12,4,3) a[1:2,2] a[1:2,2,drop=FALSE] #5)选取满足条件的行或列 a[a[,1]<3,] #6)用矩阵内的元素值作为下标 #手动输入矩阵元素,手动输入18个数值,然后按两下回车 mat<-matrix(scan(),ncol=3,byrow=TRUE) 1: 1 1 12 1 2 7 2 1 9 2 2 16 3 1 12 3 2 15 19: Read 18 items #预设一个3*2 值为NA的矩阵 newmat<-matrix(NA,3,2) #使用mat中的值作为newmat的下标,再进行赋值 newmat[mat[,1:2]]<-mat[,3] newmat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 矩阵运算
加减乘除:+、-、、/.
对各行/列求和:rowSums()/colSums()
对各行/列求均值:rowMeans()/colMeans()
转置:t()
求行列式:det()
矩阵乘法:A%*%,分项乘积之和
矩阵内积/外积:crossprod()/outer()
A+1:各个元素都加1
矩阵求解(DX=A):solve(D,A)
特征值和特征向量:eigen(D)
求逆矩阵:solve(x)
取对角线元素或生产对角矩阵:diag()
a<-matrix(1:9,nrow=3,ncol=3) b<-matrix(9:1,nrow=3,ncol=3) c<-matrix(c(1,3,2,3,2,5,4,3,2),nrow=3,ncol=3) a+b #矩阵加法 a-b #矩阵减法 a*b #矩阵乘法 a/b #矩阵除法 rowSums(a) #行求和 rowMeans(a) #行平均 colMeans(a) #列平均 t(a) #矩阵a转置 det(c) #矩阵c的行列式 a%*%b #数学意义矩阵乘法 crossprod(a,b) #矩阵内积 outer(a,b) #矩阵外积 eigen(a) #矩阵特征值及特征向量 solve(c) #求逆矩阵 solve(c,a) #求cx=a diag(a) #对角线元素 #5)数组创建array(data数组的元素,dim数组维数,dimnames各维度名称标签列表) data<-c(1:30) dim1<-c("n1","n2","n3") dim2<-c("m1","m2","m3","m4","m5") dim3<-c("o1","o2") a<-array(data,dim=c(3,5,2),dimnames=list(dim1,dim2,dim3)) a #7)数组维度转换 没看懂 d<-array(1:24,dim=c(2,3,4)) d aperm(d,c(2,3,1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2.2.4 列表
#1)列表创建 mylist<-list(a1=c(1,3,5),a2=T,a3=c(2i+1,-4i+3),a4=c("a","b")); mylist #2)列表索引 mylist[[1]] mylist[1] #3)列表编辑 #1)列表合并 mylist2<-c(mylist,list(e=c(T,T,F,F))) #注意下述两个合并的效果: x<-list(list(1,2),c(3,4)) x str(x) y<-c(list(1,2),c(3,4)) y str(y) #2)列表转换为向量 unlist(list(c(1:3),c("one","two")))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.2.5 数据框
#1)数据框创建 names<-c("a","b","c","d") score<-c(2,3,2,1) id<-c(1,2,3,4) df<-data.frame(name=names,sco=score,id=id) df #矩阵转数据框 data.matrix<-matrix(1:12,c(3,4)) data.frame(data.matrix) #2)查看及修改列名称 #输出列名 names(df) #找到要修改的列名进行赋值修改 names(df)[2]<-"score" names(df) #3)数据框索引 #1)索引列 df$name df[["name"]] df[[1]] df[,1] df[,1:2] #读取多列数据 #2)索引行 df[1:2,] #3)索引元素 df$name[1] #选取name列的第一行元素 df[["name"]][1] df[[2]][1] #选取第二列的第一行元素 df[1,2] ##选取第二列的第一行元素 df[1:2,c(1,3,2)] #选取第一、三、二列的第一、二行数据 #4)筛选数据 subset(df,id>2&id<=4,select=c(name,id)) #4)编辑数据框 #1)数据框合并 df_a<-data.frame(id1=c(2,1,4,3),id2=c(3,7,6,9)) cbind(df,df_a) #横向连接 增加数据框属性 df_b<-data.frame(name=c("e","f"),score=c(4,3),id=c(5,6)) rbind(df,df_b) #纵向连接 增加数据框记录条数 #2)数据框删除 df_a[-1,] df_b[,-1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2.2.6 因子
