
- 1多模态技术在淘宝主搜召回场景的探索
- 2【Linux】网络编程套接字一
- 3循环神经网络实现文本情感分类之使用LSTM完成文本情感分类_lstm情感分类
- 4Pytorch与深度学习 —— 11. 使用 LSTM 做姓名分类预测之 RNN提高篇_请构造一个lstm网络用于人名分类任务
- 5自然语言处理--词向量_词向量不用结合语义
- 6清华NLP组年度巨献:机器翻译30年最重要论文阅读清单(下)_once a man: towards multi-target attack via learni
- 7使用paddle进行身份证识别用到的脚本_padleocr 身份证识别
- 8mask decoder
- 9Fragment简易新闻_android中通过fragement实现 新闻阅读的代码案例
- 10问答模型方案设计
K8S 快速入门(十五)实战篇:Headless Services、StatefulSet 部署有状态服务_statefulset headless service
赞
踩
上一个章节我们已经清楚地的认识的pv,pvc的数据绑定原理,及pv,pvc与pod的绑定方法,那么对于有状态服务部署其实已经非常简单的了,有状态服务本身就是有实时的数据需要存储,那么现在数据存储的问题已经解决了,现在就来一个statefulset的实例部署。
StatefulSet 需要无头服务 来负责 Pod 的网络标识,所以先认识Headless Services。
一、Headless Services
1. Services
前面的章节讲解并演示过 使用Delployment 部署无状态服务。
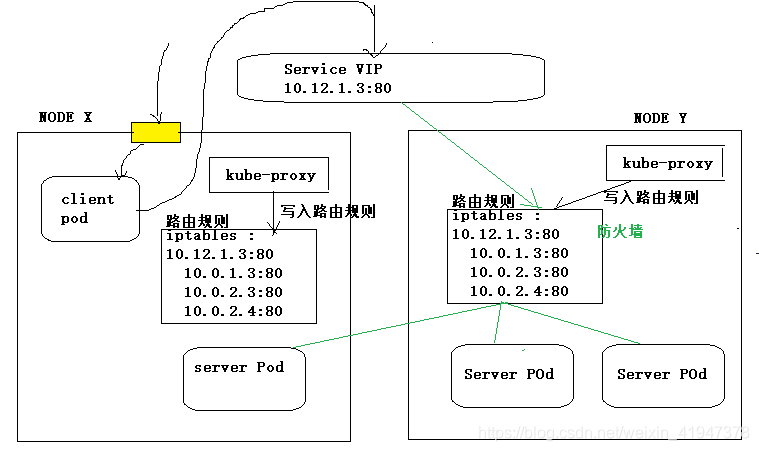
Kubernetes Service:
- 将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
- 使用 Kubernetes,你无需修改应用程序即可使用不熟悉的服务发现机制。 Kubernetes 为 Pods 提供自己的 IP 地址,并为一组 Pod 提供相同的 DNS 名, 并且可以在它们之间进行负载均衡。
2. Headless Services
2.1 理论
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 “None” 来创建 Headless Service。
你可以使用无头 Service 与其他服务发现机制进行接口,而不必与 Kubernetes 的实现捆绑在一起。
对这无头 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
-
带选择算符的服务
对定义了选择算符的无头服务,Endpoint 控制器在 API 中创建了 Endpoints 记录, 并且修改 DNS 配置返回 A 记录(地址),通过这个地址直接到达 Service 的后端 Pod 上。 -
无选择算符的服务
对没有定义选择算符的无头服务,Endpoint 控制器不会创建 Endpoints 记录。 然而 DNS 系统会查找和配置,无论是:- 对于 ExternalName 类型的服务,查找其 CNAME 记录
- 对所有其他类型的服务,查找与 Service 名称相同的任何 Endpoints 的记录
2.2 场景
Headless Services是一种特殊的service,其spec:clusterIP表示为None,这样在实际运行时就不会被分配ClusterIP。
前面章节中我们了解了Service的作用,主要是代理一组Pod提供负载均衡服务,但是有时候我们不需要这种负载均衡场景,比如下面的两个例子。
- 比如kubernetes部署某个kafka集群,这种就不需要service来代理,客户端需要的是一组pod的所有的ip。
- 还有一种场景客户端自己处理负载均衡的逻辑,比如kubernates部署两个mysql,由客户端处理负载请求,或者根本不处理这种负载,就要两套mysql。
例如:
Redis,kafka等等软件,客户端需要的是一组pod对应的ip地址,负载均衡是自己控制的。
客户端自己负载,但是客户端怎么知道有哪些ip?
并且由于pod一但崩溃重建,IP是变化的,那么客户端如何感知到新Pod的IP呢?
