
- 1【联邦学习实战】基于FATE框架的MNIST手写数字识别——卷积神经网络_联邦学习fate mnist
- 2清除此计算机中wps云盘,使用注册表删除我的电脑中的WPS网盘、百度网盘、微盘云等图标...
- 3高通SDX12:串口及ADB鉴权 加密登录_网络adb 鉴权
- 4Redis - 一篇走心的 RedisUtil 工具类_redisutils.lock
- 5怎么看localhost的ip是多少_localhost的ip地址
- 6鸿蒙HarmonyOS开发框架—学习ArkTS语言(基本语法 五)_鸿蒙 语言 atks
- 7如何查看Jupyter notebook中文件的存放位置_如何在jupter找到本地文件
- 8鸿蒙开发实战项目(八十):AirTouch_鸿蒙开发项目
- 9实现CSS等分布局的5种方式_css 设置td等分
- 103D Object Detection——Voxel based methods_voxel- based methods
“新KG”视点 | 王文广——图模互补:知识图谱与大模型的共生新模式
赞
踩
OpenKG

大模型专辑
导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期邀请到达观数据有限公司王文广分享“图模互补:知识图谱与大模型的共生新模式”。
分享嘉宾 | 王文广 达观数据有限公司
笔记整理 | 邓鸿杰(OpenKG)
内容审定 | 陈华钧
01
引言
在生物领域,共生系统是指两种或多种不同的生物种类在一定的时间和空间内,通过某种方式相互作用,从而形成的一个有机的整体。互利共生是共生系的典型现象,是指两种或多种不同的生物在一定的时间和空间内相互依赖,从而获得利益的一种生态现象。比如蜜蜂和花朵之间的关系,蜜蜂通过采集花蜜获取食物,同时帮助花朵传播花粉。有名的动画电影《海底总动员》中的主角小丑鱼与其居住地海葵之间,也是一种互利共生的关系。小丑鱼依赖海葵获得庇护和繁殖场所,而海葵也在一定程度上依赖小丑鱼获得营养和免受捕食[1]。

在自然界之外,科技的发展也产生了许多共生系统,典型的一个例子有光伏发电、水电和牧羊之间的互利共生模式[2]。在这个模式中,一方面是“水光互补”,实现了将原本间歇、随机、功率不稳定的锯齿形光伏电源,调整为均衡、优质、安全的平滑稳定电源。即当太阳光照强烈时,用光伏发电,水电停用或少发。当天气变化或夜晚来临时,用水力多发电,以减少天气变化对光伏发电的影响,从而获得稳定可靠的电源。同时,光伏发电板上发电、板下牧羊,又将光伏发电和畜牧业相结合,实现了“光伏+牧场”方式,既减少了光伏企业成本,也助力农牧民增收,实现了经济、环境效益的双赢。“水光牧”的互利共生,实现了经济、生态、 社会三大效益高度统一。
同样的,在大模型如火如荼的今天,当我们探索大模型的产业应用中,发现其存在幻觉、不可控、不可解释等问题。而此前几年热门的知识图谱等技术,则恰好是事实性、可控性和可解释性非常好的技术,是可解释人工智能的代表性成果,可以很好地弥补大模型的不足。同时,在知识图谱中令人诟病的构建难和语言理解问题,恰好又是大模型所擅长的。当我们仔细评估大模型和知识图谱各自的特性时,会发现他正如同自然界的小丑鱼和海葵,或者“水光牧”,形成了很好的互利共生的关系。本文首次提出了“图模互补”一词来概括知识图谱与大模型的共生新模式。下面深入探讨这种图模互补的共生模式。
02
相关工作
知识图谱[3]和大模型[4]是人工智能领域的两个重要概念,它们分别代表了不同的知识表示和处理方式,也有着相互促进和补充的关系。
大模型是一种基于深度学习的人工智能模型,通常指具有超大规模参数量和数据量的神经网络模型。大模型通过从大量文本或多模态数据中学习语言和模式识别能力,可以更好地理解和处理自然语言,甚至生成新的文本或内容[4]。狭义的大模型,即大语言模型,指具备数十亿乃至万亿参数,通过高达万亿词元数量的文本语料训练出来的深度神经网络模型。大语言模型在语言理解和生成上取得了出色的成绩,其发展历史可以追溯到2013年的 Word2Vec[5],但直到近年诸如GPT-3[6]、LaMDA[7]、 PaLM[8]、PaLM-2[9]、LLaMA[10]、LLaMA-2[11]、CodeLLaMA[12]、WizardMath[13]等大模型的出现(如图2),才使得大语言模型的应用得到了普及。