
- 1果然来了!GPT-4.5贵有贵的道理?微软Phi-2精准超越谷歌;LLM怪诞心理学;斯坦福创业课精华笔记;新手LLM训练系统指南 |ShowMeAI日报_gpt4.5
- 2vuex报错:Property or method “$store“ is not defined on the instance but referenced during render. Make_property or method "$store" is not defined on the
- 3Python 指定信息在批量文件中搜索_pymatgen 批量搜索结构
- 4机器学习笔记(八)——随机梯度上升(下降)算法调优
- 5java.lang.management接口MemoryMXBean_managementfactory.getmemorymxbean()
- 6ChatGPT PLUS 团队版 和 ChatGPT PLUS 比较_gptplus团队版更便宜么
- 7Midjourney学习系列之三——宝藏网站与博主分享_mj参考网站
- 8Android显示PDF文件之iText_android itextg读取显示pdf文件
- 9定制化区块链交易所开发:Dapp、DeFi和IDO的全方位解决方案
- 10鸿蒙原生应用/元服务开发-代理提醒说明(一)
特征提取方法简介
赞
踩
one-hot 表示一个词
bag-of-words 表示一段文本
tf-idf 用频率的手段来表征词语的重要性
text-rank 借鉴page-rank来表征词语的权重
从基于SVD纯数学分解词文档矩阵的LSA,到pLSA中用概率手段来表征文档形成过程并将词文档矩阵的求解结果赋予概率含义,再到LDA中引入两个共轭分布从而完美引入先验
1. one-hot
1.1 one-hot编码
什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
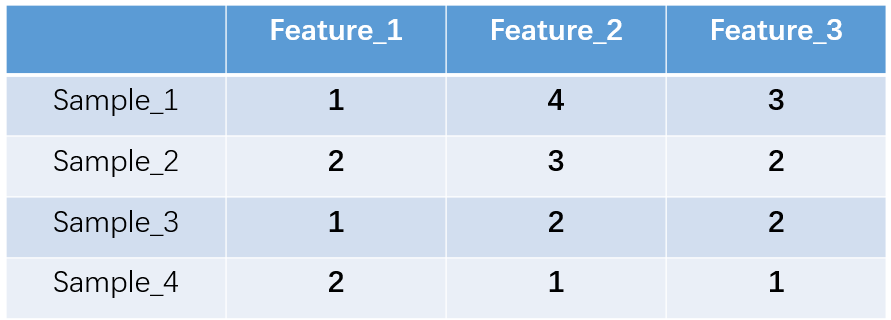
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:
这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,所以我们可以得到这些样本特征的新表示:
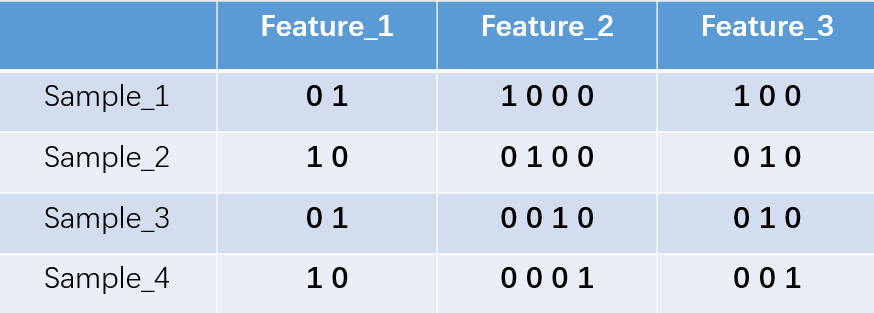
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

1.2 one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
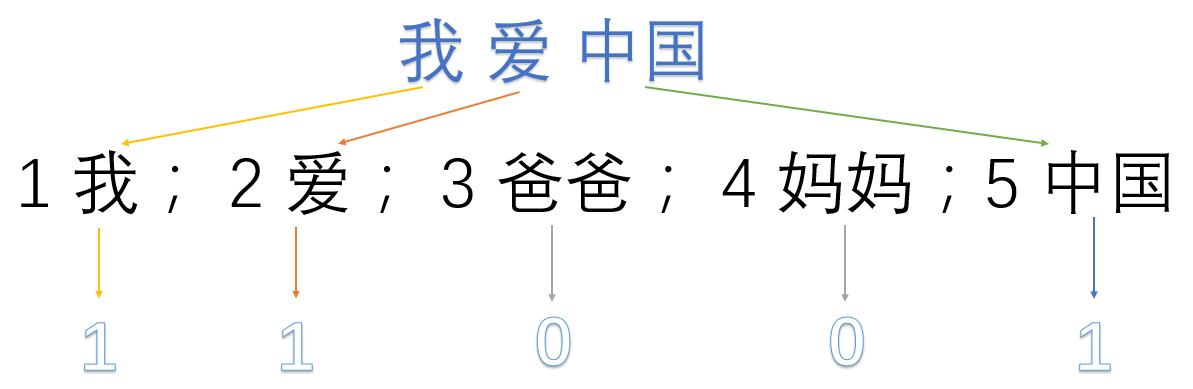
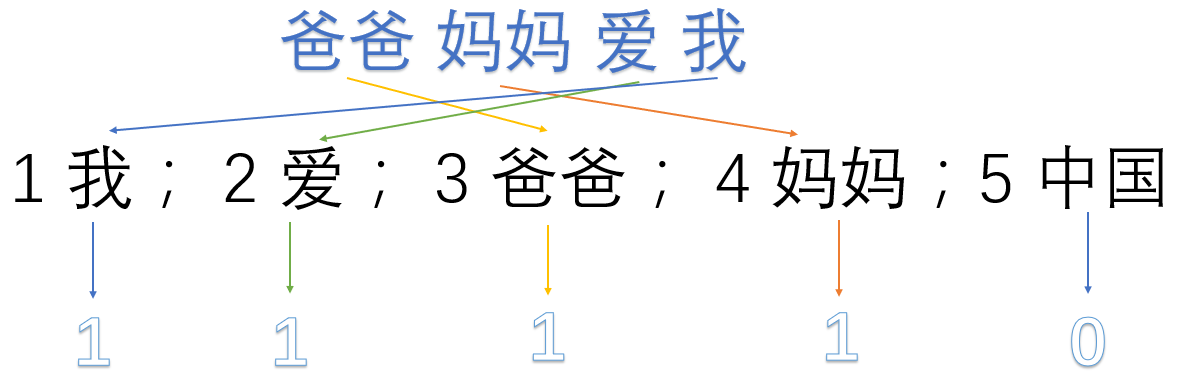