就可以通过headless service,本身不提供cluster ip,但是提供了关联的pod的IP信息和域名作为唯一标识。
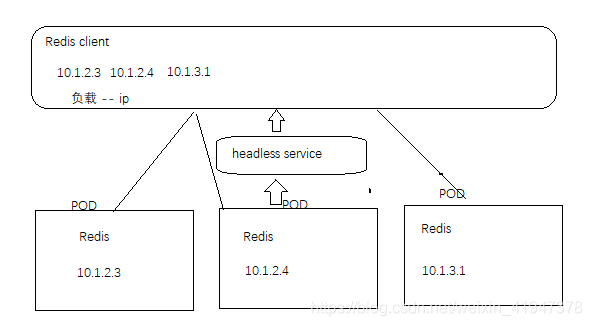
基于上面的例子,kubernates增加了headless serivces功能,字面意思,无头service其实就是该service对外不提供IP,也可以看做它为网络提供了一个唯一标识、唯一ID。下面我们看看它如何配置的。
2.3 实战演示
2.3.1 对比演示,先演示Service
找到以前的案例:
部署一个pod和service:
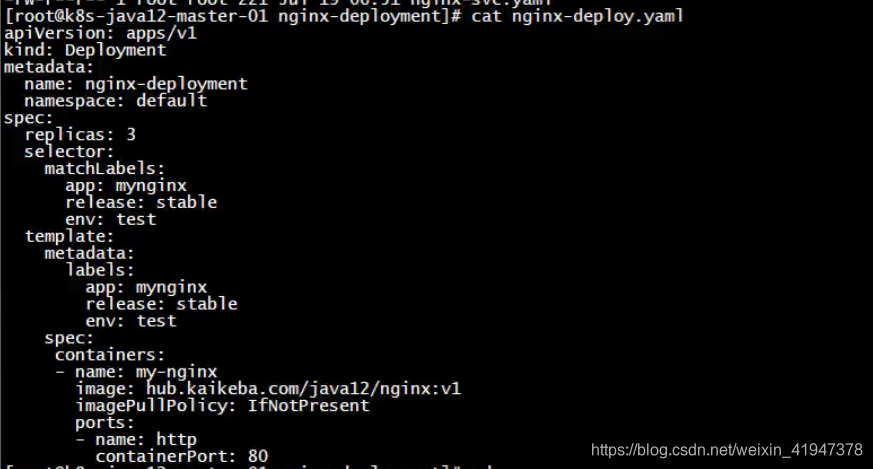
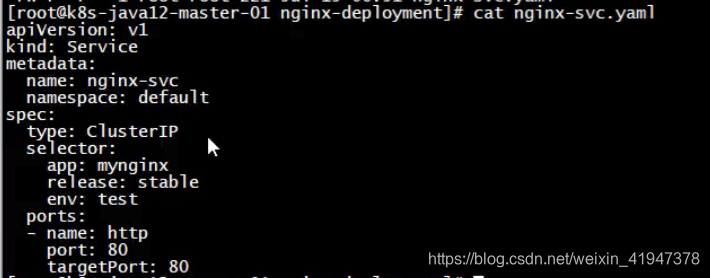
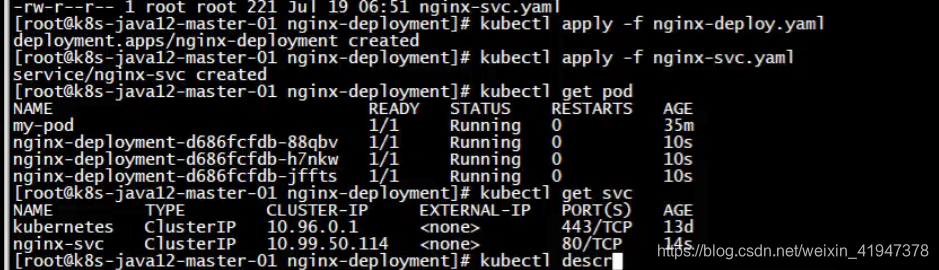

2.3.2 部署headless service
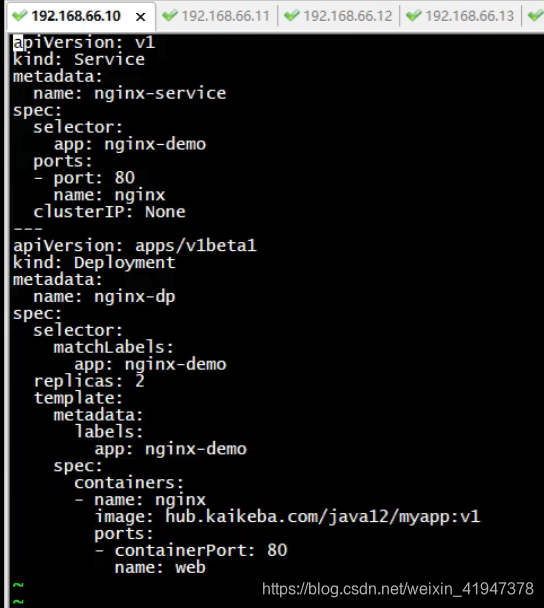
apiVersion: v1 kind: Service metadata: name: nginx-service spec: selector: app: nginx-demo ports: - port: 80 name: nginx clusterIP: None #和Service的区别就在这,这里是None! --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: nginx-dp spec: selector: matchLabels: app: nginx-demo replicas: 2 template: metadata: labels: app: nginx-demo spec: containers: - name: nginx image: hub.kaikeba.com/java12/myapp:v1 ports: - containerPort: 80 name: web

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
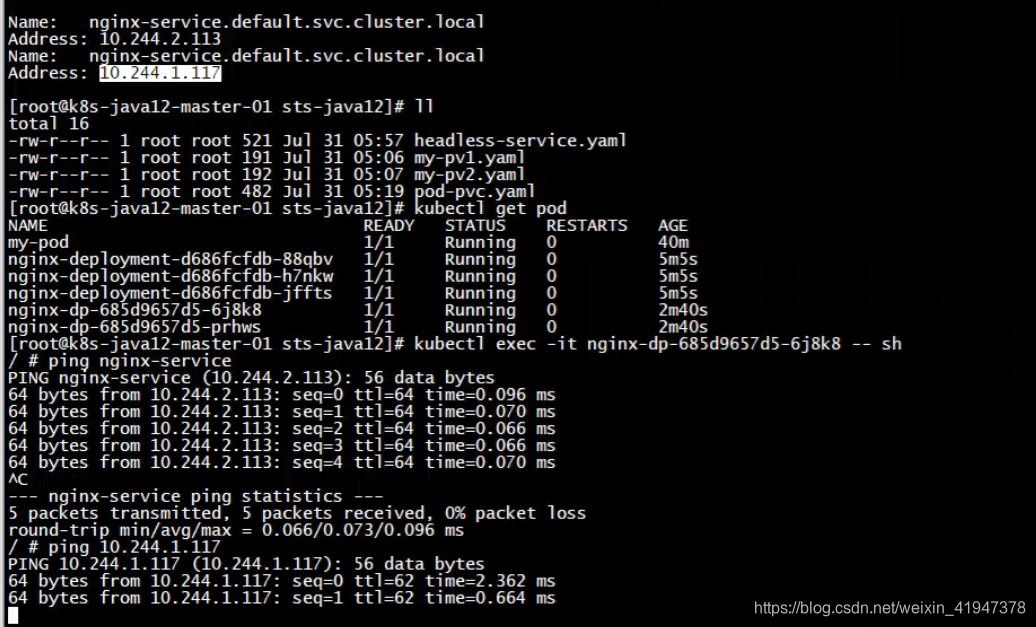
headless service里面有pod的地址,但是没有cluster ip
Dns解析
nslook [serviceName].[nameSpace].svc.cluster.local [DNS服务器ip地址]
可以看到headless service为我们配置了网络域,其中 cluster.local 是集群域
检测pod之间是否可以通过域名相互通信:
直接ping到是第一条DNS记录的ip上
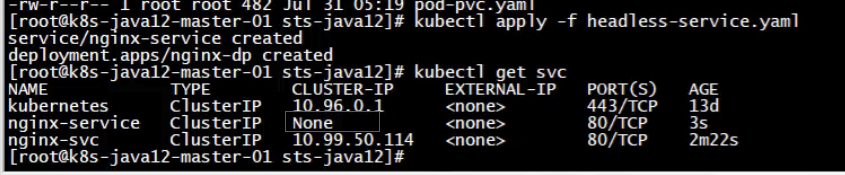
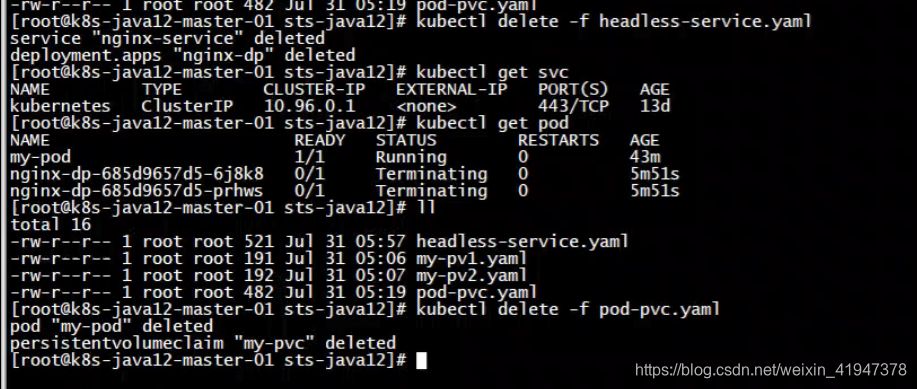
清除测试环境
pod-pvc.yaml是上一节演示的PVC案例。
现在只剩下两个pv,并且可以看到my-pv1的状态已经释放了,但是还不能用,CLAIM还绑定在之前那个PVC,需要进一步手动处理。





二、Statefulset
1. 理论
1.1 介绍
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用 StatefulSet 作为解决方案的一部分。 尽管 StatefulSet 中的单个 Pod 仍可能出现故障, 但持久的 Pod 标识符使得将现有卷与替换已失败 Pod 的新 Pod 相匹配变得更加容易。
1.2 应用场景
