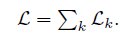- 1C++11的tuple用法笔记_c++ tuple的用法
- 2ElasticSearch搜索office文档_elasticsearch检索doc
- 3Flutter对uniapp是碾压?快算了吧,至少在中国不是。_flutter框架市场占有率和前景
- 4【Grafana安装和使用】_grafana模板下载
- 5ArcGIS教程:37个Arcmap技巧总结(建议收藏)
- 6小程序的组件_小程序组件是什么
- 7Qt多文件传输功能实现及方法概述_qt udp传输文件夹下的所有文件
- 8linux文件目录操作实验报告,linux文件及目录访问权限实验报告
- 9人脸超分辨率阅读论文汇总_2019-joint super-resolution and alignment of tiny
- 10LTP测试工具解析_ltp工具
医学影像处理_medical image caption
赞
踩
一.医学诊断报告生成
1.特点
不同于image captioning 或者 sentence generation, 报告的句子结构更复杂,通常由固定模板套路,设计到医学专业词汇,对语言逻辑性,疾病判断准确性要求高。
2.相关方法
早期方法包括:
基于模板检索
基于学习生成
目前的方法将二者融合,平衡了模板检索和学习生成,产生更准确,流畅有逻辑的诊断报告
3.论文解读
《Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation》
(1)输入正面和侧面图,抽取图像特征(densenet,vgg19等)
(2)将visual feature转为context vector(特征编码)
(3)送入带有注意力机制的stacked-RCNN,得到一系列主题topic
(4)对每个topic,通过fully-connected network+softmax 实现概率预测,最大概率索引为0 对应通过generate 模块生成句子S ; 最大概率索引为正整数 i 对应 retrieve 模块 ,句子也即为database 索引为 i 的句子,通过该步实现句子的预测
(5)计算奖励,根据奖励更新相应模块,优化模型
如果句子为retrieve得到,只计算句子奖励(sentence-reward),更新retrieve模块
如果句子为generat得到,计算句子奖励(sentence-reward)和单词奖励(word-reward),更新retrieve模块和generate模块

创新点:引入强化学习进行选择句子是直接检索还是自己生成,检索模块和生成模块相互促进,相辅相成。
《Knowledge-driven Encode, Retrieve, Paraphrase for Medical Image Report Generation》

(1)输入正面和侧面图,CNN抽取视觉特征
(2)设计了一个图转换器graph transformer–GTR,
(2.1)
Endoer:首先将视觉特征转为Abnormality graph(利用prior knowledge,强化学习那篇没有用到图结构)
Retrieve:从Abnormality graph 转为模板图(得到Templates) 得到模板t (利用prior knowledge,人为构建模板数据库)
Paraphrase: 利用t和Abnormality graph 转为报告图(实现对模板语句的修正和调整,得到Report)
(2.2)
从Abnormality graph 直接转为Disease graph(利用prior knowlege人为构建好疾病图),得到疾病预测
创新点:引入图神经网络(知识图谱)
1.可以更好的利用prior knowledge
2.更好的利用数据的内部结构与相关性。这两点是卷积神经网络所不具备的。
图的节点代表一个疾病或异常等(disease or abnormality) 节点相关性即边权可通过注意力机制(multi-head attention)+先验设定获得
关于transform 和 self-attention 参考链接:https://blog.csdn.net/m0_37565948/article/details/85111700
图转换即GTR模块,就是多次的目标图图内信息传递与源图向目标图的图间信息传递,逐步提升目标图使之涵盖高级语义特征,完成图转换
二. 疾病检测和定位
1.特点
(1)属于Multi-label Classification 问题,一幅图片往往对应多个相关疾病
(2)医学图片标注问题困难:
A.医学图片 label难以获得,需要医学专业基础
B.病变区域相对整幅图片太小,需要密集大量的bounding box, 但这难以实现,太费时间
C.没法在ImageNet完成预训练,ImageNet不包含医学领域图片
以上困难决定医学问题无法使用一般目标检测方法
2.相关方法
数据的获取:通过NLP技术等从病人 疾病image对应的 疾病report 中抽取图片标签信息,构造训练数据库
模型训练:
采用 weakly-supervised训练方法,即仅仅通过图片的标签信息 完成对疾病的检测 同时 定位(没有或仅有少量bounding box 参与)
3.论文解读
《TextRay: Mining Clinical Reports to Gain a Broad Understanding of Chest X-rays》
识别:最后直接整体给出包含所有疾病类别的概率得分向量。模型简单
《ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases》
识别:与上篇类似,疾病类别判断是最后直接整体给出包含所有疾病类别的概率得分向量
定位:通过得到疾病激活图实现

