
- 1【2024软件测试面试必会技能】Postman(1): postman的介绍和安装_测试简历中postman怎么描述
- 2python中appium环境搭建(新版本)_python安装appium
- 3SRC应急响应平台汇总_src平台大全
- 4VS Code中出于性能原因,未对长行进行解析。解析长度阈值可通过‘editor.maxTokenizationLineLength‘字符长度限制问题_出于性能原因,未对长行进行解析。解析长度阈值可通过“editor.maxtokenizationli
- 5智能超表面系统级性能研究
- 6STM32之HAL开发——QSPI协议介绍_ospi、qspi
- 7IntelliJ IDEA 2023.2.1使用Git时弹出“使用访问令牌登录”问题解决_如何取消webstorm中自动弹出使用访问令牌登录
- 8利用sentencepiece训练中文分词器,并与LLaMA分词器合并_sentencepiece中文分词
- 9npm digital envelope routines::unsupported_:digital envelope routines::unsupported
- 10(2020)指代消解ontoNotes_Release_5.0处理详细流程_ontonotes release 5.0
【SVD生成视频+可本地部署】ComfyUI使用(二)——使用Stable Video Diffusion生成视频 (2023.11开源)_svd官网
赞
踩
SVD官方主页 : Huggingface | | Stability.ai || 论文地址
huggingface在线运行demo : https://huggingface.co/spaces/multimodalart/stable-video-diffusion
SVD开源代码:Github(含其他项目) || Huggingface
在Comfyui使用: ComfyUI国内下载 | SVD模型下载 | | 官网下载(Github)