#1)生成因子 colour <- c('G', 'G', 'R', 'Y', 'G', 'Y', 'Y', 'R', 'Y') col <- factor(colour) #创建因子 col #将因子水平设置为Green、Red、Yellow col1 <- factor(colour, levels = c('G', 'R', 'Y'), labels = c('Green', 'Red', 'Yellow')) col1 #将因子水平设置为1,2,3 col2 <- factor(colour, levels = c('G', 'R', 'Y'), labels = c('1', '2', '3')) col2 col_vec <- as.vector(col2) #转换成字符向量 col_num <- as.numeric(col2) #转换成数字向量 col_vec col_num #因子水平为Y的没有设置水平,默认转化为NA col3 <- factor(colour, levels = c('G', 'R')) col3 #2)有序和无序因子 factor(c(1,2,3,4)) a<-factor(c(1,2,3,4),levels=c(3,2,1,4),ordered=TRUE) a #3)选择参照因子 str(InsectSprays) head(InsectSprays) InsectSprays$spray relevel(InsectSprays$spray,'C') #4)重排因子顺序 #因子spray根据count的均值大小排序 reorder(InsectSprays$spray,InsectSprays$count,mean) #5)查看因子和设置水平 a<-as.factor(c(1,2,3)) a levels(a) levels(a)[1] a nlevels(a) # 2.数值型因子计算 fert<-c(10,20,20,50,10,20,10,50,20) fert<-factor(fert,levels=c(10,20,50),ordered=TRUE) mean(as.numeric(levels(fert)[fert])) #1 mean(as.numeric(as.character(fert))) #2 #3.因子操作 #1)取因子子集 ltes<-sample(letters,size=100,replace=TRUE) ltes<-factor(ltes) ltes[1:5,drop=TRUE] table(ltes[1:5,drop=TRUE]) #2)两因子合并 fact1<-factor(sample(letters,size=10,replace=TRUE)) fact2<-factor(sample(letters,size=10,replace=TRUE)) fact12<-factor(c(levels(fact1)[fact1],levels(fact2)[fact2])) fact12 #3)多个因子交互成组合因子 data(CO2) str(CO2) #各因子交互水平组合: newfact<-interaction(CO2$Plant,CO2$Type) #各因子交互水平组合,去除那些在原始数据中没有数值的因子组合 newfact<-interaction(CO2$Plant,CO2$Type,drop=TRUE) #4.连续型变量创建因子 #1)连续型变量离散化 #breaks为单个整数值: x<-rep(0:8,c(9,4,6,5,3,10,5,3,5)) #breaks为向量 cut(x, breaks = 2:3, labels = FALSE) #labels为TRUE时因子就表示为区间,即标签 cut(x, breaks = 2:3) cut(x, breaks = 3*(-2:5), right = FALSE) #左闭右开 cut(x, breaks = 2*(0:4), right = FALSE) table( cut(x, b = 8)) y <- c(1,2,3,4,5,2,3,4,5,6,7) #生成因子有顺序,dig.lab表示区间分割值为4位小数 cut(y, 3, dig.lab = 4, ordered = TRUE) #2)日期和时间的因子 #生成时间序列 everyday<-seq(from=as.Date('2005-01-01'),to=as.Date('2005-12-31') ,by='day') #设置日期格式 cmonth<-format(everyday,'%b') #创建时间因子 months<-factor(cmonth,levels=unique(cmonth),ordered=TRUE) #按每周分割 wks<-cut(everyday,breaks='week') #5.因子存储方式 chavec<-c("a","b","c","d") class(chavec) chavec_fac<-factor(chavec,ordered=TRUE) class(chavec_fac) storage.mode(chavec_fac) #参看存储格式 as.numeric(chavec_fac) levels(chavec_fac)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
