
- 1Ubuntu如何下载geo的数据 Linux下载geo R安装Cairo_linux安装cairo
- 2C# winform 请求http ( get , post 两种方式 )_vbnet post get 服务器
- 3配置wpf的cefsharp控件(netcore3.1)_cefsharp.wpf.netcore
- 4简述C++ 多线程编程:实现并发性与性能的关键_c++ 多线程 性能
- 5Android 系统属性(SystemProperties)_sys.powerctl
- 6【AspectJX】Android 中快速集成使用一款 AOP 框架并附加数据埋点解决方案实现
- 7PyQt5 实战记录1 如何进行资源打包_pyqt5 打包 图片
- 8拥抱AI裁员8000!百年巨头IBM的“广进计划”开始了
- 9使用pytorch编写一个yolo模型的图像识别系统_pytorch图像识别
- 10opencv 简单美颜效果_java opencv 图片美化参数
QLoRA:量化LLM的高效微调策略与实践
赞
踩
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。
一、前言
在大型语言模型(LLM)领域,微调是提高性能和调整行为的关键过程。然而,由于内存需求巨大,对于大型模型进行微调可能非常昂贵。最近,华盛顿大学发表了一项关于解决这一问题的创新方案——QLoRA(Quantized Low-Rank Adapter)。
QLoRA是一种新的微调大型语言模型(LLM)的方法,它能够在节省内存的同时保持速度。其工作原理是首先将LLM进行4位量化,从而显著减少模型的内存占用。接着,使用低阶适配器(LoRA)方法对量化的LLM进行微调。LoRA使得改进后的模型能够保留原始LLM的大部分准确性,同时具有更小的体积和更快的速度。
以上是对QLoRA的简要介绍,下面将进一步探讨其原理和应用。
二、QLoRA 介绍
QLoRA 是一种高效的微调方法,通过将梯度反向传播到低阶适配器(LoRA)中,以显著减少内存使用量。它可以在单个48GB GPU上微调650亿个参数的模型,并且能够保持完整的16位微调任务性能。
同时还推出了一个名为 Guanaco 的新模型家族,它在Vicuna基准上表现出色,达到了ChatGPT性能水平的99.3%。令人惊喜的是,只需要在单个GPU上进行24小时的微调,就能够取得如此优异的结果。这些创新使得在资源有限的情况下,能够以更高效的方式进行模型微调,并取得了非常令人满意的成果。
QLoRA是一种创新的微调LLM方法,经过多项任务验证,包括文本分类、问题回答和自然语言生成等,证明了其在各个领域的有效性。这一方法的出现为更广泛的用户和应用程序提供了更便捷的LLM应用方式,并有望进一步推动LLM在不同领域的应用。
2.1、关键创新
统的 LoRA(低秩适配器)和 QLoRA(量化 LoRA)都是微调大型语言模型并减少内存需求的方法。然而,QLoRA 引入了多项创新,以在保持性能的同时进一步减少内存使用。以下是两种方法的比较:
LoRA:
-
- 使用一小组可训练参数(适配器),同时保持完整模型参数固定。
-
- 随机梯度下降期间的梯度通过固定的预训练模型权重传递到适配器,适配器被更新以优化损失函数。
-
- 与完全微调相比,内存效率更高,但仍需要 16 位精度进行训练。
QLoRA:
-
- 通过冻结的 4 位量化预训练语言模型将梯度反向传播到低阶适配器 (LoRA) 中。
-
- 引入 4 位 NormalFloat (NF4),这是一种适用于正态分布数据的信息理论上最佳量化数据类型,可产生比 4 位整数和 4 位浮点更好的经验结果。
-
- 应用双量化,一种对量化常数进行量化的方法,每个参数平均节省约 0.37 位。
-
- 使用具有 NVIDIA 统一内存的分页优化器,以避免在处理具有长序列长度的小批量时在梯度检查点期间出现内存峰值。
-
- 显着降低内存需求,与 16 位完全微调基准相比,允许在单个 48GB GPU 上微调 65B 参数模型,而不会降低运行时间或预测性能。
总之,QLoRA 建立在传统 LoRA 的基础上,引入了 4 位量化、4 位 NormalFloat 数据类型、双量化和分页优化器,以进一步减少内存使用,同时保持与 16 位微调方法相当的性能。
2.2性能分析
通过对模型规模和聊天机器人性能进行深入研究,发现了一些有趣的结果。由于内存开销的限制,常规微调方法无法使用。因此,采用了一种特殊的指令微调方法,在多个数据集、不同的模型架构和参数数量范围内进行了训练,总共训练了1000多个模型。
结果显示,即使使用比之前最先进的模型更小的模型,通过QLoRA对小型高质量数据集进行微调,也能够获得最先进的结果。这表明,数据质量对于模型性能的影响远远大于数据集的大小。这一发现对于优化聊天机器人的性能具有重要的指导意义。
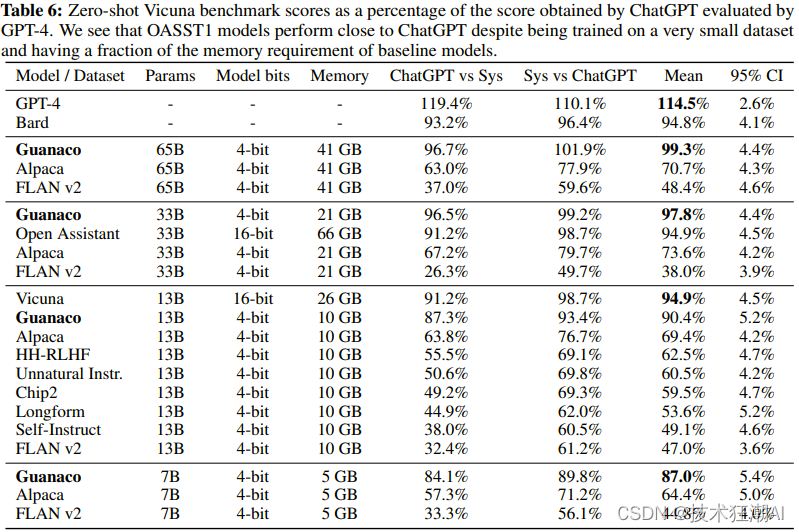
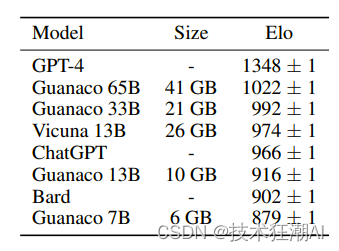