广义的大模型则包含了语言、声音、视觉等多模态任务,其典型代表是Flamingo[14]和GPT-4[15]。大模型能够发展到如此高度,得益于充分利用注意力机制[16]进行序列建模的变换器网络(Transformer)架构[17]及诸如稀疏变换器网络[18]这样的变种。最近,变换器网络架构最终统一了语言[6-13]、视觉[19]、声音[20]和多模态[14,15,21,22]的建模。大模型支持通过提示工程(Prompt Engineering)[23,24]来实现应用于特定任务上的情境学习,展示了强大的通用能力,并预示了通用人工智能曙光初现[25,26]。
知识图谱(Knowledge Graph)是一种结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构[3,27]。知识图谱的概念源于语义网络(Semantic Network),后来受到本体(Ontology)、语义网(Semantic Web)、链接数据(Linked Data)等理念的影响和发展[28]。知识图谱可以帮助人工智能系统更好地理解实体之间的关系和属性,从而提高自然语言处理、信息检索、推荐系统、问答系统等领域的准确性和效率。
知识图谱和大模型之间有着密切的联系,它们可以相互配合,实现更加复杂和精准的任务[29]。例如,大模型可以从大量文本数据中提取出实体和关系,然后将它们转换成知识图谱的形式[30]。知识图谱可以帮助大模型更好地理解实体之间的关系和上下文,从而提升自然语言处理的准确性和效率[31]。同时,知识图谱也可以作为一种约束机制,避免大模型产生一些不符合逻辑或常识的输出,进一步的,知识更新、事实凭据、复杂推理等对智能系统至关重要,知识图谱在其中发挥着关键作用[3,27]。
03
知识图谱与大模型的共生模式
不管是知识图谱还是大模型,都有其问题所在。从知识图谱的视角,存在诸多问题,比如:
知识图谱的构建和维护是一项耗时和费力的工作,需要大量的人工标注和质量控制来从非结构化文本中抽取实体、关系和属性,构建成知识图谱。
知识图谱也难以覆盖领域内和场景所需的所有知识,容易出现不完整的问题。
基于知识图谱的问答中,语言理解和生成问题一直是棘手所在,使用知识图谱的门槛较高。
另一方面,大模型同样存在诸多问题,包括:
大模型的训练和推理需要消耗大量的计算资源和能源,带来巨额的成本,同时也给环境(碳排放)带来负担。
大模型也缺乏对事实知识的验证和纠正机制,容易出现幻觉问题。幻觉问题指的是大模型生成的内容与给定的输入或背景不一致或不相关,或者与事实或知识不符或无法验证的情况。幻觉会影响大模型生成内容的质量和可信度,甚至会对人类用户造成误导和危害。
更新大模型所具备的知识成本巨大,无法实时更新,特别是,目前无法纠正一个特定的错误知识。
输出基于概率完全黑盒,难以精确控制其结果,同时对如何产生这样的结果也无法解释。
而恰好,大模型的问题,知识图谱较为擅长,同时大模型也善于解决知识图谱所存在的问题。这正如同前文所提到的科技界的“水光牧”互补或者自然界中的小丑鱼与海葵之间的共生关系,可以相互支持和促进。探索知识图谱与大模型的共生方式,利用两者各自的优势相互赋能,弥补各自的不足,实现更高层次的认知能力。此外,大模型和知识图谱还可以互相作为对方的评估工具,实现有效的额反馈、调整和改进。也正是通过这种共生关系,知识图谱与大模型一起共同解决了当前单纯依靠大模型存在的幻觉、不可解释、不可控等问题,也解决了单纯知识图谱存在的构建难、语言理解与生成能力弱等问题,实现可信、可靠、以人为本的通用人工智能。具体来说,在图模互补的共生系统中:
大模型负责语言的理解与生成,实现对话式的交互,并负责跨语言的知识对齐和知识获取。具体到大模型对知识图谱的贡献上,则可以利用大模型在语义理解、内容生成等方面的技术优势,实现大模型对知识图谱构建至应用全生命周期各环节的增强,提升效率和质量。例如,利用大模型从文本中抽取实体和关系,构建或更新知识图谱;利用大模型根据知识图谱生成自然语言描述或问答对话,应用或传播知识图谱。