2.2.7 数据类型的辨别和转换
is.numeric():辨别是否为数值型;as.numeric:转换为数值型
is.character():辨别是否为字符型;as.numeric:转换为字符型
is.vecter():辨别是否为向量;as.vecter:转换为向量
is.matrix():辨别是否为矩阵;as.matrix:转换为矩阵
is.data.frame():辨别是否为数据框;as.data.frame:转换为数据框
is.factor():辨别是否为因子;as.factor:转换为因子
is.logical():辨别是否为逻辑值;as.logical:转换为逻辑值
2.3 工作空间和查看对象
#2.3.1 工作空间和工作目录 getwd() setwd("d:\\Users\\rjluo\\Desktop\\R语言工作空间") #查看对象 ls() gc() rm(drv) help(lm) options(digits=2) history() savehistory("test") savehistory("myhistory") loadhistory("myhistory") save(age_gen,file="myobject") save.image("myworkspace") load("myworkspace") q() #2.3.2 遍历、创建、删除文件夹 #遍历当前工作目录下的所有文件 list.files(getwd()) #遍历当前工作目录下所有R脚本 list.files(getwd(),pattern = '*.[R|r]$') #创建文件夹 dir.create("tmp") #删除文件夹 unlink("tmp") #如果tmp为空则删除文件夹 unlink("tmp",recursive=F) #删除文件夹tmp内的所有内容 unlink("tmp",recursive=TRUE) #2.3.3 查看对象方法 df<-data.frame(id=c(1,2,3,4),score=c(22,12,32,55)) class(df) length(df) #查看对象 ls() #删除对象mat rm(mat) summary(df) str(df) names(df) dim(df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
2.4 数据导入和导出
2.4.1 数据导入
着重MySQL 与R的链接
#1)txt文件 #设定路径 setwd("D:\\创作文档\\审查稿件\\2 第二章 R语言") #放文件夹的地方 #读取数据 readtxt<-read.table("readme.txt",header=TRUE,as.is=FALSE) a #2) csv文件 setwd("D:\\创作文档\\审查稿件\\2 第二章 R语言") readcsv<-read.csv("readme.csv",header=TRUE) #sep允许导入那些使用逗号以外的符号来分隔行内数据,sep=“\t”读取以制表符分隔的文件,默认为sep="",分隔符可以是一个或多个空格、制表符、换行符或回车符 #3) Excel文件 library(xlsx) #读取testexcel中的第一个sheet readxlsx<-read.xlsx("readme.xlsx",1) #还有readxl函数包也可以加载Excel文件 #as.data.frame 是否保存为dataframe #loadWorkbook():将XLSX文件载入R中作为对象 #getSheets():将R中XLSX对象的表读出并作为对象 #removeRow():可删除某XLSX表对象中的行 #addDataFrame():可向某XLSX表对象中添加数据框 #saveWorkbook():可保存修改过的XLSX对象为XLSX文件 #4) 复制剪贴板数据 read.delim(file,header=TRUE,sep="\t",quote="\",dec=".",fill=TRUE,comment.char="") read.table("clipboard",header=TRUE) #5)从其他软件的数据文件中读入 read.spss(file,to.data.frame=TRUE) #从SPSS中读入数据
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
6)数据库连接及操作
配置好环境后,还需要加载RODBC程序包
常用函数
odbcConnect(dsn,uid=“”,pwd=“”) : 建立并打开连接
sqlTables(channel) :查看数据库表结构
sqlColumns(channel,sqltable) :查看某一张表的表结构
sqlSave(channel,dfname,tablename=sqtable,append=TRUE) :把R中的对象存入SQL server中
sqlFetch(channel,sqtable) :从数据库中读表
sqlQuery(channel,query) :在数据库中查询数据
sqlDrop(channel,sqtable) :删除表
close(channel) :关闭连接
#加载包
library(RODBC)
