- 1编程报错:missing 1 required positional argument
- 2python aiml_使用Python AIML搭建聊天机器人的方法示例
- 3Spring Boot项目启动速度优化
- 4开源的页面生成器:拖拽即可生成小程序、H5页面和网站
- 5矩阵分解在自然语言处理中的应用:情感分析和文本摘要
- 6Python - 深度学习系列13- 显卡与CPU计算对比_显卡算法和处理器算法
- 7中文医学大模型“本草”(原名华驼):医学知识增强在中文大型语言模型指令微调上的初步探索...
- 8字节8年经验之谈 —— 聊一聊自动化测试为什么很难落地!
- 9数据库更新两张相关联的表
- 10Asp.Net Core文件上传IFormFile_asp.net core iformfile
两个应用于金融领域的预训练模型FinBERT解读
赞
踩
两个应用于金融领域的FinBERT模型解读
一、熵简科技FinBERT (中文)
Github地址:https://github.com/valuesimplex/FinBERT
熵简科技 AI Lab 近期开源了基于 BERT 架构的金融领域预训练语言模型 FinBERT 1.0。据我们所知,这是国内首个在金融领域大规模语料上训练的开源中文预训练模型。
1.1 网络架构
熵简 FinBERT 在网络结构上采用与 Google 发布的原生BERT 相同的架构。包含了 FinBERT-Base 和 FinBERT-Large 两个版本,其中前者采用了 12 层 Transformer 结构,后者采用了 24 层 Transformer 结构。考虑到在实际使用中的便利性和普遍性,本次发布的模型是 FinBERT-Base 版本。本文后面部分统一以 FinBERT 代指 FinBERT-Base。
2.2 训练语料
FinBERT 1.0 所采用的预训练语料主要包含三大类金融领域的语料,分别如下:
• 金融财经类新闻: 从公开渠道采集的最近十年的金融财经类新闻资讯,约 100 万篇;
• 研报/上市公司公告: 从公开渠道收集的各类研报和公司公告,来自 500 多家境内外研究机构,涉及 9000 家上市公司,包含 150 多种不同类型的研报,共约 200 万篇;
• 金融类百科词条: 从 Wiki 等渠道收集的金融类中文百科词条,约 100 万条。
2.3. 预训练方式
如上图所示,FinBERT 采用了两大类预训练任务,分别是字词级别的预训练和任务级别的预训练。两类预训练任务的细节详述如下:
2.3.1 字词级别的预训练
包含两类子任务:
- Finnacial Whole Word MASK(FWWM):考虑汉语字和词之间的关系,更好的学习到领域内的先验知识。
- Next Sentence Prediction(NSP)
(一)Finnacial Whole Word MASK(FWWM)
基于WWM:
Whole Word Masking (wwm),一般翻译为全词 Mask 或整词 Mask,出自Google 在2019年5月发布的一项升级版的BERT中(第一篇BERT是2018年),主要更改了原预训练阶段的训练样本生成策略。简单来说,传统基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。 在全词Mask中,如果一个完整的词的部分WordPiece子词被 Mask,则同属该词的其他部分也会被 Mask,即全词Mask。
改进:
传统:在谷歌原生的中文 BERT 中,输入是以字为粒度进行切分,没有考虑到领域内共现单词或词组之间的关系,从而无法学习到领域内隐含的先验知识,降低了模型的学习效果。
改进:我们将全词Mask的方法应用在金融领域语料预训练中,即对组成的同一个词的汉字全部进行Mask。首先我们从金融词典、金融类学术文章中,通过自动挖掘结合人工核验的方式,构建出金融领域内的词典,约有10万词。然后抽取预语料和金融词典中共现的单词或词组进行全词 Mask预训练,从而使模型学习到领域内的先验知识,如金融学概念、金融概念之间的相关等,从而增强模型的学习效果。
例如单词:“投资”,字由“投”、“资”构成,按照FWWM的方式,不会仅掩盖“投‘或”资“,会掩盖整个单词“投资”。
(二)Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。具体方式可参考BERT原始文献。
2.3.2 任务级别的预训练
为了让模型更好地学习到语义层的金融领域知识,更全面地学习到金融领域词句的特征分布,我们同时引入了两类有监督学习任务,分别是研报行业分类和财经新闻的金融实体识别任务,具体如下:
研报行业分类:40万条文档级语料,对于公司点评、行业点评类的研报。
财经新闻的金融实体识别:50 万条的有监督语料
2.4 实验
实验一:金融短讯类型分类
数据集共包含 3000 条样本,其中训练集数据约 1100 条,测试集数据约 1900条
实验三:金融情绪分类
数据集共包含 2000 条样本,其中训练集数据约 1300 条,测试集数据约 700条
实验四:金融领域的命名实体识别
数据集共包含 24000 条样本,其中训练集数据共3000条,测试集数据共21000条
2.5 总结
整体而言,为使 FinBERT 1.0 模型可以更充分学习到金融领域内的语义知识,做了如下改进: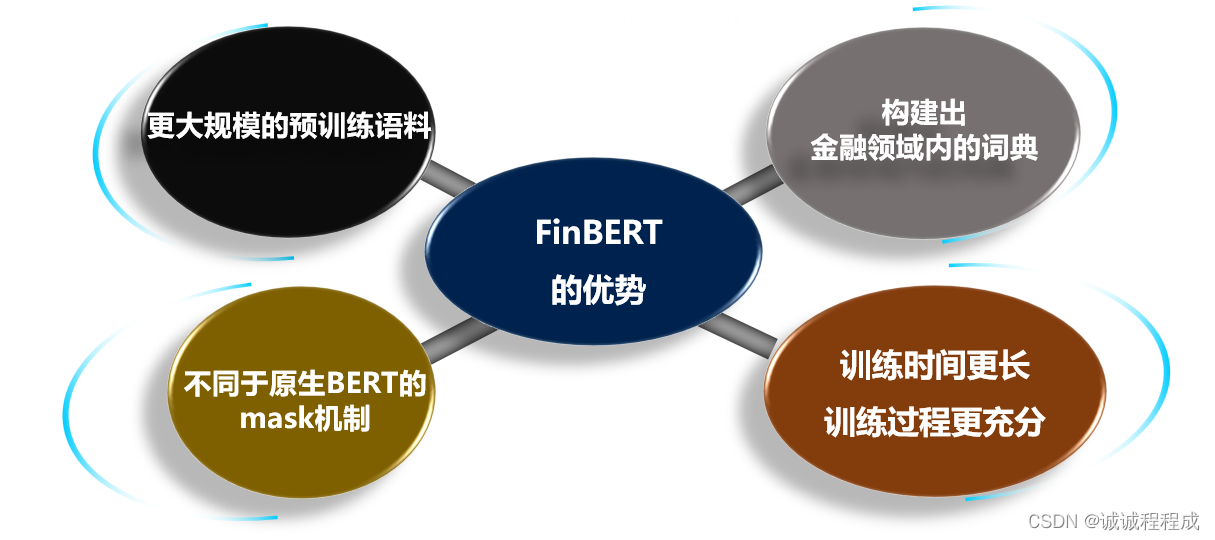
(1)更大规模的预训练语料:
采用更大规模的预训练语料,主要包含如下三大类金融领域的语料:
金融财经类新闻: 从公开渠道采集的最近十年的金融财经类新闻资讯,约 100 万篇;
研报/上市公司公告: 从公开渠道收集的各类研报和公司公告,来自 500 多家境内外研究机构,涉及 9000 家上市公司,包含 150 多种不同类型的研报,共约 200 万篇;
金融类百科词条: 金融类中文百科词条,约 100 万条。
在金融业务专家的指导下,对于各类语料的重要部分进行筛选、预处理,得到最终用于模型训练的语料
(2)构建出金融领域内的词典:
从金融词典、金融类学术文章中,通过自动挖掘结合人工核验的方式,构建出金融领域内的词典,约有10万词
然后抽取预语料和金融词典中共现的单词或词组进行全词 Mask预训练,从而使模型学习到领域内的先验知识,如金融学概念、金融概念之间的相关等,从而增强模型的学习效果
(3)不同于原生BERT的mask机制:
谷歌原生的中文 BERT :输入是以字为粒度进行切分,没有考虑到领域内共现单词或词组之间的关系,从而无法学习到领域内隐含的先验知识,降低了模型的学习效果。
语义信息提取层:全词Mask,即对组成的同一个词的汉字全部进行Mask。
例如单词:“投资”,字由“投”“资”构成,按照全词Mask的方式,不会仅掩盖“投‘或”资“,会掩盖整个单词“投资”。
考虑中文的字和词之间关系,相比于恢复单个字,恢复整个单词对模型更具有挑战性

(4 )训练时间更长、训练过程更充分:
为了取得更好的模型学习效果,延长模型第二阶段预训练时间至与第一阶段的tokens总量一致;
二、FinBERT(英文)
论文:FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
这是一篇被ICLR2020收录的文章,首次将BERT应用于金融领域,提出了FinBERT,FinBERT先在庞大的金融数据集上进行预训练,然后在特定的金融数据集上进行微调,在2个数据集上都取得state-of-the-art的效果,在分类任务上准确率比当前最好的模型提升了14个点。
1.1 挑战
本论文的主要研究兴趣是极性分析,即在特定领域将文本分类为正面、负面或中性。它需要解决两个挑战:
1)利用神经网络的最复杂的分类方法需要大量的标记数据,而标记金融文本片段需要昂贵的专业知识。
2)在一般语料库上训练的情感分析模型不适合该任务,因为金融文本具有专门的语言和独特的词汇,并且倾向于使用模糊的表达方式而不是容易识别的负面/正面词。
本文基于迁移学习的方法,提出了基于bert的模型 – FinBERT,在数据集上达到SOTA的水平。
1.2 方法
本文基于BERT的两大预训练任务:
第一个任务是比起根据当前词预测下一个词,Bert会随机掩蔽句子15%的词并进行相应预测,第
二个任务是next sentence prediction,即给定两个句子,判断第二个句子是否紧跟在第一个句子后面。
本文作者现在一个更庞大的通用的金融语料集上预训练Bert,然后在特定的分类金融语料集上对上一步预训练好的Bert进行微调。
1.2 实验
作者利用两个数据集:
1、TRC2-financial.(包括46143个文档,超过29000000个单词和接近400000条句子)
2、Financial PhraseBank(是从LexisNexis数据库里的金融新闻中随机选中得到的4845条句子,对应的的标签由16个金融和商业背景的人打出)
毫无疑问,在所有的指标中,FinBERT都取得了最佳的效果。
作者在Github发布的代码,提供两个不同数据集上预训练的模型:在 TRC2 上训练的语言模型和在Financial PhraseBank训练的语言模型
github地址:https://github.com/ProsusAI/finBERT