知识图谱则负责确定性的事实与知识,提供实时或及时更新的新鲜的知识,负责确定性的演绎推理和谓词逻辑,以及对错误知识的及时编辑与纠正等等。例如,由于知识图谱在知识标准化、可解释性、可溯源性、可控性、新鲜和及时更新等方面的优势,可以通过知识图谱来增强大模型从训练到应用的多个环节,提升大模型的应用效果和推理结果的可用性。例如,利用知识图谱作为额外的监督信号或输入特征,提升大模型在预训练或微调阶段的表现;利用知识图谱作为外部记忆或参考文献,在推理或生成阶段对大模型进行指导、纠正和知识溯源。
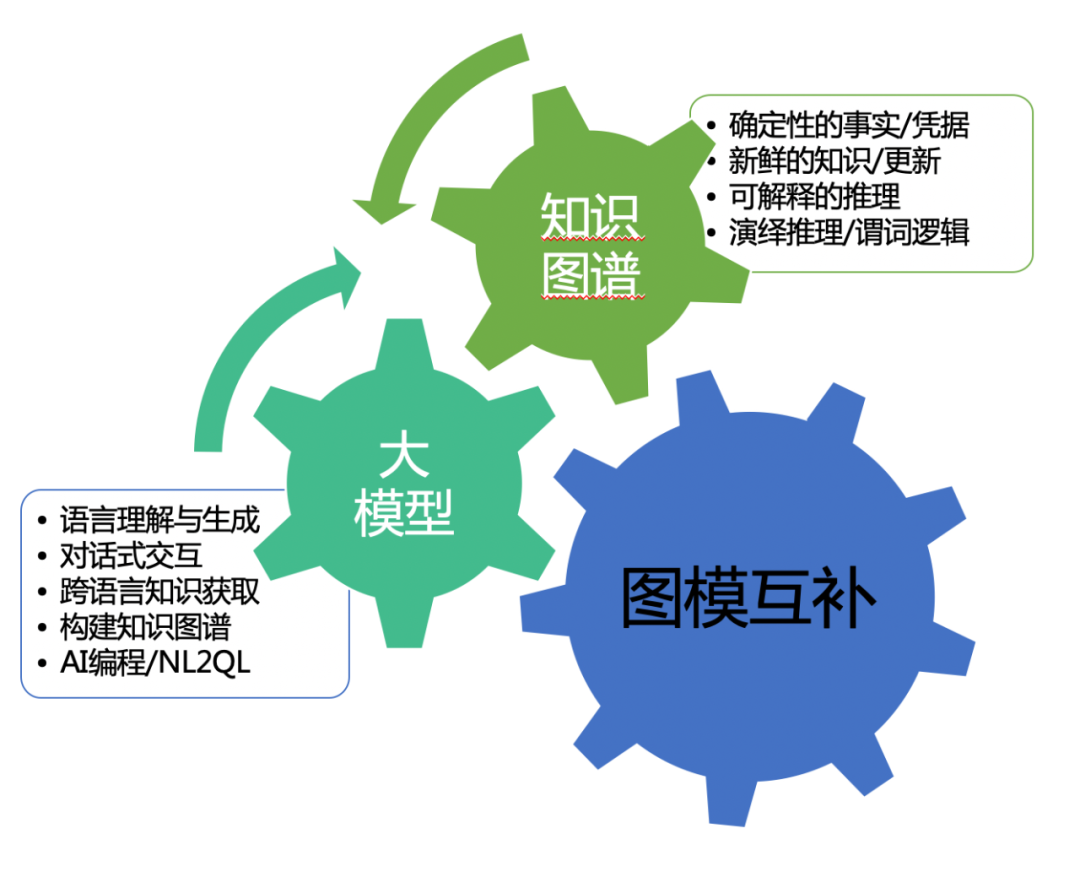
在图模共生的人工智能系统中,能够实现:
减少或避免幻觉和胡编,生成准确、有效、新鲜、能溯源的结果,避免产生一些错误或编造的输出。
以可控的约束和指导来提供更丰富的背景和语境,实现可信与可解释的人工智能,确保符合逻辑、常识、事实。
以图模共生为指导,确保人工智能的输出符合逻辑,理解用户,适应环境,向上向善,而不会对人类造成误导与伤害,实现以人为本的通用人工智能。
04
图模互补的机制
图模互补的机制,可以分为两种,即“模宗”和“图宗”:
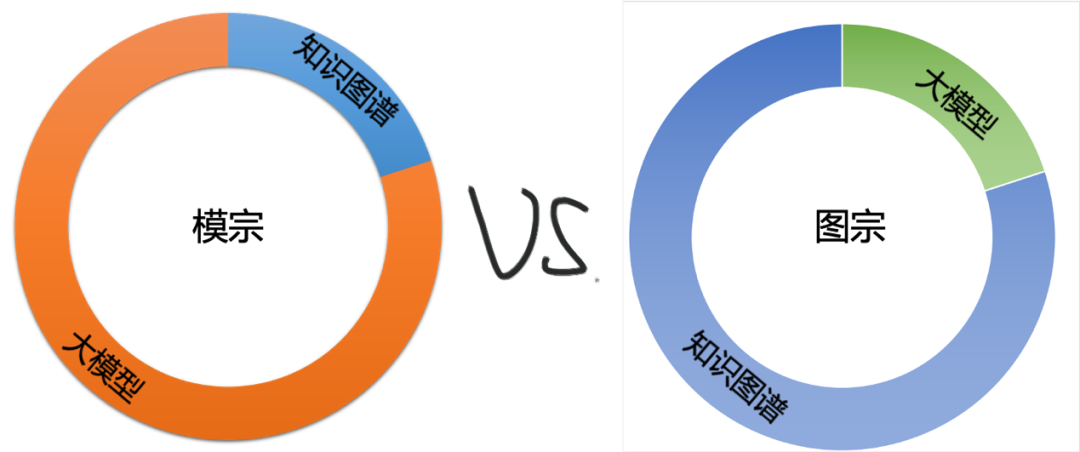
模宗:大模型为主,知识图谱为辅,把知识图谱作为增强大模型的能力,也可以称之为知识图谱增强的大模型。
图宗:知识图谱为主,大模型为辅,把大模型作为增强知识图谱的能力,也可以称之为大模型增强的知识图谱。
当然,看到这两个词,很多人可能会想起《笑傲江湖》中的“剑宗”和“气宗”,真正能够笑傲江湖的,并不需要强分高低,而是适者生存。在“模宗”和“图宗”中也是一样,适合于场景,能够满足用户需求的,才是最好的!强分高下并非明智之举。至于拿着锤子(知识图谱或大模型),就觉得任何东西都是钉子的,是用敲的,就落于下乘了。
知识图谱增强大模型的“模宗”
模宗的核心是利用知识图谱中的知识来增强大模型的能力,解决大模型的幻觉、新鲜知识以及专业性的推理等难题,进而提升人工智能系统的可信和可靠,并在某种程度上实现可控性。其核心问题是解决如何有效地将知识图谱中的实体、关系、属性和事件等知识融入到大模型的训练、推理和评估过程中,使大模型能够更好地理解和使用知识图谱中的知识。这有助于解决大模型的幻觉与编造的问题。幻觉(Hallucination)是指大模型在生成文本时,产生了与事实不符或没有依据的内容。编造(Fabrication)是指大模型在生成文本时,故意或无意地编造了虚假或误导性的信息。这两种现象都可能会导致大模型的输出不真实、不准确或不可信。例如,在生成新闻报道时,大模型可能会幻觉出一些不存在的人物、事件或细节,或者编造出一些有利于某方利益的言论或观点。这样的输出可能会误导读者,造成社会和道德上的问题。究其原因,一方面是大模型依赖于语言模型的概率分布来生成文本,而不考虑文本是否与现实世界或常识一致,缺乏对事实和逻辑的验证机制,从而生成一些违反事实或逻辑的内容。另一方面则是大模型通常使用来自互联网的无结构或半结构文本作为预训练数据,而这些数据可能包含了错误、过时、有偏见或有争议的信息,缺乏对知识来源和质量的评估与保证机制,从而使得大模型可能会从这些数据中学习到一些错误或有问题的知识,并在生成文本时使用这些知识。总得来说,大模型精确操作知识的能力非常有限,无法为生成的结果提供知识凭据,同时更新知识和修正知识(更新或修正存储与大模型中的世界知识)是巨大困难且悬而未决的。知识图谱可以帮助大模型来确认事实性问题,并在一定程度上避免幻觉与编造。其做法通常有在训练阶段和推理阶段介入,并在评估阶段也可以使用知识图谱来对大模型的输出进行评测,来确保和预期的方向相一致。
在大模型的预训练阶段,通常可以利用知识图谱中的实体、三元组或路径作为额外的输入或目标,使大模型能够学习到知识图谱中的语义信息,其方法方法丰富多样。对于将知识图谱转化为文本语料库,是将知识图谱转换为合成自然语言句子以增强现有的预训练语料库,使其能够在不改变架构的情况下集成到预训练语言模型中,从而在提供事实知识是必不可少的知识密集型任务(例如问答)等任务中,能够潜在地降低有毒输出,提高真实性。KELM[32]是典型的方法之一,使用了TEKGEN语言化管道来将知识图谱转化为知识增强语言模型 (Knowledge-Enhanced Language Model,KELM) 语料库。该管道包括启发式对齐器、三元组转换为文本的生成器、实体子图(把多个进行一起语言化的三元组组合成子图)创建器、删除低质量输出的后处理过滤器四个部分。KGPT[33]则使用了更简单的训练语料生成方法。