StatefullSet 是为了解决有状态服务的问题(对应Deployments 和 ReplicaSets 是为无状态服务而设计)
StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
即Pod重新调度后其 PodName 和 HostName 不变,基于Headlesss Service(即没有 Cluster IP 的 Service)来实现。(ip肯定是会变的)
- 稳定的、持久的存储。
即Pod重新调度后还是能访问的相同持久化数据,基于PVC来实现
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从 0 到 N-1,在下一个Pod运行之前所有之前的Pod必须都是Running 和 Ready 状态),基于 init containers 来实现。
有序部署,有序删除的意义?保证pod的顺序一致
在上面描述中,“稳定的”意味着 Pod 调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或伸缩,则应该使用 由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment 或者 ReplicaSet 可能更适用于你的无状态应用部署需要。
1.3 限制
- 给定 Pod 的存储必须由
PersistentVolume 驱动(就是PV和PVC) 基于所请求的 storage class 来提供,或者由管理员预先提供。 - 删除或者收缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
- StatefulSet 当前需要
无头服务来负责 Pod 的网络标识。你需要负责创建此服务。 - 当删除 StatefulSets 时,StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的 Pod 可以有序地且体面地终止,可以在删除之前将 StatefulSet 缩放为 0。
- 在默认 Pod 管理策略(OrderedReady) 时使用 滚动更新,可能进入需要人工干预 才能修复的损坏状态。
1.4 组件
下面的示例演示了 StatefulSet 的组件。
apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx # has to match .spec.template.metadata.labels serviceName: "nginx" replicas: 3 # by default is 1 template: metadata: labels: app: nginx # has to match .spec.selector.matchLabels spec: terminationGracePeriodSeconds: 10 containers: - name: nginx image: k8s.gcr.io/nginx-slim:0.8 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] storageClassName: "my-storage-class" resources: requests: storage: 1Gi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 名为 nginx 的
Headless Service用来控制网络域名。 - 名为 web 的