1.对给定图片,使用预训练的Alexnet或GoogleNet或VGGNet或ResNet抽取特征
2.上述主体网络去掉最后全连接层和softmax层,后接Transition Layer,Pooling Layer 和 Prediction Layer
3.Transtion Layer 负责将前面预训练网络的输出转为统一维度 SSD
4.后面Pooling Layer + Prediction Layer(DC C为疾病类别个数) 得到疾病类别预测概率
5.同时,Transtion Layer的输出 SSD 与 Prediction Layer权重相乘 DC, 得到SSC (C个类别激活图)根据激活图设置阈值 得到患病位置的bounding box)
注:图片标签是(0,0,1,0,1,0…) one-hot 形式 1代表有对应疾病
因为数据不平衡,大量数据标签是(0,0,0,0,0,0,),所以训练时易忽视疾病类别
所以设置 Multi-label Classification Loss:即在普通交叉熵损失上加权重,强行让网络重视疾病类别的学习

《Iterative Attention Mining for Weakly Supervised Thoracic Disease Pattern Localization in Chest X-Rays》
识别:每个疾病类别单独计算损失,单独判断是否患该病,即一个疾病对应一个二分类器
定位: 通过Attention mining 对每个疾病分支 独立挖掘激活图实现疾病定位
将用于提取图像特征的主干网络的分类层分成 C 个分支 (C为疾病类别)

1.Attention mining 注意力挖掘
对主干网络最后输出的特征 迭代执行:(每个疾病类别分开执行)
Mt 模板初始化为全1, 在之后的t次迭代中:
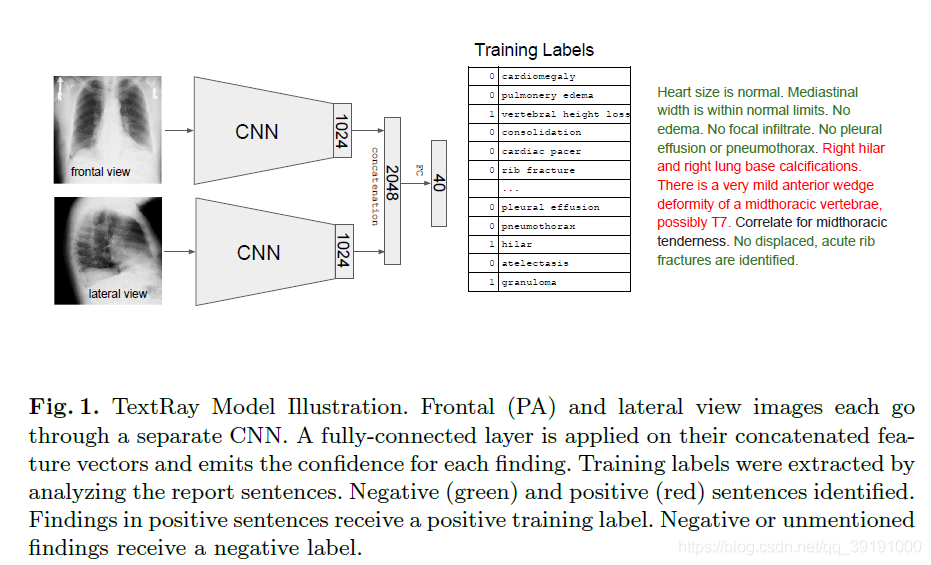
Mt 根据 Ht (激活图)更新,将Ht 全局最大值像素位置对应的Mt-1相应位置 置零,得到更新后的Mt. 重复上述过程,得到c类别对应的t个激活图X1,X2,…Xt
对t个激活图取均值融合,得到最终c类别激活图,即实现c类别疾病的定位
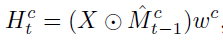
同时,根据Mc , drop out 原始特征图部分区域后送入 c 对应分支,计算输出结果和交叉熵 loss,网络总损失Lcs为各类别loss之和 (drop out 操作通过 Mc 模板 实现)
2.knowledge preservation
drop out 的副作用是使网络忘记学习过的重要内容
使用 l2-distance 强行约束更新后网络和原始网络 保留相应参数内容,该部分损失计算如下:
AM 和 KP 损失和:
3.multi-scale aggregation (MSA) 多尺度融合 将融合后的结果送入AM
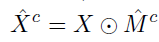
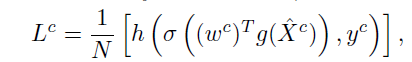
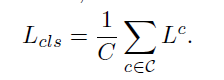
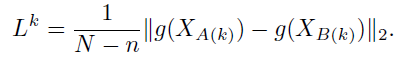
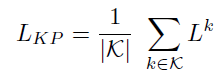
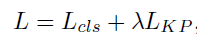
《Thoracic Disease Identification and Localization with Limited Supervision》
识别:同样是每个疾病单独判断,即每个疾病对应一个二分类器。采用多示例学习方法,只要有一个patch患病k,image就很大概率被判为患病k.
定位:与上面工作不同,训练时使用了少量Bounding box标签信息。
将源图片分成众多patch,通过找到所有患病k的patch(这一步实现通过比较当前patch患病k的概率得分与阈值T(0.5)比较,大就判断为患病),完成源图片疾病k的定位。论文不要求位置是标准矩形或正方形。