知识内嵌的另一种方法是将知识图谱结构嵌入大语言模型,即知识增强型大语言模型。这类预训练语言模型能从文本捕捉事实知识,并利用丰富的文本信息,在相同规模和算力下实现更好效果。ERNIE[31]系列是代表性的方法, 它融合了自回归网络和自编码网络,实现零样本学习、少样本学习和微调。如百度推出的类似ChatGPT的底层模型ERNIE 3.0[34],使用4TB纯文本和大规模知识图谱训练,在54个中文NLP任务和SuperGLUE基准测试(2021年7月3日)上优于最先进模型。知识增强的大语言模型还有直接在知识图谱的事实三元组上训练T5模型的SKILL[35],融合了知识聚合器、远程监督和实体链接实现知识图谱增强的并且能够集成细粒度关系的预训练语言模型 KLMo[36],既能将事实知识集成到PLM中又能基于PLM产生有效的文本增强的知识嵌入的统一的知识嵌入和预训练语言表示模型KEPLER[37]。
事实上,在2018年以BERT和GPT为代表的预训练模型刚出现没多久,知识增强型预训练模型就出现了。通过知识图谱进行知识支持的语言表示模型K-BERT[38]是较早的尝试,它将知识图谱的三元组作为领域知识注入到句子中,引入了软位置和可见矩阵来限制和消解知识噪声的影响。与之类似的是KnowBERT[39],这是一种使用集成实体链接来检索相关的实体嵌入,实现了词到实体的关注形式更新上下文词的表示的方法,进而将多个知识库嵌入到大规模模型中进行知识增强。而最新的尝试则是在 AI4Science 领域,将专业的化学知识构建出化学元素知识图谱来表达元素之间的微观关联,使用具有功能提示的知识图增强分子对比学习(knowledge graph-enhanced molecular contrastive learning with functional prompt,KANO)方法来将知识图谱中的知识在预训练和微调中引入到大模型中,获得了更加优秀的性能,并在预测中提供了合理的化学解释,有助于更有效的药物设计[40]。
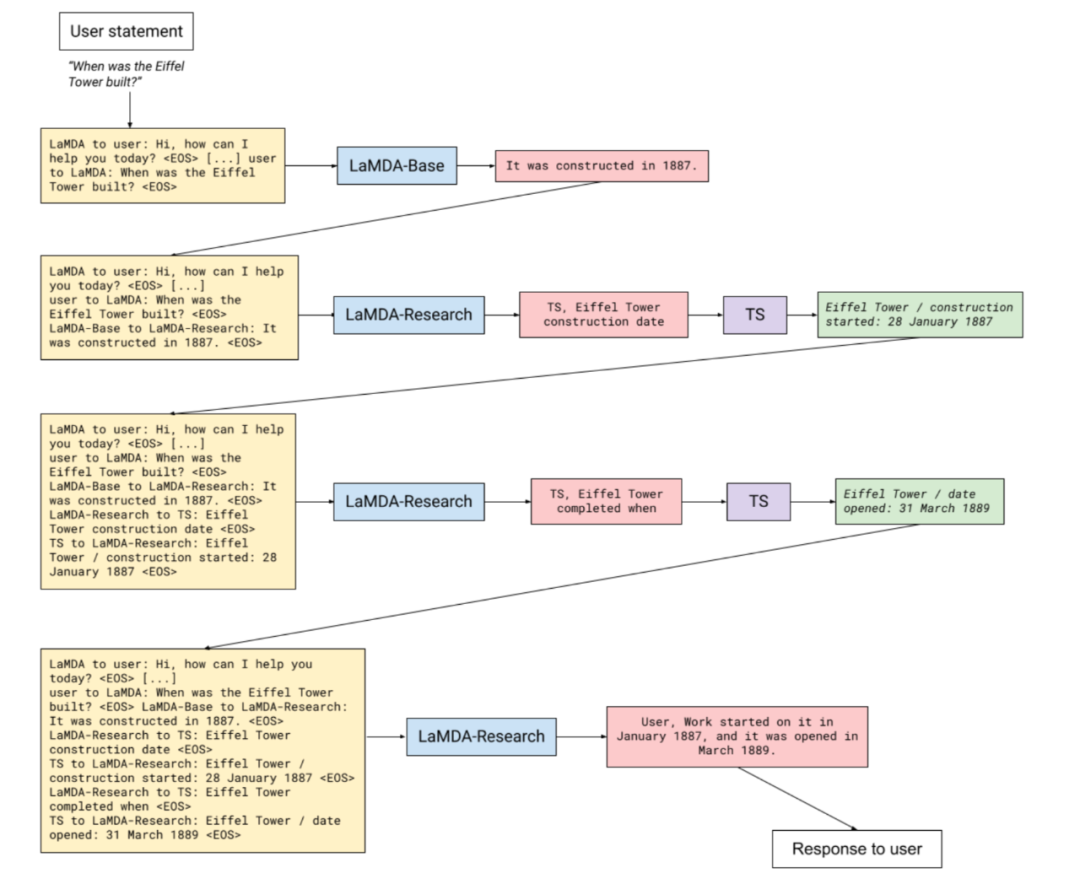
除了知识增强预训练模型本身之外,知识图谱也用来增强大模型的推理能力。其中最经典的当属 Google 的LaMDA[7],其基本原理是在大模型的推理阶段,利用知识图谱中的实体、关系和属性等信息进行编码建模,使大模型能够根据知识图谱中的语义信息进行推理。LaMDA 中使用专门的LaMDA-Research 模型来从知识图谱中检索符合要求的三元组,来作为大模型输出的事实凭据,从而确保了大模型知识的准确性,其架构见下图所示。论文[41]则研究了通过图注意力网络增强的GPT-2混合架构来捕获跨域的槽间关系和依赖关系,实现了对槽值进行因果、顺序预测,进而实现更强大的对话状态跟踪能力。KG-BART[42]进了一步,利用图注意力机制来聚合知识图谱中所蕴含的丰富概念语义,从而增强模型对不可见概念集的泛化能力,使得所生成的句子更合乎逻辑、更自然、并具备较好的常识推理能力。
检索增强生成(Retrieval-augmented generation,RAG) 则是知识图谱增强大模型的泛化,用于解决精确的知识获取,以及协调大模型自身无法更新知识的问题。RAG不仅仅针对知识图谱,而是针对文档索引来进行的外部知识的引入。[43]下图是一个经典的方法,使用了包含查询编码器(Query Encoder)和文档索引的预训练的检索器(Retriever)和预训练的生成式模型相结合的端到端的训练方法,其中检索器使用输入的检索词来检索文本,并在生成目标序列是将所检索到的文本作为附加的上下文来输入给文本生成模型,并最终获得生成的文本结果。这种方法与 LaMDA 类似,都是需要单独的模型来检索知识。相比于 LaMDA检索知识图谱这种精确的知识,RAG 本身能够检索更为广泛的文档,但检索结果精确度受到相当的损失。RETRO[44]则使用了从大型语料库中检索文档块来增强大模型的能力,使用了更小的参数模型达到了更大模型的效果(约25倍),但模型本身的复杂性限制了其大规模使用。
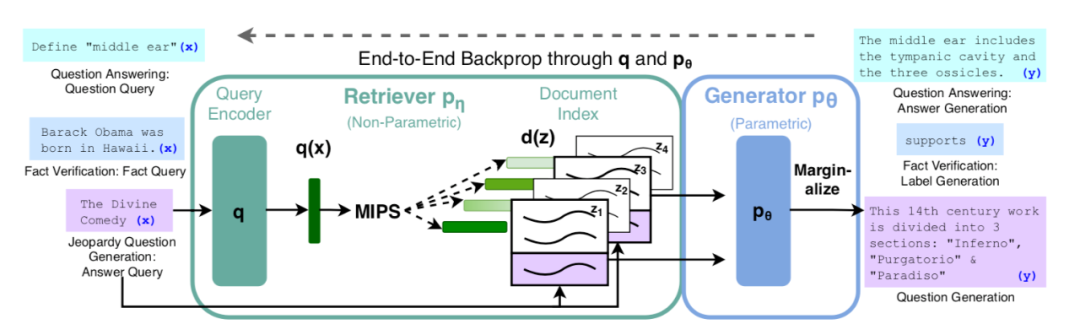
RAG
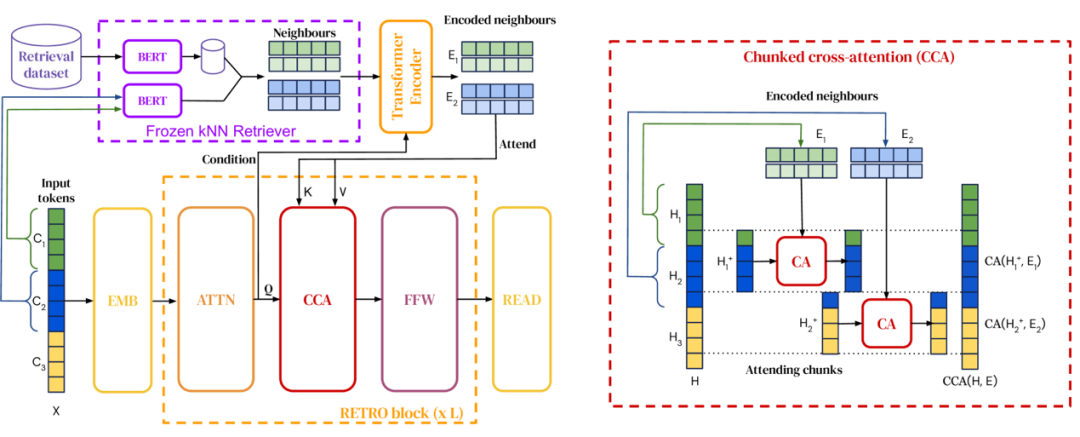
RETRO
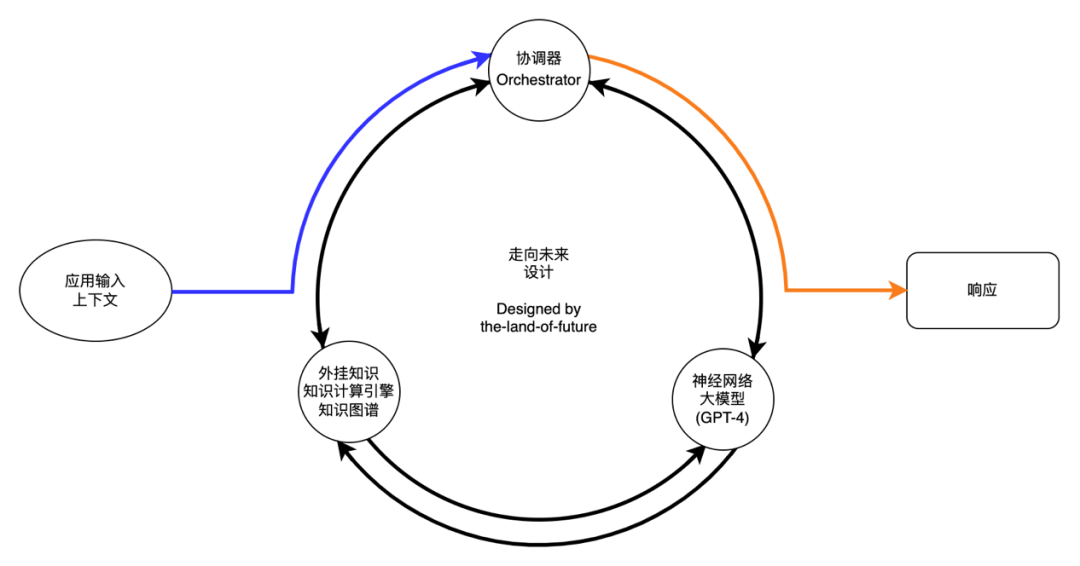