StatefulSet有一个Spec,它表明将在独立的 3 个 Pod 副本中启动 nginx 容器。 volumeClaimTemplates将通过PersistentVolumes 驱动提供的 PersistentVolumes 来提供稳定的存储。
即三个组件 Headless Service、StatefulSet、volumeClaimTemplates
1.5 Pod 选择算符
你必须设置 StatefulSet 的 .spec.selector 字段,使之匹配其在 .spec.template.metadata.labels 中设置的标签。在 Kubernetes 1.8 版本之前, 被忽略 .spec.selector 字段会获得默认设置值。 在 1.8 和以后的版本中,未指定匹配的 Pod 选择器将在创建 StatefulSet 期间导致验证错误。
1.6 Pod 标识
StatefulSet Pod 具有唯一的标识,该标识包括顺序标识、稳定的网络标识和稳定的存储。 该标识和 Pod 是绑定的,不管它被调度在哪个节点上。
1.6.1 有序索引
对于具有 N 个副本的 StatefulSet,StatefulSet 中的每个 Pod 将被分配一个整数序号, 从 0 到 N-1,该序号在 StatefulSet 上是唯一的。
1.6.2 稳定的网络 ID
StatefulSet 中的每个 Pod 根据 StatefulSet 的名称和 Pod 的序号派生出它的主机名。 组合主机名的格式为$(StatefulSet 名称)-$(序号)。 上例将会创建三个名称分别为 web-0、web-1、web-2 的 Pod。 StatefulSet 可以使用 无头服务 控制它的 Pod 的网络域。管理域的这个服务的格式为: $(服务名称).$(命名空间).svc.cluster.local,其中 cluster.local 是集群域。 一旦每个 Pod 创建成功,就会得到一个匹配的 DNS 子域,格式为: $(pod 名称).$(所属服务的 DNS 域名),其中所属服务由 StatefulSet 的 serviceName 域来设定。
下面给出一些选择集群域、服务名、StatefulSet 名、及其怎样影响 StatefulSet 的 Pod 上的 DNS 名称的示例:
| 集群域名 | 服务(名字空间/名字) | StatefulSet(名字空间/名字) | StatefulSet 域名 | Pod DNS | Pod 主机名 |
|---|---|---|---|---|---|
| cluster.local | default/nginx | default/web | nginx.default.svc.cluster.local | web-{0…N-1}.nginx.default.svc.cluster.local | web-{0…N-1} |
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0…N-1}.nginx.foo.svc.cluster.local | web-{0…N-1} |
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0…N-1}.nginx.foo.svc.kube.local | web-{0…N-1} |
说明: 集群域会被设置为 cluster.local,除非有其他配置。
1.6.3 稳定的存储