通过对 Guanaco 65B 模型进行了评估,该模型使用 QLORA 对 OASST1 的变体进行了微调。结果表明,它是性能最佳的开源聊天机器人模型,其性能可与 ChatGPT 相媲美。与 GPT-4 相比,Guanaco 65B 和 33B 的预期获胜概率为 30%。
-
在 Vicuna 基准测试中,Guanaco 65B 在 GPT-4 之后表现最好,相对于 ChatGPT 达到了 99.3% 的性能。尽管参数较多,但由于权重仅使用 4 位精度,Guanaco 33B 模型的内存效率比 Vicuna 13B 模型更高。此外,Guanaco 7B 可以安装在现代手机上,同时得分比 Alpaca 13B 高出近 20 个百分点。
-
尽管结果令人印象深刻,但许多模型的性能重叠,置信区间范围很广。作者将这种不确定性归因于缺乏明确的规模规范。为了解决这个问题,他们建议使用 Elo 排名方法,该方法基于人类注释者和 GPT-4 的成对判断。
-
Elo 排名表明,Guanaco 33B 和 65B 模型在 Vicuna 和 OA 基准测试中的表现优于除 GPT-4 之外的所有模型,并且与 ChatGPT 的表现相当。然而,微调数据集的选择极大地影响了性能,表明数据集适用性的重要性。
三、使用 QLoRA 微调 GPT 模型
3.1、QLoRA 的硬件要求:
-
GPU:对于参数少于200亿的模型,例如GPT-J,建议使用至少具有12 GB VRAM的GPU。例如,可以使用 RTX 3060 12 GB GPU。如果您有更大的 GPU 和 24 GB VRAM,则可以使用具有 200 亿个参数的模型,例如 GPT-NeoX-20b。
-
RAM:建议您至少拥有 6 GB RAM。目前大多数计算机都满足这一标准。
-
Hard Drive:由于 GPT-J 和 GPT-NeoX-20b 是大型型号,因此您的硬盘上至少需要有 80 GB 的可用空间。
如果您的系统不满足这些标准,您可以使用 Google Colab 的免费实例。
3.2、QLoRA 的软件要求:
-
CUDA:确保您的计算机上安装了 CUDA。
-
Dependencies: 依赖项:
-
bitsandbytes:该库包含量化大型语言模型(LLM)所需的所有工具。
-
Hugging Face Transformers 和 Accelerate:这些标准库用于 Hugging Face Hub 的高效模型训练。
-
PEFT:该库提供了各种方法的实现,以微调少量额外的模型参数。 LoRA 需要它。
-
数据集:虽然不是强制性的,但可以使用数据集库来获取数据集以进行微调。或者,您可以提供自己的数据集。
确保在继续对 GPT 模型进行基于 QLoRA 的微调之前安装所有必需的软件依赖项。
四、QLoRA 演示
Guanaco 是一个专为研究目的而设计的系统,可以通过以下的演示地址体验。
-
访问 Guanaco Playground 演示[4],这是33B型号的演示,65B型号的演示将稍后进行。
-
如果您想要托管自己的 Guanaco gradio 演示,您可以使用此[5]。对于7B和13B型号,它可以与免费GPU配合使用。
-
关于ChatGPT和guanaco之间的区别,可以在[6]中比较它们的模型响应。在Vicuna提示上,您可以看到ChatGPT和guanaco 65B之间的对比。
五、QLoRA 安装
要使用 Transformer 和 BitsandBytes 加载 4 位模型,您必须从源代码安装加速器和 Transformer,并安装当前版本的 BitsandBytes 库 (0.39.0)。您可以使用以下命令来实现上述目的:
- pip install -q -U bitsandbytes
- pip install -q -U git+https://github.com/huggingface/transformers.git
- pip install -q -U git+https://github.com/huggingface/peft.git
- pip install -q -U git+https://github.com/huggingface/accelerate.git
六、QLoRA 入门
qlora.py 函数可用于对各种数据集进行微调和推断。以下是在 Alpaca 数据集上微调基线模型的基本命令:
python qlora.py --model_name_or_path <path_or_name>
对于大于13B的模型,我们建议调整学习率:
python qlora.py –learning_rate 0.0001 --model_name_or_path <path_or_name>
6.1、量化
量化参数由 BitsandbytesConfig 控制,如下所示:
-
通过
load_in_4bit启用 4 位加载。 -
bnb_4bit_compute_dtype用于线性层计算的数据类型。 -
嵌套量化通过
bnb_4bit_use_double_quant启用。 -
bnb_4bit_quant_type指定用于量化的数据类型。支持两种量化数据类型:fp4(四位浮点)和nf4(常规四位浮点)。我们提倡使用nf4,因为理论上它对于正态分布权重来说是最佳的。