不管是 RAG 还是 RETRO,由于其都需要训练单独的检索模型,在面对大量文档时,特别是会随时更新的文档时,都存在与大模型本身类似的问题。在GPT-4出现之后,支撑微软的Bing Chat的技术架构普罗米修斯(Prometheus)[45]如下图所示,使用协调器来来将知识图谱和搜索引擎等外部知识引入到大模型中,实现知识增强的大模型对话应用。
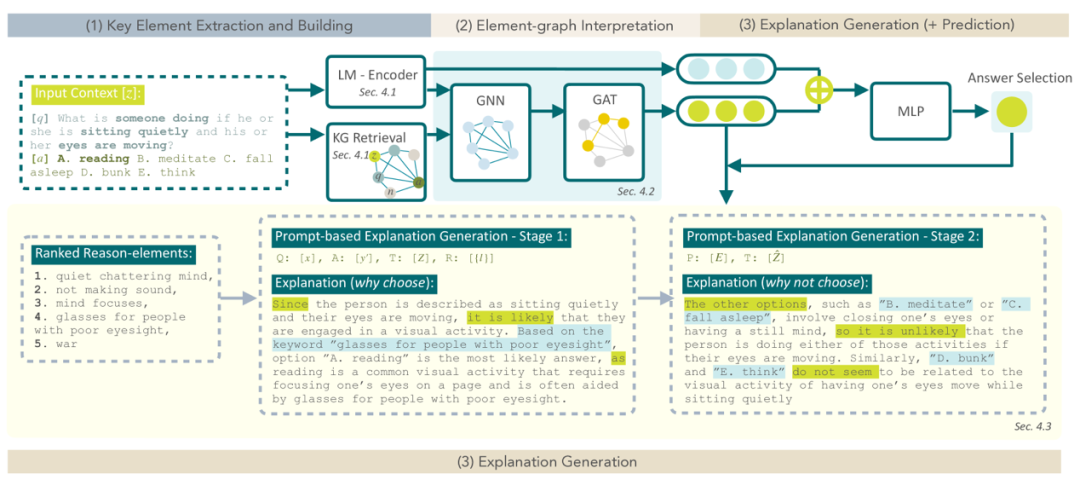
即使在大模型生成内容比较好的情况下,也存在不可解释性的问题,这在许多场景下也是不可以接受的,比如司法领域、医学领域以及金融、汽车等许多强监管的场景。通过知识图谱来增强大语言模型的解释是个好的方法,这方面的尝试是LMExplainer[46],它采用知识图谱和图注意力网络来提取大模型的关键决策信号,提供了全面、清晰的解释。一个示例如下图所示,其过程包括通过大模型来生成输入语言的迁入,并从知识图谱中检索到相关的子图。语言嵌入和子图作为 GNN 的输入,并通过 GAT来获取注意力分数,这个既用于最终的预测结果 ,也用来生成决策过程的解释。
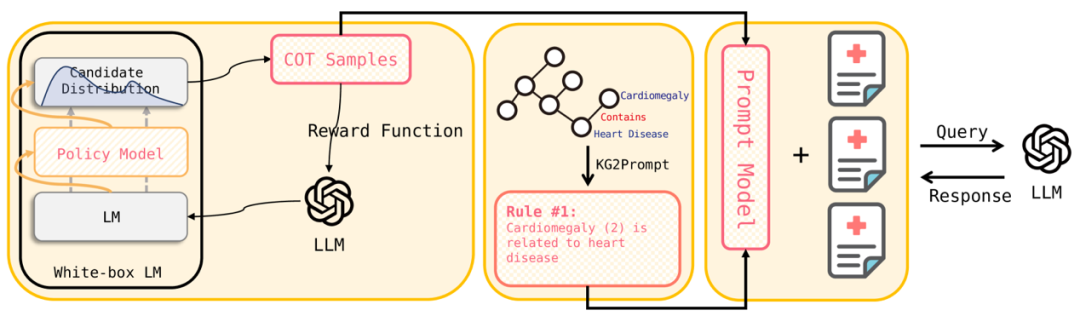
与解释问题类似,大模型在专业领域知识密集型任务上表现也不佳,知识图谱既能够增强大模型的事实,同时也能够增强大模型的推理能力。CohortGPT[47]将知识图谱和大模型提示工程中的思维链技术相结合,通过强化学习中的策略梯度[48]的策略来选择样本来构建 CoT,将知识图谱的内容转化为可执行的规则来构建提示作为大模型的而输入,获得了令人满意的性能。下图是其整体框架。
大模型增强知识图谱的“图宗”
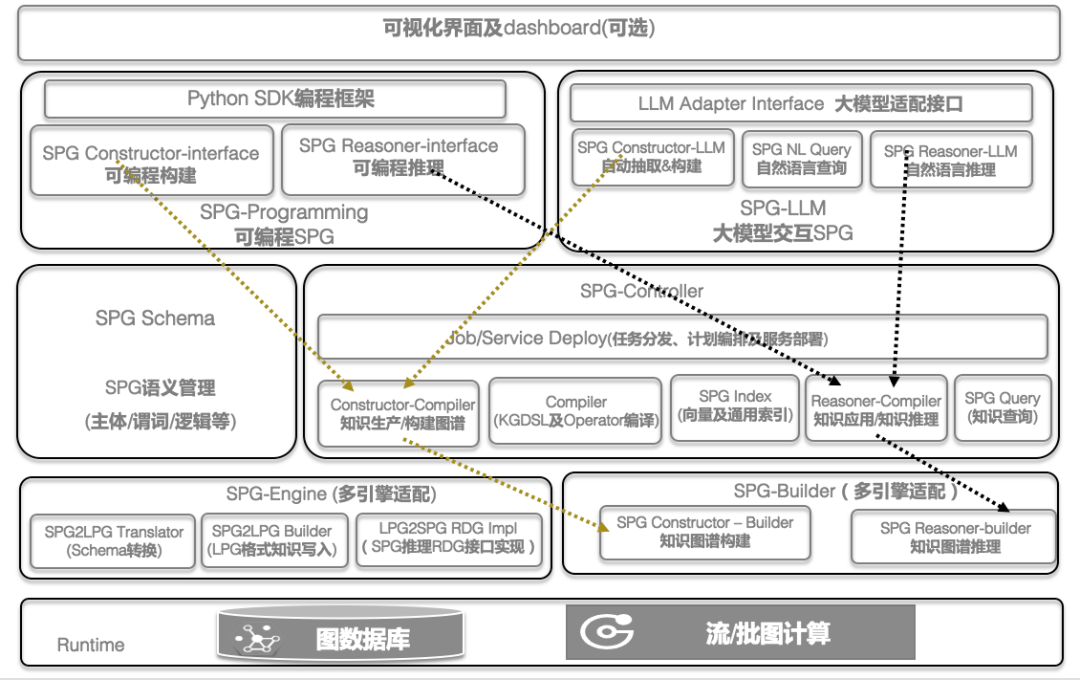
知识图谱通常是一种以实体顶点,以关系三元组(头实体,关系,尾实体)为边的有向图,符号形式表示知识,表达世界上的事物,以及它们之间的联系。知识图谱可以从多种来源构建,并涵盖众多领域的知识,具有类型丰富,层次结构,便于查询和可视化,支持逻辑推理和解释等优秀的特点。然而,在过去知识图谱高速发展的十年中,也发现了诸多问题,比如知识图谱构建难,因为语言理解问题而无法很好地自动抽取实体与关系,缺乏自然语言理解和生成能力导致交互和体验上有所欠缺,同时也存在无法覆盖某个领域所有的实体和关系,导致知识的缺失和不完整。进一步地,在多模态知识图谱中,跨模态知识的表示与融合也是一个难点。而大模型强大的语言理解和生成能力则能够很好地协助知识图谱来解决这些问题,用于实现自动化的知识图谱构建,补充和扩展知识图谱中的内容,并提供基于自然语言的知识获取、分析和推理的方法。将大模型和知识图谱结合,能够极大提升知识图谱的通用性、适应性和体验。这方面的综合性成果是CCKS2023上发布的《语义增强可编程知识图谱 SPG白皮书》[49],其总体框架如下图所示,大模型增强知识图谱从宏观上可以分为知识图谱构建、自然语言查询和自然语言推理。
在知识图谱构建方面,利用大模型的自然语言理解能力来从文本或其他数据源中抽取实体、关系和属性,构建、补全和持续更新知识图谱中的内容,使知识图谱能够更加完善和丰富。许多研究都揭示了大模型具备强大的语言理解能力,能够通过零样本或少样本来处理结构化输出的各种 NLP 任务,这包括专业领域的实体抽取和关系抽取等[50]。ChatIE[51]则将实体抽取、关系抽取和事件抽取转化为两阶段的多轮问答任务,并在 ChatGPT 上获得了非常好的效果,下图是 ChatIE的典型示例。
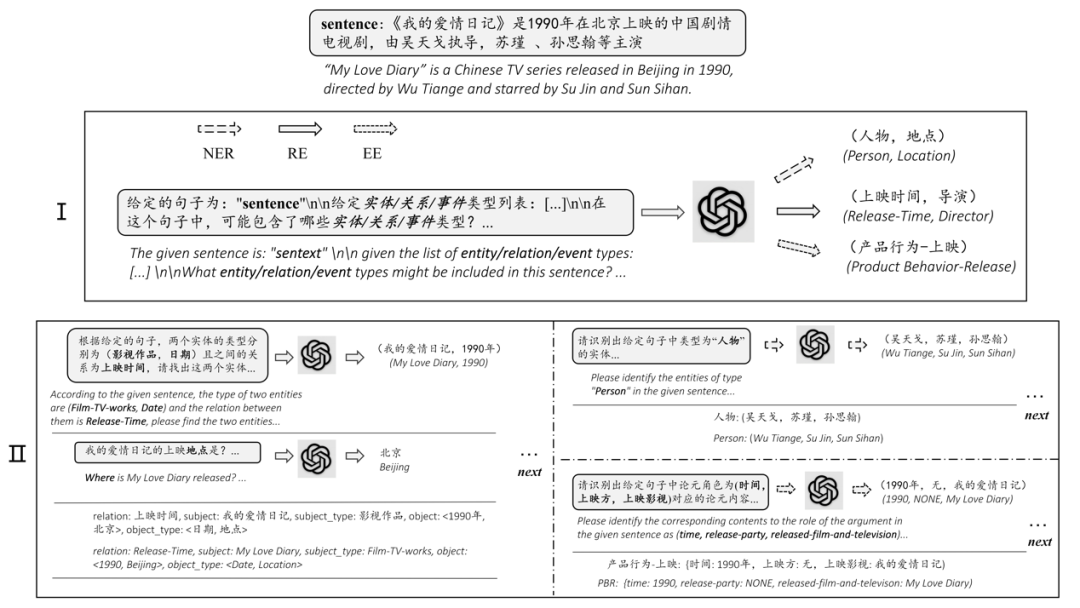
与ChatIE 类似的还有ChatExtract[52],其核心是构建通过提示工程来构建一系列的用于提取结构化数据的提示和问题集。从这些论文的探索中可以看出,基于大模型的少样本抽取的表现非常优秀,从而下图所示的流程也成为基于大模型构建领域知识图谱的标准流程。
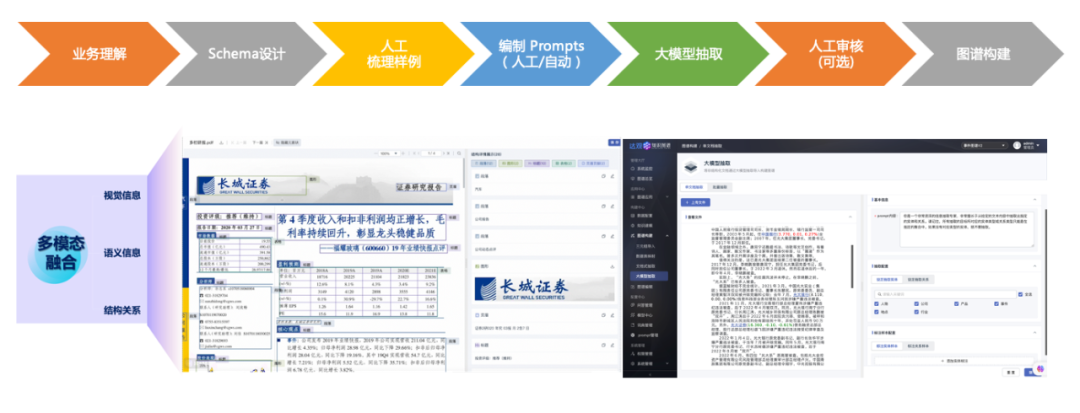
单纯使用零样本的大模型抽取存在一定的稳定性问题,从而在上述流程中引入了人工梳理样例(人工标注)。然而,大模型本身也可以用来生成标注样本,实现基于数据生成的少样本学习。论文[53]探索了如何引导 ChatGPT 生成所需要的句子结构和语言模式的标注样本,用于训练实体抽取和关系抽取方面的模型,以解决隐私问题。同样的,该方法可以用于上述的知识图谱构建流程,从而替代人工梳理样例环节,进而实现知识图谱构建完全的自动化。