Kubernetes 为每个 VolumeClaimTemplate 创建一个 PersistentVolume。 在上面的 nginx 示例中,每个 Pod 将会得到基于 StorageClass my-storage-class 提供的 1 Gib 的 PersistentVolume。如果没有声明 StorageClass,就会使用默认的 StorageClass。 当一个 Pod 被调度(重新调度)到节点上时,它的 volumeMounts 会挂载与其 PersistentVolumeClaims 相关联的 PersistentVolume。 请注意,当 Pod 或者 StatefulSet 被删除时,与 PersistentVolumeClaims 相关联的 PersistentVolume 并不会被删除。要删除它必须通过手动方式来完成。
VolumeClaimTemplate 为每个pod创建一个PVC
1.6.4 Pod 名称标签
当 StatefulSet 控制器(Controller) 创建 Pod 时, 它会添加一个标签 statefulset.kubernetes.io/pod-name,该标签值设置为 Pod 名称。 这个标签允许你给 StatefulSet 中的特定 Pod 绑定一个 Service。
1.7 部署和扩缩保证
- 对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0…N-1。
- 当删除 Pod 时,它们是逆序终止的,顺序为 N-1…0。
- 在将缩放操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
- 在 Pod 终止之前,所有的继任者必须完全关闭。
StatefulSet 不应将 pod.Spec.TerminationGracePeriodSeconds 设置为 0。 这种做法是不安全的,要强烈阻止。更多的解释请参考 强制删除 StatefulSet Pod。
在上面的 nginx 示例被创建后,会按照 web-0、web-1、web-2 的顺序部署三个 Pod。 在 web-0 进入 Running 和 Ready 状态前不会部署 web-1。在 web-1 进入 Running 和 Ready 状态前不会部署 web-2。 如果 web-1 已经处于 Running 和 Ready 状态,而 web-2 尚未部署,在此期间发生了 web-0 运行失败,那么 web-2 将不会被部署,要等到 web-0 部署完成并进入 Running 和 Ready 状态后,才会部署 web-2。
如果用户想将示例中的 StatefulSet 收缩为 replicas=1,首先被终止的是 web-2。 在 web-2 没有被完全停止和删除前,web-1 不会被终止。 当 web-2 已被终止和删除、web-1 尚未被终止,如果在此期间发生 web-0 运行失败, 那么就不会终止 web-1,必须等到 web-0 进入 Running 和 Ready 状态后才会终止 web-1。
1.8 Pod 管理策略
在 Kubernetes 1.7 及以后的版本中,StatefulSet 允许你放宽其排序保证, 同时通过它的 .spec.podManagementPolicy域保持其唯一性和身份保证。
- OrderedReady Pod 管理
OrderedReady Pod 管理是 StatefulSet 的默认设置。它实现了 上面描述的功能。1.7描述的功能
- 并行 Pod 管理
Parallel Pod 管理让 StatefulSet 控制器并行的启动或终止所有的 Pod, 启动或者终止其他 Pod 前,无需等待 Pod 进入 Running 和 ready 或者完全停止状态。
1.9 更新策略
在 Kubernetes 1.7 及以后的版本中,StatefulSet 的 .spec.updateStrategy 字段让 你可以配置和禁用掉自动滚动更新 Pod 的容器、标签、资源请求或限制、以及注解。