- model = AutoModelForCausalLM.from_pretrained(
- model_name_or_path='/name/or/path/to/your/model',
- load_in_4bit=True,
- device_map='auto',
- max_memory=max_memory,
- torch_dtype=torch.bfloat16,
- quantization_config=BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_compute_dtype=torch.bfloat16,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type='nf4'
- ),
- )
6.2、分页优化器
为了处理 GPU 偶尔耗尽内存的情况,QLoRA 使用了利用 NVIDIA 统一内存功能的分页优化器,该功能在 CPU 和 GPU 之间执行自动页到页传输,其功能与 CPU RAM 和 GPU 之间的常规内存分页非常相似。磁盘。此功能用于为优化器状态分配分页内存,然后在 GPU 内存不足时将其移至 CPU RAM,并在需要时转移回 GPU 内存。
我们可以使用以下参数访问分页优化器。
--optim paged_adamw_32bit
七、使用 QLoRA 微调 LLaMA 2
接下来我们将介绍如何在单个 Google Colab 上微调最新的 Llama-2-7b 模型并将其转变为聊天机器人。我们将利用 Hugging Face 生态系统中的 PEFT 库以及 QLoRA 来实现更高效的内存微调。
7.1、PEFT 或参数高效微调
PEFT(即参数高效微调)是 Hugging Face 的一个新开源库,可将预训练语言模型 (PLM) 高效地适应各种下游应用程序,而无需微调所有模型参数。 PEFT 目前包括以下技术:
-
LoRA:大语言模型的低阶自适应[8]
-
前缀调优:P-Tuning v2:快速调优可与跨尺度和任务的通用微调相媲美
-
P-Tuning:GPT 也能理解[9]
-
即时调优:规模的力量可实现参数高效的即时调优[10]
7.2、设置开发环境
首先需要安装必要的依赖,我们将需要安装 accelerate 、 peft 、 transformers 、 datasets 和 TRL 库,以利用最新的 SFTTrainer 。通过使用 bitsandbytes 将基本模型量化为 4 位。同时还将安装 einops ,因为它是加载 Falcon 模型所必须的库。
- pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
- pip install -q datasets bitsandbytes einops wandb
7.3、准备数据集
我们将从 AlexanderDoria/novel17_test 数据集中加载了 train 数据集分割。该数据集包含了一些法语小说的文本数据,用于进行自然语言处理任务的训练和评估。该数据集中的文本将被用于训练模型,以便让模型能够对法语小说进行自然语言处理。
- from datasets import load_dataset
-
- #dataset_name = "timdettmers/openassistant-guanaco" ###Human ,.,,,,,, ###Assistant
-
- dataset_name = 'AlexanderDoria/novel17_test' #french novels
- dataset = load_dataset(dataset_name, split="train")
7.4、加载模型
加载预训练模型并使用 BitsAndBytesConfig 函数设置了量化配置,将模型加载为 4 位,并使用 torch.float16 计算数据类型。通过 from_pretrained 函数将预训练模型加载到 model 变量中,并将量化配置传递给模型。
- import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoTokenizer
-
- model_name = "TinyPixel/Llama-2-7B-bf16-sharded"
-
- bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=torch.float16,
- )
-
- model = AutoModelForCausalLM.from_pretrained(
- model_name,
- quantization_config=bnb_config,
- trust_remote_code=True
- )
- model.config.use_cache = False

加载预训练模型的分词器,并将其配置为在序列结尾添加填充标记,以便在使用模型进行推断时进行批处理。
- tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
- tokenizer.pad_token = tokenizer.eos_token
创建一个 PEFT 配置对象,以便在训练和评估模型时使用。
- from peft import LoraConfig, get_peft_model
-
- lora_alpha = 16
- lora_dropout = 0.1
- lora_r = 64
-
- peft_config = LoraConfig(
- lora_alpha=lora_alpha,
- lora_dropout=lora_dropout,
- r=lora_r,
- bias="none",
- task_type="CAUSAL_LM"
- )
7.5、加载训练器
我们将使用 TRL 库中的 SFTTrainer ,它提供了transformers Trainer 的包装器,以便使用 PEFT 适配器轻松地在基于指令的数据集上微调模型。让我们首先加载下面的训练参数。
- from transformers import TrainingArguments
-
- output_dir = "./results"
- per_device_train_batch_size = 4
- gradient_accumulation_steps = 4
- optim = "paged_adamw_32bit"
- save_steps = 100
- logging_steps = 10
- learning_rate = 2e-4
- max_grad_norm = 0.3
- max_steps = 100
- warmup_ratio = 0.03
- lr_scheduler_type = "constant"
-
- training_arguments = TrainingArguments(
- output_dir=output_dir,
- per_device_train_batch_size=per_device_train_batch_size,
- gradient_accumulation_steps=gradient_accumulation_steps,
- optim=optim,
- save_steps=save_steps,
- logging_steps=logging_steps,
- learning_rate=learning_rate,
- fp16=True,
- max_grad_norm=max_grad_norm,
- max_steps=max_steps,
- warmup_ratio=warmup_ratio,
- group_by_length=True,
- lr_scheduler_type=lr_scheduler_type,
- )
然后最后将所有内容传递给训练器,创建一个训练器对象,以便对指定的语言模型进行训练。
- from trl import SFTTrainer
-
- max_seq_length = 512
-
- trainer = SFTTrainer(
- model=model,
- train_dataset=dataset,
- peft_config=peft_config,
- dataset_text_field="text",
- max_seq_length=max_seq_length,
- tokenizer=tokenizer,
- args=training_arguments,
- )
我们还将通过升级 float 32 中的层规范来预处理模型,以获得更稳定的训练
- for name, module in trainer.model.named_modules():
- if "norm" in name:
- module = module.to(torch.float32)
7.6、训练模型
接下来启动模型的训练过程,以便通过反向传播算法来更新模型参数,从而提高模型的性能。
trainer.train()
在训练过程中,模型应该很好地收敛,如下所示:
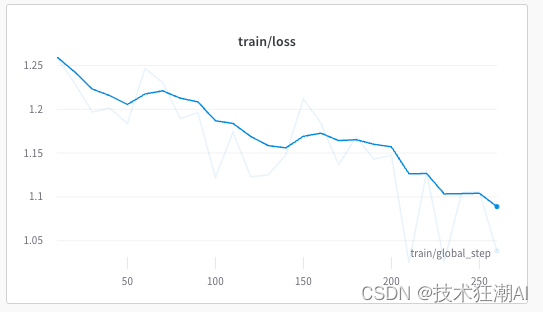
将训练后的模型保存到本地文件系统中以备后续使用。SFTTrainer 仅正确保存适配器,而不是保存整个模型。
- model_to_save = trainer.model.module if hasattr(trainer.model, 'module') else trainer.model # Take care of distributed/parallel training
- model_to_save.save_pretrained("outputs")
使用 LoraConfig 类加载预训练模型的配置信息,并将其与现有的模型结合起来以获取一个新的模型。
- lora_config = LoraConfig.from_pretrained('outputs')