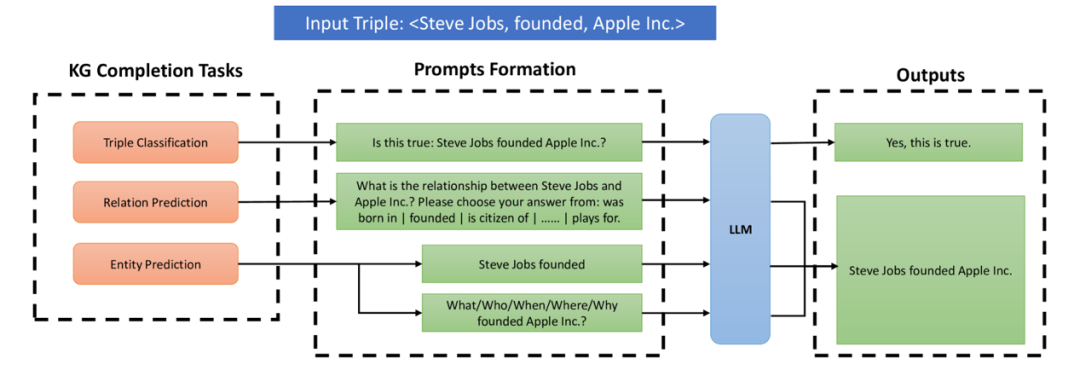
与此同时,大语言模型从超大规模语料中也学习了大量的知识,而知识图谱构建过程中可能存在知识不完整的情况,探索如何从大模型中提取可信的知识来实现知识图谱的补全也是值得探索的。一种做法是将知识图谱补全中的三个任务三元组分类、关系预测和实体(链接)预测转化为大模型中的简单提示问题,并通过问答的方法从大模型中获得结果,下图[54]是一个典型的例子。
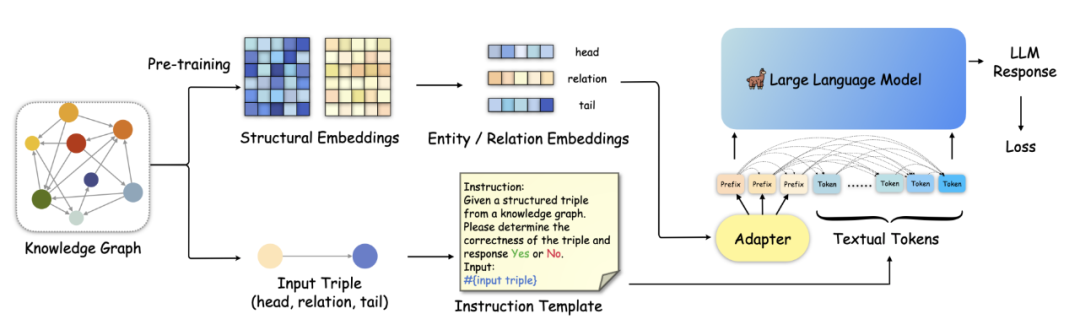
简单的问答方法来补全知识图谱,既缺乏对大模型推理能力的有效利用,也忽略了知识图谱中重要的结构信息等。如果能够将知识图谱中的实体、关系等结构信息融入大模型,实现大模型中结构感知的推理,能够获得更有效和准确的知识图谱补全。KoPA[55]在这方面进行了探讨,下图是KoPA 的整体框架。
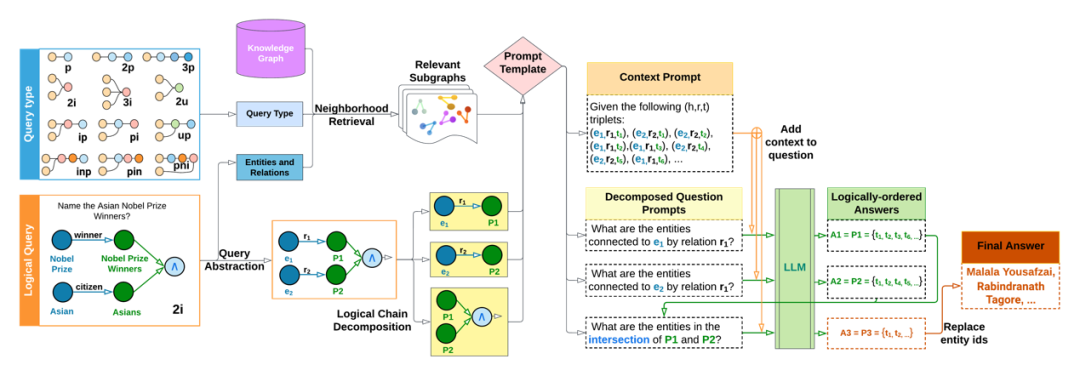
知识图谱的推理任务也是一个非常具有挑战性的任务,一方面需要理解语言和知识间的深层关系,另一方面对底层逻辑的理解也至关重要。现有的做法要么是利用知识计算进行显示的推理[3],要么利用深度学习技术将实体和关系嵌入到高维向量空间进行推理[3]。但这些方法都依赖于知识图谱自身的知识,而缺乏“世界知识”或者通识来支撑。大模型的出现,使得结合通识和知识图谱进行推理成为了可能。利用大模型引导的知识图谱复杂推理是将复杂的知识图谱推理转化为为上下文知识图谱搜索和逻辑查询推理的组合,以利用图提取算法和大语言模型双方的优势来实现复杂推理的更高性能。下图[56]展示了复杂的知识图谱推理转化为简单推理的组合,并利用了大模型的能力。
另一种方法是利用大语言模型生成知识图谱的查询语言,或者利用大模型的语言理解和生成能力,来实现知识图谱的问答,为知识图谱用户提供自然语言的交互方式。这本身就包括了知识推理 ,但更重要的是, 过往基于知识图谱的问答(KBQA)对 语言理解能力的不足限制了 KBQA 的广泛应用,而大模型和知识图谱的结合解决了这个问题。[57]探讨了用ChatGPT将自然语言问题翻译为给定知识图谱的语法正确且结构良好的 SPARQL查询。
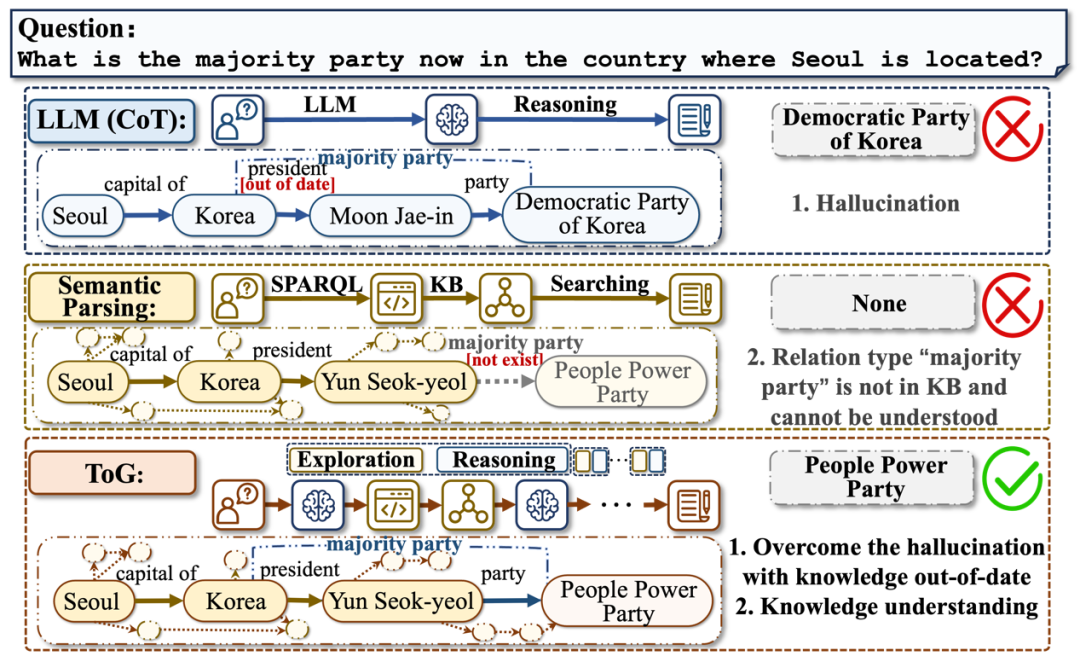
单纯使用大模型问答会存在问题,而单纯使用大模型来生成SPARQL语句检索知识图谱也可能存在问题,论文[58]探讨了这个问题,给出了下图的例子。
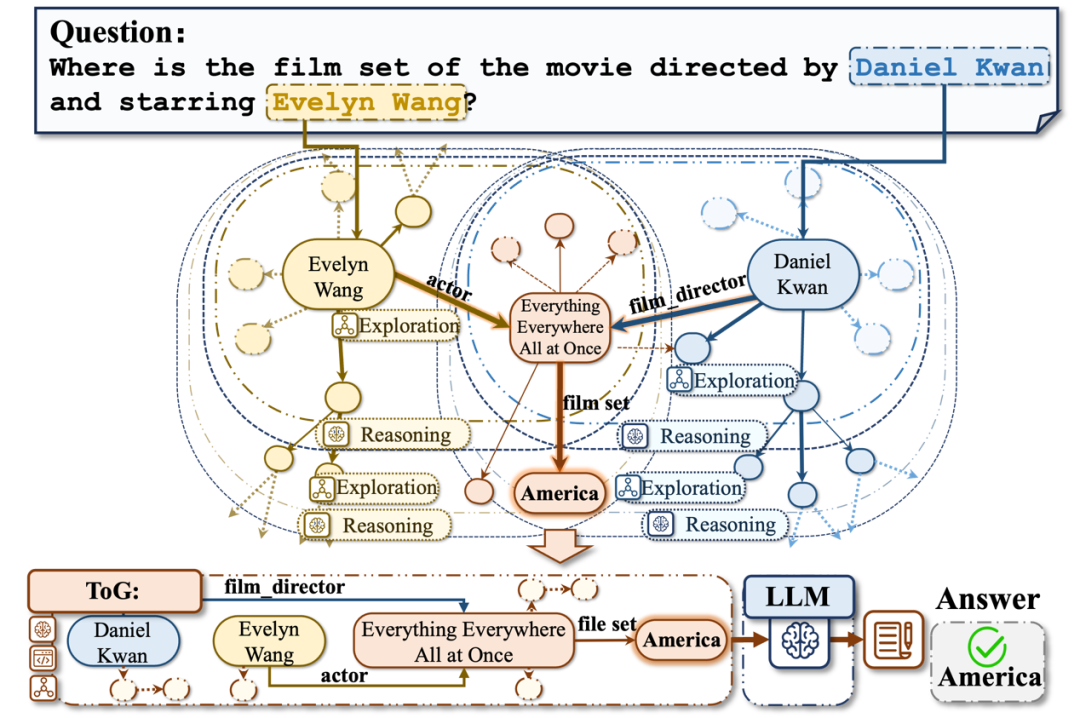
下图所示的图思考(Think-on-Graph,ToG)框架 [58]试图解决这个问题,其核心思想是大模型根据知识图谱中检索到的实体以及通过探索实体和关系来寻找可能存在的多条路径,并以此来回答用户的问题。
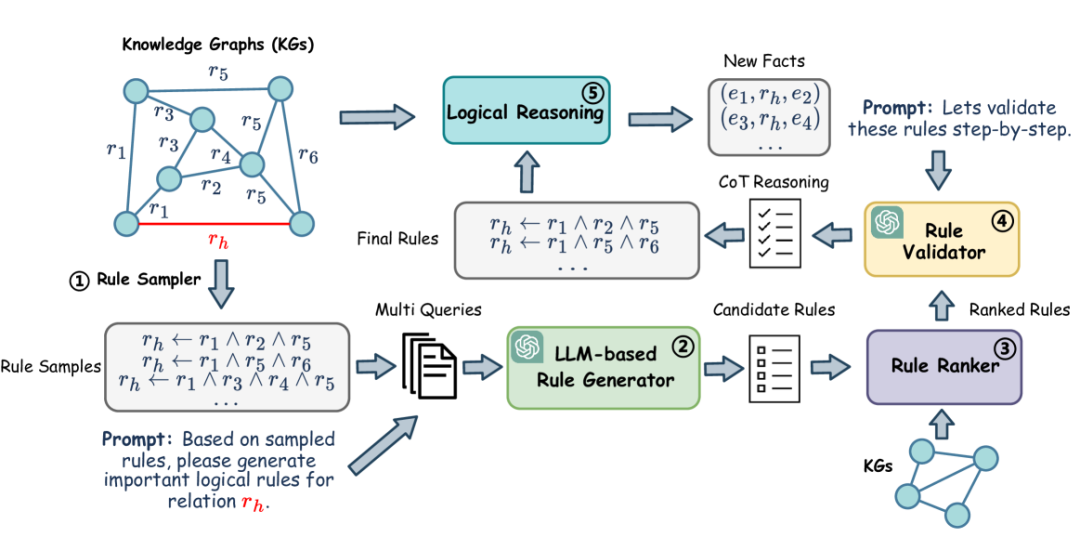
演绎推理一直是知识图谱推理的强项,但挖掘出合适的推理规则有较大的成本,或者需要人类专家来编写。大语言模型能够理解自然语言,并可以利用内化到深度学习模型中的语义知识和结构信息来生成有意义的规则,结合知识图谱的知识,能够辅助人们开发用于知识图谱推理的规则。同时,大语言模型还可以用于辅助推理规则的评估。ChatRule[59]是这方面的一个尝试,其框架如下图所示。
双向奔赴,图模互补
在“模宗”和“图宗”分别一个为主一个为辅,用对方的优势来不足自身的不同。在实践中,同一个智能系统,各部分组件是可以互相配合来实现的场景的需求的。这在许多应用中至关重要。
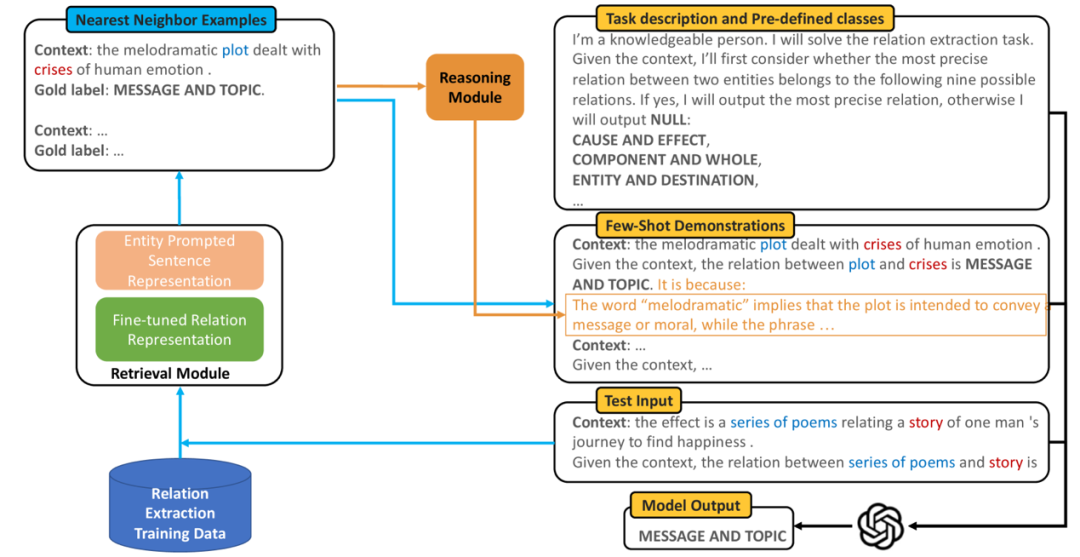
医学的辅助诊断就是一个例子,电子健康记录(EHR) 等各类患者健康、诊断和治疗的整体医疗记录是医疗实践中对患者进行诊断的重要知识来源,利用大模型将这些记录构建成知识图谱,并融合医疗领域知识图谱,在诊断推理过程中将知识图谱和大模型结合来实现临床诊断推理,能够极大提升自动诊断的准确性,是实现医疗诊断决策支持系统的关键环节。前述提到的 ChatIE[51]、ChatExtract[52]以及图*所示的知识图谱构建过程都可以用在从医疗记录文档中来构建知识图谱。对于更复杂的关系抽取,GPT-RE[60]采取了实体感知检索和金标签(golden label)诱导推理的方法来实现更好的关系抽取的情境学习,如下图所示。其中实体感知检索更强调文本中的实体-关系信息而文本语义信息,金标签诱导推理则以类似思维链的方式使用知识图谱中存在的实体-关系来增强大模型的关系分类能力,进而增强大模型少样本中少样本学习下的关系分类精度。