conn<-odbcConnect("olap",uid="myname",pwd="pwd") #建立连接
sqlTables(conn) #查看数据库中的表信息
sqlColumns(conn,"olapmbuipcategorySDK") #查看数据库中表结构
sqlSave(conn,mtcars,rownames='state',append=TRUE) #保存R对象到数据库中
sqlFetch(conn,"mtcars",rownames="state") #获取表的所有内容
sqlQuery(conn,"select cyl from mtcars where gear=4") #查询数据
sqlDrop(conn,"mtcars") #删除表
close(conn) #关闭连接
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.4.2 数据导出
write(x,file,append=FALSE)
x:数据源
file:输出文件
append:是否清空原有数据,默认FALSE,若为TRUE,则在文件原有内容的基础上追加写入
write.table()
x:要输出的对象
file:要输出到的文件名和路径
append:逻辑值,表示x是否追加到已有的excel中
quote:TRUE时,所有字符型和因子输出时带双引号,若是数字向量,则其元素被作为列索引引用。
sep:每行中数值的分隔符
na:用于数据中缺失值的填充
dec:小数点的字符
row.names、col.names:逻辑值,行名标签是否输出
#将对象mtcars输出到mtcars的txt文件中
write.table(mtcars,file='mtcars.txt',sep=",")
#将对象mtcars输出到test的xlsx文件中,sheet名称设为test
write.xlsx(mtcars,"test.xlsx",sheetName="test")
#将mtcars输出到mtcars的csv文件中
write.csv(mtcars,file="mtcars.csv")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.5.1 操作符和函数
一些运算符
!= :不等于
!x:非x
x|y :x或y
xor(x,y) :x和y的值不同,返回TRUE,反之返回FALSE
x%in%y: x中的元素是否在y中
identical(x,y):x和y是否相同,且位置是否相同
all.equal(x,y):x和y是否近似相等
is.element(x,y):x中的元素是否在y中
is.na:识别有无缺失值
complete.cases:识别矩阵或数据框中没有缺失值的记录
#---&和&&的区别 c(TRUE, FALSE) & c(TRUE, TRUE) c(TRUE, FALSE) && c(TRUE, TRUE) ##当左边是FALSE时不管右边是什么结果都是FALSE FALSE&&A ##这个会报错因为:当左边是TRUE时候需要判断右边 TRUE&&A #&不管左边是什么都需要判断右边的对象 TRUE&A FALSE&A #--all.equal和identical区别 all.equal(1.1,1.4-0.3) identical(1.1,1.4-0.3) #3)赋值函数 X <- 0 Fun <- function() { X<<-5 } Fun() x #assign和get 赋值和获取值 #下述两个赋值等价 x<-c(1,2,3,4) assign("x",c(1,2,3,4)) x assign("xxx[1]",1) xxx xxx[1] ##若赋值对象是文本,那么只能赋值,而只有get函数能查看 get("xxx[1]") x get("x[1]") a<-x[1] a get("a")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.5.2 函数
1.数学函数


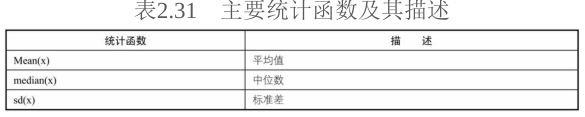
2.统计函数

#----概率函数 normdt<-rnorm(20) #生随机数(随机偏差) normdt dnorm(normdt) #密度函数 pnorm(normdt) #分布函数 qnorm(0.9,mean=0,sd=1) #分位数函数 #----字符串函数 x<-c("ab","cde") length(x) nchar(x) #x中的字符数量 x<-"abcdef" substr(x,2,4) #替换的字符串个数大于要替换的字符串个数,多余部分不变 substr(x,2,4)<-"2" x substr(x,2,4)<-"222" x grep("A",c("b","A","c")) sub("abc","a","abdscabcac") strsplit("abc","") x<-"aBCDabE" tolower(x) #大写转换 toupper(x) #小写转换 #----输出函数 for(i in 1:3) print(1:i) name<-"peter" cat("name:",name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.6 数据集操作
2.6.1 变量操作