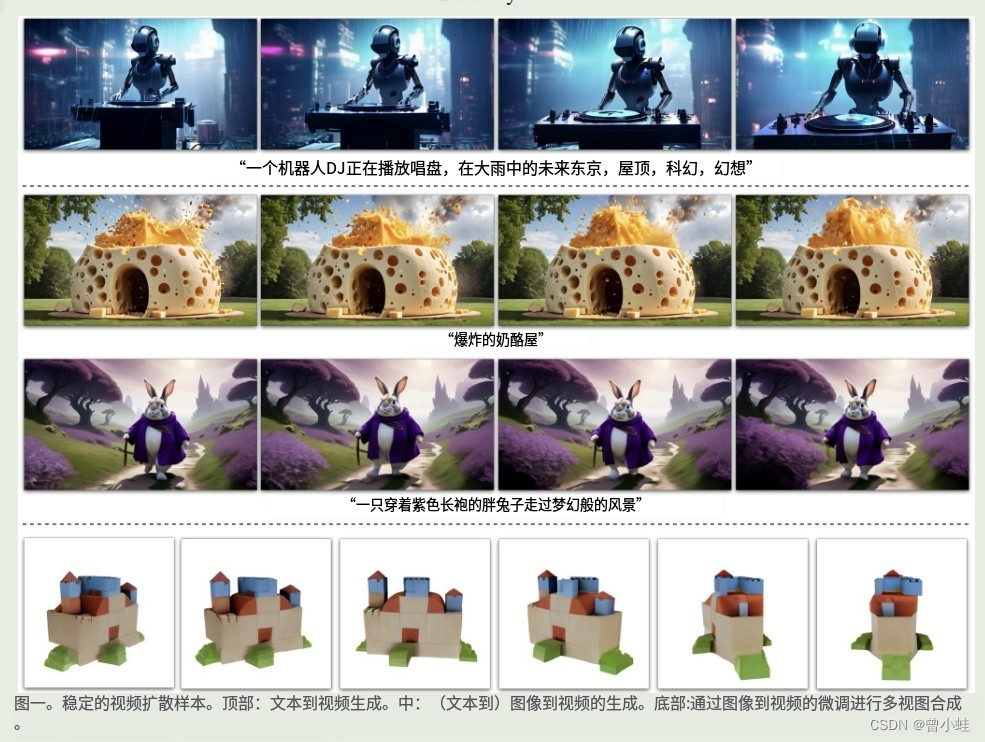
一、SVD是什么,能做什么?(图片到视频)
2023年11月21日 由 Stability AI 开源2个图片到视频模型(“Stable Video Diffusion”(稳定视频扩散模型)
它将静止图像(still image)作为条件帧(conditioning frame),并从中生成视频分辨率(1024x576)。
- 上传已有1张图片,生成相关的视频片段、生成视频长度2-5秒,帧率 3-30帧每秒,
- 串联一个Stable-XL模型,生成图片后,再生成视频 (文字到图片再到视频)
1.1 模型的缺点(不能干的事情)?
- 生成的视频相当
短(<=4秒),并且该模型没有实现完美的真实感。 - 该模型可能生成没有运动的视频,或者生成非常慢的相机平移(
没变化)。 - 不能
直接文本控制模型 (需要串联其他模型)。 - 该模型无法呈现清晰的
文本(legible text)(让艺术字动起来)。 - 一般来说,
人脸和人物可能无法正确生成。 - 模型的自动编码部分是有损的(lossy)。
二、在comfyui中使用 (约15G显存)
使用说明: https://comfyanonymous.github.io/ComfyUI_examples/video/
2.1 Stable-XL生成图片再生成视频(Text2Img2Video)
工作流文件: 链接:https://pan.baidu.com/s/1CvyGmUibreM8SM7AFjt1uA?pwd=0125
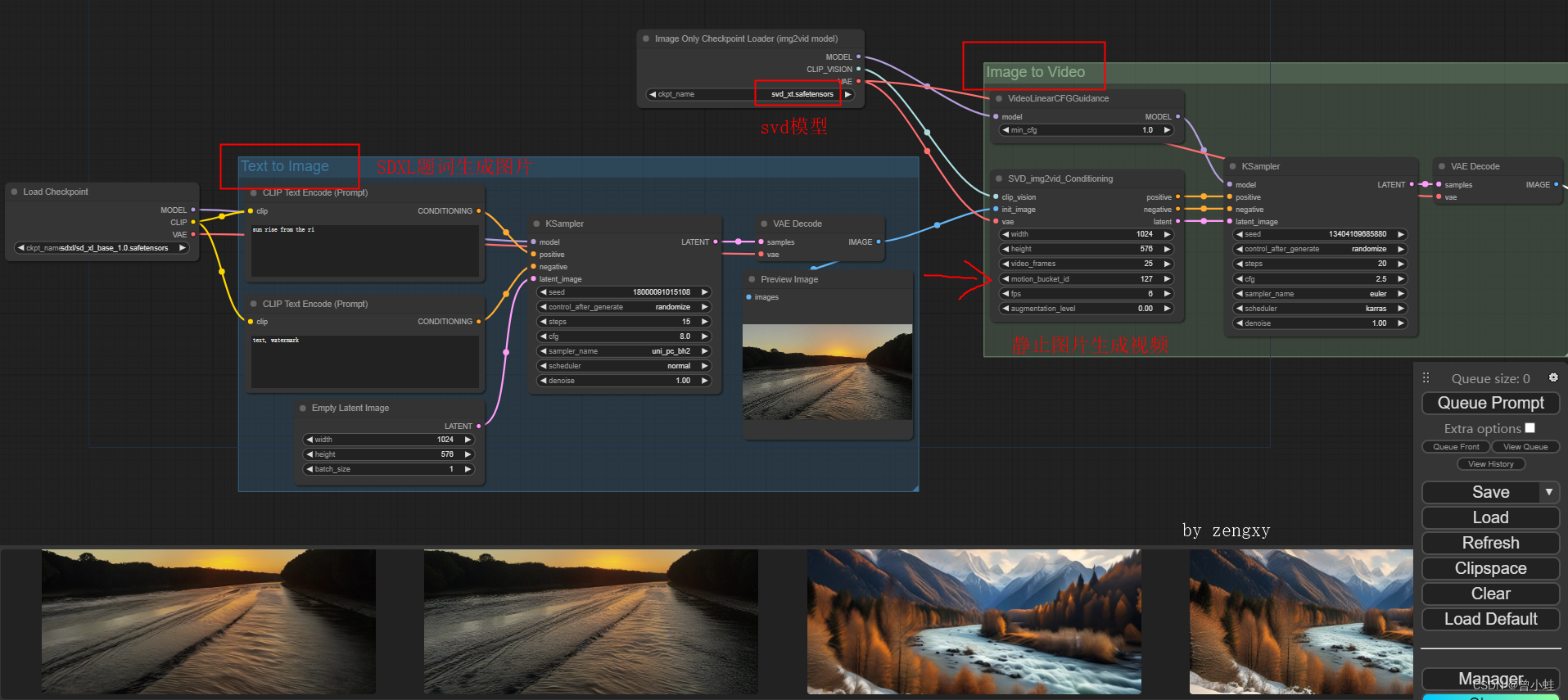
第一次初始化+运行示例,在3090Ti上花费 209.35秒
拍摄美丽的风景自然山脉阿尔卑斯河急流雪天积云
photograph beautiful scenery nature mountains alps river rapids snow sky cumulus clouds

第二次 花费 生成图片(6秒)+视频 (花费70秒)
题词来源于论文图17
一艘悠闲地沿着塞纳河航行的船,背景是文森特·梵高的埃菲尔铁塔
题词
A boat sailing leisurely along the Seine River with the Eiffel Tower in background by Vincent van Gogh
- 1

一只独角兽在一个神奇的小树林里,非常详细
A unicorn in a magical grove, extremely detailed
- 1
- 2

使用上传的图片生成视频?
三、方法 (未完待续)
该模型训练经过,
- 在给定相同大小的上下文帧的情况下,以
576x1024的分辨率生成25帧, - 再从图像帧
微调为视频[14帧]。我们还对广泛使用的f8解码器( f8-decoder )进行了时间一致性(temporal consistency)微调。 - 为了方便起见,我们在这里为该模型额外提供了标准的
逐帧解码器(frame-wise decoder )。
利用了Nvidia提出的Align your Latents基本结构
Align your Latents: 23.07.High-Resolution Video Synthesis with Latent Diffusion Models
项目主页: https://research.nvidia.com/labs/toronto-ai/VideoLDM/