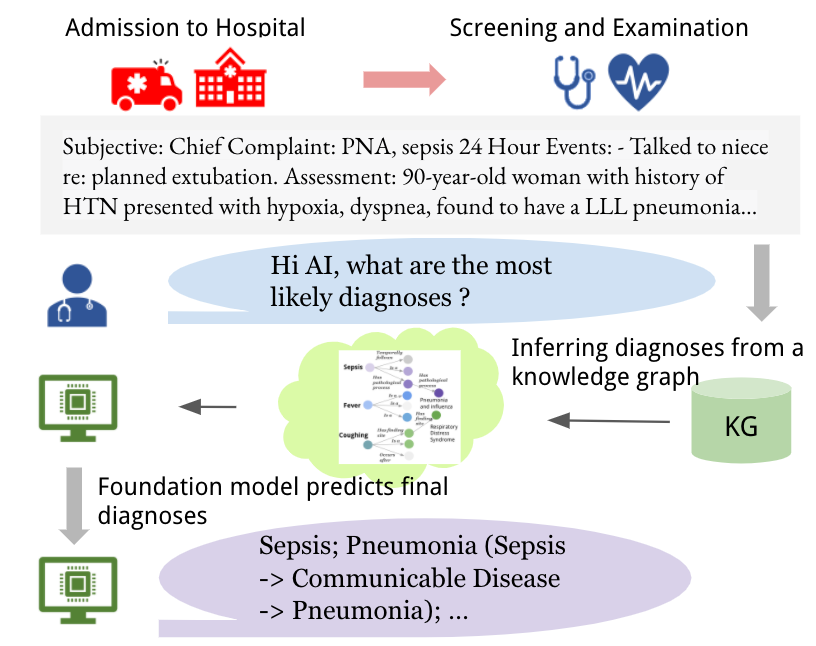
在大模型用于知识图谱构建之上,所构建的知识图谱可以用于疾病诊断推理中,并与大模型一起实现医疗决策支持。下图所示的Dr.Knows[61]是一个例子,当患者输入疾病有关的信息后,通过前述所构建的知识图谱获取有关的子图,并通过文本和知识图谱的语义关联和逻辑关联来提取子图,并用这个子图作为大模型的提示工程输入来引导大模型的决策。知识图谱和大模型的结合,不仅提升了疾病诊断决策支持的效果,同时提供了更强的解释性。
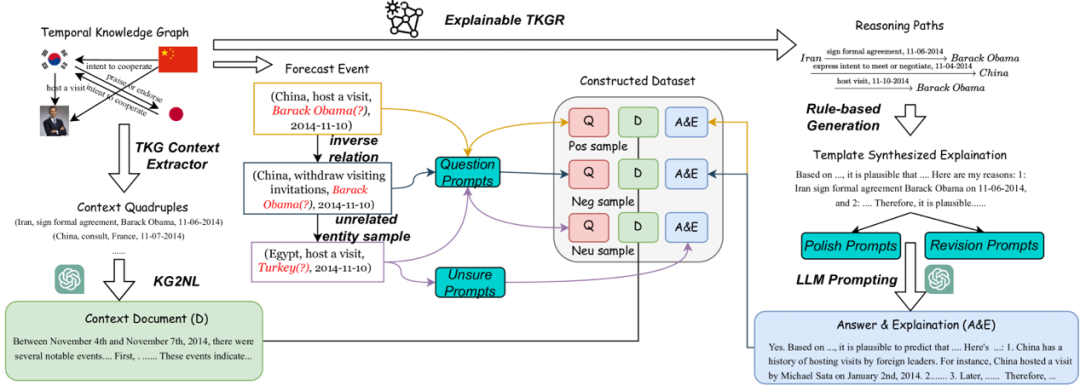
与专业领域平行的,还有适合多领域的特殊场景,比如与时间有关的推理。在知识图谱中,事件图谱是知识图谱中特殊的一类,是与时间强相关的知识的表示。大模型擅长于进行事件抽取[62]、事件之间的关系检测[63]、时间的检测与归一化[64]等。与此同时,大模型则不擅长与进行时间方面的推理[65]。由此,将大模型与知识图谱结合,既可以极大地方便构建时间知识图谱、事件图谱和事理图谱,同时所构建的图谱又可以用于增强大模型的复杂时间推理能力,并提升推理结果的可解释型[66]。下图是一个利用知识图谱大模型结合来实现智能系统整体的时间推理能力的例子[66]。大模型与知识图谱的结合使得进行事件以及事件之间的关系,以及其他与时间有关的推理任务方面前景广阔。
在实践中,图模互补系统中,如何如何在知识图谱与大模型之间建立有效的反馈机制,使两者能够根据不同的任务和场景进行动态调整和优化至关重要。我在达观数据的实践中,一方面类似图*一样使用大模型进行知识图谱构建之外,另一个关键的是融合知识图谱和大模型的问答,双方有效的反馈是关键,其架构图如下图所示。这个系统中,一方面大模型会利用知识图谱和用户的查询作为输入,来生成合适的问答答案。另一方面则是通过大模型生成知识图谱的检索语句,并利用图数据库执行结果的反馈来纠正可能存在的错误。最后,这些结果以提示工程的方式输入到大模型中,并生成最终的答案来实现与用户的交互。
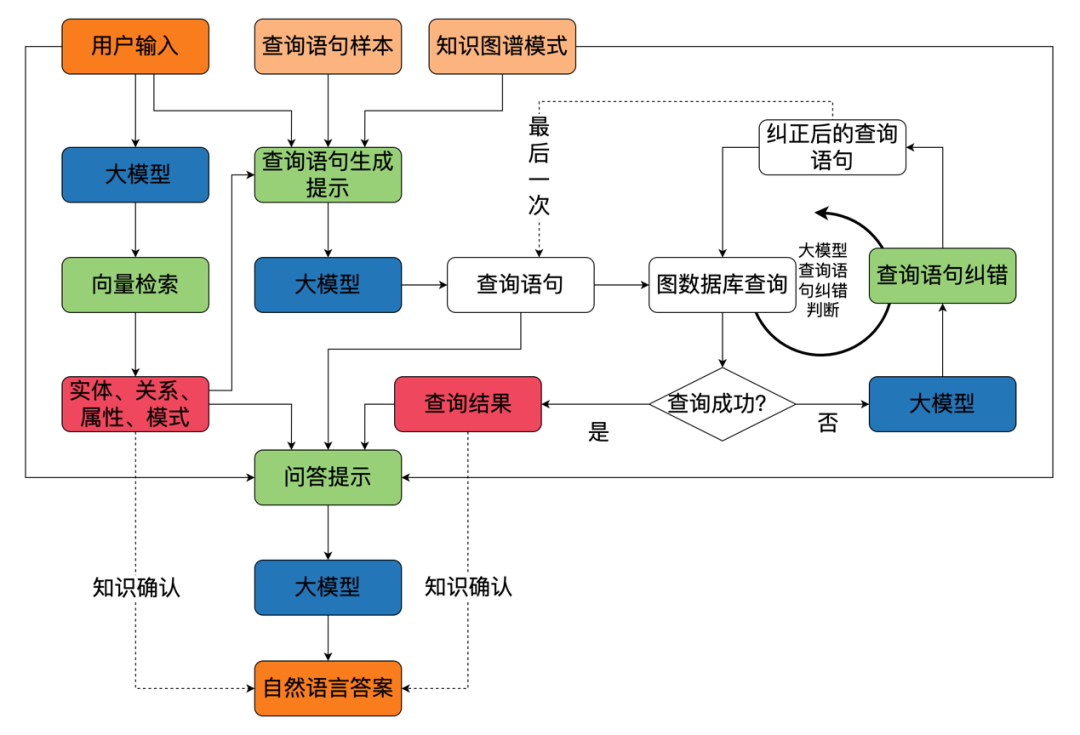
这个系统的关键点在于三点:
1.大模型和知识图谱的互动,以及整个系统能够给大模型的反馈;
2.在不同任务和场景中,知识图谱会提供不同的模式(Schema)给大模型,同时知识图谱的存储系统(图数据库)可以反馈执行结果;
3.前述所提到的各种推理增强方法都可应用到这个系统中,既包括知识图谱增强大模型的推理能力(比如时间推理能力),也包括大模型增强知识图谱的推理能力(比如长路径预测)。
本质上,这就是一种知识图谱和大模型在同等地位上相互协作与共生,双方协同来实现具体任务或领域上的增强,提升系统的智能水平、可控性、可靠性和可解释性。
05
总结
本文使用自然界和科技界广泛存在的共生系统来探讨了知识图谱和大模型的互补与协同,提出了图模互补的思想。在此之上,全面审查了知识图谱增强大模型的方法,大模型增强知识图谱的方法。同时,针对图模互补,从领域和场景两个角度详细解析了图模互补的典型方法,提出了图模互补系统的架构和关键要素。总之,通过全面细致的前沿论文审查和实践经验总结,图模互补系统是大模型浪潮之下产业应用的最佳实践。
参考文献
1. Fautin, D. G. (1991). Review article The Anemonefish Symbiosis: What is Known and What is Not. Symbiosis.
2. 刘乐艺(2022-07-05).青海戈壁荒滩兴起“光伏海”.人民日报海外版,005. http://paper.people.com.cn/rmrbhwb/html/2022-07/05/content_25927103.htm
3. 王文广. (2022). 知识图谱:认知智能理论与实战. 电子工业出版社.