1.input image 经过 CNN提取特征
2.Patch Slicing 负责对 的特征h’×w’×c’ 转为为固定维度 p’×p’×c’(Max Pooling 或 双线性插值)
这一步类似Yolo思想,代表着将源图片分成p×p个小块
3.进入Recognition Network,最后的输出为p×p×K,K为疾病类别个数,即每个小块都有所有疾病类别的概率得分。因为这是Multi-label classification问题,不同疾病并不相互排斥,所以构建K个二分类器,依次综合p×p个小块得分判断是否换当前病k。
训练部分 (对一个image):
A 如果当前病k 含有Bounding box, 即为普通 监督学习。在当前图片i, bounding box 下, 患病k的概率:
N代表bounding box内patch, M\N代表bounding box 外patch, Pij 代表第 i 个图片的第 j 个 patch的得分概率
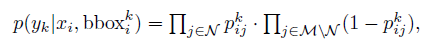
B 如果不含有Bounding box , 看为多示例学习(Multi Instance Learning(MIL)),一个image就是一个bag, 一个patch 是一个instance, 当图片有疾病时,必然至少一个patch 有病,当所有patch都健康,一个image才对应健康。
在当前图片i ,不含bounding box 下,患病k的概率是:(有一个patch 患病,整体概率就会很大)
注:在测试时,我们也采用该式判断图片i 是否换k病
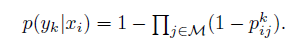
对A,B 数据采用两种不同的loss函数,并联合起来,即可统一成一个完整模型。
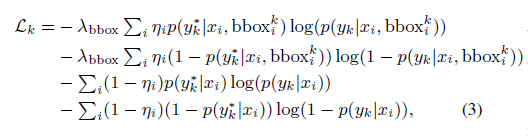

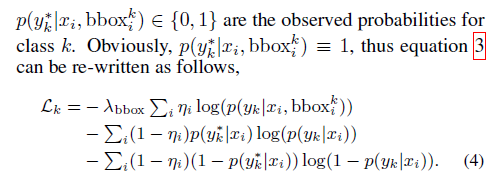
最后,统一所有类别损失,构建end-to-end 网络: