- 1CoverDesignAI——快速生成图书封面和Midjourney提示词_ai专辑封面提示词
- 2chatglm常用参数 :Top-k, Top-p, Temperature_chatglm temperature
- 3用通俗易懂的方式讲解:大模型微调方法总结_大模型怎么用问答对去微调
- 4关于在winform中使用chart一些总结_winform chart
- 5Kernel Log
- 6vue使用axios发送post请求(data为json格式)_前端axios post请求json格式入参
- 7Android-gradle配置详解_gradle unittests.returndefaultvalues
- 8使用opencv 进行图像美化_opencv窗口美化
- 9Zookeeper_nn2 active
- 10统计学——几种常见的假设检验_假设检验类型
高级DBA手把手教你解决clickhouse数据库宕机生产事故实战全网唯一_clickhouse日志路径
赞
踩
高级DBA手把手教你解决clickhouse数据库宕机生产事故实战演练
一、事故描述
生产环境clickhouse宕机,重启之后,反复重启,重启几秒钟又死了。甲方客户叫天,大老板火冒三丈,天下大乱。老板电话打过来,要求半小时内解决,压力山大,有点慌!!!
二、clickhouse运行日志文件定位
查看clockhouse的运行日志路径默认地址为:

/var/log/clickhouse-server/clickhouse-server.err.log #日志的默认路径
- 1
cd /var/log/clickhouse-server/
tail -f clickhouse-server.err.log
- 1
- 2
三、日志中定位核心问题

permission denied [/var/lib/clickhouse/metadata/system]
- 1
综合上述的报错,基本上已经定位了是权限问题导致,应该是运维人员用户组的权限调整了,间接影响到了数据库的文件系统的归属。导致。
ll /var/lib/clickhouse/metadata/system #翻看当前路径的归属
- 1
翻看当前路径文件的归属,缺发现都变成了root。默认应该为clickhouse用户才对。

解决思路就是先把日志提示的路径的文件的归属改回clickhouse
cd /var/lib/clickhouse/metadata/system
chown -R clickhouse *
- 1
- 2
clickhouse restart #重启服务
- 1
再翻看日志还是一样还是反复重启,报错一致,很奇怪奔溃。
去百度翻看一下国外大神有没有遇到过,翻看了国外的程序员贴吧。
大概的意思是,要把所有的关于clickhouse的文件系统的文件全部重置用户归属。
也就是说,我刚刚执行的重置权限的可能还是有漏掉的文件。
查询所有clickhouse相关路径
find / -iname "clickhouse*"
- 1
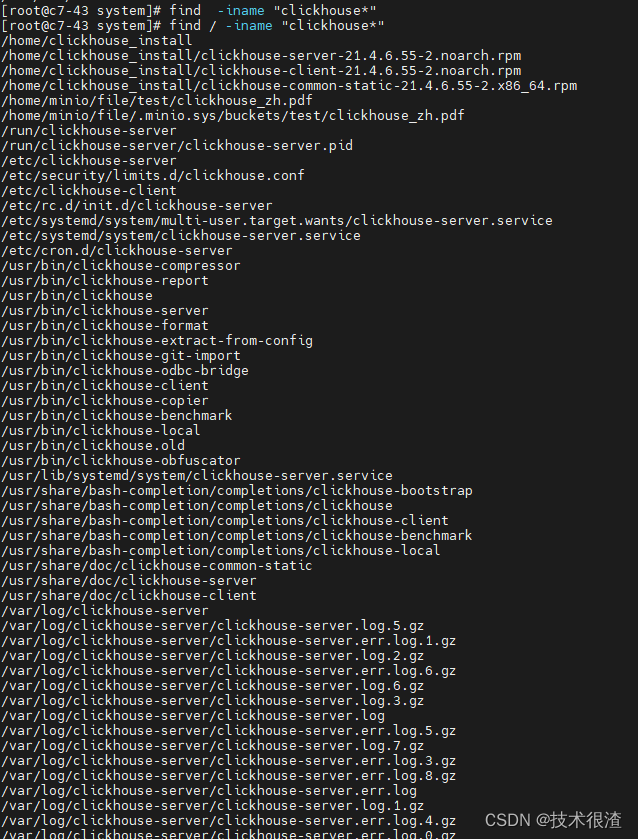
通过与其他测试环境文件系统进行层层对比最终定位clickhouse文件系统的路径分布如下:
/var/lib/clickhouse
/var/log/clickhouse-server
/etc/clickhouse-server
/etc/clickhouse-client
- 1
- 2
- 3
- 4
执行重置用户组的命令
sudo chown -R clickhouse /var/lib/clickhouse /var/log/clickhouse-server /etc/clickhouse-server /etc/clickhouse-client #重置所有clickhouse文件系统的用户归属命令
- 1
执行重置命令,重启clickhouse服务
clickhouse restart #重启服务
- 1
问题成功解决
四、总结问题
总的来说主要是操作系统权限导致的,关键是定位到所以相关的文件归属。linux服务器会经常遇到。这个处理步骤跟分析方法我写的很详细。
五、大招方法把clickhouse删除从装解决
如果上述操作解决不了则可以运用下方法:
解决思路是:将clickhouse全部删除,从装。但是保留数据库的数据文件。覆盖安装的思路解决。
主要要记得保留好数据库的数据文件目录,保留历史数据
/var/lib/clickhouse/data #clickhouse的数据库文件路径
- 1
注意要保留上述的文件路径,并且要确保这个路径下所有文件的归属为clickhouse

(1)去官方网站下载安装包
https://packages.clickhouse.com/rpm/stable/
- 1
需要下载三个包按最新的版本号*代表最新的版本号
| 1 | clickhouse-client-* |
|---|---|
| 2 | clickhouse-server-* |
| 3 | clickhouse-common-static-* |
(2)删除之前的旧版本不如会冲突
rpm -qa | grep clickhouse
- 1

rpm -e clickhouse-client-20.12.5.14-2.noarch
rpm -e clickhouse-server-20.12.5.14-2.noarch
rpm -e clickhouse-common-static-20.12.5.14-2.x86_64
rm -rf /etc/clickhouse-server/ #删除之前的配置文件,不删除也是会冲突,建议提前备份
- 1
- 2
- 3
- 4
(3)重新安装新版本的安装包
rpm -ivh clickhouse-common-static-21.4.6.55-2.x86_64.rpm
rpm -ivh clickhouse-server-21.4.6.55-2.noarch.rpm
rpm -ivh clickhouse-client-21.4.6.55-2.noarch.rpm
sudo clickhouse start
- 1
- 2
- 3
- 4
(4)重新调整配置设置用户密码、外网访问权限根据之前的备份的配置文件
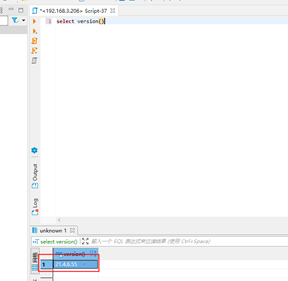
select version() #最终检查升级后的版本号
- 1
作者后言
本案例只是举一个简单的经常遇到的宕机案例,而实际的情况会更加复杂,比如掺杂这数据库主从集群数据恢复问题,或者中间的操作过程并没有作者叙述的那么顺利,中间的每个环节都可能被卡住。实际的情况,也根据实际的局面跟以往的经验去尝试解决,本文案例只是举一个毕竟常见的宕机情况。基本上数据库运维人员都会碰到。最好提前部署好HA高可用架构,让数据丢失的可能性降低到最低。但是往往出现生产事故中,是需要DBA迅速马上解决问题的,真实的情况遇到的压力会非常大,时间也非常紧迫,造成的人力物力财力的损失也不可估量,更需要我们的“胆量”,“信心”,“魄力”,‘技术能力’,毕竟真正能处理数据库生产事故的开发是国内开发团队中也是极少数。
作者本人简介:现任国内某大型软件公司大数据研发工程师、MySQL数据库DBA,软件架构师。直接参与设计国家级亿级别大数据项目。并维护真实企业级生产数据库300余个。紧急处理数据库生产事故上百起,挽回数据丢失所操作的灾难损失不计其数。
本文拿一个真正生产案例MYSQL宕机的实际案例做讲解,主要是叙述解决问题的思路跟方法,毕竟真正解决生产数据库事故的研发人员也是极少的。