因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
sklearn实现one hot encode
- from sklearn import preprocessing
-
- enc = preprocessing.OneHotEncoder() # 创建对象
- enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 拟合
- array = enc.transform([[0,1,3]]).toarray() # 转化
- print(array)
2. bag-of-words
词袋表示,也称为计数向量表示(Count Vectors)。文档的向量表示可以直接用单词的向量进行求和得到。
词袋模型能够把一个句子转化为向量表示,是比较简单直白的一种方法,它不考虑句子中单词的顺序,只考虑词表(vocabulary)中单词在这个句子中的出现次数。下面直接来看一个例子吧(例子直接用wiki上的例子):
"John likes to watch movies, Mary likes movies too"
"John also likes to watch football games"
对于这两个句子,我们要用词袋模型把它转化为向量表示,这两个句子形成的词表(不去停用词)为:
[‘also’, ‘football’, ‘games’, ‘john’, ‘likes’, ‘mary’, ‘movies’, ‘to’, ‘too’, ‘watch’]
因此,它们的向量表示为:

scikit-learn中的CountVectorizer()函数实现了BOW模型,下面来看看用法:
- from sklearn.feature_extraction.text import CountVectorizer
- corpus = [
- "John likes to watch movies, Mary likes movies too",
- "John also likes to watch football games",
- ]
- vectorizer = CountVectorizer()
- X = vectorizer.fit_transform(corpus)
- print(vectorizer.get_feature_names())
- print(X.toarray())
-
- #输出结果:
- #['also', 'football', 'games', 'john', 'likes', 'mary', 'movies', 'to', 'too', 'watch']
- #[[0 0 0 1 2 1 2 1 1 1]
- # [1 1 1 1 1 0 0 1 0 1]]
3. Bi-gram和N-gram
与词袋模型原理类似,Bi-gram将相邻两个单词编上索引,N-gram将相邻N个单词编上索引。
为 Bi-gram建立索引:
- {"John likes”: 1,
- "likes to”: 2,
- "to watch”: 3,
- "watch movies”: 4,
- "Mary likes”: 5,
- "likes too”: 6,
- "John also”: 7,
- "also likes”: 8,
- "watch football": 9,
- "football games": 10}
这样,原来的两句话就可以表示为:
- John likes to watch movies. Mary likes too. -->> [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
- John also likes to watch football games. -->> [0, 1, 1, 0, 0, 0, 1, 1, 1, 1]
这种做法的优点是考虑了词的顺序,但是缺点也很明显,就是造成了词向量的急剧膨胀。
4. TF-IDF
IF-IDF是信息检索(IR)中最常用的一种文本表示法。算法的思想也很简单,就是统计每个词出现的词频(TF),然后再为其附上一个权值参数(IDF)。举个例子:
现在假设我们要统计一篇文档中的前10个关键词,应该怎么下手?首先想到的是统计一下文档中每个词出现的频率(TF),词频越高,这个词就越重要。但是统计完你可能会发现你得到的关键词基本都是“的”、“是”、“为”这样没有实际意义的词(停用词),这个问题怎么解决呢?你可能会想到为每个词都加一个权重,像这种”停用词“就加一个很小的权重(甚至是置为0),这个权重就是IDF。下面再来看看公式:

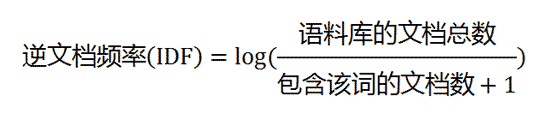
IF应该很容易理解就是计算词频,IDF衡量词的常见程度。为了计算IDF我们需要事先准备一个语料库用来模拟语言的使用环境,如果一个词越是常见,那么式子中分母就越大,逆文档频率就越小越接近于0。这里的分母+1是为了避免分母为0的情况出现。TF-IDF的计算公式如下:
根据公式很容易看出,TF-IDF的值与该词在文章中出现的频率成正比,与该词在整个语料库中出现的频率成反比,因此可以很好的实现提取文章中关键词的目的。
优缺点分析
优点:简单快速,结果比较符合实际
缺点:单纯考虑词频,忽略了词与词的位置信息以及词与词之间的相互关系。
sklearn实现tfidf

原文链接:
https://www.cnblogs.com/lianyingteng/p/7755545.html
https://blog.csdn.net/u012328159/article/details/84719494
https://zhuanlan.zhihu.com/p/42310942