1.9.1 关于删除策略
OnDelete 更新策略实现了 1.6 及以前版本的历史遗留行为。当 StatefulSet 的 .spec.updateStrategy.type 设置为 OnDelete 时,它的控制器将不会自动更新 StatefulSet 中的 Pod。 用户必须手动删除 Pod 以便让控制器创建新的 Pod,以此来对 StatefulSet 的 .spec.template 的变动作出反应。
1.9.2 滚动更新
RollingUpdate 更新策略对 StatefulSet 中的 Pod 执行自动的滚动更新。 在没有声明 .spec.updateStrategy 时,RollingUpdate 是默认配置。 当 StatefulSet 的 .spec.updateStrategy.type 被设置为 RollingUpdate 时, StatefulSet 控制器会删除和重建 StatefulSet 中的每个 Pod。 它将按照与 Pod 终止相同的顺序(从最大序号到最小序号)进行,每次更新一个 Pod。 它会等到被更新的 Pod 进入 Running 和 Ready 状态,然后再更新其前身。
分区
通过声明 .spec.updateStrategy.rollingUpdate.partition 的方式,RollingUpdate 更新策略可以实现分区。 如果声明了一个分区,当 StatefulSet 的 .spec.template 被更新时, 所有序号大于等于该分区序号的 Pod 都会被更新。 所有序号小于该分区序号的 Pod 都不会被更新,并且,即使他们被删除也会依据之前的版本进行重建。 如果 StatefulSet 的 .spec.updateStrategy.rollingUpdate.partition 大于它的 .spec.replicas,对它的 .spec.template 的更新将不会传递到它的 Pod。 在大多数情况下,你不需要使用分区,但如果你希望进行阶段更新、执行金丝雀或执行 分阶段上线,则这些分区会非常有用。
强制回滚
在默认 Pod 管理策略(OrderedReady) 下使用 滚动更新 ,可能进入需要人工干预才能修复的损坏状态。
如果更新后 Pod 模板配置进入无法运行或就绪的状态(例如,由于错误的二进制文件 或应用程序级配置错误),StatefulSet 将停止回滚并等待。
在这种状态下,仅将 Pod 模板还原为正确的配置是不够的。由于 已知问题,StatefulSet 将继续等待损坏状态的 Pod 准备就绪(永远不会发生),然后再尝试将其恢复为正常工作配置。
恢复模板后,还必须删除 StatefulSet 尝试使用错误的配置来运行的 Pod。这样, StatefulSet 才会开始使用被还原的模板来重新创建 Pod。
2. 实战演示
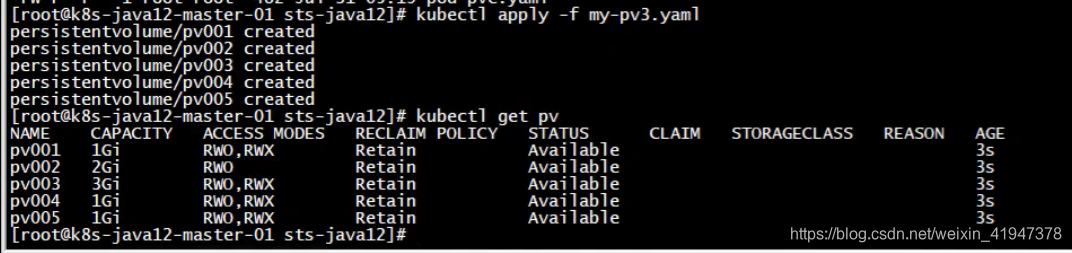
2.1 创建5个PV:
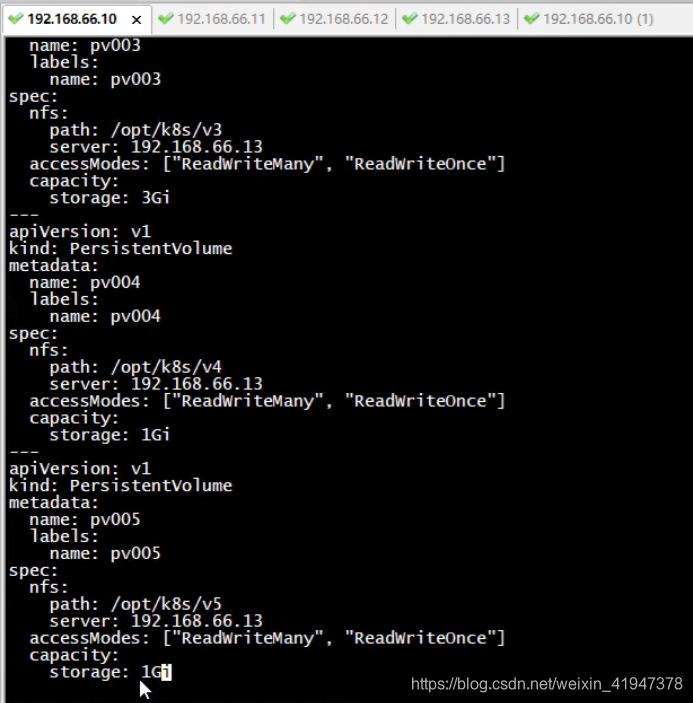
apiVersion: v1 kind: PersistentVolume metadata: name: pv001 labels: name: pv001 spec: nfs: # 绑定一个nfs path: /opt/k8s/v1 server: 192.168.66.13 accessModes: ["ReadWriteMany", "ReadWriteOnce"] # 访问模式 capacity: storage: 1Gi # 存储大小 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv002 labels: name: pv002 spec: nfs: path: /opt/k8s/v2 server: 192.168.66.13 accessModes: ["ReadWriteOnce"] capacity: storage: 2Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: pv003 labels: name: pv003 spec: nfs: path: /opt/k8s/v3 server: 192.168.66.13 accessModes: ["ReadWriteMany", "ReadWriteOnce"] capacity: storage: 3Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: pv004 labels: name: pv004 spec: nfs: path: /opt/k8s/v4 server: 192.168.66.13 accessModes: ["ReadWriteMany", "ReadWriteOnce"] capacity: storage: 1Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: pv005 labels: name: pv005 spec: nfs: path: /opt/k8s/v5 server: 192.168.66.13 accessModes: ["ReadWriteMany", "ReadWriteOnce"] capacity: storage: 1Gi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
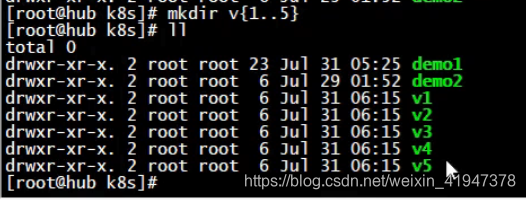
删除原来的测试环境:
创建5个pv:
要确保nfs服务器上对应的目录是存在的。


2.2 声明方式部署:
自定义pv,pod的name名称: statefulsetName-0…N
此时多个pod用一个pvc
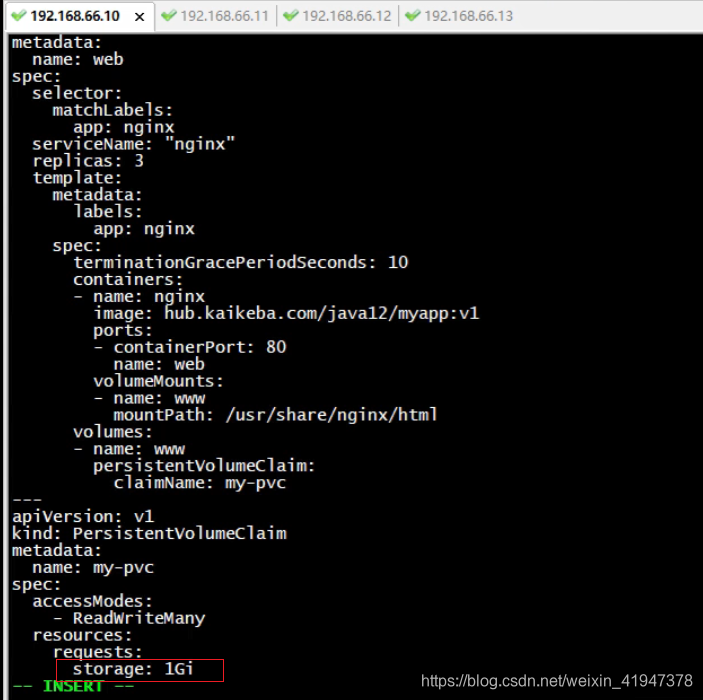
# 部署stateful类型的有状态服务, 指定pvc apiVersion: v1 kind: Service # 创建headless service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet # 创建StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx # 该serviceName就是上面的headless service的name,指定此StatefulSet 属于哪个headless service serviceName: "nginx" replicas: 3 # 副本数量 template: metadata: labels: app: nginx spec: # 等待 terminationGracePeriodSeconds 这么长的时间。