4. Ian Goodfellow, Yoshua Bengio, Aaron Courville. (2017). 深度学习. 人民邮电出版社.
5. Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems NIPS2013 (pp. 3111-3119).
6. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
7. Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H. T., ... & Le, Q. (2022). Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
8. Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., ... & Fiedel, N. (2022). Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
9. Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., ... & Wu, Y. (2023). Palm 2 technical report. arXiv preprint arXiv:2305.10403.
10. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
11. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., ... & Scialom, T. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
12. Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., ... & Synnaeve, G. (2023). Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
13. Luo, H., Sun, Q., Xu, C., Zhao, P., Lou, J., Tao, C., ... & Zhang, D. (2023). Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583.
14. Alayrac, J. B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., ... & Simonyan, K. (2022). Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35, 23716-23736.
15. OpenAI. (2023). GPT-4 technical report. arXiv preprint arXiv:2303.08774.
16. Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473. ICLR2015
17. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008)
18. Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509
19. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
20. Gong, Y., Chung, Y. A., & Glass, J. (2021). Ast: Audio spectrogram transformer. arXiv preprint arXiv:2104.01778.
21. Akbari, H., Yuan, L., Qian, R., Chuang, W. H., Chang, S. F., Cui, Y., & Gong, B. (2021). Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. Advances in Neural Information Processing Systems, 34, 24206-24221.
22. 走向未来. (2023). GPT-4模型架构:它比你想象的更简单. https://mp.weixin.qq.com/s/PKMf_-6R8qieLqEYb1HxUA
23. Shin, R., Razeghi, Y., . Logan IV, R.L., Wallace, E. & Singh, S. (2020). AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). P4222-4235.
24. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
25. 王文广.(2023).跨文化传播中的通用人工智能:变革、机遇与挑战. 对外传播(05),48-51.
26. Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., ... & Zhang, Y. (2023). Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712.
27. 王文广 & 王昊奋.(2023).融合大模型的多模态知识图谱及在金融业的应用. 人工智能(02),18-28+40. doi:10.16453/j.2096-5036.2023.02.002.
28. Ehrlinger, L., & Wöß, W. (2016). Towards a definition of knowledge graphs. SEMANTiCS (Posters, Demos, SuCCESS), 48(1-4), 2.
29. Yao, L., Mao, C., & Luo, Y. (2019). KG-BERT: BERT for knowledge graph completion. arXiv preprint arXiv:1909.03193.
30. Bosselut, A., Rashkin, H., Sap, M., Malaviya, C., Celikyilmaz, A., & Choi, Y. (2019). COMET: Commonsense transformers for automatic knowledge graph construction. arXiv preprint arXiv:1906.05317.
31. Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129.
32. Agarwal O, Ge H, Shakeri S, et al. Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training[J]. arXiv preprint arXiv:2010.12688, 2020.
33. Chen W, Su Y, Yan X, et al. Kgpt: Knowledge-grounded pre-training for data-to-text generation[J]. arXiv preprint arXiv:2010.02307, 2020.
34. Sun Y, Wang S, Feng S, et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation[J]. arXiv preprint arXiv:2107.02137, 2021.
35. Moiseev F, Dong Z, Alfonseca E, et al. SKILL: Structured Knowledge Infusion for Large Language Models[J]. arXiv preprint arXiv:2205.08184, 2022.
36. He L, Zheng S, Yang T, et al. Klmo: Knowledge graph enhanced pretrained language model with fine-grained relationships[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 4536-4542.
37. Wang X, Gao T, Zhu Z, et al. KEPLER: A unified model for knowledge embedding and pre-trained language representation[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 176-194.
38. Liu W, Zhou P, Zhao Z, et al. K-bert: Enabling language representation with knowledge graph[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(03): 2901-2908.
39. Peters M E, Neumann M, Logan IV R L, et al. Knowledge enhanced contextual word representations[J]. arXiv preprint arXiv:1909.04164, 2019.
40. Knowledge graph-enhanced molecular contrastive learning with functional prompt
41. Lin W, Tseng B H, Byrne B. Knowledge-aware graph-enhanced GPT-2 for dialogue state tracking[J]. arXiv preprint arXiv:2104.04466, 2021.
42. Liu Y, Wan Y, He L, et al. Kg-bart: Knowledge graph-augmented bart for generative commonsense reasoning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(7): 6418-6425.
43. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
44. Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., ... & Sifre, L. (2022, June). Improving language models by retrieving from trillions of tokens. In International conference on machine learning (pp. 2206-2240). PMLR.
45. 走向未来(2023-03-21). New Bing技术架构普罗米修斯:AGI 驱动智能应用开发的基本框架.走向未来公众号. https://mp.weixin.qq.com/s/a1YqsrK68kAjcDqdwSvtQw
46. Chen, Z., Singh, A. K., & Sra, M. (2023). LMExplainer: a Knowledge-Enhanced Explainer for Language Models. arXiv preprint arXiv:2303.16537.
47. Guan, Z., Wu, Z., Liu, Z., Wu, D., Ren, H., Li, Q., ... & Liu, N. (2023). Cohortgpt: An enhanced gpt for participant recruitment in clinical study. arXiv preprint arXiv:2307.11346.
48. Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. arXiv preprint arXiv:2209.14610, 2022.
49. OpenSPG(2023-08-26).语义增强可编程知识图谱 SPG白皮书. https://spg.openkg.cn/.
50. Agrawal, M., Hegselmann, S., Lang, H., Kim, Y., & Sontag, D. (2022, December). Large language models are few-shot clinical information extractors. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 1998-2022).
51. Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., ... & Han, W. (2023). Zero-shot information extraction via chatting with chatgpt. arXiv preprint arXiv:2302.10205.
52. Polak, M. P., & Morgan, D. (2023). Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering--Example of ChatGPT. arXiv preprint arXiv:2303.05352.
53. Tang, R., Han, X., Jiang, X., & Hu, X. (2023). Does synthetic data generation of llms help clinical text mining?. arXiv preprint arXiv:2303.04360.
54. Yao, L., Peng, J., Mao, C., & Luo, Y. (2023). Exploring Large Language Models for Knowledge Graph Completion. arXiv preprint arXiv:2308.13916.
55. Zhang, Y., Chen, Z., Zhang, W., & Chen, H. (2023). Making Large Language Models Perform Better in Knowledge Graph Completion. arXiv preprint arXiv:2310.06671.
56. Choudhary, N., & Reddy, C. K. (2023). Complex Logical Reasoning over Knowledge Graphs using Large Language Models. arXiv preprint arXiv:2305.01157.
57. Meyer, L. P., Stadler, C., Frey, J., Radtke, N., Junghanns, K., Meissner, R., ... & Martin, M. (2023). Llm-assisted knowledge graph engineering: Experiments with chatgpt. arXiv preprint arXiv:2307.06917.
58. Sun, J., Xu, C., Tang, L., Wang, S., Lin, C., Gong, Y., ... & Guo, J. (2023). Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph. arXiv preprint arXiv:2307.07697.
59. Luo, L., Ju, J., Xiong, B., Li, Y. F., Haffari, G., & Pan, S. (2023). ChatRule: Mining Logical Rules with Large Language Models for Knowledge Graph Reasoning. arXiv preprint arXiv:2309.01538.
60. Wan, Z., Cheng, F., Mao, Z., Liu, Q., Song, H., Li, J., & Kurohashi, S. (2023). Gpt-re: In-context learning for relation extraction using large language models. arXiv preprint arXiv:2305.02105.
61. Gao, Y., Li, R., Caskey, J., Dligach, D., Miller, T., Churpek, M. M., & Afshar, M. (2023). Leveraging a medical knowledge graph into large language models for diagnosis prediction. arXiv preprint arXiv:2308.14321.
62. Gao, J., Zhao, H., Yu, C., & Xu, R. (2023). Exploring the feasibility of chatgpt for event extraction. arXiv preprint arXiv:2303.03836.
63. Chan, C., Cheng, J., Wang, W., Jiang, Y., Fang, T., Liu, X., & Song, Y. (2023). Chatgpt evaluation on sentence level relations: A focus on temporal, causal, and discourse relations. arXiv preprint arXiv:2304.14827.
64. Yuan, C., Xie, Q., & Ananiadou, S. (2023). Zero-shot temporal relation extraction with chatgpt. arXiv preprint arXiv:2304.05454
65. Tan, Q., Ng, H. T., & Bing, L. (2023). Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models. arXiv preprint arXiv:2306.08952.
66. Yuan, C., Xie, Q., Huang, J., & Ananiadou, S. (2023). Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models. arXiv preprint arXiv:2310.01074.
以上就是本次分享的内容,谢谢。


作者简介
INTRODUCTION

王文广

达观数据副总裁

王文广,高级工程师,CCF高级会员,达观数据副总裁,《知识图谱:认知智能理论与实战》作者,主要研究方向为知识图谱、大模型、自然语言处理、计算机视觉、深度学习、强化学习、AI大工程等。
ORCID:0000-0001-6969-6112
wangwenguang@datagrand.com
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