#1) 创建新变量 #将系统自带的mtcars中的两列选出来 mydata<-mtcars[,c("gear","carb")] #增加两列数据:sumx是gear和carb的总和;meanx是gear和carb的均值 mydata<-transform(mydata,sumx=gear+carb,meanx=(gear+carb)/2) head(mydata) #生成一个序列 id<-rep(1,nrow(mydata)) #直接新增一个列并赋值 mydata$id<-id #选取前n条数据 head(mydata) #2) 删除列变量 #删除最后一列 mydata[,-1] #批量删除列名 myvars<-names(mydata)%in%c("id","meanx") newdata<-mydata[!myvars] head(newdata) #3)对变量重新编码 mydata<-mtcars mydata$dd<-mydata$wt attach(mydata) mydata[which(wt <= 2), ]$ dd<-"第一组" mydata[which(wt > 2 & wt<= 4), ]$dd <-"第二组" mydata[which(wt > 4), ]$dd<- "第三组" detach(mydata) head(mydata) #4)变量重命名 names(mydata) names(mydata)[2]<-"newcyl" names(mydata) #5) 变量排序 sort(mtcars$mpg) # 用sort函数对向量进行排序,返回排完序后的向量 sort(mtcars$mpg,decreasing=TRUE) # 倒序排列 #用rank函数对向量排序,返回相应的秩 x<-c(2,3,1,4,3,4,7,5,4) x rank(x) rank(x,ties.method="first") rank(x,ties.method="random") rank(x,ties.method="max") mtcars[order(mtcars$mpg,-mtcars$cyl),] #对数据框中mpg正序、cyl倒序排列
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2.6.2 数据集操作
#1)大致了解数据集情况 head(mtcars) #默认查看前6条记录 head(mtcars,10) #查看前10条记录 tail(mtcars) #查看默认后6条记录 tail(mtcars,10) #查看默认后10条记录 #2)查看表结构 str(mtcars) #3)查看列名 names(mtcars) #----2数据集修改 #添加列 df_a<-data.frame(id=c(1,2,3),score=c(11,22,33)) df_b<-data.frame(phone=c(123,234,345),add=c('a','b','c')) df_a;df_b cbind(df_a,df_b) #直接合并两个数据集 df_c<-data.frame(id=c(1,3,4),add=c('a','b','c')) merge(df_a,df_c) #按公共变量连接,只连接有的公共元素 df_d<-data.frame(id=c(5,6),score=c(44,55)) rbind(df_a,df_d) #添加行 #-------3 数据集选取 head(mtcars[,c(1,2)]) head(mtcars[,c("mpg","disp")]) myvars<-c("mpg","disp") head(mtcars[myvars]) #2)剔除变量 head(subset(mtcars,select=c(-mpg,-cyl))) myvars<-names(mtcars)%in%c('disp',"hp") head(mtcars[!myvars]) #3)选入观测 subset(mtcars,disp>=150 & hp<110,select=c("mpg","cyl","hp")) #4)选取某列不重复的数值 unique(mtcars$cyl) #5)挑选重复值记录 x<-c(9:20,1:5,3:7,0:8) x[duplicated(x)] #取出重复值 x[!duplicated(x)] #取出没有重复的指 duplicated(x,fromLast=TRUE) #从后往前判断重复 #6)随机抽取n条记录 #随机数范围:行数不能超过数据集的行数 x<-c(1:nrow(mtcars)) #sample生成随机数 sample(x,size=5,replace=FALSE) samp<-sample(x,size=5,replace=FALSE) samp mtcars[samp,]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
2.6.3 数据集连接
base包中的merge函数,dplyr包中可以使用intersect函数取两个数据集的交集,用union函数取两个数据集的并集,用setdiff函数取两个数据集的差集等。
x<-data.frame(a=c(1,2,4,5,6),x=c(2,12,14,21,8))
y<-data.frame(a=c(1,3,4,6),y=c(8,14,19,2),x=c(2,3,4,5))
merge(x,y) #根据相同字段内连接,即a和x两个字段全相等才连接
merge(x,y,by=c("a")) #根据字段a内连接
merge(x,y,all=TRUE) #根据相同字段全链接
merge(x,y,all.x=TRUE,by=c("a")) #左连接
merge(x,y,all.y=TRUE,by=c("a")) #右连接
merge(x,y,by=c("a","x")) #根据a和x两个字段连接
merge(x,y,by.x="a",by.y="y") #根据x表中a和y表中y连接
#也可以使用sqldf包的SQL语句选取数据
library(sqldf)
newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names=TRUE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.6.4 数据汇总
#设置有效位数为3 options(digits=3) aggdata<-aggregate(mtcars,by=list(mtcars$cyl,mtcars$gear),FUN=mean,na.rm=TRUE) aggdata ##以cyl和gear为排序条件,计算每个指标的均值 ma <- matrix(c(1:4, 1, 6:8), nrow = 2) apply(ma,1,sum) apply(ma,2,sum) year<-c(2007,2007,2007,2007,2008,2008,2008,2009,2009,2009) province<-c("A","B","C","D","A","C","D","B","C","D") sale<-c(1,2,3,4,5,6,7,8,9,10) da<-data.frame(year,province,sale) tapply(da$sale,list(year,province),mean) x <- list(a = 1:10, beta = exp(-3:3),logic=c(TRUE,FALSE,FALSE,TRUE)) x lapply(x,quantile) ##对x每个元素应用函数,生成一个与元素个数相同的值列表 sapply(x,quantile) ##对x每个元素应用函数,生成一个与元素个数相同的值列表或矩阵 #重复生成1:4,每个元素分别重复1次、2次、3次和4次 mapply(rep,times=1:4,1:4) #重复生成列表 #先是1两次,再是2两次,然后1再两次,最后2两次 mapply(rep,times=c(2,2),MoreArgs=list(x=1:2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2.7 控制流
#for 循环 for (i in 1:5) print("hello") #生成Fibonacci数列 x <- c(1,1) for (i in c(3:30)) { x[i]<- x[i-1]+x[i-2] } x #while 结构 x <- c(1,1) i <- 3 while (i <= 30) { x[i] <- x[i-1]+x[i-2] i <- i +1 } #repeat-break 循环 ##repeat是无限循环,加上break后,在达到条件后跳出循环 pv<-c(1,2,3,2,1,2,15,7,21) i<-1 result<-"" repeat{ if(i>length(pv)){ break } if(pv[i]<=5){ result[i]<-"初级用户" } else if(pv[i]<=15){ result[i]<-"中级用户" } else{ result[i]<-"高级用户" } i<-i+1 } result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.7.2 条件执行
1.if-else结构,else语句不能单独占一行,除非在大括号内
a<-2 { if(a==1) { case<-1 case1<-case+1 } else if(a==2) { case<-2 case1<-case+2 } else { case<-3 case1<-case+3 } } case1 #2) ifelse结构 a ifelse(a>1,b<-1,b<-2) #--switch结构 i<-"happy" switch(i, happy="a", afraid="b", sad="c", angry="d" ) #输出第二个向量 switch(2,mean(1:10),1:5,1:10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.8 自定义函数
myfun<-function(a,b){ x<-a+b return(x) } myfun(1,2) x<-2 myfun<-function(a,b){ x<-a+b return(x) } myfun(1,2) x<-2 myfun<-function(a,b){ x<<-a+b return(x) } myfun(1,2) x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
“<-”赋值符号在函数体内可以赋值,但是无法在工作空间中赋值,“<<-”既可以在函数体内赋值,也可以在工作空间中赋值


