
- 1incrediBuild的一个细节问题_xgconsole profile.xml
- 2树莓派Centos8安装Nginx编译问题及部署VUE项目_树莓派 vue
- 3Android11.0 V-A/B无缝OTA升级update_engine_实现 a/b update
- 4大语言模型在推荐系统的实践应用
- 5Flutter 自定义三角形_flutter 三角形
- 6spyder 无法启动,跟pyqt有关,折腾半天终于好了_spyder 4.1.5 requires pyqt5<5.13; python_version >
- 7macOS Monterey官方镜像下载地址 - 迅雷可用 - 12.13G_macos官方下载地址
- 8输入两个正整数m和n,求出[m,n]区间的所有素数。_输入两个正整数m和n,计算其间的所有素数的个数。
- 9Proe(Creo)如何做剖面图_creo剖面图
- 10使用link rel=“shortcut icon“为网页标题加图标
中文医学信息处理评测基准CBLUE2.0介绍_cmeee数据集
赞
踩
引言

中文医学NLP评测基准CBLUE
中文医学信息处理评测基准CBLUE的全称是Chinese Biomedical Language Understanding Evaluation,CBLUE由中国中文信息学会医疗健康与生物信息处理专业委员发起,由阿里云天池平台承办,目标是推动国内医疗处理领域的技术发展和人才培养。
CBLUE1.0回顾
CBLUE于2011.4月份推出了1.0版本,由医渡云(北京)技术有限公司、平安医疗科技、阿里夸克、鹏城实验室、北京大学、哈尔滨工业大学(深圳)、同济大学、郑州大学等开展智慧医疗研究的单位共同协办。 榜单涵盖了医学文本信息抽取(实体识别、关系抽取)、医学术语归一化、医学文本分类、医学句子语义相关性判定4大类常见的医疗信息处理任务,共包含8个子任务,数据集是由CHIP会议往届的学术评测比赛和夸克医疗搜索业务数据集组成,是业界首个中文医学NLP领域的公开benchmark。
CHIP的全称是China Health Information Processing Conference,是中国中文信息学会医疗健康与生物信息处理专业委员会主办的关于医疗、健康和生物信息处理和数据挖掘等技术的年度会议,是中国健康信息处理领域最重要的学术会议之一。截止到2022年CHIP已经连续举办了七届,每年都有很多医界、学界、业界的专家参与,从事医疗健康赛道的同学们可以关注下这个会议: http://cips-chip.org.cn/
CBLUE1.0经过9个月的发展,截止2022.1月份已累计超过1,200组数据集申请,有接近400支队伍在CBLUE1.0榜单上提交模型评估结果,打榜机构来自于知名互联网大厂、医疗AI企业、医学院&医学研究院和高校,受到了政产学研界的广泛关注[1,2,3,4]。CBLUE工作组还推出了配套的baseline代码[5],对于医学AI或者NLP的初学者比较友好,目前已经被浙江大学软件学院《自然语言处理》课程作为课程配套实践项目,累计培养研究生100余人。初步达到了CBLUE的建设目标:推动国内医疗处理领域的技术发展和人才培养。
CBLUE2.0介绍
在CBLUE发起之初,我们就计划将其建设成一个不断更新的评测基准,CBLUE要代表先进的技术方向,要贴近实际临床,对医疗AI应用落地要起到引导作用。因此在1.0时期,我们就同步开启了2.0的建设工作。CHIP2021大会的CBLUE发布会上,专委会秘书长汤步洲教授也对2.0规划做了简单介绍:

CBLUE2.0发布会
CBLUE2.0的共建单位新增了“复旦大学”、“腾讯天衍实验室”和“中山大学”几家单位,任务种类由1.0的4大类扩充为5大类,子任务由8个增加到15个。总体来说,相比1.0版本CBLUE2.0有如下几个主要变化:
- 技术领域,从自然语言理解(NLU)扩展到自然语言生成(NLG),新增两个医患对话生成任务。
- 任务更贴近临床实践和辅助诊疗,新增了互联网医患对话诊疗任务,以及临床发现事件抽取任务。
- 任务的语料来源更丰富,1.0版本语料来源于医学教科书、医学期刊、临床试验、互联网搜索、医学论坛,2.0版本新增了电子病历(医学专家编制而成)和互联网医患对话语料集,任务更贴近辅助诊疗。
- 对1.0的部分任务做了数据集调整(如更换测试集)和任务设置调整。
随着“互联网+医疗”的迅速发展,在线问诊平台逐渐兴起,在政策和疫情的影响之下,在线问诊需求增长迅速。然而医生资源是稀缺的,由此促使了自动化医疗问诊的发展,以人机对话来辅助问诊过程,我们判断未来基于基于对话的医学自然语言处理必然会受到更多学者的关注和投入,因此将对话类任务列成一个大类。
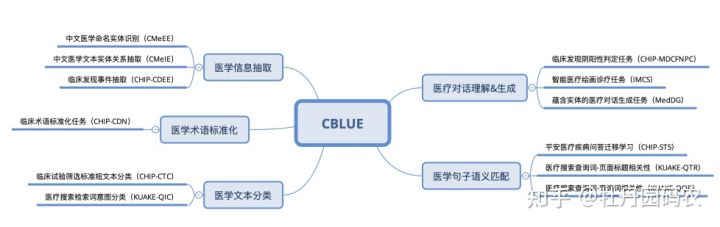
CBLUE2.0任务概图
医学信息抽取
- CMeEE(Chinese Medical Entity Extraction dataset):医学实体识别任务。评测任务共标注了938个文件,47,194个句子,包含了504种常见的儿科疾病、7,085种身体部位、12,907种临床表现、4,354种医疗程序等9大类医学实体,训练、验证和测试集分别为15,000、5,000和3,000条。数据集来源于CHIP2020学术评测比赛,由“北京大学”、“郑州大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供。
- CMeIE(Chinese Medical Information Extraction dataset):医学关系抽取任务。评测数据集来源于儿科和百余种常见疾病(其中儿科训练语料来源于518种儿科疾病,常见疾病训练语料来源于109种常见疾病),共标注了2.8万疾病语句、近7.5万三元组数据和53种关系类型。数据集来源于CHIP2020学术评测比赛,由“郑州大学”、“北京大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供。