- model = get_peft_model(model, lora_config)
使用预训练模型生成一段新的文本,以便测试模型的生成能力。
- text = "Écrire un texte dans un style baroque sur la glace et le feu ### Assistant: Si j'en luis éton"
- device = "cuda:0"
-
- inputs = tokenizer(text, return_tensors="pt").to(device)
- outputs = model.generate(**inputs, max_new_tokens=50)
- print(tokenizer.decode(outputs[0], skip_special_tokens=True))
将模型推送到 Hugging Face Hub 上,可以与其他人共享和访问。
- from huggingface_hub import login
- login()
-
- model.push_to_hub("llama2-qlora-finetunined-french")
八、QLoRA 的局限性
QLoRA 是一种基于LoRA(Logical Reasoning Architecture)的推理模型,它在某些方面存在一些局限性。以下是一些已知的局限性:
-
推理速度较慢:使用四位的推理时,QLoRA的推理速度相对较慢。目前,QLoRA的四位推理系统尚未与四位矩阵乘法连接,这可能会影响到其性能和速度。
-
Trainer恢复训练失败:在使用Trainer来恢复LoRA的训练运行时,可能会遇到失败的情况。这可能是由于一些内部问题或配置不正确导致的,需要进一步调查和解决。
-
bnb4bitcomputetype='fp16'的不稳定性:目前,使用bnb4bitcomputetype='fp16'可能会导致不稳定性。特别是对于7B LLaMA任务,只有80%的微调运行没有问题。虽然有解决方案,但尚未以比特和字节的形式实现。
-
设置tokenizer.bostokenid为1:为了避免产生困难,建议将tokenizer.bostokenid设置为1。这可能是为了确保在使用QLoRA时,开始标记(BOS)的ID被正确设置为1,以避免潜在的问题。
九、总结
QLoRA 是一种基于量化的语言模型微调方法,它可以将预训练的语言模型量化为低精度格式,从而在保持模型性能的同时提高推理速度和减少模型存储空间。
本文我们探讨了如何使用 QLoRA 方法微调 LLaMA 2 模型,包括加载预训练模型、设置量化配置、使用 SFTTrainer 类创建训练器对象、训练模型等步骤。我们还讨论了如何使用 BitsAndBytesConfig 函数将模型量化为 4 位,并将 torch.float16 计算数据类型用于计算。这些操作可以帮助我们在保持模型性能的同时提高推理速度和减少模型存储空间,从而使得在资源受限的环境下也能够进行语言模型的部署和应用。
十、References
[1]. QLoRA GitHub:
https://github.com/artidoro/qlora
[2]. QLoRA Pager:
https://arxiv.org/abs/2305.14314
[3]. Bits and Bytes (for 4-bit training):
https://github.com/TimDettmers/bitsandbytes
[4]. Guanaco HF Playground:
https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi
[5]. Guanaco Gradio Colab:
https://colab.research.google.com/drive/17XEqL1JcmVWjHkT-WczdYkJlNINacwG7?usp=sharing
[6]. Guanaco vs ChatGPT Colab:
https://colab.research.google.com/drive/1kK6xasHiav9nhiRUJjPMZb4fAED4qRHb?usp=sharing
[7]. PEFT GitHub:
https://github.com/huggingface/peft
[8]. LoRA Pager:
https://arxiv.org/pdf/2106.09685.pdf
[9]. P-Tuning Pager:
https://arxiv.org/pdf/2103.10385.pdf
[10]. Prompt Tuning Pager:
https://arxiv.org/pdf/2104.08691.pdf
[11]. SFTTrainer HF:
https://huggingface.co/docs/trl/main/en/sft_trainer
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。