(默认为30秒) # 超过terminationGracePeriodSeconds等待时间后, K8S 会强制结束老POD terminationGracePeriodSeconds: 10 containers: - name: nginx image: hub.kaikeba.com/java12/myapp:v1 ports: - containerPort: 80 name: web volumeMounts: - name: www #挂载数据卷 mountPath: /usr/share/nginx/html volumes: - name: www persistentVolumeClaim:# 持久卷申领方式 claimName: my-pvc # 数据卷挂载pvc --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-pvc spec: accessModes: - ReadWriteMany # pvc自动选择pv,需要的访问模式 resources: requests: storage: 5Gi # pvc自动选择pv,需要的存储空间
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
这里我们的pvc要求要5g大小的容量,但是我们创建的pv是没有5g大的
如果找不到匹配的 PV 卷,PVC 申领会无限期地处于未绑定状态。
这样绑定不会成功,所以把storage改成1g
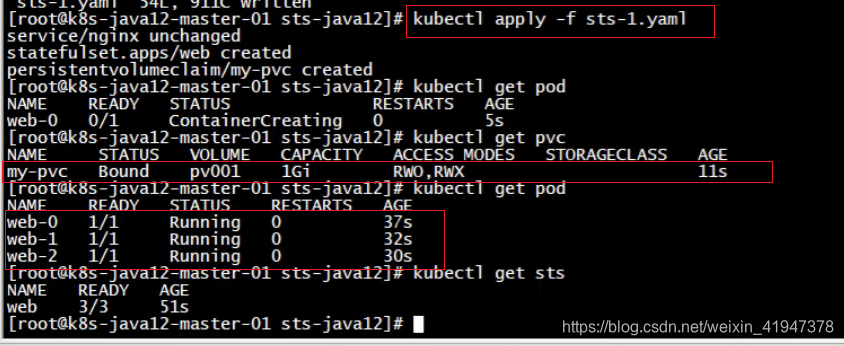
创建查看:
pod的名字是根据StatefulSet 的名字命名的
StatefulSet Name + 1/2/3/…


2.3 模板部署:
volumeClaimTemplates :帮助我们自动创建pvc,不需要我们手动定义pvc
此时每个pod都有一个pvc
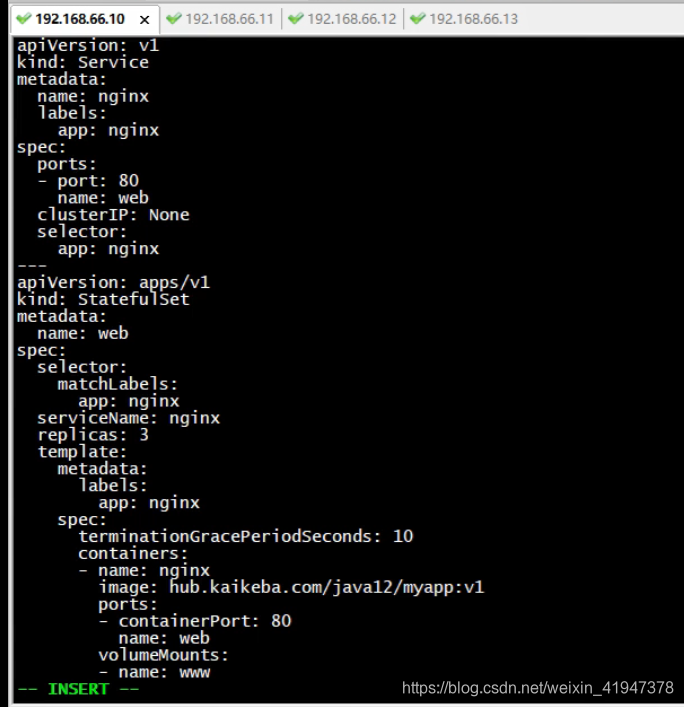
# 使用volumeClaimTemplates直接指定pvc,申请pv apiVersion: v1 kind: Service # 无头Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx serviceName: nginx replicas: 3 template: metadata: labels: app: nginx spec: terminationGracePeriodSeconds: 10 containers: - name: nginx image: hub.kaikeba.com/java12/myapp:v1 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: # 这里不再是volumes,变成了volumeClaimTemplates - metadata: name: www # 这个是pvc的名字 spec: # 下面是pvc请求的方式 accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 1Gi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
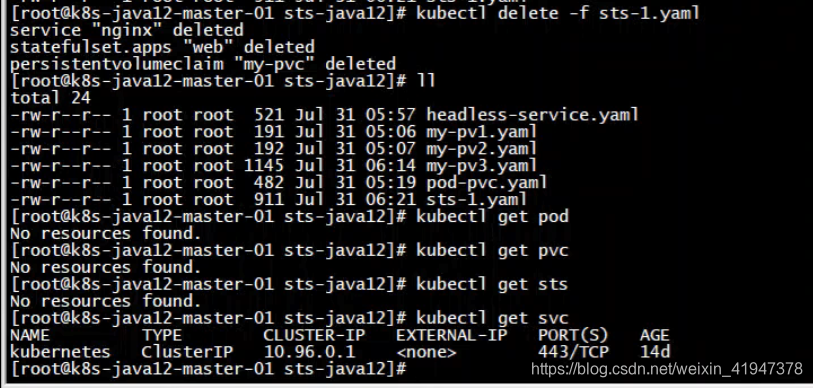
删除之前环境:
创建,看到自动创建了三个pvc
即一个pvc绑定一个pv,一个pvc属于其中一个pod
查看其中一个pod详情:
看到web-0 pod绑定的pvc是www-web-0
web-1 pod绑定的pvc是www-web-1
web-2 pod绑定的pvc是www-web-2

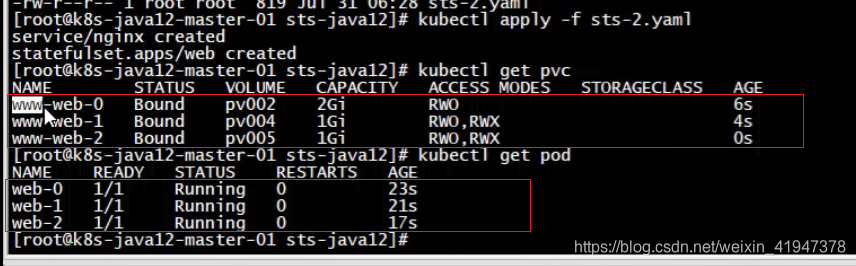

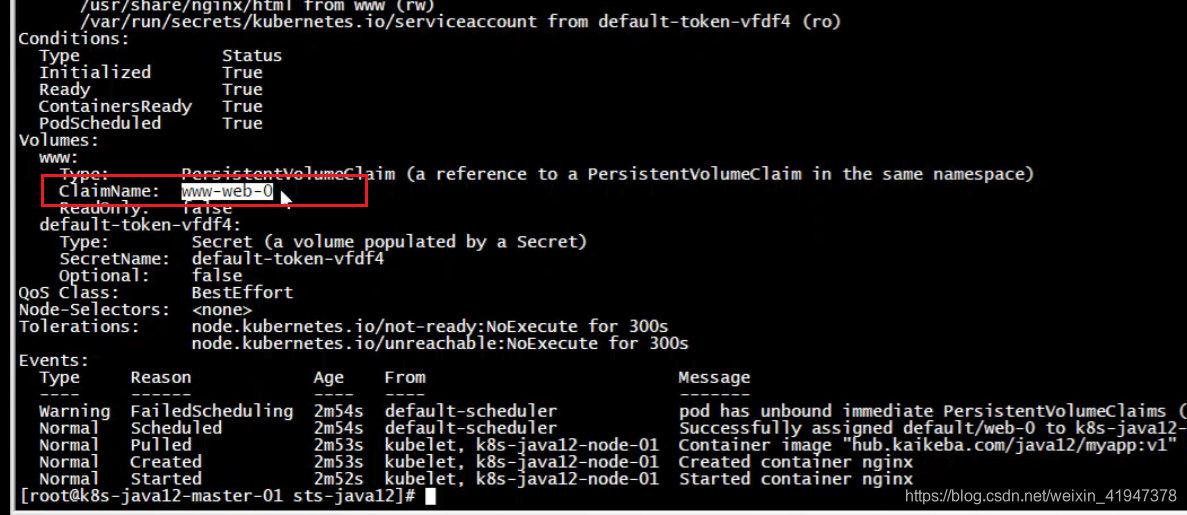
volumeClaimTemplates方式部署,会自动创建pvc,然后绑定相应的pv持久化的数据卷。
特点: 默认创建与pod相对应的数量的pvc,一个pod对应一个pvc,然后挂载一个pv。