- CHIP-CDEE(Clinical Discovery Event Extraction dataset):临床发现事件抽取任务。评测数据集来源于医学专家编制的2,602段电子病历,人工标注了13,905个临床发现事件。 数据集来源于CHIP2021学术评测比赛,由“医渡云(北京)技术有限公司”、“山西医科大学”、“哈尔滨工业大学(深圳)”联合提供。
医学术语归一化
- CHIP-CDN(CHIP - Clinical Diagnosis Normalization dataset):医学术语标准化任务,要求将给定的医学症状实体映射到医学标准字典ICD-10上(如:“右肺结节住院” -> “肺占位性病变”)。评测任务包括训练集6,000条,验证集2,000条和测试集10,000条。数据集来源于CHIP2021学术评测比赛,任务同CHIP2020的CHIP-CDN任务,唯一变化是增加了2,500条手术标准化标注语料来辅助诊断标准化,由医渡云(北京)技术有限公司提供。
医学文本分类
- CHIP-CTC(CHIP - Clinical Trial Criterion dataset):医学文本分类问题。主要针对临床试验筛选标准进行分类,共有44个类别。评测任务包括训练集22,962条,验证集7,682条和测试集10,000条。数据集来源于CHIP2019学术评测比赛,由同济大学生命科学与技术学院提供。
- KUAKE-QIC(KUAKE - Query Intention Classification dataset),医学文本分类问题。针对医疗搜索引擎用户查询进行意图识别,共有11种类别。评测任务包括训练集6,931条,验证集1,955条和测试集1,994条。数据集由阿里夸克提供。
医学句子语义相似度判断
- CHIP-STS(CHIP - Semantic Textual Similarity dataset):医学句子语义匹配问题。数据集包含5大类疾病,给定来自不同病种的问句对,要求判定两个句子语义是否相同或者相近,是2分类问题(0/1两类标签)。评测任务包括训练集16,000条,验证集4,000条和测试集10,000条。数据集来源于CHIP2019学术评测会议,由平安医疗科技公司提供提供。
- KUAKE-QTR(KUAKE – Query/Title Relevance dataset):典型的“检索词-页面标题”相关度匹配问题,是一个4分类问题(相关性分为0~3分4档)。评测任务包括训练集24,174条,验证集2,913条和测试集5,465条。数据集由阿里夸克提供。
- KUAKE-QQR(KUAKE – Query/Query Relevance dataset):典型的“检索词-检索词”相关度匹配问题,主要用于解决搜索长尾词的检索结果提升问题,是一个3分类问题(相关性分为0~2分3档)。评测任务包括训练集15,000条,验证集1,600条和测试集1,596条。数据集由阿里夸克提供。
医学对话理解与生成
- CHIP-MDCFNPC(CHIP - Medical Dialogue Clinical Findings Negative Positive Classification dataset):医患临床发现阴阳性判定任务,考察对互联网医患对话中出现的临床发现(疾病或者症状)进行阴阳性判定分类。评测任务包括训练集6,000条,验证集和测试集各2,000条。数据集来源于CHIP2021学术评测会议,数据集由阿里夸克提供。
- IMCS21 (Intelligent Medical Consultation System):智能诊疗对话评测任务,数据集来源真实的在线医患对话,IMCS涵盖了3个子任务,分别是实体识别(IMCS-NER)、意图识别(IMCS-IR)、诊断识别(IMCS-SR)和医学报告生成(IMCS-MRG),涵盖了端对端的对话理解和生成任务。供标注了 3,052 段医患对话样本,其中训练集1,824条、验证集616条、测试集512条。数据集来源于CCL2021学术评测会议,数据集由复旦大学大数据学院和复旦大学医学院联合提供。
- MedDG(Medical Dialog Generation dataset):蕴含实体的中文医疗对话生成任务,任务要求从给定医生和患者交流的前K句对话历史来生成医生的下一句回复,生成的回复中应当包含尽可能准确的医疗实体。MedDG是一个带有实体标注的医疗对话数据集,希望对话中蕴含的医疗实体可以辅助增强生成任务。评测任务包括训练集数据17,864条,验证集数据2,747条,测试集数据1,600条。数据集由腾讯天衍实验室和中山大学联合提供。
CBLUE挑战榜
- CBLUE官网:https://tianchi.aliyun.com/cblue
- CBLUE详情页:https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414
- CBLUE论文:https://arxiv.org/abs/2106.08087
- Github: https://github.com/CBLUEbenchmark/CBLUE
致谢
CBLUE2.0的发布要特别感谢中国中文信息学会医疗健康与生物信息处理专业委员的认可和支持,感谢专委会秘书长汤步洲老师的大力支持。欢迎国内开展医疗AI的同行们对榜单多提建议并参与到榜单的建设中,一起推进我国医疗AI社区的发展和创新。
引用
[1] https://mp.weixin.qq.com/s/wIqPaa7WBgkxUGLku0RBEw
[2] http://cips-chip.org.cn/2021/CBLUE
[3] https://baijiahao.baidu.com/s?id=1717484132439444143&wfr=spider&for=pc

